基于隨機森林的藏文文本分類
2019-03-04 11:05:01包晗西熱旦增郭龍銀尚慧杰
電腦知識與技術 2019年34期
包晗 西熱旦增 郭龍銀 尚慧杰


摘要:針對藏文文本及其語法和詞法結構,采用條件隨機場進行分詞,利用人工統計和標注進行停用詞詞典建立,然后采用tf-idf的詞向量空間,予以權重計算,最后采用隨機森林算法構建分類器,進行文本分類。并使用查全率、查準率和F1值三種評價函數與邏輯回歸、多項式樸素貝葉斯、支持向量機三種算法相比,結果顯示,隨機森林算法在高維特征的藏文文本分類上優于其他分類器。
關鍵詞:藏文;條件隨機場;TF-IDF;隨機森林;文本分類
中圖分類號:TP391
文獻標識碼:A
文章編號:1009-3044(2019)34-0178-03
隨著藏語言在互聯網的傳播,藏語語言信息數據及資源呈現海量特征,而研究藏文文本分類可有效管理和利用這些海量信息。其中,文本分類(textcategorization,簡稱TC)技術是信息檢索和文本挖掘的重要基礎,其中主要任務時在預先給定的類別標記(label)集合下,根據文本內容判定它的類別1。藏文文本分類目前還處于統計學習和深度學習的過渡階段,尤其是在藏文文本數據語料不龐大和標注程度深度不夠的前提下,隨機森林(Random Forest)算法能夠處理高維特征的輸入樣本,且不需要降維處理。
1 藏文文本分詞
藏文自動分詞可以看作是計算機自動辨識藏文文本字符流中的詞,并在詞與詞之間加入明顯的詞切分標記符的過程2目前,已有多種分類方法,例如:最大匹配算法3、基于格助詞和接續特征的書面藏語自動分詞-等,在比較多種分詞方法后,確定以洛桑嘎登的基于知識融合的條件隨機場s進行藏文分詞。
x為音節,ξ為閾值,第一種為黏著詞、歧義詞等音節組合規則庫建立,第二種為人名、地名、非藏文字符等固定音節規則庫。最后統計和人工篩選出最終的庫的元素,將閾值極高的元素在分詞之間先行篩除,其余元素在分詞中將閾值與條件隨機場輸出比較。
2 tf-idf特征提取
2.1 文本向量空間模型
向量空間模型(VSM)6由哈佛大學的G Salton提出,是基于統計的代數模型。文本向量空間模型(TVSM)則是擬定一個向量空間概念,將文本中的每一個詞轉換為空間的不同維度,文本的表達與向量之和相似,形成一個在高維度上的帶方向的點,而一個詞的權重即是該點在對應維度上的絕對值。一個文本的表達式為:
在文本向量空間模型中,單個文本的維度一般在百維至千維以上,高緯度的文本所包含的內容更為豐富,詞與詞之間的聯系也更為緊密,允許文本分類的種類更為多且層次更深。
2.2 tf-idf特征提取
Trf-idf(Term-frequency times inverse document-frequenry)詞頻乘以逆文本頻率,公式:
tf(t,d)為詞頻函數,表示某個藏文詞在一個文本中出現的次數,他和文本越相關,則在文本中出現的次數越多。但在大型語料庫中,一些許多特定的詞出現的頻率極高,例如藏語中的連接詞等,他們不具有分類特征,會影響分類器的判斷,我們應當在構建詞頻矩陣前排除。
idf(t)為逆文本頻率函數,表示某個藏文詞在某文本類別的影響頻率,即該詞在某個類別出現的頻率越高而在其他類別出現的頻率越低,則該詞對某類別的分類影響程度越高,公式6:
其中n是語料集中所有文本數,d (t)是語料集中擁有t維度的所有文本數。
Ridge回歸,使用Frobenius范數,將單文本中所有的tf-idf值進行回歸,最終將所有文本轉換為多維浮點數矩陣,公式為:
3 隨機森林分類器
3.1 決策樹
決策樹是將文本中的詞作為節點,計算該詞加上所有父節點構成的詞序列對某一類別的分類誤差率,設立閾值,根據閾值判別產生不同的子節點,循環此過程,直到閾值為0或無子序列。決策樹主要分三個步驟:特征選擇、決策樹生成、剪枝。
特征選擇,本文采用CART算法來進行特征選擇,CART(Classification And Regression Tree)。是Breiman等人在1984年提出的,是一種二分決策樹,它判別規則是要么為某一類,要么就是其他類,它使用基尼系數(Gini)來對二叉樹的節點進行選擇。Gini系數的公式:
決策樹生成,即決策過程,根節點為特定的詞序列,即只有一個詞,該詞在所有詞中分類誤差率最好,對某一個類別概率最大。隨后的子節點依據上一個判定劃分成左右兩個子樹,若基尼系數不為零或者詞序列無子序列則停止決策,若不為零且不唯一,則在可能的類別里繼續決策。具體決策樹如圖1所示(該決策樹僅演示所用,取少量數據構建的部分子樹)。
剪枝,裁剪決策樹的一些子樹并將該子樹作為葉節點。決策樹有時會根據所有訓練樣本的形成一個非常龐大的決策樹,在訓練樣本上準確率很高而對于測試樣本準確率往往不理想,形成過擬合現象。過擬合現象的解決方式需要人工的觀察和調試,觀察和控制每一層決策樹大小,設置最小葉節點的樣本個數,調整葉節點的最小權重等等。
3.2 隨機森林
隨機森林( RandomForest),是在bagging算法8基礎上更進一步。
bagging算法是從所有文本中重采樣出n個文本構建分類器,然后重復m次此過程獲得m個分類器最后根據這m個分類器的投票結果決定文本屬于哪一類。隨機森林不需要交叉驗證,步驟如下:
其中I(.)是示性函數,avk表示取平均值,邊際函數表示了在正確分類Y之下X的得票數目超過其他錯誤分類的最大得票數目的程度。邊際函數可有效地展示隨機森林的決策樹組合效果,此外還可以根據邊際函數進行決策樹的n文本個數的調整,決策樹中詞數的調整以及分類的組合方式。
4 實驗結果
本文的數據集的文本總數為12090篇,共分為10個類。分別為:藝術、文化、教育、歷史、哲學、科技、體育、政治、經濟、自然。文本分布如圖2:
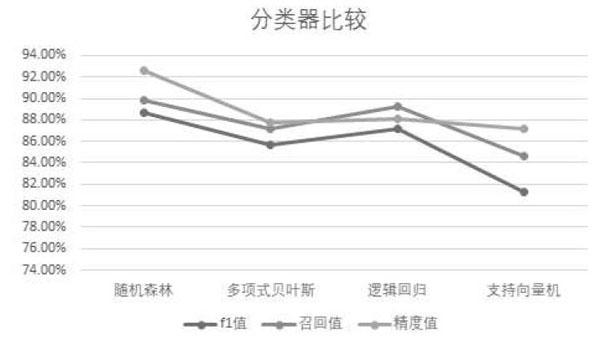
本文為了快速比較四種算法的效果,采用scikit_learn7的skleam. naive_bayes. MultinomiaINB, sklearn. linear_model. Logisti-cRegression,sklearn.svm作為多項式貝葉斯算法、邏輯回歸算法、支持向量機算法的分類器。根據精度值(precisionscore),召回值(recallscore),fl值(fl score)對比效果,如圖3所示。
結果顯示隨機森林分類器的效果要優于其他分類器。
5 結束語
本文從分詞到最終的文本預測,完成了基于隨機森林的藏文文本分類的全部任務。實驗結果顯示文本分類效果良好,且相比于多項式貝葉斯、邏輯回歸、支持向量機效果更為優秀。但進步空間仍然很大,1)應該擴充語料庫為大型語料庫進而再做測試,在大型語料庫上單一的統計算法分類器不能很好地滿足分類需求,要構建多種算法加權預測。2)分類效果上還有上升空間,且目前深度學習研究前景更好,我們應該將統計算法與神經網絡相互融合,從而提高分類效果。
參考文獻:
[1]蘇金樹,張博鋒,徐昕.基于機器學習的文本分類技術研究進展[J].軟件學報,2006(9):1848-1859.
[2]茂松,鄒嘉彥.漢語自動分詞研究評述[J]當代語言學,2001,3(1):22-23.
[3]羅秉芬,江荻.藏文計算機自動分詞的基本規則[C]//中國少數民族語言文字現代化文集.北京:民族出版社,1999.
[4]陳玉忠,李保利,俞士汶,等.基于格助詞和接續特征的藏文自動分詞方案[J].語言文字應用,2003(1):75-82.
[5]洛桑嘎登,楊媛媛,趙小兵.基于知識融合的CRFs藏文分詞系統[J].中文信息學報,2015,29(6):213-219。
[6] Salton G,Wang A,Yang C S.A vector space model for automat-ic indexing[J]. Communication of the ACM, 1975, 18(11):613-620.
[7] https://scikit-leam.org/stable.
[8] Breiman J. Bagging predictors[J]. Machine Learning, 1996, 24(2):123 -140.
【通聯編輯:唐一東】
收稿日期:2019-08-15
基金項目:2018年大學生創新創業訓練計劃項目“基于隨機森林的藏文文本分類”(項目編號:2018XCX045)
作者簡介:包晗(1998-),男,浙江麗水人,本科;通信作者:西熱旦增(1989-),男,西藏那曲人;郭龍銀(1997-),男,江西九江人,本科,主要研究方向為自然語言處理;尚慧杰(1996-),女,河南周口人,本科。
