鐵路客票售票系統接口數據速查程序分析與設計
2019-01-25 06:09:22中國鐵路上海局集團有限公司收入稽查處
上海鐵道增刊 2018年4期
王 珂 中國鐵路上海局集團有限公司收入稽查處
1 客票系統接口文件信息檢索工作概述
1.1 客票系統接口文件概述
鐵路客票售票系統是由鐵道科學研究院(下稱鐵科院)開發的中國鐵路客運的制票系統。系統采用導出程序將每日數據導出為接口文件,向各局集團公司收入部門、統計部門提供客票售票相關數據,以協助相關單位利用這些數據進一步開展收入審核、統計、核算等相關工作。由于網絡安全需求設計,客票售票網與鐵路辦公網物理隔斷,鐵科院設計、實施了接口服務器設備,每日從客票網向鐵路辦公網轉移客票系統接口文件。每天每個售票站一般會產生13個接口文件,分別是車站售票存根(LS文件)、車站退票存根(LR文件)、財收二匯總數據(kcs2文件)、財收四匯總數據(kcs4文件)、退票二號表數據(st2文件)、售票二號表數據(sk2文件)、電子客票交易明細數據(SEPAY文件)、卡務窗口二號表數據(ZT2文件)、卡務財收四數據(ZT4文件)、閘機手續費明細數據(ZT1)、售票廢票數據(FP數據)、外站售本站存根(YS文件)、外站退本站存根(YR文件),這些文件是運輸收入后續審核、核算、列賬的基礎,有著十分重要的作用。
上海局集團公司是全路第一客運企業,2018年日均售票量超過270萬張,日均改簽、退票量合計超3萬張。超過200個客運營業站單日生成的接口文件尺寸約為4 GiB,合計每月接口文件數量超過4萬個,總大小超過120 GiB,記錄總數超過1億條。這樣規模的數據量無論是數據文件的存儲、歸檔、使用都有別于傳統的數據文件操作,對實施人員的技術水平是一個不小的考驗。
1.2 傳統接口文件查詢作業的弊端
接口文件是收入核算的原始數據,根據會計法要求,原始憑證應妥善保存15年,為了更好地存儲與備份這些基礎信息,收入稽查處建設了客票系統接口數據歸檔服務器,存放來自客票接口服務器的接口文件。
接口文件以車站電報碼作為文件擴展名,其內容是逗號分隔的文本文件,每一行代表一條記錄。收入處工作人員在電子支付差異核對、清算數據核對、特殊售票記錄確認等特殊情況下需要直接對接口文件的內容進行檢索。采用傳統方式檢索,首先確認需要查詢的車站電報碼,找到對應時間區間的接口文件,并通過FTP軟件下載到本地。隨后,利用EmEditor或UltraEditor等文本編輯器逐個打開文件,利用編輯器的查找功能,查詢文件內的內容。
傳統的查詢方式有很多弊端,首先,文件在查閱前,需要逐個找到并利用FTP工具下載到本地,對于互聯網售票或虹橋等大站的售票存根來說,下載過程也需要消耗可觀的時間。其次,接口文件內容以逗號分隔,利用文本編輯工具打開后數據緊密排列在一起,沒有分列顯示,也沒有字段說明,要分析某條數據,需要依靠人工經驗并花費大量的時間。最后,檢索工作依賴人工,只能逐個打開查詢,無法并行檢索,文件數量大時,檢索相應的數據需要花費大量的精力和時間,效率很低。
2 客票系統接口文件速查需求分析
鑒于以上問題,本人設計并開發了“客票售票系統接口數據速查程序”下稱速查程序),程序在規劃、分析時,著重考慮了以下幾點需求:
(1)跨單位跨時間段信息通查需求
考慮到信息檢索工作常常需要檢索多個單位某個時間范圍內所有的數據存根,程序應實現跨單位、跨時間段信息檢索功能。舉例來說,2018年10月份香港跨境高鐵運行后,為核對跨境高鐵收入,收入處審核部希望檢索11月全局范圍內所有車站發售的G99次列車車票,檢索條件是有發站或到站為“香港西九龍”的售票和退票記錄。這是一個典型的多站多時間點的通查要求,數據分布在全月12 000多個接口文件中,通過傳統手工查詢很難實現。
(2)并行高速信息查詢需求
在上述信息檢索工作的例子中,12000多個文件的檢索過程需要控制在合理的時間范圍內,具體來說,就是需要客票接口文件速查程序能夠發揮服務器主機多處理器、大內存、高速存儲的優勢,以并行執行的方式對不同的數據文件同時進行地檢索,從而最大程度地減少信息檢索所消耗的時間。
(3)接口文件格式可擴展性需求
隨著客運業務的不斷變化、客票售票系統的不斷升級,接口文件的格式也在不斷地改變。這就要求速查程序不能對接口文件的格式硬編碼,需要提供某種方案,讓程序能夠適應未來可能產生的改變。舉例來說,鐵路開展電子支付業務后,售票存根接口增加了電子支付相關的幾個數據字段,記錄相應信息,旅客乘意險業務上線后,接口格式中又加入了乘意險相關的幾個數據字段。自客票售票系統投入使用以來,售票接口存根已經從最初的50列左右逐步擴展為現在的74列,可以預見的是,這樣的改變今后仍然會不斷發生。
(4)SQL語言輸入智能感知需求
接口數據文件是具有一定的格式,可以按列進行區分顯示。速查程序最佳的設計方案是兼容結構化查詢語言SQL,采用數據表的方式,對數據文件進行檢索。兼容SQL語言查詢具有顯著的優勢,首先,查詢結果以列表顯示,十分直觀;其次,SQL具有豐富的函數庫,功能強大;最后,利用SQL的where子句可自由定義查詢條件,實現檢索條件的邏輯組合以及模糊查詢,非常靈活。
接口文件檢索程序兼容SQL語言的好處顯而易見,但仍需要解決一些細節問題。舉例來說,站售客票接口文件有74列,在寫SQL的where條件時,明確具體哪一列是什么數據類型,代表什么意思,就成了一個非常繁瑣的問題。程序需要實現編程IDE環境中類似Intellisese的功能,對用戶的輸入進行智能感知,給出用戶列名、含義相關提示,以方便用戶編寫SQL語句。
3 客票新系統接口文件速查程序設計方案
3.1 利用XML文件描述接口文件結構,滿足可擴展性要求
可擴展標記語言XML,是一種常用的描述性語言。速查程序利用XML語言,對接口文件的定義、文件中各列的定義進行了描述(如圖1)。接口定義XML文件中,一個File節描述了一個接口文件的類型、代碼、字段數量等基本屬性,其下擁有多個Column節,分別描述了不同列的名稱、數據類型等列的基本屬性。接口文件速查程序根據XML文件中的定義,“理解”各個接口文件及文件中的內容,并據此將文件檢索結果展示為數據表,以方便最終用戶檢索。

圖1 XML文件描述接口格式
3.2 利用SSH協議管理接口文件分布,滿足文件通查要求
歸檔服務器中不同時間段的接口文件按月創建文件夾歸檔存放,當月的文件在沒有歸檔前,存放在默認目錄中。在執行查詢之前,需要首先確認對應的數據文件是否存在,存放位置是否默認目錄,Oracle數據庫中對這一目錄是否已經創建了目錄對象,Oracle用戶對數據文件是否有讀權限。極端特殊的情況是,一些小站如果某些日期沒有發生客票售票業務,將不會生成對應的接口文件,在這樣的情況下,程序將通過SSH協議訪問歸檔服務器的操作系統,檢測到不存在的數據文件,并詢問執行者是否繼續進行檢索。
3.3 利用Oracle外部表及并行執行技術,滿足高速檢索要求
Oracle數據庫的外部表功能,可以借助數據庫引擎以表的方式訪問平面文件(文本文件),同時,利用外部表直接檢索歸檔服務器上的接口文件還避免了文件傳輸到本地計算機的過程,節省了大量的時間。Oracle支持以數據泵Data-Pump引擎或加載器Sqlldr引擎兩種方式定義外部表訪問平面文件。sqlldr引擎具有速度快的優勢,被選擇作為速查程序使用的解決方案。使用外部表檢索需要做一系列前期準備工作,速查程序負責自動將前期所有工作配置妥當,無需檢索用戶參與,以降低操作難度。
Oracle數據庫支持并行操作,具體來說是由一組parallel初始化參數控制了整個數據庫環境的并行操作執行的過程。速查程序使用Oracle系統的自動并行度,由數據庫根據操作系統資源使用的情況配置并行計算使用的資源,這是一個比較理想的選擇,可以減少由于客戶端“超配”產生的“過勞”排隊或其他等待。速查程序通過對用戶提交的SQL進行改寫,在語法中增加Parallel相關的提示,指導Oracle數據庫在查詢時采用并行方式執行,從而最大程度節省檢索時間,提高效率。
3.4 編寫SQL文法分析模塊,滿足SQL智能感知輸入需求
為了方便用戶SQL語句編寫的過程,速查程序開發了智能感知輸入提示功能,隨著用戶的鍵入過程,系統不斷跟蹤分析用戶的輸入,對用戶輸入的內容進行輔助列表提示(如圖2),智能匹配用戶的輸入。提示列表告知用戶字段名稱及其代表的含義、取值范圍等信息,用戶選中想要的條目,按Tab鍵直接補齊余下的字符,十分方便快捷。
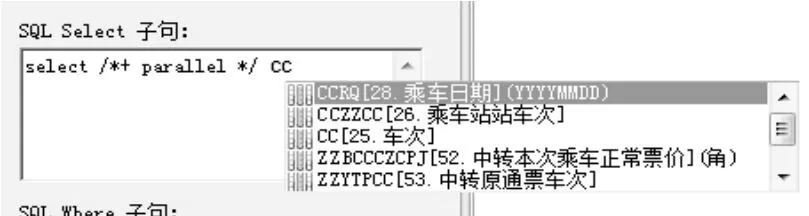
圖2 智能感知輸入提示
3.5 查詢過程執行流程
系統執行流程如圖3所示,用戶首先選擇所需查詢的車站列表,確認數據的類型和時間區間。在select文本框中編輯SQL的select子句,在where文本框中編輯選擇條件,點擊【查詢接口文件】按鈕。系統首先判斷對應的文件是否存在,文件所在目錄是否創建的目錄對象,然后為每個數據文件創建對應的外部表對象,最后對用戶輸入的SQL片段進行語法分析,改寫、組合成為最終的SQL語句,提交給Oracle服務器執行查詢,并取得最終的查詢結果。
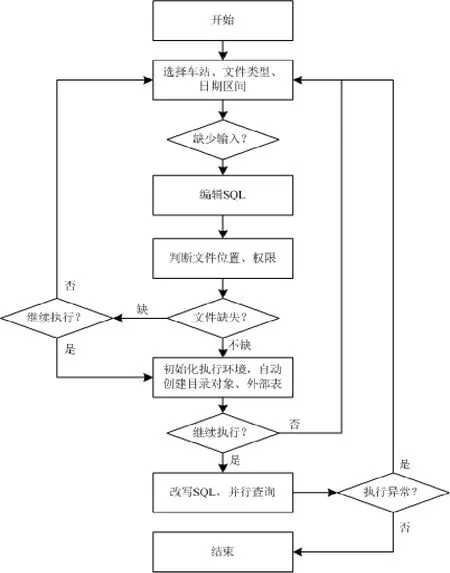
圖3 軟件執行流程
4 綜述
程序投入使用后,大幅度簡化了接口文件數據查詢的過程,有效提高了相關工作的效率和精度。經測算,對上海虹橋及上海站一旬20個客票存根接口文件進行遍歷搜索,查找所有發售的G99次列車車票存根,耗時約為2 min,時間經濟性顯著。
綜上,接口文件是應用系統之間數據交換的一種常用方式,利用SSH服務結合Oracle外部表、并行查詢、XML等技術設計的接口文件速查應用程序有著靈活的可擴展性和優異的性能表現,是解決類似問題優良的解決方案,希望本文的闡述可以為類似需求的應用程序設計提供有益的啟示。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
家庭影院技術(2017年9期)2017-09-26 03:41:45
環球時報(2017-03-30)2017-03-30 06:44:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
