上市公司信息披露的文字主觀敘述與盈余操縱
——基于機器學習法提取主觀模式的研究
2019-03-01 07:55:02毛怡欣
商業研究 2019年1期
關鍵詞:財務
毛怡欣
(廈門大學 管理學院,福建 廈門 361005)
內容提要:選取2006-2016年滬深A股上市公司樣本,研究上市公司是否會操縱文字信息披露,以更主觀的方式敘述來配合上市公司的盈余操縱行為。利用機器學習法提取2-POS主觀模式,構建了可量化的文字敘述的主觀性指標,通過實證檢驗發現,處于財務重述前,即在盈余操縱隱藏期間,上市公司年報中使用的主觀句比例更高、整體主觀性分數也更高;進一步的研究發現,良好的外部市場環境和內部治理環境會抑制上市公司利用主觀色彩更濃的信息敘述來配合其盈余操縱的行為。本文的研究既為上市公司操縱文字信息披露的動機提供了新的證據,補充了財務數據與文字信息披露關系的相關研究,也為監管部門加強信息披露監管以及外部信息使用者判斷信息質量提供了新的實證依據。
一、引言
公司年報中有大量的文字敘述,對財務狀況和其他重要的非財務狀況進行說明和解釋,這些文字敘述是非常重要的展示上市公司的方式(Li,2010)。雖然監管部門要求上市公司進行信息披露時必須保證其內容客觀真實,但是上市公司在進行相關事實的文字敘述時,敘事者是難以跳脫出自身的認知模式、完全不帶任何自身的態度和感情色彩的(沈家煊,2001),并且由于語言的復雜性,相關監管部門也難以制定出系統的、可量化的標準來對上市公司的相關文字敘述進行統一的規范。因此,上市公司年報的文字敘述很難達到完全客觀、不帶任何上市公司自身的立場和感情色彩(Baginski等,2016)。盡管上市公司在年報的文字敘述難以擺脫主觀性印記,主觀性在各上市公司年報中普遍存在,但是各公司年報主觀性程度是不同的。有的上市公司在敘事時盡量的還原事實,使文字敘述成為向外部人員傳遞信息的重要渠道,從而使外部投資者掌握更多有效信息做出更準確的決策;但是有的上市公司會利用更主觀的敘述來模糊或轉移焦點,故意夸大對上市公司有利的事實以及故意削弱對上市公司不利的事實,誤導外部信息使用者。上市公司的財務數據與文字信息是相輔相成的,上市公司披露的相關財務數據需要利用文字進行進一步說明和解釋,管理狀況、發展前景等其他重要的非財務狀況的文字敘述又是財務信息的重要支撐,所以,文字信息和財務數據不是相互獨立的(Loughran和Mcdonald,2016)。那么上市公司若進行了盈余操縱,就會有強烈的動機操縱文字敘述,對相關事實進行更主觀的敘述,運用詞匯和句法等方式削弱某些事實的真實性,以此來配合盈余操縱,以避免相關操縱行為被外部信息使用者發現。因此,構建一套可量化的指標衡量上市公司年報文字的主觀程度,對上市公司信息披露進行實證檢驗是有必要的。本文通過機器學習法對年報語料進行訓練提取2-POS主觀模式對年報文字敘述的主觀性特征進行度量后,對上市公司文字敘述是否配合盈余操縱進行的實證檢驗。
二、文獻回顧和研究假設
(一)文本挖掘方法的使用及研究
近年來,隨著機器學習、自然語言處理技術的發展,文本挖掘方法越來越多地被應用到對上市公司會計文本的定量分析中。其中關于對文本主觀性的研究起始于對英文語料的研究,早期的研究認為形容詞的使用是判斷主觀性的重要特征,因此利用標識形容詞來計算文本的主觀性(Hatzivassiloglou和Wiebe,2000),這也激發了學者對其他詞性與主觀性關系的研究。Riloff等(2003)發現名詞也與語句的主觀性存在很強的相關性,通過Bootstraping算法得出1052個主觀性的名詞,然后將這些主觀性名詞作為判斷語句主觀性的特征。隨后,有學者在前人的基礎上又突破了僅以單個的詞語作為標識語句主觀性的依據,葉強等(2007)基于中文的語料提出了利用連續雙詞詞類模式(2-POS模式)作為判斷語句主觀性的依據。目前國內已經有較多學者將2-POS模式進一步應用到對中文的主觀性判斷中,并且驗證了利用2-POS模式判斷中文主觀性的可行性。張文文和王挺(2013)在比較了6種不同的主客觀分類方法后,發現基于2-POS模式的方法效果是最好的。雖然大多關于文本主觀性研究的語料是基于互聯網的評論、微博和新聞等,這些語料與上市公司披露的會計文本的語料有一定的差異。但段釗等(2017)也將2-POS模式應用到上市公司的社會責任報告的文本分析中,發現利用2-POS主觀模式對主觀句的查全率和查準率可以達到90%以上,這表明了利用2-POS模式對上市公司披露的會計文本進行主觀性分析是可行的。
(二)文字主觀性與盈余操縱
許多研究顯示上市公司對文字信息披露進行的策略性管理更多的是為了轉移外部信息使用人員對不利消息的關注或模糊上市公司的不利消息,即出于信息模糊動機而進行文字信息披露的操縱。例如,Bonsall等(2013)發現當上市公司面臨的不確定越高,就會披露更多與盈余無關的前瞻性信息;Merkley(2014)也發現當上市公司的業績較差時會披露更多關于研發的信息,并且當公司績效較差時,上市公司年報的可讀性也會越差。上市公司年報中的財務數據和文字信息之間并不是相互獨立的,財務數據由準確的數字構成可以提供更為客觀的公司狀況,年報中的文字敘述可以反映結構化的財務數據無法反映的更多細節信息,例如財務數據相關的會計準則和管理者動機,外部信息使用者在了解了相關會計準則后,可以更準確地理解財務數據的含義,上市公司對外公告的財務數據與文字敘述之間是相互聯系和相互印證的。相關的研究也顯示了上市公司的會計文本信息對財務數據起到補充作用而不是替代作用,例如Bochkay和Levine(2013)發現結合財務數據和管理層討論與分析的文本信息才可以做出更準確的盈余預測,上市公司的文本信息也會影響財務數據與市場反應之間的關系。因此,為了隱藏上市公司的盈余操縱行為,上市公司就會有強烈的動機采取對文字信息也進行操縱的手段,提供更模糊的相關事實的信息以避免相關盈余操縱行為被外部人員發現。雖然利用文字對相關事實進行敘述時難以避免敘述者所帶的立場和感情從而難以達到絕對客觀(沈家煊,2001),上市公司年報中的文字敘述可能普遍存在著一定程度上的主觀性,但是各上市公司的文字敘述所帶的主觀色彩程度并不是完全一致的,其中也大量存在有主觀目的性的。
對前期財務報告中的財務數據進行更正的財務報告重述(即“財務重述”)行為經常性地在一定程度上隱藏了上市公司的盈余操縱行為(Richardson等,2002;Lev,2003;周曉蘇和周琦,2011)。通過以我國上市公司為研究樣本的實證檢驗發現,我國上市公司財務重述泛濫的主要原因就在于上市公司為了掩蓋其不良經營狀況進行的盈余操縱(于鵬,2007);上市公司及其管理層盈余操縱行為一旦實施,財務重述就會隨即發生 (Lo等,2017)。魏志華等(2009)通過梳理我國上市公司年報重述情況后也認為監管部門需要重點關注上市公司的財務重述中可能存在的盈余操縱。許多學者也在實證研究中把財務重述作為上市公司進行盈余操縱的表征,例如,程新生等(2015)利用財務重述作為上市公司盈余操縱的表征,實證檢驗盈余操縱與MD&A中的非財務信息披露之間的配合;張璇等(2016)也把財務重述作為上市公司盈余質量的代理變量。因此,本文選擇在財務信息披露以后進行過財務重述,但該年報還未被重述,公司進行了盈余操縱但還處于隱藏期間的年報作為樣本,來研究上市公司是否會在該財務報告中以更主觀的文字敘述來配合其盈余操縱行為。若上市公司的年報處于財務重述前的狀態,這時上市公司處于盈余操縱隱藏期間,上市公司是具有為了隱藏和配合其盈余操縱行為,策略性披露更主觀的文字敘述的動機的。因此,本文提出了以下假設。
假設1:相較于其他沒有進行過財務重述的上市公司,進行過財務重述的上市公司在財務重述公告前,即在隱藏期間,其尚未被更正的年報中會使用更多的主觀句式。
假設2:相較于其他沒有進行過財務重述的上市公司,進行過財務重述的上市公司在財務重述公告前,即在隱藏期間,其尚未被更正的年報文字部分的整體主觀性更高。
三、研究設計
(一)樣本選擇和數據來源
本文選取2006-2016年滬深兩市的A股上市公司作為研究樣本,剔除了金融行業樣本、上市時間不超過兩年的樣本以及相關變量缺失的樣本后,一共得到了11715個樣本數據,其中在年報披露后進行過財務重述但當前處于還未被重述的狀態的年報樣本共有655個。由于在進行進一步分析時涉及了不同變量,導致變量缺失情況不同,因此樣本數略有不同。上市公司的年報數據來自于Wind數據庫,財務重述公告數據來自于國泰安數據庫,內部控制指數數據來自于迪博數據庫,其他相關變量數據來自于銳思數據庫。為了消除極端異常值的影響,本文對所有連續變量都進行了1%和99%水平下的Winsorize縮尾處理。本文的行業分類標準為證監會門類行業。
(二)變量度量
1.被解釋變量。本文的被解釋變量為主觀句占比(Sub_1)和主觀性分數(Sub_2)。本文采用2-POS模式(將句子按照詞性進行分詞,2個連續詞的順序組合就構成1個2-POS模式)來對語句主觀性進行度量。提取2-POS主觀模式以及計算主觀句占比(Sub_1)、主觀性分數(Sub_2)這兩個變量的具體步驟如下所示:
第一步,在上市公司年報中的文本中隨機抽取2000個句子,請3位志愿者分別對這2000個句子屬于主觀句還是客觀句進行標注,若有兩位志愿者以上將語句標注為主觀句,那么將該句劃分為主觀句,否則劃分為客觀句,一共得到744句主觀句和1256句客觀句,再隨機抽取500句主觀句和500句客觀句,構建訓練年報語料的樣本。
第二步,利用LTP(Language Technology Platform)分詞系統對訓練樣本進行分詞和詞性的標注,將所有主觀句和客觀句中的按順序組合的連續雙詞模式(2-POS模式)提取出來,計算所有主觀句中的2-POS模式的χ2值并排序,選取前20個2-POS模式作為2-POS主觀模式。χ2值的計算公式如下:
(1)
其中,N表示主觀句和客觀句總數,A表示主觀句中包含該2-POS模式的句數,B表示客觀句中包含該2-POS模式的句數,C表示主觀句中不包含該2-POS模式的句數,D表示客觀句中不包含該2-POS模式的句數。
第三步,計算前20個2-POS主觀模式的查準率和查全率,即按照利用該2-POS模式判斷出的主觀句的準確率和比例作為該2-POS模式的查準率和查全率,具體計算公式為:

(2)

(3)
將2-POS主觀模式的查準率作為主觀性分數的權重。表1報告了提取的20個2-POS主觀模式的查準率和查全率。

表1 2-POS主觀模式
第四步,利用LTP(Language Technology Platform)分詞系統將所有樣本的年報進行分詞和詞性標注后,提取每一份年報中每句話中包含的2-POS模式,然后標識年報中包含的2-POS主觀模式,再加總每句話中各自包含的2-POS主觀模式與其主觀權重乘積。當按主觀和客觀進行分類設置閾值時,發現將閾值設置為0時,主客觀分類的查準率和查全率都達到90%以上,因此本文將判斷主客觀句的閾值設置為0,即加總該句話中包含的2-POS主觀模式與其主觀權重乘積大于0,那么將該句分類為主觀句,否則將該句分類為客觀句。因此可計算出年報中的主觀句占比(Sub_1)和主觀性分數(Sub_2),Sub_1和Sub_2的具體計算公式分別如下所示:
(4)
(5)
公式(4)中的sub_count表示年報中包含的主觀句數,ob_count表示年報中包含的客觀句數;公式(5)中的ni表示年報中包含的第i個2-POS主觀模式的頻數,weihgti表示第i個2-POS主觀模式的主觀權重,2-POS_count表示包含的所有2-POS模式個數。
2.解釋變量。本文的解釋變量為財務重述前(Restate_pre),若上市公司在披露年報之后對該年報進行了財務重述,那么在該年報還未進行財務重述之時,變量取值為1,否則取值為0。在經過處理后,一共得到了655個財務重述前的樣本。
3.控制變量。本文選取了公司規模(Size)、資產負債率(Lev)、總資產報酬率(ROA)、公司成長性(Growth)、分析師關注度(Follow)、機構持股比(Ins)、董事會規模(BDS)、獨董比例(Indep)、是否國有控股(State)這些對上市公司信息披露可能會有顯著影響的因素作為控制變量。除此以外,為了控制上市公司年報披露在不同年份和不同行業之間的差異,還控制了行業虛擬變量(Industry)和年份虛擬變量(Year)。表2報告了本文涉及的主要變量的定義和計算方法。

表2 變量定義以及計算方法
(三)模型設定
為了檢驗假設1和假設2,構建了如下回歸模型:
Sub_1i,t=α0+β1Restate_prei,t+β2Sizei,t+β3Levi,t+β4ROAi,t+β5Growthi,t+β6Followi,t+β7Insi,t+β8BDSi,t+β9Indepi,t+β10Statei,t+∑Industry+∑Year+εi,t
(I)
Sub_2=α0+β1Restate_prei,t+β2Sizei,t+β3Levi,t+β4ROAi,t+β5Growthi,t+β6Followi,t+β7Insi,t+β8BDSi,t+β9Indepi,t+β10Statei,t+∑Industry+∑Year+εi,t
(II)
分別以Sub_1和Sub_2作為回歸模型(I)和回歸模型(II)的被解釋變量;回歸模型(I)和回歸模型(II)的被解釋變量為Restate_pre,控制變量為Size、Lev、ROA、Growth、Follow、Ins、BDS、Indep、State;采用行業和年份固定效應模型;回歸模型中各變量的具體定義和計算方法如表2所示。若回歸模型(I)和回歸模型(II)中解釋變量Restate_pre的回歸系數β1顯著為正,那么假設1和假設2成立。為了解決內生性問題以及進行穩健性檢驗,本文進一步采用傾向性評分匹配(PSM)方法為處于財務重述前的樣本進行1:1匹配選取控制組樣本,利用匹配后的樣本再次對回歸模型(I)和回歸模型(II)進行回歸,以及構建雙重差分模型進行檢驗,除此以外還采用修正Jones模型計算上市公司的盈余管理作為盈余操縱代理變量重新進行回歸。
四、實證結果分析
(一)主要變量描述性統計和相關性分析
表3報告了本文涉及的主要變量的描述性統計結果。其中:上市公司年報中的主觀句占比的平均值為0.3444,表示年報中的語句中平均有大約34%比例的為主觀句;年報的整體得分平均為0.1157,而主觀性分數最低為0.088,最高得分為0.1831。從主觀句占比和主觀性分數的描述性統計結果來看,最小值都大于0并且都沒有趨近于0,這表明上市公司在年報中的文字敘述中普遍都帶有主觀性色彩,但是不同上市公司的年報主觀性程度是有差異的;財務重述前的平均值為0.0559,這表示約有5.6%的上市公司年報處于盈余操縱隱藏期間。根據是否國有的平均值來看,樣本中國有控股公司的比例接近30%。其他公司特征在不同上市公司之間也存在著一定的差異,資產負債率、總資產報酬率、公司成長性、分析師關注都有較大的差異;資產負債率最小值僅有4.78%,而最大值達到了107.44%;總資產報酬率最低為-7.87%,最高為19.85%;公司成長性最小值為-0.616,而成長性最高的公司的營業總收入增長近2倍;有的上市公司沒有分析師關注,而有的上市公司多達36位分析師對其進行跟蹤;上市公司最低機構持股比例為0,最高機構持股比例達84.25%。
表4報告了本文涉及的主要變量之間的Pearson相關系數。其中:年報的主觀句比例與主觀性分數之間的相關系數為0.7407,在1%水平下顯著,主觀句比例和主觀性分數有較強的正相關關系;財務重述前與主觀句比例、主觀性分數的相關系數分別為0.0905和0.0836,并且在1%水平下顯著,解釋變量與被解釋變量之間都有顯著的正相關關系。支持假設1和假設2。解釋變量與其他控制變量之間的相關系數都不超過0.3,雖然在控制變量中,公司規模與分析師關注度、公司規模與機構持股比、分析師關注度與機構持股比、董事會規模與獨董比例的相關系數超過了0.3,但在進行回歸檢驗時進行了多重共線性檢驗,方差膨脹因子(vif值)都小于5,因此,本文的回歸模型不存在多重共線性問題。
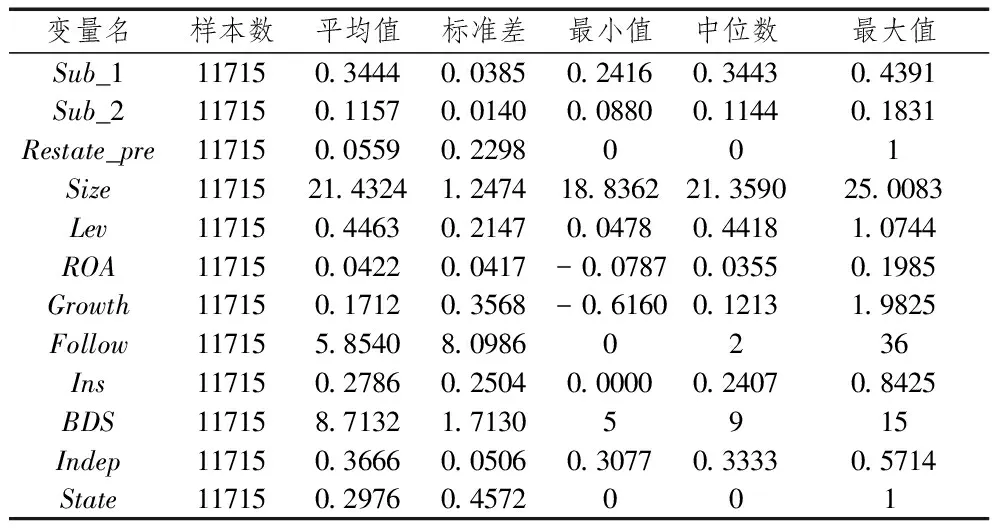
表3 主要變量描述性統計結果

表4 主要變量Pearson相關系數
注:*表示在10%水平下顯著,**表示在5%水平下顯著,***表示在 1%水平下顯著(下同)。

表5 主要變量是否處于財務重述前的差異
本文進一步以上市公司年報是否處于財務重述前為劃分標準將樣本劃分為兩組子樣本進行了描述性統計,表5報告了兩組子樣本主要變量的樣本數和平均值、兩組子樣本主要變量之間的均值差以及對兩組子樣本主要變量之間的平均值是否有顯著差異進行的t檢驗結果。根據表5報告的數據,除了分析師關注度以外,其他主要變量的平均值在兩組樣本之間都有顯著的差異。其中,沒有處于財務重述前的年報的主觀句比例平均為34.36%,處于財務重述前的年報的主觀句比例平均為35.87%,經過t檢驗,沒有處于財務重述前的年報的主觀句比例顯著低于處于財務重述前的年報。沒有處于財務重述前的年報的主觀性分數平均為0.1154,而處于財務重述前的年報的主觀性分數平均為0.1205,根據t檢驗結果,沒有處于財務重述前的年報的主觀性分數也顯著低于處于財務重述前的年報。從分組描述性統計結果來看,處于財務重述前的年報的文字敘述的主觀性程度更高。

表6 財務重述前與年報主觀句比例、主觀性分數
(二)財務重述前與年報主觀性
表6報告了回歸模型(I)和回歸模型(II)的回歸結果。其中:第2列報告了以年報主觀句比例(Sub_1)作為被解釋變量的回歸結果,控制了相關影響因素后,解釋變量財務重述前(Restate_pre)的回歸系數為0.0059,在1%水平下顯著,財務重述前與主觀句占比顯著正相關;第3列報告了以年報主觀性分數(Sub_2)為被解釋變量的回歸結果,加入控制變量后,解釋變量財務重述前(Restate_pre)的回歸系數為0.0014,也在1%的水平下顯著,財務重述前與主觀性分數顯著正相關;回歸結果表明處于財務重述前狀態的年報中使用的主觀句的比例更高、年報的整體主觀性分數也更高,上市公司在盈余操縱隱藏期間,會使用更主觀的文字敘述配合其盈余操縱行為,與本文提出的假設1和假設2的預期是一致的。
(三)上市公司外部市場環境的影響
不同地區的上市公司所面臨的外部市場化環境是不同的。在市場化程度較高的地區,上市公司面臨更為有效的外部治理機制,上市公司與外部人員之間的信息傳遞效率可能會更高,這可能會使上市公司操縱年報文字信息披露隱藏盈余操縱行為的動機減弱,因此上市公司面臨的外部市場環境可能會影響上市公司年報中的主觀文字敘述與盈余操縱之間的關系。為了進一步檢驗上市公司所處的外部市場環境是否影響盈余操縱對主觀文字敘述的影響,本文根據王小魯等(2016)編制的中國分省份市場化指數,將樣本劃分為市場化程度較低(MKT-L)和市場化程度較高(MKT-H)兩組,進行分組回歸檢驗。計算各地區的市場化指數中位數,上市公司所在地區的市場化程度低于中位數,那么將其劃分為市場化程度較低組,反之則將樣本劃分為市場化程度較高組。除了利用王小魯等(2016)編制的市場化指數進行分組以外,東部和中西部地區之間的市場化發展程度有顯著差異,因此本文還將樣本以上市公司所在省份屬于東部還是中西部劃分為東部和中西部兩組,進行分組回歸檢驗。
表7報告了外部市場環境影響的檢驗結果,其中,第2列至第5列報告了市場化程度較高組和市場化程度較低組的分組回歸結果,第6列至第9列報告了東部組和中西部組的分組回歸結果。從第2列和第4列的回歸結果來看,在市場化程度較高的情況下,是否處于財務重述前(Restate_pre)對主觀句比例(Sub_1)和主觀性分數(Sub_2)沒有顯著的影響;而第3列和第5列的回歸結果顯示在市場化程度較低的情況下,財務重述前(Restate_pre)對主觀句比例(Sub_1)和主觀性分數(Sub_2)的影響顯著為正。第6列和第8列顯示,在東部地區,財務重述前(Restate_pre)對年報中的主觀句比例(Sub_1)和年報的主觀性分數(Sub_2)沒有顯著的影響;而第7列和第9列的回歸結果顯示,在中西部地區,財務重述前(Restate_pre)與主觀句比例(Sub_1)、年報的主觀性分數(Sub_2)都是在1%水平下顯著正相關。綜合表7的分組回歸結果,上市公司的外部市場環境發展程度越好,上市公司操縱年報文字敘述以掩蓋盈余操縱的動機就會減弱,高程度的市場化環境可以抑制上市公司在年報中采用較多的主觀敘述進行策略性的披露;而上市公司在面臨較差的市場化環境時,更容易利用主觀敘述配合其盈余操縱,在外部市場化程度發展較低時,盈余操縱與主觀敘述之間的關系更為顯著。
(四)上市公司內部治理環境的影響
除了外部市場環境會影響上市公司的信息披露行為以外,前人的研究也顯示了公司內部的治理環境也會影響上市公司信息披露行為(李慧云等,2013)。若上市公司內部治理環境良好,可能會約束管理層對信息披露的操縱,因此內部治理環境更好的上市公司利用主觀性敘述掩蓋盈余操縱的可能性會降低。本文選取了是否兩職合一、董事會規模、獨董比例、監事會規模、前十大股東持股比例、機構持股比例這些公司治理指標,利用主成分分析法構建了上市公司的公司治理指數,將公司治理指數高于中位數的上市公司劃分為公司治理環境較好的一組(GI_H),低于中位數的上市公司劃分為公司治理環境較差的一組(GI_L),分別對兩組樣本進行回歸檢驗。本文還利用了迪博數據庫的內部控制指數將上市公司劃分為內部控制環境較好(IC_H)和內部控制環境較差(IC_L)兩組樣本,內部控制指數高于中位數則劃分為內部控制環境較好一組,低于中位數,則劃分為內部控制環境較差一組,然后也對兩組樣本進行分組回歸檢驗。
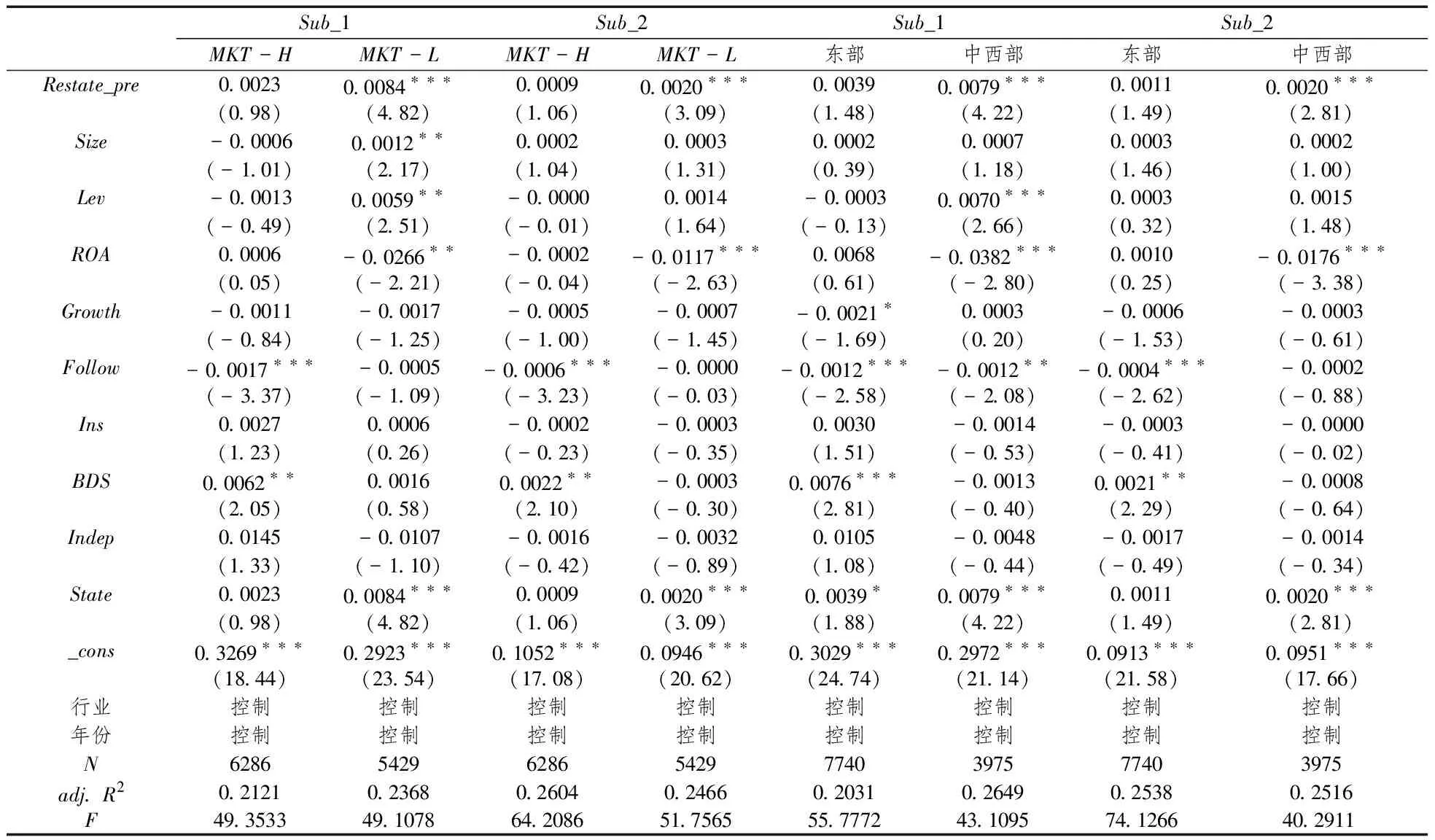
表7 外部市場環境影響

表8 內部治理環境的影響
表8報告了上市公司內部治理環境對年報主觀敘述的影響。其中:第2列至第5列報告了以公司治理指數分組的回歸結果,回歸結果顯示只有在公司治理環境較差的情況下(GI_L),財務重述前(Restate_pre)的回歸系數顯著為正,在公司治理環境較好的情況下(GI-H),財務重述前(Restate_pre)的回歸系數并不顯著。第6列至第9列中報告了以內部控制指數分組的回歸結果,只有在內部控制環境較差的情況下(IC_L),財務重述前(Restate_pre)的回歸系數顯著為正,當上市公司的內部控制較好時,財務重述前(Restate_pre)對年報的主觀句比例(Sub_1)和主觀性分數(Sub_2)沒有顯著影響。因此根據表8報告的分組回歸結果,上市公司良好的內部治理環境會抑制操縱文字信息披露配合盈余操縱的行為,而較差的內部治理環境會使上市公司操縱文字敘述,以帶有更多主觀色彩的描述與盈余操縱相配合。

表9 PSM匹配樣本和DID模型回歸結果
(五)穩健性檢驗
1.傾向性評分匹配(PSM)。在前文的回歸檢驗中,采用了整體混合樣本進行檢驗,本文在穩健性檢驗中進一步采用傾向性評分匹配方法進行1:1匹配,為發生過財務重述的上市公司在沒有發生過財務重述的上市公司中尋找配對樣本,以配對后得到的實驗組和控制組的樣本重新對回歸模型(I)和回歸模型(II)進行回歸。首先將進行過財務重述的上市公司的公司年標記為實驗組(treat=1),沒有發生過財務重述的上市公司的公司年標記為控制組(treat=0);選取的匹配變量為:行業(Industry)、上市年份(Age)、公司規模(Size)、資產負債率(Lev)、總資產報酬率(ROA)和營業總收入增長率(Growth),然后進行Logit回歸;根據傾向性評分對每一個財務重述前的樣本進行最近鄰一對一匹配,最終得到632組(1264個)配對樣本。表9中的第2列和第3列報告了PSM匹配樣本的回歸結果,財務重述前(Restate_pre)的回歸系數仍然顯著為正,利用PSM方法得到匹配樣本進行的穩健性檢驗得到的回歸結果與前文的回歸結果是一致的,仍然支持本文提出的假設1和假設2,上市公司會在年報中采用更主觀的敘述配合盈余操縱行為。
2.雙重差分模型。本文進一步設計了雙重差分模型(DID)對內生性問題進行檢驗,雙重差分模型如下所示:
Sub_1i,t=α0+β1Resi,t+β2Prei,t+β3Resi,t×Prei,t+β4Sizei,t+β5Levi,t+β6ROAi,t+β7Growthi,t+β8Followi,t+β9Insi,t+β10BDSi,t+β11Indepi,t+β12Statei,t+∑Industry+∑Year+εi,t
(III)
Sub_2=α0+β1Resi,t+β2Prei,t+β3Resi,t×Prei,t+β4Sizei,t+β5Levi,t+β6ROAi,t+β7Growthi,t+β8Followi,t+β9Insi,t+β10BDSi,t+β11Indepi,t+β12Statei,t+∑Industry+∑Year+εi,t
(IV)
在回歸模型(III)和回歸模型(IV)中,Res定義為是否發生過財務重述的虛擬變量,若上市公司發生過財務重述,那么取值為1,否則取值為0。Pre定義為財務重述隱藏期間的虛擬變量(隱藏期可能大于一年),在上市公司還未發布財務重述公告,取值1,發布了財務重述公告后,取值0;若是PSM配對樣本,若處于其配對樣本還未進行財務重述公告前的期間,Pre取值1;若處于其配對樣本進行財務重述公告后的期間,Pre則取值0。回歸模型(III)和回歸模型(IV)中的Res和Pre的交乘項的回歸系數β3是本文關注的雙重差分的估計量,表示盈余操縱對主觀句比例和主觀性分數的凈影響。表9的第5列和第6列報告了DID模型的回歸結果,根據表中報告的數據,交乘項的回歸系數都顯著為正,這表明相較于沒有進行過財務重述的上市公司,進行過財務重述的上市公司在進行財務重述公告前披露的年報的主觀句比例更高、主觀性分數也更高,這與前文的結論也是一致的。
3.其他穩健性檢驗。本文還選取了盈余管理(|DA|)作為盈余操縱的代理變量再次進行回歸檢驗,本文采用修正Jones模型計算上市公司的盈余管理,首先估計回歸模型:
TAi,t/Ai,t-1=α1*1/Ai,t-1+α2*(ΔREVi,t-ΔRECi,t)/Ai,t-1+α3*PPEi,t/Ai,t-1+εi,t
(Ⅴ)
其中,TAi,t為第t年凈利潤與經營活動凈現金流之差,Ai,t-1為第t-1年年末的資產總額,ΔREVi,t為第t年與第t-1年營業收入之差,ΔRECi,t為第t年與第t-1年應收賬款之差,PPEi,t為第t年年末固定資產。將模型(Ⅴ)分別按行業和年份進行回歸,回歸模型的殘差就是上市公司的盈余管理DAi,t。由于本文不考慮盈余管理方向,因此采用絕對值|DAi,t|作為盈余管理指標。表10中的第2列和第3列報告了以|DA|為解釋變量的回歸結果,從回歸系數來看,|DA|的回歸系數都顯著為正。除此以外本文還構建了高盈余管理(|DA|_H)虛擬變量,若上市公司的盈余管理高于中位數,|DA|_H取值1,否則取值0,表9中的第4列和第5列報告了以|DA|_H作為解釋變量的回歸結果,結果顯示高盈余管理與主觀句比例和主觀性分數顯著正相關。選取上市公司的盈余管理作為代理變量進行穩健性檢驗結果仍然顯示上市公司會利用主觀性敘述配合上市公司的盈余操縱行為。
五、結論與啟示
本文利用機器學習方法對上市公司年報語料進行訓練,通過提取2-POS主觀模式,構建了度量年報文字敘述主觀程度的指標,即年報的主觀句比例(Sub_1)和整體主觀性分數(Sub_2)。對上市公司年報的主觀性指標進行分組描述性統計后,發現處于進行財務重述前狀態的上市公司年報的主觀句比例、主觀性分數都顯著高于不處于財務重述前的上市公司年報。通過回歸檢驗發現,年報中的主觀句比例、主觀性分數與年報處于財務重述前的狀態是顯著正相關的。經過進一步的分組回歸檢驗發現,在較差的外部市場環境和內部治理環境下,主觀句比例、主觀性分數與年報處于財務重述前的狀態顯著正相關;而在較好的外部市場環境和內部治理環境下,主觀句比例、主觀性分數與年報是否處于財務重述前之間并不顯著相關。本文的實證結果顯示,我國上市公司進行盈余操縱的同時,會采取主觀的文字敘述策略模糊其盈余操縱行為,但是外部的高市場化環境和內部的良好治理環境會抑制上市公司利用主觀文字敘述隱藏盈余操縱行為的問題。
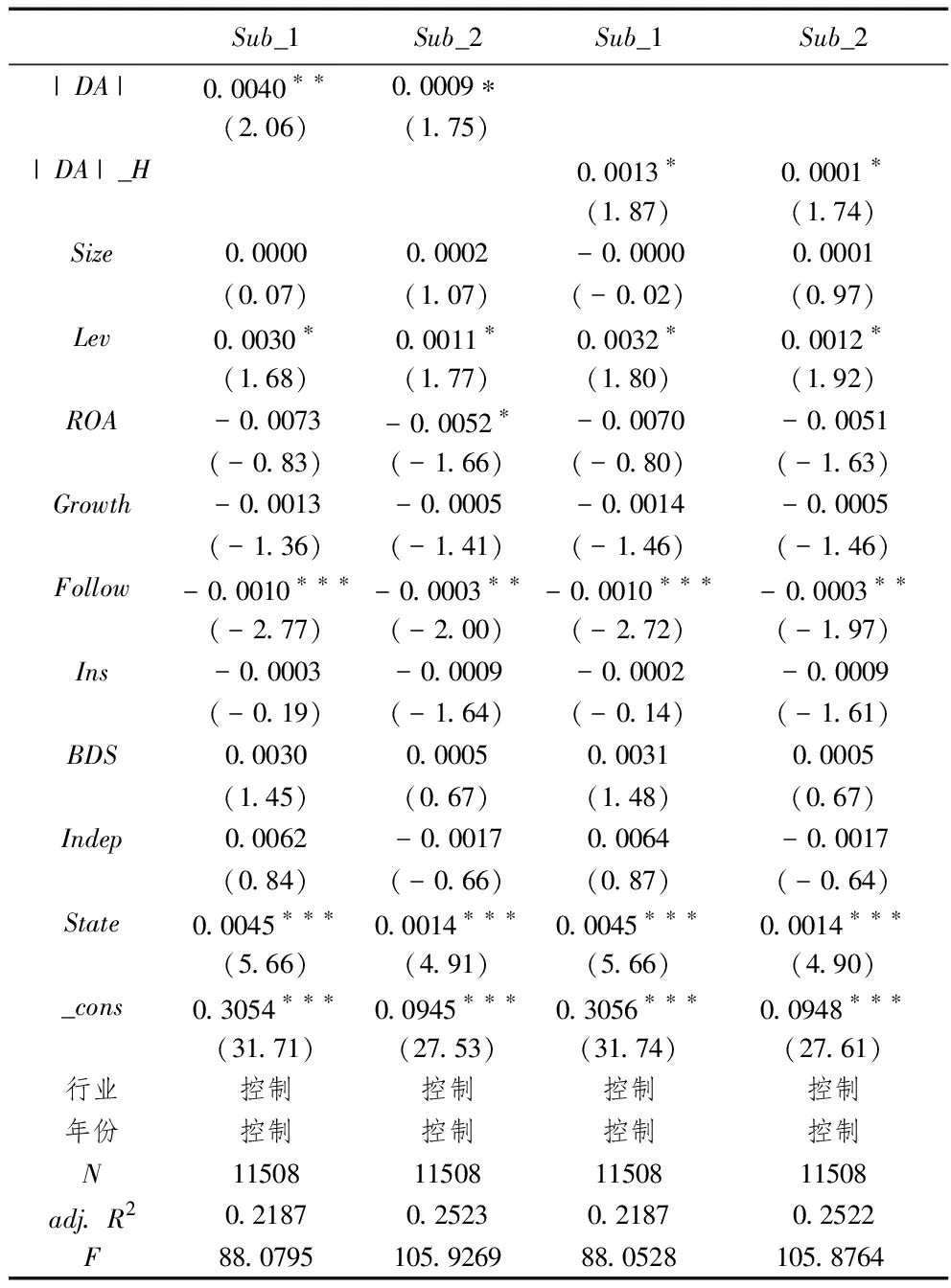
表10 盈余管理與年報主觀句比例、主觀性分數
針對我國上市公司披露的主觀敘述問題,由于中文語言的復雜性以及監管部門目前對上市公司文字信息披露的監管力度仍然較弱,為上市公司對文字信息披露進行操縱提供了可乘之機。我國監管部門應該加強對上市公司文字信息披露的監管力度,進一步規范上市公司會計文本的用語。美國證監會(SEC)在1998年制定了“Plain English”的規則,并且發布了指導上市公司如何使用簡潔和規范用語的相關手冊,我國監管部門也可以借鑒國外相關成功經驗制定相關會計文本披露規范對我國上市公司的文字信息披露問題進行監管。對于外部信息使用者而言,應該注意上市公司文字敘述所帶的主觀色彩,當文字敘述的主觀色彩較濃時,應該仔細辨別相關文字信息的質量,考慮上市公司是否具有信息披露的操縱行為,以避免被低質量的信息誤導,從而做出錯誤的決策。
猜你喜歡
江西理工大學學報(2022年2期)2022-07-26 07:05:36
活力(2021年6期)2021-08-05 07:24:28
現代企業(2021年2期)2021-07-20 07:57:18
現代經濟信息(2020年34期)2020-06-08 06:02:40
現代經濟信息(2020年34期)2020-06-08 06:02:40
現代經濟信息(2020年34期)2020-06-08 06:02:36
意林·全彩Color(2019年9期)2019-10-17 02:25:48
活力(2019年15期)2019-09-25 07:21:32
智富時代(2019年2期)2019-04-18 07:44:42
河南水利年鑒(2017年0期)2017-05-19 02:29:27
