基于Hadoop平臺的準大學生網購手機消費行為分析
2019-03-07 05:22:18徐俊梅陳濱
電腦知識與技術 2019年35期
關鍵詞:大學生
徐俊梅 陳濱

摘要:智能手機改變了幾代人的生活方式,引領著新技術潮流,準大學生市場成為手機廠家的必爭之地。筆者通過Chrome瀏覽器開發者工具采集某電商網站上高考后三個月互聯網中手機銷售數據,利用Hadoop技術生態組件對數據進行清洗過濾、分析存儲、可視化呈現,分析準大學生購買手機的傾向,通過品牌、顏色、屏幕尺寸三個方面分析其購買行為,預測目標群體網購趨勢,引導手機廠家提升產品技術水平,從而更好促進手機市場更好發展。
關鍵詞:大學生;手機網購;hadoop平臺;Python;數據可視化
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2019)35-0235-03
伴隨著我國居民收入水平的穩定增長,同時互聯網+、智能化技術滲透到生活中,平臺應用和虛擬貨幣概念已經深入人心,特別是告別高中緊張的學習生活即將踏入象牙塔的準大學生們,他們對于移動通訊設備的需求量占據當年電子產品消費市場很大比例,其中智能手機的消費需求最甚。從著名的市場調研機構組織Gartner公布的2019年第一季度全球智能手機銷量就近達40億臺,各大手機制造銷售廠商更是推出了不同類型、不同外觀和功能的手機。那么目前手機市場上到底哪些手機品牌更受關注?哪種手機顏色更受廣大消費者歡迎?是否手機屏幕尺寸越大就越受消費群體青睞?本文研究的目光投放在當代準大學生身上,通過對全國在校大學生手機使用情況開展分析調查,從而預測準大學生們的需求和使用趨勢。
1 大學生手機使用情況概括分析
1.1全國大學生手機使用基本情況
經調查,從全國大學生收取的8000份調查樣本顯示,2018年手機消費價格在1000-2000元之間的大學生占43.99%;手機消費價格在2000-3000元之間的大學生占22.34%;使用3000元以上手機的大學生占據18.76%,其中85.34%大學生購買手機的費用來源于家庭,另外有60%以上大學生更換手機周期在兩年或以上,調查樣本收回數據顯示本科院校與高職院校大學生手機配置參數無異,并且生活費用高低與手機支付價格高低成正比[1][2]。
1.2全國大學生對手機的使用習慣
大學生一般會根據自身需求或喜好選擇不同手機,其中待機時長、手機功能、屏幕尺寸、外觀、品牌、攝像頭像素、價格等考慮的主要因素;超過50%的大學生使用每日使用手機時間超過5個小時,而使用頻率高峰期發生在20:00至24點之間。
1.3大學生選擇不同品牌手機的影響因素
1.3.1手機消費心理影響因素
大學生群體處于心理發展敏感期,容易受到外界因素影響或干擾;媒體多樣化宣傳手段和求異個性、攀比虛榮的消費心理極易喚起大學生的購買手機的欲望。
1.3.2原生家庭環境因素
大學生在校生活學習費用主要來源于家庭,而家庭經濟支持與消費習慣局限著大學生購買空間,如何分配好生活必需品、學習耗品、移動設備、娛樂休閑消費比例成為其群體當下要考慮的重要問題。
1.3.3個人購買傾向因素
時尚靚麗外觀與科技功能配置是吸引年輕群體蜂擁圍觀手機市場的重要原因,從眾心理、品牌效應、提前消費等外來因素無不影響大學生消費傾向,如何取舍和理性消費這就需要大學生們自己去斟酌[2]。
1.4大學生使用手機的用途和建議
社交平臺、網購、手機游戲使大學生成為網絡平臺消費的主力軍,但是過度使用手機不但會影響視力、阻礙社交能力發展,更會影響學業,據調查數據顯示已有35.12%的大學生對手機產生依賴,工作學習生活中幾乎所有的業務辦理都在手機應用平臺上發生[3]。
2 準大學生網購手機數據分析
本文采用脫敏方式,使用Chrome瀏覽器訪問目標網站,通過開發者工具收集某電商網站2018年8月手機銷售數據,利用Hadoop技術生態組件對數據進行解析及關鍵數據提取,使用Python語言完成無關數據清洗和有效數據存儲,最后運用Echarts數據可視化組件,呈現數據的可視化,分析出最受準大學生追捧的手機品牌、手機顏色和手機屏幕尺寸,預測準大學生的手機消費水平和需求趨勢,有的放矢地更好調控手機消費市場。
2.1電商網站手機銷售網頁數據采集
利用爬蟲工具萃取某電商網站的在線手機銷售數據,但采集到的JSON數據文件中包含部分臟數據,這就需要對目標數據集進行特征參數提取,構建文本向量。數據集描述如下:
2.1.1數據范圍
Chrome瀏覽器爬蟲到2018年6月電商網站用戶購買手機數據交易數據集合。
2.1.2數據格式
Phone_brand:***//手機品牌名稱
Phont_name:***//手機型號
parameters:[//手機特征參數
{//parameter_1
”namel”:”value1”,
”name2”:”value2”,
……
}]
{//parameter_n
”name1”:”valuel”,
”name2”:”value2”,
……}]
2.1.3數據樣例
{”phone_brand”:”華為”,
”phone_name”:”華為P10”,
”parameter”:[
{”品牌”:”華為”,
”型號”:”華為P10”, ”制作商名稱”:”華為技術有限公司”,
”出廠年份”:”2018年”,
”出廠月份”:”6月”}
{”機身顏色”:”曜石黑”,
”手機類型”:”智能手機拍照手機4G手機時尚手機”,
”操作系統”:”華為EMUI 5.1(兼容Android 7.0)”,
”CPU品牌”:”麒麟960”,
”核心數”:”八核+微智核i6”,
”電池類型”:”不可拆卸式電池”,}
{”分辨率”:”1920x1080”,
”觸摸屏類型”:”多點觸控”,
”屏幕尺寸”:”5.1英寸”,}
{”運行內存RAM”:”4GB”,
”存儲容量”:”64GB 128GB”,}
{”鍵盤類型”:”虛擬觸屏鍵盤”,
”款式”:”直板”}
{”后置攝像頭”:”2000萬像素(黑白)+1200萬像素(彩色)”,
”攝像頭類型”:”三攝像頭(后雙)”,
”視頻顯示格式”:”*.3gp,*.mp4,*.wmv,*.rm,*,rmvb,*.asf”}]}
利用python語言來構建數據采集請求功能函數,利用Re-sponse JSON數據解析,并在本地完成手機銷售數據文件的創建和書寫[4][5]。具體功能語句如下:
def response_handler(self,url,data)://使用目標網頁Url或接口構造Response對象
response=requests.post(url=url,data=data, headers=self.head-ers)
def parse(self,response)://對Response對象進行解析;形成結構化數據
items=[]
datas=json.loads(response.text).get('data ',[])
def save_data(self,item)://將解析到的數據存儲到指定目錄下的Json文件中去
data=json.dumps(item, ensure_ascii=False)
self.fp.write(data+',\n')
2.2手機銷售數據清洗與過濾
在搭建好的Hadoop集群的偽分布環境中讀取采集到的HDFS數據文件,經數據解析后,進行過濾和分區,利用MapRe-duce程序完成編譯、打包,發布與執行,從而完成手機銷售數據的清洗。下面從數據文件中解析JSON格式數據,從數據中獲取需要的字段[6]:
String phoneBrand=GetStringByName(rawValue,"phone_brand");//提取手機品牌名稱
String phoneSize=GetPhoneSize(rawValue);//提取手機屏幕尺寸
String buyColor=GetPhoneColor(rawValue);//提取用戶購買手機顏色
2.3手機銷售數據分析與可視化
在Linux Shell基礎上完成Hive數據庫和數據表的創建,利用HQL語言完成數據統計,并實現Sqoop數據推送,因手機網購數據集包含三種手機特征參數,分別是手機品牌、手機顏色、手機屏幕尺寸,故最后在Flask網頁后臺利用可視化前端開發工具Echarts組件調用HTTP API接口實現數據可視化渲染,從而呈現手機銷售與三組參數的數據分析結果,需要特別說明的是這三個手機特征參數均排除了其他的聚類項的影響,獨立獲取的對應手機銷售量。運行Chrome瀏覽器,輸入URL地址后即可查看數據可視化成果[7][8]。
利用上傳工具(如SFTP)將清洗后的手機銷售網頁數據傳至分布式服務器中,并利用Hive創建數據庫和數據表,加載清洗后數據至數據表中,進而完成手機銷售數據的查詢分析[9]。具體功能語句如下:
Hadoop fs—mkdir/data//Hadoopshell命令創建目錄
hadoop fs—put/home/清洗后的數據目錄/data//上傳數據至HDFS目錄下
Create database db_phone;//Hive創建數據庫
Create table tb_phone_data(Phone_Brand string, Phone_colorstring, Phone_size string) row format delimited fields terminated by'|';//原始數據表
Create table Phone_brand_count(Phone_Brand string,Phone_sale_count int);//手機品牌銷量查詢暫存表
Create table Phone_color_count(phone_color string,Phone_sale_count int);//手機顏色銷量查詢暫存表
Create table Phone_size_count(phone_size string,Phone_sale_count int);//手機屏幕尺寸銷量查詢暫存表
Load data inpath '/data/*' into table phone_data;//數據加載
Insert overwrite table Phone_brand_count selectPhone_Brand_Name,count(1) as Phone_sale_count from phone_da-to group by Phone_bBrand_Name;//手機品牌銷量查詢insertoverwrite table Phone_color_count select phone_color, count(1) asPhone_sale_count from phone_data group by phone_color;
//手機顏色銷量查詢
insert overwrite table Phone_size_count select phone_size,count(1) as Phone_sale_count from Phone_phone_data group byphone_size;//手機屏幕尺寸銷量查詢
在python創建項目的根目錄下使用python manager.py run-server命令,在chrome瀏覽器中輸入URL地址顯示可視化結果,具體呈現如下面三張圖所示。
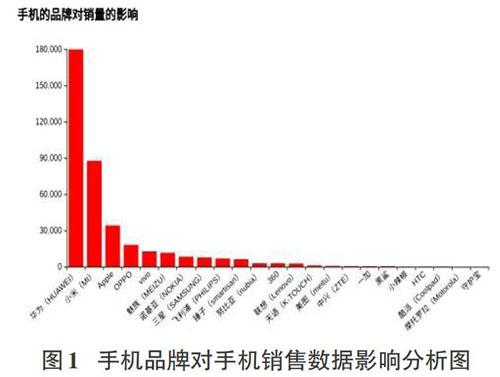
第一組:差異手機品牌對手機銷售量的影響結果圖。
用二維柱狀圖呈現的是不同手機品牌的銷售數據,X軸表示抓取電商網站中在售品牌,Y軸表示不同品牌手機的銷售數量,數量是臺。
從圖1中數據分布整體結構上看,國產手機品牌銷售量在手機銷售中占有較大優勢,手機銷售量排名前十的手機品牌中,國產手機品牌共有7個,認可度較高的手機在售品牌的排名次序依次為華為、小米、Apple、OPPO、VIVO、魅族、諾基亞、三星、飛利浦、錘子、努比亞。其中華為、小米的手機銷量占有比較明顯的優勢,排行第三名的蘋果手機銷售量與前兩名銷量更是有較大差距。隨著大學生愛國意識的不斷增強,國產手機不管是外觀設計、人體工程學理念還是核心技術支撐已經有了巨大的發展,更符合中國人的使用喜好和習慣。
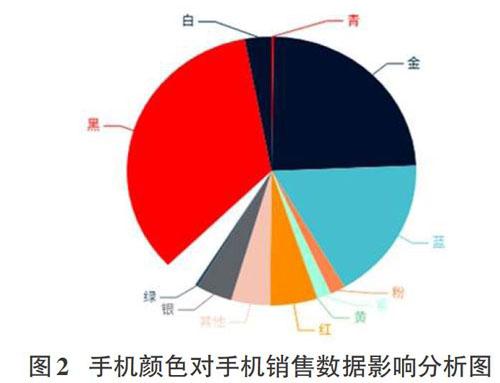
第二組:差異手機顏色對手機銷售量的影響結果圖。
此二維餅圖輸出的是不同顏色手機銷售數據分布,從電商網站獲取到的手機數據量顯示每種顏色手機銷售比例,不同色塊大小代表指定手機顏色的銷售數據量。
從圖2中手機銷售數據比例分析結果看,排名前三的手機顏色是黑色、藍色和金色,其中黑色是最受消費者歡迎的顏色,更得到對象群體的青睞。
第三組:差異手機尺寸對手機銷售量的影響結果圖。
此折線圖呈現的是不同屏幕尺寸手機銷售數據,X軸表示的是手機屏幕尺寸,Y軸表示的是手機銷售數據,數量是臺。
從圖3中數據分析結果上看,5.99英寸是最受群體歡迎的手機屏幕尺寸,5.5英寸次之,5.84英寸手機銷售數據排名第三,而更大尺寸的手機屏幕并沒有出現在銷量較高的手機范圍內,因現在移動終端設備種類和用途的多樣性,所以并不是手機屏幕越大越受目標群體的青睞。
3 小結
依據小概率事件不發生原理,本文從某電商網站中采集到的2018年8月手機銷售數據經數據清洗和可視化處理后,得到的三種特征參數:手機品牌、手機顏色和手機屏幕尺寸與手機銷售數據的比例分布圖,可以預測出準大學生們的手機網購傾向,幫助手機制造廠商掌握市場消費動向,有針對性地開展主動營銷方案,精準投放產品,提升企業服務質量。
參考文獻:
[1]李文韜.從手機品牌選擇看大學生消費觀——基于對南充市某高校大學生手機品牌使用情況調查[J].山西青年,2017(9):266.
[2]虞雀.大學生手機消費影響因素實證研究[J].江蘇科技信息,2015(20):75-77.
[3]牟瀟,侯玲.大學生網購手機消費行為分析[J].文化與探索,2018(16):146-147.
[4]趙科軍,葛連升,劉洋,等.基于Hadoop和Spark構建可擴展的網絡安全分析平臺[J].華中科技大學學報:自然科學版,2016(S1):11-13.
[5]Yeonhee Lee,Youngseok Lee.Toward scalable internet traffcmeasurement and analysis with Hadop[J].ACM SIGCOMMComputer Communication Review,2012(1):117—119.
[6]Hingave H,Ingle R.An appmach for MapReduce based loganalysis using Hadoop[C].Electronics and Communication Sys—tems(ICECS),2015 2nd Intemational Conference,2015:201—204.
[7]劉萍.基于Hadop與Spark的大數據處理平臺的構建研究[J].通化師范學院學報,2018(6):59—62.
[8]于金良,朱志祥,李聰穎.Hadoop平臺的自動化部署與監控研究[J].計算機與數字工程,2016(12):34—37.
[9]孟永偉,黃建強,曹騰飛,等.Hadoop集群部署實驗的設計與實現[J].實驗技術與管理,2015(1):21—23.
【通聯編輯:唐一東】
收稿日期:2019-08-15
基金項目:安徽省教育廳(相助省級重點項目)質量工程(2017zhkt358)
作者簡介:徐俊梅(1983-),女,安徽合肥人,講師,碩士,主要研究方向為計算機網絡技術及大數據技術;陳濱(1981-),男,安徽合肥人,學士,講師,研究方向為軟件工程。
猜你喜歡
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
黃河之聲(2017年14期)2017-10-11 09:03:59
北方音樂(2017年7期)2017-05-16 00:32:46
教育與職業(2014年16期)2014-01-19 01:24:34
中國火炬(2013年7期)2013-07-24 14:19:23
中國火炬(2010年9期)2010-07-25 11:45:09
