漢語詞匯識別的聲調時長效應 *
2019-03-12 07:45:34丁潼飛
心理與行為研究 2019年1期
于 秒 丁潼飛
(1 教育部人文社會科學重點研究基地天津師范大學心理與行為研究院,天津 300074)(2 北京外國語大學中國語言文學學院,北京 100089)
1 引言
默讀時,人們能夠聽到自己大腦里發出所讀文本的聲音。這種聲音一般被稱為內在聲音或內在言語。在科學術語里,內在言語一般指人們在閱讀時激活的大腦中的語音信息表征(Huestegge,2010)。內在言語能夠指導和幫助人們進行閱讀,這種觀點在差不多整個20世紀一直都被人們認為是正確的(Rayner, Pollatsek, Ashby, & Clifton, 2012)。
在過去的近30年中,心理語言學研究者們開始批判地審視閱讀時內在言語的作用。研究者們關注的一個主要問題是內在言語是否只是閱讀時聽到的一個附帶現象?還是它確實影響了讀者對語言的加工和理解。一些研究認為,內在言語僅僅只是默讀時聽到的一種附帶現象,其在默讀時并非總是起作用(Carlson, 2009; Foltz, Maday, & Ito,2011; Halderman, Ashby, & Perfetti, 2012; Jun,2010)。而Fodor(1998, 2002)提出的內隱韻律假說(Implicit Prosody Hypothesis)堅持認為:即使在默讀時,讀者也可以產生句子語調、重音、停延和節奏等表征,這些表征均能影響讀者對文本的理解。該假說提出后,得到了諸多研究的支持(如Ashby & Clifton, 2005; Breen & Clifton, 2011,2013; Drury, Baum, Valeriote, & Steinhauer, 2016;Hwang & Steinhauer, 2011; Jun & Bishop, 2015;Steinhauer, 2003; Stolterfoht, Friederici, Alter, & Steube,2007; Webman-Shafran, 2018; Yao & Scheepers, 2018)。
關于閱讀中內在言語作用的研究主要聚焦在兩種類型的語音表征上:音段語音和超音段語音。音段語音信息主要指的是影響詞匯識別的元音、輔音等音素,而超音段語音主要指詞層面以上的語音現象,如重音、節奏、語調等韻律信息。
1.1 音段及音段組合在語言加工中的作用
音段方面的研究主要集中在元音時長和輔音時長(指元音和輔音聲學上的時長,元音時長指長元音、短元音時長,輔音時長指VOT長短)對詞匯識別的影響(Abramson & Goldinger, 1997;Ashby, Treiman, Kessler, & Rayner, 2006; Lukatela,Eaton, Sabadini, & Turvey, 2004; Huestegge, 2010)。如Abramson和Goldinger(1997)比較了正字法長度相同但元音長度和詞首輔音長度不同的詞的詞匯判斷時間,結果發現,被試對含有長元音或長詞首輔音的詞(如wart、sake)的判斷時間長于含有短元音和短詞首輔音(如wade、tape)的詞,這種時長效應發生在低頻詞條件下。這表明在詞匯加工過程中,默讀確實激活了內在言語。Lukatela等人(2004)在詞匯命名任務中也報告了邊緣的元音長度效應,也證實了元音長短影響詞匯通達。Huestegge(2010)的眼動研究發現,元音長度影響詞語的凝視時間。該研究中,被試閱讀包括目標詞(改變其元音長短和詞頻)的句子。結果發現,目標詞為長元音時,被試對其的凝視時間大于含有短元音的目標詞,證實了默讀時語音信息扮演了重要角色。
一些研究發現預視信息與目標詞詞首音節信息一致時詞匯識別更快(Ashby, 2006; Ashby &Martin, 2008; Ashby & Rayner, 2004)。如 Ashby(2006)通過操控預視詞與目標詞詞首音節重音位置一致或不一致來考察重音位置對詞語加工的影響。研究發現,在低頻詞條件下,與詞首音節重音位置不一致(如預視詞為“pos_zvzv”, 目標詞為“position”)條件相比,當預視詞詞首音節重音位置(如“po_ zvzvz”)與目標詞詞首音節重音位置(如“position”)一致時,被試對目標詞的加工時間更快。Ashby和Rayner(2004)使用帶有CV起始音節 (如DE.MAND) 或者CVC起始音節 (如LAN.TERN) 的目標詞,操控啟動詞與目標詞起始音節匹配或者不匹配。研究也發現,與詞匹配的預視的首次注視時間短于不匹配的預視的首次注視時間。這些研究為默讀時的內在言語作用提供了來自多層次語音表征的證據。
1.2 超音段信息在語言加工中的作用
大量研究發現,內隱韻律邊界(Hirose, 1999;Hwang & Schafer, 2009; Luo, Yan, & Zhou, 2013;Quinn, Abdelghany, & Fodor, 2000; Swets, Desmet,Hambrick, & Ferreira, 2007; Traxler, 2009)、內隱重音(Ashby & Clifton, 2005; Breen & Clifton, 2011,2013; Speer & Foltz, 2015)、內隱語調(Abramson,2007)等均影響語言加工。
很多研究考察內隱韻律邊界在語言理解中的作用,如Hwang和Steinhauer(2011)采用ERP技術考察韓語歧義句加工時發現,主語是長名詞短語時誘發了韻律邊界成分CPS,名詞短語后的內隱韻律邊界的延遲插入會誘發P600成分。Steinhauer和Friederici (2001)讓被試默讀局部歧義句,當解歧的韻律邊界出現時誘發了CPS成分。一些研究通過在句法歧義句和非歧義句中插入逗號的方法來探討內隱韻律邊界的作用。如Luo等人(2013)使用逗號作為韻律邊界標記,放置在歧義句的解歧位置,結果發現,逗號和韻律邊界線索一樣,影響詞匯加工。
有些研究通過眼動實驗來考察默讀時詞匯重音對詞匯識別影響。研究發現,讀者默讀時也激活了詞匯水平的韻律信息。如Ashby和Clifton(2005)考察被試閱讀帶有一個或兩個重讀音節的目標詞的眼動差異。研究發現,與有一個重讀音節的詞(如intensity)相比,被試加工擁有兩個重讀音節的詞(如radiation)花費的時間更長。Breen和Clifton (2011) 在被試閱讀打油詩的同時測量被試的眼動情況。打油詩中末尾詞為重音交替變化的名動或名形同音異義詞 (如PREsent, preSENT),詞的重音通過匹配或不匹配的打油詩韻律模式來實現。研究發現,讀者閱讀不匹配末尾詞重讀模式時花費了更多的加工時間。表明讀者在默讀時,產生了一種內隱的重讀模式,影響同音異義詞的加工。
另外,Abramson (2007)通過聽覺呈現一個語調模式與句末詞一致或不一致的詞,考察被試加工陳述句或疑問句句末目標詞的情況。研究證實了聽覺呈現詞的語調模式與視覺呈現的句末詞語調匹配時加工更加容易。
前面我們已經從音段及超音段兩個大方面回顧了內在言語作用的一些證據。學者們從不同層面探討了內在言語在語言加工中的作用,取得了很多研究成果,但關于內在言語作用的研究還存在一些有待于繼續深入探討的問題:(1)現有的有關內在言語作用的研究絕大多數均是在拼音文字體系的語言中發現的,而對漢語內在語言作用的研究較為少見。拼音文字體系的語言多屬于表音體系的語言,語音與正字法的關系相對透明,而漢語屬于表意體系的文字,其正字法與語音本身不如拼音語言那樣透明。因此,內隱韻律是否對漢語這種表意體系的語言的加工也同樣起作用?(2)在詞匯識別層面,以往研究多集中在元音和輔音時長對詞匯識別的影響,聲調時長信息是否也影響詞匯識別?漢語與印歐語系在音系上的一個重大差別即是漢語是有聲調語言。聲調不僅是漢語音節結構的重要組成部分,同時它又像英語等語言的詞內重音一樣,屬于超音段信息,韻律信息。聲調是否影響漢語詞匯識別是一個值得研究的問題。
因此,為了進一步探討內在言語的作用及其跨語言的普遍性,本研究擬通過兩個實驗來探討這一問題。實驗一從聲學角度探討漢語四個聲調的時長是否存在差異;實驗二在實驗一的基礎上探討聲調時長對詞匯識別的影響。
2 實驗一: 漢語聲調時長差異的聲學分析
2.1 研究方法
2.1.1 被試
被試為15名普通話流利(普通話水平二級甲等及以上)的大學生,視力或矯正視力正常。被試實驗后均獲得一份禮物。
2.1.2 實驗設計
實驗采用單因素四水平被試內設計。四個水平為普通話的四個聲調調類,即陰平、陽平、上聲和去聲。
2.1.3 實驗材料
從國家語委語料庫中隨機選擇各類調類單音節詞若干,控制各類調類詞中送氣擦音,塞擦音的數量以及各類調類詞的詞頻和筆畫數,最后選定80個單音節詞,每個調類(陰平如“多”“包”,陽平如“拔”“奪”,上聲如“寶”“百”,去聲如“報”“拜”)各20個。詞頻(次/兩千萬)及筆畫數均值見表 1。
統計分析發現,詞頻主效應不顯著,F(3,57)=0.76,p>0.05,η2=0.04,筆畫數主效應也不顯著,F(3, 57)=0.36,p>0.05,η2=0.02。
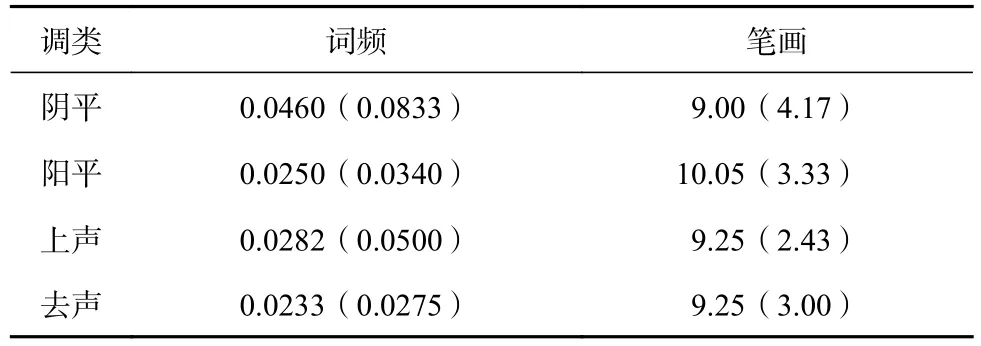
表 1 80 個單音節詞的詞頻和筆畫的均值及標準差(括號內)
2.1.4 實驗程序
將80個單音節詞(每個調類20詞)打亂呈現給被試。請被試事先熟悉實驗材料,確認每個單音節詞的發音,然后大聲朗讀每個單音節詞。采用praat聲學軟件對被試的朗讀進行錄音,采樣率為11025 Hz,單聲道。錄音后采用praat進行語音標注并采集被試朗讀的80個單音節詞的時長數據。
2.2 結果
統計分析發現:四個聲調時長被試分析和項目分析差異均顯著,F1(3, 42)=236.04,p<0.001,η2=0.94,F2(3, 57)=978.81,p<0.001,η2=0.98。兩兩比較發現,上聲時長均長于其它三個調類的時長,ps<0.001,去聲時長均小于其它三個調類的時長,ps<0.001,陰平時長與陽平時長無顯著差異。這表明,在普通話的聲調時長中,上聲時長最長,去聲時長最短。
2.3 討論
實驗1研究發現,普通話的四個聲調中,上聲時長最長,而去聲時長最短。這與劉復(1924)、白滌洲(1934)、石鋒(1991)等對北京話單字調調長差異的研究結論一致。與鄧丹,石鋒和呂士楠(2006)、馮勇強,初敏,賀琳和呂士楠(2001)以及宋雅男,何偉(2005)研究結論略有不同,造成結論不同的主要原因之一是采用的統計方法不同。前人研究多數僅是對聲調時長均值的比較,而非進行統計分析,這在一定程度上影響了研究的科學性。為了較為準確地判定漢語聲調的時長差異,實驗1采用統計分析方法重新分析了漢語四個聲調調長的差異。另一原因是是否在自然語流中測量聲調時長。由于實驗1主要探討聲調時長在詞匯識別時的差異,暫不關心單音節詞處于語流中的情況,從單音節詞的聲調時長判斷來看,鄧丹等人(2006)研究也發現上聲詞時長最長,馮勇強等人(2001)在自然語流中也發現去聲詞時長最短。馮隆(1985)研究發現目標詞處于句末時上聲詞時長最長,陽平詞時長次之,陰平詞時長較短,去聲詞時長最短,與本研究結論大致一致。

表 2 普通話四個聲調時長均值(ms)及標準差
實驗1的結果顯示,在朗讀時,上聲詞時長長于去聲詞時長。那么,在默讀時,是否也存在如此差異?這種差異與詞頻間是否存在交互作用?實驗2將在實驗1的基礎上,選擇漢語單音節的上聲詞和去聲詞作為實驗材料,探討詞匯識別中上聲詞時長和去聲詞時長在不同詞頻下的差異。
如果存在聲調時長效應,那么被試在漢語詞匯識別時將會利用聲調時長信息,對上聲詞的加工時間將會長于去聲詞的時間。如果不存在聲調時長效應,那么,上聲詞的加工時間與去聲詞的加工時間將不存在差異。本研究假設,不管在高頻詞條件還是低頻詞條件下,上聲詞在默讀時的加工時間均要長于去聲詞時長。
3 實驗二: 漢語詞匯識別中的聲調時長效應
3.1 研究方法
3.1.1 被試
天津外國語大學學生27名,普通話流利,所有被試視力或矯正視力正常。參加實驗的被試實驗后均會獲得一份禮物。
3.1.2 實驗設計
實驗采用2(調類: 上聲、去聲)×2(詞頻: 高頻、低頻)被試內設計。
3.1.3 實驗材料
為了避免詞性因素以及名詞具體性對實驗結果的影響,本研究僅選擇具體名詞作為實驗材料。從國家語委語料庫中搜索到359個上聲和去聲單音節名詞。通過控制詞頻、筆畫數和單音節詞的輔音類型,最后確定了108個單音節名詞(低頻上聲詞,如“餅”“苯”、低頻去聲詞,如“被”“弟”、高頻上聲詞,如“筆”“板”、高頻去聲詞,如“電”“報”,各27個)作為實驗材料。108個單音節名詞的詞頻及筆畫信息見表 3。同時,我們又從國家語委語料庫中搜索到52個單音節名詞(陰平詞和陽平詞各26個)和120個單音節動詞(每個調類各40個)作為填充材料。
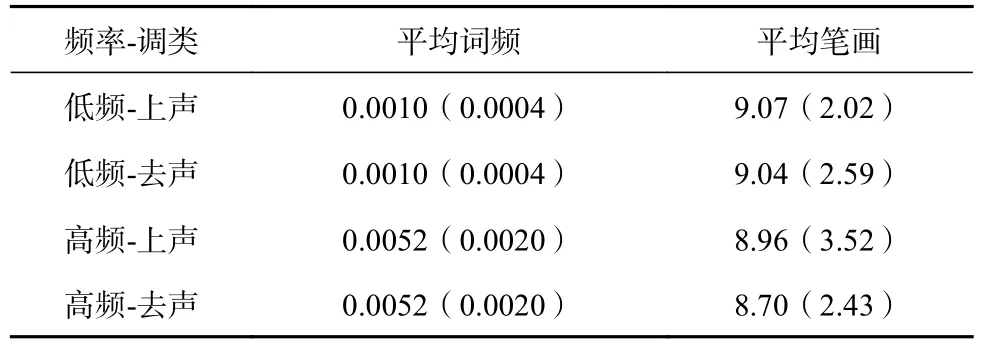
表 3 108 個單音節詞的詞頻和筆畫數的均值及標準差(括號內)
經檢驗,詞頻差異顯著,F(3, 78)=81.58,p<0.001,η2=0.76,低頻上聲詞的詞頻與低頻去聲詞的詞頻差異不顯著,p>0.05,高頻上聲詞的詞頻與高頻去聲詞的詞頻差異不顯著,p>0.05,低頻上聲詞的詞頻與高頻上聲詞的詞頻差異顯著,p<0.01,低頻去聲詞的詞頻與高頻去聲詞的詞頻差異顯著,p<0.01。筆畫數差異不顯著,F(3, 78)=0.11,p>0.05,η2=0.004。
3.1.4 實驗程序
實驗使用DMDX實驗軟件編程。刺激呈現在電腦顯示器上,呈現的字體顏色均為白底黑字。實驗采用的是詞性判斷任務。被試坐在電腦屏幕前,眼睛距離屏幕約40厘米。實驗要求被試盡量快而準確地判斷屏幕中心出現的單音節詞是名詞還是動詞,如果是名詞按電腦鍵盤的“J”鍵,如果是動詞按“F”鍵。實驗開始時,首先在屏幕上出現一個十字形的注視點,持續時間為300 ms,然后空屏300 ms,刺激項目呈現的時間為300 ms。前后刺激項目的呈現時間間隔為3 s。計算機記錄下刺激開始呈現到被試開始反應的時間。正式實驗前,被試要進行10個刺激項目的練習,練習詞中包括5個名詞和5個動詞。確認被試完全理解了實驗任務后,開始正式實驗。整個實驗持續大約20分鐘。
3.2 結果
被試的詞性判斷正確率均在90%以上。從結果分析中去掉平均數加減三個標準差之外的數據,這樣有74個數據 (1.86%)從數據分析中去掉。平均反應時和正確率見表 4。
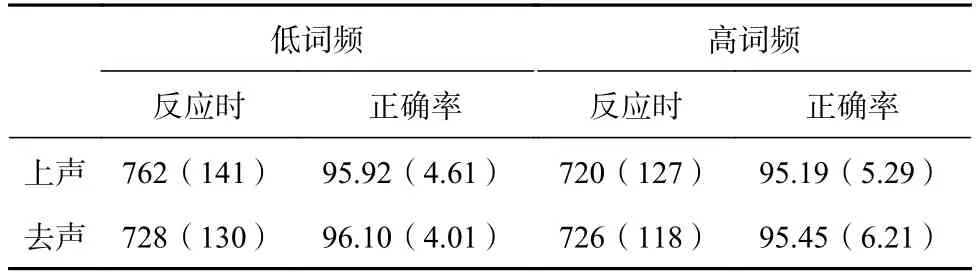
表 4 詞性判斷的反應時(ms)、和正確率(%)
反應時的方差分析表明:調類主效應不顯著,F1(1, 26)=2.37,p>0.05,η2=0.08,F2(1,19)=1.74,p>0.05,η2=0.08。詞頻主效應被試分析顯著,F1(1, 26)=11.83,p<0.01, η2=0.31,項目分析邊緣顯著,F2(1, 19)=4.32,p=0.05,η2=0.15。調類與詞頻的交互作用顯著,F1(1,26)=23.49,p<0.001,η2=0.48,F2(1, 19)=5.13,p<0.05,η2=0.21。進一步簡單效應分析發現,低頻條件下,上聲詞的反應時長于去聲詞的反應時,t1(26)=3.40,p<0.01,t2(19)=2.70,p<0.05,高頻條件下,上聲詞的反應時與去聲詞的反應時差異不顯著,t1(26)=-0.59,p>0.05,t2(19)=-0.41,p>0.05;上聲詞條件下,低頻詞的反應時長于高頻詞,t1(26)=5.29,p<0.001,t2(19)=2.86,p<0.05,去聲詞條件下,低頻詞的反應時與高頻詞的反應時差異不顯著,t1(26)=0.34,p>0.05,t2(19)=-0.15,p>0.05。
正確率的方差分析表明:調類主效應、頻率主效應以及二者的交互作用均不顯著,ps>0.05。
3.3 討論
實驗2使用上聲單音節詞和去聲單音節詞作為實驗材料,使用詞性判斷任務考察了漢語詞匯識別過程中聲調的時長效應。研究結果表明:高頻詞條件未發現聲調的時長效應,而在低頻詞條件下,出現了聲調時長效應:即上聲詞的反應時長于去聲詞的反應時時長。本實驗的研究結果與以往在音段信息(Abramson & Goldinger, 1997;Huestegge, 2010; Jared & Seidenberg, 1991; Lee,Binder, Kim, Pollatsek, & Rayner, 1999; Lukatela et al.,2004)以及超音段信息(Ashby et al., 2006; Ashby &Clifton, 2005; Breen & Clifton, 2011, 2013)對詞匯識別的作用的研究類似。尤其與Abramson和Goldinger(1997)在低頻詞條件下發現元音音段的時長效應類似。Abramson和Goldinger發現,低頻詞下長元音的詞匯判斷時間長于短元音的判斷時間,這種時長效應恰恰反映了默讀時聲學表征的激活,即內在言語的激活,而不是抽象的語音編碼的激活。Jared和Seidenberg(1991)的實驗也發現在低頻詞條件下,語音對詞義的通達起促進作用。
本實驗僅在低頻詞條件下發現了聲調的時長效應。顯然,這一結論與之前的假設不完全一致。這與我們的實驗任務以及聲調本身具有區別意義的特點相關。本實驗為了使被試能夠通達詞匯的意義,采用的是詞性判定任務,被試需要對刺激進行詞性判斷。漢語是一種缺乏形態變化的語言,被試在實驗過程中無法從詞形上判斷出一個詞的詞性,又因為本實驗采用孤立詞呈現,被試也無法從語法功能上判斷詞性,而僅能通過意義來判斷刺激為何種詞性。James(1975)詞匯判斷實驗發現,在一定程度上,對于不常見的低頻詞,人們更傾向于在語義水平上對其進行加工。閆國利,杜晨,卞遷和白學軍(2014)也發現了低頻詞條件的名詞具體性效應。具體性效應實際上也是一種語義效應。因此,低頻詞使被試能夠加工到語義水平。這成為區別上聲詞和去聲詞時長效應的條件。高頻詞情況下沒有發現聲調的時長效應很可能與熟悉性相關。由于高頻上聲詞和去聲詞在熟悉性上一樣,因此,熟悉性很可能抵消了聲調的時長效應。
本研究通過兩個實驗考察了漢語詞匯識別時的聲調時長效應。實驗1為了驗證前人對漢語聲調時長研究的結論,重新從聲學上測量了漢語四個聲調的時長,并統計分析了四個聲調時長的差異。研究結果確認了漢語上聲詞時長最長,去聲詞時長最短。在實驗1的基礎上,實驗2重點考察了上聲單音節詞和去聲單音節詞在不同詞頻條件下是否存在聲調時長效應。結果在低頻詞條件下發現了聲調時長效應。一般認為,聲調區別意義主要體現在音高上,但本研究結果表明,聲調時長在區別詞義時也具有重要的參考價值。尤其是對于上聲和去聲來說,對區別詞義具有顯著的作用。
本研究的兩個實驗明確地表明,漢語詞匯識別在默讀和朗讀時一樣,聲調時長的聲學表征被激活,即內在言語被激活。表明在默讀情況下,漢語調類的時長差異在漢語詞匯的識別中具有重要作用。被試需要利用聲調時長這一語音信息來進行詞匯通達。聲調屬于超音段信息,即韻律信息。因此,本研究的結論為詞匯識別中內隱韻律作用提供了漢語的證據,支持了內隱韻律假說。
4 結論
在本實驗條件下,本研究得出以下結論:(1)漢語上聲詞的時長長于去聲詞的時長。(2)低頻詞條件下,漢語上聲詞的加工時間長于去聲詞的加工時間。聲調時長在漢語詞匯識別中具有重要作用。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
發明與創新(2016年38期)2016-08-22 03:02:52
