一種改進的實體識別方法實現
2019-03-14 07:17:42蔣存鋒趙川
現代計算機 2019年4期
蔣存鋒,趙川
(1.上海計算機軟件技術開發中心,上海 200000;2.Teradata Corporation,圣地亞哥,美國)
0 引言
排序是計算機程序設計中一項基本的操作,在實際應用中,有很多情況下需要對數據按照某種方式進行排序后才能達到某種要求,因此,學習和研究各種排序方法是計算機工作者的重要課題之一。
實體識別也稱為重復記錄去除、身份識別、對象識別、引用識別、記錄連接、混合-清除、數據關聯等。
實體是由屬性來描述的,屬性的值構成了某個特定實體的信息。例如,一個人有諸如姓名、生日、指紋等屬性。因為實體是真實世界的實體,所以屬性值的集合是獨一無二和真實存在的。我們可能知道一個實體的真實屬性值,也可能不知道。我們只有實體的引用,也就是實體屬性值的一個集合。對于某一個特定實體,我們可能有多個引用,每一個引用都有不同的屬性值集合。因為這些集合看上去不同,所以我們需要確定他們是否對應的是同一個真實世界實體。從一個比較窄的意義上來說,這也就是實體識別要做的事情。在更廣泛的意義上,實體識別還牽涉到更多的工作。有的數據也許是沒有結構的,也沒有明顯的實體引用(屬性值集合)。或者有實體引用,但是缺乏統一的格式。Talburt[1]列出了實體識別在一個廣泛意義上所涉及的五個主要的工作:
●實體引用抽取:從無結構信息中定位和收集實體引用;
●實體引用準備:在識別之前,對結構化的實體引用施加標準化、數據清洗等技術;
●實體引用識別:確定引用是否對應同一個實體;
●實體身份管理:建立和維護一個長久的實體身份信息記錄;
●實體關系分析:開拓不同的但是相關的實體之間的關聯網絡。
我們的研究工作主要涉及的是實體引用的準備和識別。實驗所使用的數據源是文本格式,并含有明顯的實體屬性和值,所以不需要進行實體引用抽取的工作。不過我們做了一些實體引用的準備工作來提高數據質量,以便更好地比較它們。
1 方法概述
1.1 常用方法
一般地,進行實體識別的技術需要在記錄對之間建立良好的匹配標準,這樣實體識別也可以看作是分類問題:對于兩個記錄的每一對對應的屬性值之間的相似值構成的一個向量,把它歸類為“匹配(副本)”或者“不匹配(非副本)”。匹配標準可能涉及到一個度量標準和一個用戶定義的臨界值,用來確定區分匹配記錄和不匹配記錄的點。根據一些通常的定義[2],匹配標準返回三個不同的值:匹配、不匹配、需要進一步檢查。Brizan和Tansel[3]對不同的匹配技術做了一個簡潔的描述。Elmagarmid等人[4]總結了檢測不相同但是等價的數據庫記錄的技術。
實體識別系統一般使用四種基本的技術來確定是否兩個引用是等價,或者稱為對應同一個真實實體。它們是直接匹配、傳遞等價、關聯分析、斷言等價[2]。在我們改進的實體識別框架中我們使用了所有的四種技術。
傳統的實體識別方法經常使用數據屬性值之間的文本相似性。一些比較新的方法則考慮由數據上下文導出的關系相似性作為附加的信息,還有一些方法是基于概率模型的。匹配含有多個屬性的記錄方法大致可以分為兩類。一類是依靠學習數據來“學習”如何匹配數據,這一類方法通常使用概率的方法以及監督的機器學習技術。另一類方法依靠領域知識或者屬性距離度量標準來匹配記錄。
1.2 改進的方法
通過研究,我們結合兩種匹配方法中有用的部分,并進行改進,得到一種更為有效的匹配方法[5]。該方法提出了一個既使用直接相似度又使用間接相似度的結構化的相似度度量標準,并對非監督學習使用一個簡單的相似度模型,對監督學習則提供了一個概率的分類模型以及估算概率的方法。此外該方法提供了簡單的更新算法來消除分類匹配結果中的不一致性。
我們沿用了相似度度量和概率模型,并在此基礎上做了較大的改進。不但進行實體的識別,還兼顧到對象的合并。增加了數據預處理(pre-processing)的步驟,在其中設計了一種數據過濾策略。同時,還大大增強了后期處理過程(post-processing),設計了幾種不一致性消除的方法以及兩個有效的記錄更新算法。這些步驟都大大改進了計算效率和分類結果。另外,記錄更新算法還有兩個功能:一個是找到“正確”的記錄(擁有“真實”屬性值的記錄),另一個是為非監督學習找到一個好的匹配臨界值。
我們仍然使用F1(F度量中最常用的一種形式(Rijsbergen[6]))和AUC(Area Under precision-recall Curve)。實驗結果表明我們的方法對非監督學習和監督學習都能夠獲得高質量的實體識別結果。我們改進后的方法包含了狹義上實體識別的整個過程,并且其中的某些步驟是比較通用的,能夠應用到其他基于記錄對匹配的實體識別方法中。
對于較大的數據集或者是計算起來比較耗費時間的相似度度量,整個實體識別過程的運行時間可能會是一個問題。為了解決這個問題,一般會使用分塊(blocking)或者遮蔽(canopy)(Elmagarmid等[4],Sarka等[7])的方法來有效地選擇記錄對的一個子集來進行相似度計算,而簡單地忽略其他“不相似”的記錄對。在我們的研究中,我們設計了一個數據過濾方法,它和遮蔽有著類似的效果。
我們的方法和經典的FSM(Fellegi-Sunter Model)主要有兩點不同:首先,我們使用不同的概率匹配模型。FSM使用屬性值的模式,而我們的方法使用相似值的模式。其次,FSM只使用直接匹配,而我們的方法使用直接匹配、傳遞等價,以及斷言等價。此外,我們所改進的方法使用的間接相似度度量是基于上下文的,這就提供了進行關聯分析的好處,當然我們并不做直接的集體匹配決策。
1.3 主要貢獻
我們實體識別的研究工作的主要貢獻有:
●我們將原方法[5]擴展成了一個通用的框架;
●我們設計了兩個記錄更新算法來:改進分類結果,找到“正確”的記錄,以及為非監督學習找到好的匹配臨界值;
●我們設計了不一致性消除方法來消除匹配結果中的不一致性,同時提高匹配的精確度。
我們把實驗結果同幾個較新的實體識別方法(Sin?gla和Domingos[8]、Wick等[9],以及Rendle和Thieme[10])的結果進行了比較(使用F1和AUC)。對于相同的數據集,我們的方法總體上要優于其他方法。
2 方法框架

圖1 方法框架
我們的方法框架如圖1所示。在預處理步驟中,我們使用過濾來有效降低需要比較的記錄對的個數。接下來是匹配過程,我們對過濾后的每一對記錄對計算它們的相似度(對于非監督學習)或者相似度和等價概率(對于監督學習),以此來確定該記錄對是否是等價的。匹配過程經常會產生一些不一致的結果,所以我們設計了消除不一致性的方法,經過這一步,我們可以輸出關系集合(R),它是所有記錄對的關系(等價或者非等價)集合。在這一步后,我們還設計了記錄更新的算法。在記錄更新步驟中我們更新某些記錄的屬性值來提高識別的準確性,同時會輸出“真實”記錄集合(T)。此外,對于非監督學習,記錄更新步驟還能找到好的匹配臨界值。不一致性消除,記錄更新以及等價消除構成了我們框架中的后期處理過程。后期處理過程結束后,我們可以完成任務輸出結果,也可以回到預處理步驟重復整個過程。一般情況下一遍過程就可以獲得很好的結果。
3 實驗結果
3.1 實驗環境
所有實驗在一臺PC上進行,配置如下:
●CPU:AMD Phenom II 2.9G Hz;
●內存:3.25GB。
我們使用兩個公共的數據集Cora和CDDB。
Cora是一個科學出版物參考文獻信息的數據集。我們從Weis等[11]處下載此數據集。它包含了1878個引用,而這些引用實際上只對應139個研究論文。它是McCallum[12]提供的數據集的擴展的版本。Cora數據集中的記錄有五個屬性:標題、作者、出處、卷號,以及日期。我們在數據預處理步驟中對該數據集進行了一些清洗工作,去除了一些標點符號。如果某記錄的作者超過一個,我們把該記錄的每一個作者單獨作為一個作者屬性值。
CDDB數據集包含9763個從freeDB隨機抽取的音樂CD的信息。我們也是從Weis等[11]處下載此數據集。CDDB不像Cora數據集那樣有很多等價記錄,它的記錄對應9388個不同的音樂CD,所以等價的記錄只是一少部分。每個音樂CD記錄有七個屬性:藝術家、標題、分類、流派、年份、額外信息,以及音軌標題。類似的,我們把一條記錄的每一個藝術家單獨作為一個藝術家屬性值。
3.2 監督學習實驗結果
因篇幅所限,我們略去非監督學習的實驗結果。

表1 Cora數據集實驗結果
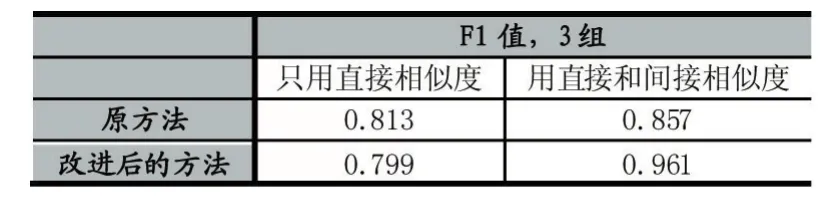
表2 CDDB數據集實驗結果
表1和表2中,3組和5組是指3組交叉驗證和5組交叉驗證。從表1和表2來看,我們改進后的方法比原方法除了一項結果有略微下降以外其他的都有明顯的提高。
4 有關研究工作
Chen等[13]提出了一種基于圖的實體識別方法。該方法分析由數據集構建的實體關系圖,并度量不同節點對之間的互聯度。
Dong等[14]考慮復雜的信息空間來解決引用關系重建的問題。該算法在決定合并兩個引用的時候,它會使用引用增強機制來利用上下文信息。他們的引用增強有一點類似與我們的記錄更新。不過我們的記錄更新是有一些限制的更新記錄,而不是合并。
Singla和Domingos[8]提出了一個基于馬爾科夫邏輯的集成的實體識別方法。馬爾卡夫邏輯結合了一階邏輯和概率圖模型。我們把同一個數據集上的實驗結果和他們的進行了比較。
Bhattacharya和Getoor[15]針對非監督學習實體識別擴展了隱含狄利克雷分布(Latent Dirichlet Allocation)模型,并且針對引用互相連接的關系領域的集體實體識別提出了一種概率模型。
Rendle和Thieme[10]提出了一個使用結構化信息的模型來進行集體的對象身份識別。我們把同一個數據集上的實驗結果和他們的進行了比較。
Cong等[16]研究了有效的方法來改進數據一致性和精確度。他們采用了一類條件的功能依賴(Bohannon等[17])來指定數據的一致性。他們設計了兩個算法來改進數據的一致性。
Chaudhuri等[18]觀察到某些情況下數據中額外的約束可被用來評估重復數據去除的質量。
Bilgic等[19]介紹了一個叫D-Dupe的交互工具。該工具結合了實體識別數據挖掘算法和網絡可視化來展現潛在的等價數據的協作上下文。
Arasu等[20]提出了一個在約束下的集體的重復實體引用去除的方法。該方法基于一個簡單的具有精確語義的說明性語言。
Wick等[9]提出了一種差異性學習模型來聯合進行引用識別和規范化(生成實體穩定表示的過程)。我們把同一個數據集上的實驗結果和他們的進行了比較。
斯坦福SERF項目組(Benjelloun等[21])開發了一個叫Swoosh的一般的實體識別方法。他們確定了四個屬性,如果這些屬性被匹配和合并函數滿足的話將會使得實體識別算法更加有效。他們為這些屬性的不同情形開發了不同的算法。他們并沒有研究這些匹配合并算法的內部細節,而是把它們視為被實體識別引擎調用的黑盒子。
更全面的實體識別方法概覽可以參考Elmagarmid等[4]以及 Winkler[22]。
5 結語
雖然我們已經在很大程度上改進了原來的方法,但是依然有很多改進的空間。方法中使用的直接相似性和間接相似性有圖形的解釋,但是它們還可以集成地更好。CDDB數據集的實驗結果比Cora要差一點,也是有改進的余地。盡管我們使用了數據過濾方法來大大降低候選記錄對的數量,對于非常大的數據集來說,成對的記錄匹配的效率依然可能會是一個問題。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
人大建設(2020年4期)2020-09-21 03:39:12
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
