基于直方統計特征的多特征組合航跡關聯
2019-04-04 01:33:10徐亞圣丁赤飚任文娟許光鑾
雷達學報 2019年1期
徐亞圣 丁赤飚 任文娟 許光鑾
①(中國科學院大學 北京 100049)
②(中國科學院電子學研究所 北京 100190)
③(中國科學院空間信息處理與應用系統技術重點實驗室 北京 100190)
④(微波成像技術重點實驗室 北京 100190)
1 引言
數據融合目前在各個領域有著廣泛地應用[1,2],分布式多傳感器融合系統是一種典型的多傳感器數據融合系統[3,4],具有魯棒性強、成本低的特點。航跡關聯方法的研究一直是分布式多傳感器融合系統中的一個熱點。航跡關聯就是確認多條來自不同傳感器的目標軌跡是否屬于同一目標,關聯后可以有效地降低數據的冗余,正確的關聯也是實現數據融合的前提。目前航跡關聯的方法可以分為兩大類,一類是基于統計的方法,另一類是基于模糊數學的方法。基于統計的方法主要是利用狀態估計的差作為統計量并建立統計假設,然后以設定的概率閾值來判定航跡是否關聯[4-6]。基于模糊數學的方法主要是選定或設計關聯隸屬度,通過計算兩兩航跡的關聯隸屬度來判斷航跡是否關聯[6-8]。這些方法主要存在以下問題:(1)對目標的航跡進行逐點比較,沒有從航跡整體的角度來考慮,忽視了航跡的全局性的特征;(2)基于統計的方法需要人工設定閾值和大量的調試,擴展性不強;(3)只考慮了隨機誤差,而忽視了其他誤差的影響。
針對上述問題,大量文獻對其進行了研究。文獻[9]將航跡的整體視為時間序列,使用動態時間規整(Dynamic Time Warping, DTW)來測量任意兩條航跡之間的相似度,從整體上考慮了航跡形狀的相似性。將DTW相似性引入航跡關聯當中,避免了在時域上進行配準,在一定程度上減小了誤差。文獻[10]將系統誤差引入到原始的傳感器量測中,構建了一種混合整數非線性規劃模型,并對系統誤差進行了估計,有效地提高了系統的性能。文獻[11]提出了一種具有自適應閾值的最大后驗概率(Maximum A Posteriori probability, MAP)關聯算法。該算法顯示,具有自適應閾值的算法性能優于固定閾值算法。
針對現有方法存在的需要人工設定閾值、參數設置復雜、只考慮單個航跡點以及航跡信息利用不充分的問題,本文提出了一種基于多特征組合的航跡關聯方法。首先從航跡的整體出發,在傳統歐式距離度量的基礎上,提出了一種距離分布直方圖的特征并提取了航跡的相似特征,有效地利用了航跡整體的特性,具有較好的抗噪聲性能以及關聯準確率。其次挖掘了航跡間的速度差分布直方圖特征、傳感器來源特征,然后將這些特征組合,考慮到目前機器學習方法強大的特征學習能力,能夠自動地學習特征中隱含的知識信息,且參數設置較為簡單,因此利用機器學習方法對挖掘的特征進行學習得到航跡關聯模型,從而有效地避免了需要人工設定閾值以及參數設置復雜的問題。最后通過實驗驗證了本文方法的有效性。
2 系統模型描述
船舶的航跡由一系列時空數據點(即經度、緯度、時間)組成,并且通過多種定位方式獲得,由于同一個目標可能會被多個源觀測到,因此在數據融合中心會出現一個目標的多條航跡觀測(對于多條觀測的情況,我們可以對觀測中的航跡兩兩進行關聯判斷,最后得到關聯結果),在系統中造成大量的數據冗余,在未判明目標時則會造成大量虛假目標信息,對后續的一些航跡知識挖掘任務,如目標識別、航跡融合造成很大的影響。
假設分布式多傳感系統中有M個傳感器,每個傳感器輸出的航跡數為ms,將其中任意一條的航跡數據即目標的狀態估計表示為sk,其中s=1,2,3,???,M,k=1,2,3,???,ms。目 標 的 狀 態估計sk可以表示成為時間序列(1維或者多維的),這里定義sk為如下的一個多維的時間序列:

其中,m表示航跡的長度,n表示屬性的維數。對于任意的兩條航跡數據(經過一定預處理后,在同一時間段里的兩條航跡數據)存在以下兩種假設H0和H1:

3 算法描述
3.1 特征挖掘
3.1.1 距離分布直方圖特征
距離是航跡間最基礎也是最直觀的特征,傳統的航跡間的距離特征有歐式距離、編輯距離以及其它描述航跡形狀相似度的距離等,傳統的歐式距離主要是計算航跡對應的距離和或者最大最小距離[12],且需要兩條航跡在時間上對齊,這些特征雖然簡單且能在一定程度上解決關聯的問題,但也有著十分明顯的缺點:(1)單一數值不能很好地反映航跡間的細節差異;(2)在關聯時需要人工設定閾值,依賴于人工經驗,且關聯準確率敏感于噪聲。
針對上述存在的問題,本文在歐式距離算法的基礎上,提出了一種基于距離分布直方圖特征(圖1)。特征描述如下:
經過一定預處理(按照4.1.2節中,第1部分所做的時間對齊和抽樣。3.1.2節及3.1.3節的特征提取也經過這樣的預處理),兩條時間上對齊(采樣點的時間相同)、航跡長度相同、特征維度為經度、緯度、時間的航跡
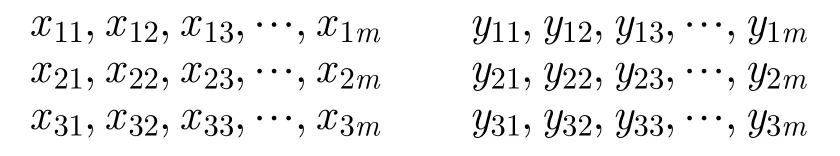
其中,m表示航跡的長度,設航跡的距離序列為

其中,di表示 和 第i個航跡點對應的距離。為了規范化處理,本文對距離序列 d istance取對數,得到:

3.1.2 動態時間規整(DTW)相似度特征
航跡作為一種時間序列,可以考慮將其相似度作為一種特征,而DTW是一種典型的用于計算時間序列相似度的算法,它廣泛應用于科學、醫學、工業、金融等領域,在人工智能領域使用得更為頻繁[13-22]。DTW定義了時間序列間的最佳匹配,它同時支持不同時間長度的相似度量,具有更好的魯棒性。DTW也從一定程度上反映了航跡間的形狀相似度。因此本文計算航跡間的DTW相似度,并將其作為一類特征。同上設有兩條航跡長度分別為m,n且m,n>1。特征維度為經度、緯度、時間的航跡

我們構建一個m×n的矩陣其中,dij為d(xi,yj),是兩條航跡兩個點xi和yj的距離。本文將距離定義為兩個經緯度點的實際距離,因此矩陣中的每個元素(i,j)表示的是兩個點的匹配程度。在矩陣中構建一條路徑表示航跡和的匹配程度:


圖1 距離分布直方圖特征計算示意圖Fig.1 Schematic diagram of feature calculation of distance distribution histogram
路徑 必須滿足以下3個條件:
(1) 邊界條件:w1=(1,1),wk=(m,n);
(2) 連續條件:給定wp=(ip,jp),wp+1=(ip+1,jp+1),有ip+1-ip≤1,jp+1-jp≤1;
(3) 單調條件:給定wp=(ip,jp),wp+1=(ip+1,jp+1),有ip+1-ip≥0,jp+1-jp≥0。
其中有多條路徑滿足上述的條件,取滿足以下條件的路徑:

為了計算式(4),需要構建一個累加距離矩陣,并且利用動態規劃的思想求解這個矩陣,遞歸如下:

初始條件為

最終得到的f(m,n)為航跡的DTW特征。圖2及圖3顯示了兩條航跡在DTW算法下的逐點對應關系。
3.1.3 其他特征
航跡間除了距離和DTW相似度兩種主要特征外,本文還提取了速度差分布直方圖特征以及航跡的來源特征,考慮到船舶的行駛速度較慢且傳感器的采樣頻率較高,本文假設任意兩個航跡點之間,船做的是勻速直線運動,從而可以得到每一個航跡點的速度,對于航跡 和,記航跡 和 的速度序列為
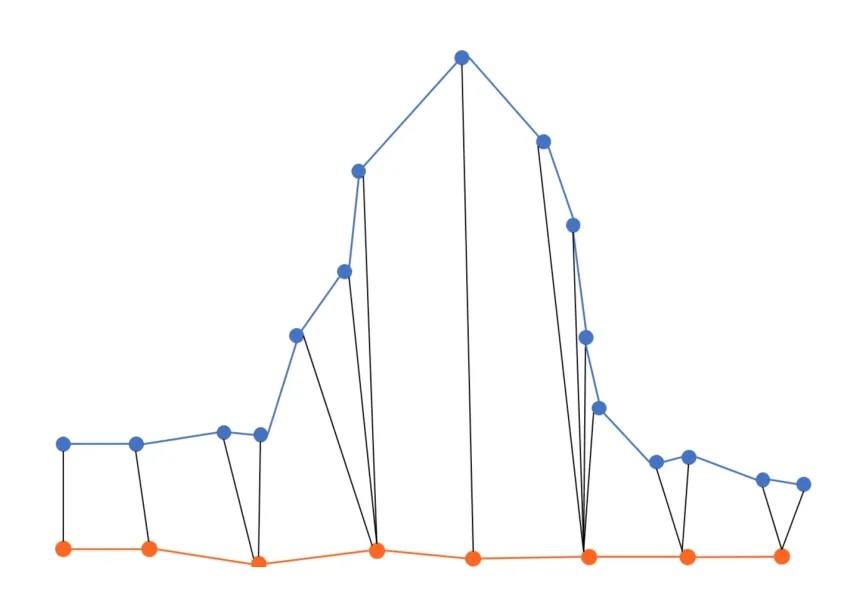
圖2 DTW航跡點對應關系Fig.2 Correspondence of DTW track points
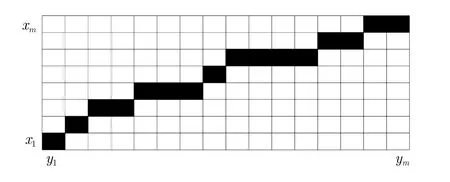
圖3 DTW算法匹配關系Fig.3 DTW algorithm matching relationship

其中:
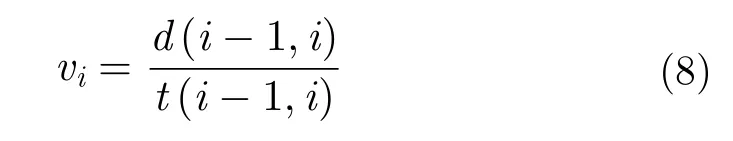
d(i-1,i) 表示的是第i個點與i-1個點的距離,t(i-1,i) 表示的是第i個點與i-1個點的時間差。
設:

為航跡X和Y的速度差序列,其中difvi表示 和第i個航跡點對應的速度的差。然后對做與d istance相同的后續處理得到速度差分布直方圖特征。
不同來源誤差往往不同,傳統的一些方法在進行仿真實驗的時候假定誤差服從高斯分布,而實際的誤差情況不僅有隨機誤差還有系統誤差的影響,同時不同來源的精度、特性也不相同,因此本文將不同數據來源量化為特征,結合機器學習的方法隱性地學習誤差信息從而在一定程度上更好地克服誤差影響。假設有n個不同的來源:

本文將其進行一定的編碼作為來源特征
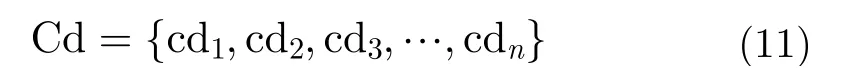
3.2 關聯流程
對任意兩條航跡數據提取距離、速度差分布直方圖特征、DTW相似度特征以及來源特征,并將這些特征進行組合。然后利用機器學習的模型來進行訓練和判斷。算法的流程圖如圖4所示。
4 實驗驗證
4.1 實驗數據集構建及預處理
4.1.1 數據集構建
傳統的一些方法實驗都是仿真數據上進行的,雖然為了接近真實的情況,在仿真數據上加入了噪聲等干擾,但大多數都是假定噪聲服從高斯分布,忽視其他誤差的影響,因此與實際的船舶航跡數據仍然有著較大的差距。本文構建了一個真實的船舶航跡數據集,船舶航跡數據集是1年多的船舶航跡數據,涵蓋了較多的航跡運動情況,數據集中每一個實驗樣本由兩條航跡組成,兩條航跡可能源于同一目標,也可能源于不同的目標。數據集的航跡樣本標注都是經過一定的歷史分析以及多個有經驗的判讀員檢驗標注的。因此數據集的標注具有較高的可靠性。本文一共標注了8063個航跡實驗樣本對,令兩條航跡源于同一目標的為正樣本,兩條航跡源于不同目標的為負樣本。其中正樣本數量為2522個、負樣本為5541個。

圖4 關聯流程圖Fig.4 Association flow chart
4.1.2 數據預處理
(1) 時間對齊和抽樣
一般情況下,各個傳感器采樣頻率上報間隔都不盡相同,因此會出現如圖5所示的情形。不同傳感器的采樣頻率往往不同,得到的航跡點的時間并不一一對應,如果直接計算距離會有較大的誤差,且不滿足計算距離分布直方圖特征的條件,因此需要對航跡進行插值,再在同一時刻進行采樣。
通過對航跡數據集中的數據(在本文構建的數據集里)進行分析后,發現傳感器的采樣頻率大多數在3~300 s,船舶行駛速率大多在11節左右(20 km/h)。因此本文假設船舶的兩個采樣點之間是做勻速直線運動,從而進行線性插值處理,此假設主要是為了減小直接計算非時間對齊航跡點的歐式距離時的較大誤差同時滿足距離分布直方圖特征的計算條件。線性插值采樣如圖6所示。同時為了更符合勻速直線運動的假設,本文將不對采樣間隔大于600 s的點做插值處理。
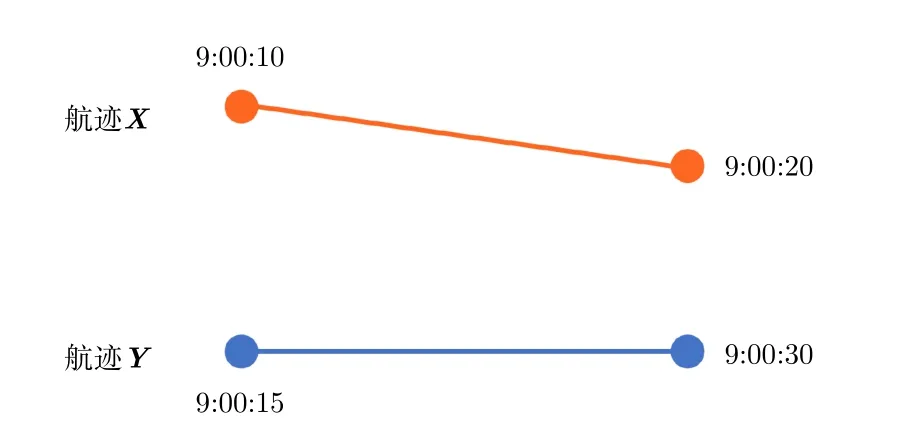
圖5 兩條航跡對應點時間不同示意圖Fig.5 Different timings of the corresponding points on the two tracks
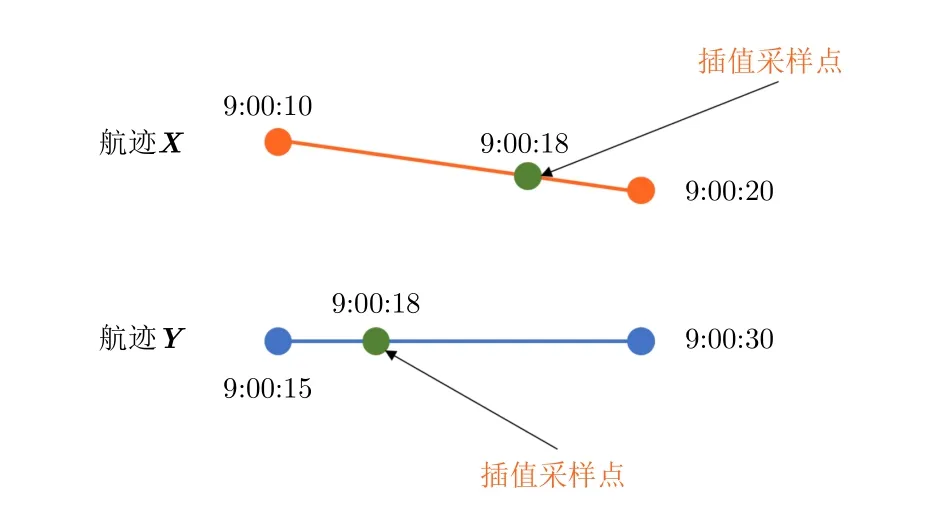
圖6 航跡線性插值采樣示意圖Fig.6 Linear interpolation sampling schematic diagram
(2) 樣本擴充
原始的可用樣本較少,正樣本數量僅為2522個、負樣本為5541個,通過對樣本的觀察發現:部分樣本的時間跨度較長且樣本點數極多(例如有些樣本航跡點數有3萬多個,時間長度超過20 h)。這樣的樣本可以對其進行拆分,拆分方式如圖7所示,本文將其拆分為時間長度為2~3 h的多個樣本以此來擴充樣本。

圖7 航跡樣本拆分示意圖Fig.7 Schematic diagram of separation of track samples
4.2 實驗結果分析
為了驗證算法的性能,本文首先比較了傳統方法提取的加權距離特征(加權航跡方法計算出的統計量特征)[23,24]、平均距離特征、最大距離特征在設定閾值與利用機器學習方法時性能的差異,其次比較了距離分布直方特征與傳統的平均距離特征、加權航跡特征、最大距離特征,之后對本文提出特征進行組合,比較組合特征和單一特征的性能,最后對比了不同的機器學習方法的性能。實驗數據集是經上述預處理后并隨機打亂后的船舶樣本集,其中80%的樣本用來訓練,20%的樣本用來測試。
4.2.1 評價指標
本文采用常用的機器學習評價指標[25],精度、查全率、查準率、F1度量、ROC (Receiver Operating Characteristic)曲線以及AUC (Area Under Curve)值,令兩條航跡源于同一目標的為正樣本,兩條航跡源于不同目標的為負樣本。則評價指標的具體定義如下:

ROC曲線根據學習器的預測結果對樣本進行排序,并且按照這個順序把樣本預測為正例,性能越好的模型,ROC曲線越接近于左上角。由于從圖形上無法直觀比較ROC曲線,因此可以通過計算ROC曲線下方的面積,即AUC值,來比較模型的好壞,一般來說AUC值越大則表示模型性能越好。
產業結構的區域差異性是制約我國經濟發展的重要因素,學術界關于我國產業結構區域特征的研究由來已久。中國產業結構的確存在區域差異性(Naughton,2003),但這種差異性在趨同作用下逐漸衰減且呈收斂特征(Poncet,2003)。三大產業的發展成本有所不同,其中第三產業的發展能降低加工成本和交易成本,有利于提高社會整體的經濟效率(吳敬璉,2014)。

表1 平均距離特征閾值方法與機器學習方法指標對比Tab.1 Comparison of average distance characteristics threshold method and machine learning method index

表2 加權距離特征閾值方法與機器學習方法指標對比Tab.2 Comparison of weighted distance characteristics threshold method and machine learning method index

表3 最大距離特征閾值方法與機器學習方法指標對比Tab.3 Comparison of maximum distance characteristics threshold method and machine learning method index
4.2.2 閾值方法與機器學習方法對比實驗
傳統的方法閾值設置大多根據統計以及設計者經驗來決定[26],其中一些方法還依賴于系統的參數[4,27],本文根據真實數據集的情況,利用了3種數據的統計值作為閾值來與機器學習方法進行比較,它們分別是精度最高閾值、平均數閾值以及中位數閾值。精度最高閾值:也是一般常用的閾值設置方法[4],在特征域值范圍內的值,通過一定的步長設置尋找最佳精度閾值;平均數閾值和中位數閾值主要是利用特征的統計特性[28],本文對3種特征分別求得它們平均數與中位數作為閾值,具體的閾值與實驗結果如表1~表3所示。機器學習模型則選較為常用的樹模型,從表1~表3中可以看出,機器學習的方法則能夠更好學習特征表示的含義,具有更強的泛化能力,因此關鍵指標均遠高于設定閾值的方法,且不需要人工設定閾值(精度最高閾值需要大量的實驗才能確定),進而說明了引入機器學習方法的有效性。
4.2.3 距離分布直方圖特征與傳統特征對比實驗
表4是利用樹模型學習不同特征的各項指標,圖8描述了不同特征的ROC曲線圖。從表4以及圖8可以看出本文提出的距離分布直方圖特征的性能優于傳統的距離特征。主要原因是距離分布直方圖特征從航跡的整體出發,更好地考慮了整體的距離分布。圖9是傳統距離特征無法識別而距離分布直方圖特征能識別的關聯目標,圖中紅色和藍色分別代表了不同來源觀測的同一目標的航跡。從圖中可以看出,傳統的距離特征由于是單一數值描述,對有噪聲干擾的目標不能準確關聯,而距離分布直方圖特征考慮的是整體的距離分布,因此具有較好的抗噪性能。圖10是距離分布直方圖特征關聯失敗的典型情況,圖10(a)和圖10(b)是兩條航跡源于同一目標,圖10(c)為兩條航跡源于不同目標。從圖10(a)和圖10(b)中可以直觀地看出,其受噪聲干擾較為嚴重,而圖10(c)兩條航跡十分接近,通過對它們特征的可視化分析發現,圖10(a)、圖10(b)距離整體分布呈現較大差異,此時距離分布直方圖特征難以有效地關聯圖10(a)、圖10(b)所示的情況。圖10(c)的距離整體分布十分接近,但速度整體分布差異較大,單一的距離分布直方圖特征在這種情況難以正確完成關聯判斷。

表4 不同特征指標對比Tab.4 Comparison of different characteristics

圖8 不同方法ROC曲線Fig.8 Different methods of ROC curves

圖9 傳統距離特征無法識別而距離分布直方圖能夠識別的目標Fig.9 The targets that can’t be identified by traditional distance feature but can be identified by distance distribution histogram

圖10 距離分布直方圖特征關聯失敗的目標Fig.10 The targets of distance distribution histogram feature error association

表5 組合特征指標對比Tab.5 Comparison of composite features

圖11 特征組合ROC曲線Fig.11 Feature combination ROC curve
4.2.4 組合特征對比實驗
表5是利用樹模型學習不同組合特征的各項指標,圖11描述了不同組合特征的ROC曲線圖,表5以及圖11中,DDH (Distance Distribution Histogram)表示的是距離分布直方圖特征,SDDH (Speed Difference Distribution Histogram)表示的速度差分布直方圖特征。圖12給出了單一特征錯誤關聯而組合特征正確識別情況(圖10(c)在加入速度差分布直方圖特征后能夠準確地判斷其為不同的目標),圖12(a)是DDH特征錯誤關聯的目標而加入DTW相似度特征準確識別的情形,主要原因是兩條航跡的距離較近,在距離維度上很難區分,而其DTW相似度差異較大(DTW相似度在一定程度上描述了航跡形狀上的相似度)。圖12(b)是DDH+DTW特征錯誤關聯的目標而加入速度差分布直方圖特征準確識別的情形,主要原因是兩條航跡的距離較近,DTW相似度也較高,而其有12.5%的航跡點速度相差5節航速,速度差分布差異較大。圖12(c)是DDH+DTW+SDDH特征錯誤關聯而加入來源特征準確識別的情形,主要原因是兩條航跡的距離較近,DTW相似度也高,速度差分布也相近,但兩條航跡來自同一觀測源,因此判定不是同一目標。圖13是距離分布直方圖特征關聯失敗的典型情況,圖13(a)和圖13(b)是兩條航跡源于同一目標,圖13(c)為兩條航跡源于不同目標。從圖13(a)、圖13(b)中可以直觀地看出,其受噪聲干擾較為嚴重,而圖13(c)兩條航跡十分接近,通過對它們特征的可視化分析發現,圖13(a)和圖13(b)的距離、速度整體分布以及DTW相似度呈現較大差異,此時組合特征難以有效地關聯圖13(a)和圖13(b)所示的情況。圖13(c)的目標十分接近,且幾乎沒有移動,因此各項特征十分接近,組合特征在這種情況難以正確完成關聯判斷。綜上分析以及從表5和圖11中可以看出,每增加一組特征,模型的各項指標都有所提升,不僅說明了所提特征的有效性,而且由于不同特征之間具有一定的互補性,多種特征的組合能夠更加全面地表征航跡間的關系,進一步提升航跡關聯準確性。在噪聲干擾較大時航跡間的特征也受到了較大的干擾,此時很難有效地進行關聯判定,同時由于目前航跡點信息有限,可以挖掘的特征有限,因此在一些較為特殊的情況下當前組合特征不能準確地完成關聯判斷。
4.2.5 不同機器學習方法對比實驗

圖13 組合特征關聯失敗的目標Fig.13 The targets of combination features error association

表6 不同機器學習方法指標對比Tab.6 Comparison of different machine learning indicators

圖14 不同機器學習方法ROC曲線Fig.14 ROC curves for different machine learning methods
5 結論
針對傳統航跡關聯方法存在需要人工設定閾值、參數設置復雜的問題,本文將機器學習的方法引入航跡關聯中,針對一些傳統方法只考慮航跡單個點的信息及抗噪聲性能較差的問題,本文從航跡的整體出發,提出了一種距離分布直方圖特征。與此同時對航跡的特征進行挖掘,提取了航跡間的DTW相似度特征、速度差分布直方圖特征以及來源特征,結合機器學習的方法提出了一種基于多特征組合的航跡關聯方法,該方法在有限的航跡點信息中挖掘了多種有效的特征信息,獲得了較高的關聯準確率,并且在實際應用中取得較好的效果,隨著樣本和航跡點信息不斷增多,關聯模型的準確率以及泛化性能還將進一步提升。理論分析和實驗結果均表明該方法的有效性和合理性。根據算法設計中各環節的假設和約束,本文目前提出的航跡關聯算法主要適用于傳感器采樣頻率較高,運動目標速度較慢(船舶、汽車、行人等)的情況,對于高速運動的目標則需要進一步地分析其運動情況,建立更加精細的插值模型,這也是本文后續工作中的一個重要的研究方面。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
學苑創造·A版(2018年11期)2018-02-01 06:29:20
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
讀者(2017年5期)2017-02-15 18:04:18
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
河南科技(2014年23期)2014-02-27 14:19:15
