基于學生教育數據的關系預測與發現
2019-04-08 00:46:38李曉偉
現代計算機 2019年6期
李曉偉
(四川大學計算機學院,成都610065)
0 引言
隨著數據科學定義的提出,機器學習、數據挖掘[1]、數據可視化等概念變得越來越流行,與學生相關的網絡服務乘著移動互聯網的東風迅猛發展,成為了最受歡迎、用戶最多的服務之一。越來越多的互聯網廠商和計算機科學研究人員開始將數據科學和社會網絡結合起來,依托龐大的用戶所產生的數據進行行為分析,為用戶提供個性化服務。學生每天會進行消費刷卡,會上課學習,這些行為等會產生許多的數據。基于大學生的消費數據和成績數據,可以分析出一些大學生生活和學習方面的規律。例如,大學生的消費習慣是否和成績相關,來自同一生源地的學生是否會喜歡在同一家餐廳吃飯,不同性別的學生的選課習慣是否不同。
本文使用某院校一個學院一個年級的成績數據和學生卡消費數據,使用決策樹(Decision Tree)和支持向量機(Support Vector Machine,SVM)兩種算法預測好友關系,采用了隨機采樣大類平衡小類的方法解決數據不平衡的問題。并使用調查問卷的形式獲取學生真實好友關系,進行真實數據驗證,使用的好友關系預測方法的精確率(Precision)、召回率(Recall)和 F1分數(F1 Score)均較高,達到了預測效果,后期使用可視化工具進行好友關系分析。
綜上所述,本文的貢獻主要分為以下幾點:
(1)提取特征進行預測性分析。根據算法的需要從源數據中選擇能夠被用來預測好友關系的大學生行為特征;
(2)通過編寫Python程序挖掘和清洗數據,通過RapidMiner等數據挖掘工具進行算法選擇和測試;
(3)使用決策樹和SVM兩種算法訓練和測試數據集,通過數據調整提高精確率和召回率;
(4)通過調查問卷獲取大學生真實好友關系以及交友情況,驗證實驗預測結果;
(5)使用 D3.js、ECharts、Matplotlib等可視化工具實現可視化模型并進行分析。
1 關系預測
1.1 數據來源與數據處理
本文使用的數據集為大學生校園卡、校園網、教務網等系統所產生的教育數據。所有數據都經過加密算法處理,將學生相關信息匿名化。這些數據遍布各個學院和各個年級,文件數量眾多,數據量龐大,使得數據具有代表性和普適性。為了保證數據真實性的可驗證性,選取了某院校一個學院一個年級所有學生2014年全年消費數據和2013年至今的成績數據進行實驗。
數據處理是機器學習預測算法進行預測之前非常重要的一步。它包含數據預處理和數據整合與清洗兩個關鍵步驟。數據預處理是要提取出消費數據中的兩名學生刷卡重疊次數和成績數據中的兩名學生選修課重疊次數。數據整合與清洗是要將數據集中所有學生兩兩配對,將兩名學生學籍相關信息(學號、姓名、性別、生源地等)和數據預處理步驟中提取出的學生刷卡重疊次數和選修課重疊次數整合,并對缺失數據、非常規數據進行清洗。
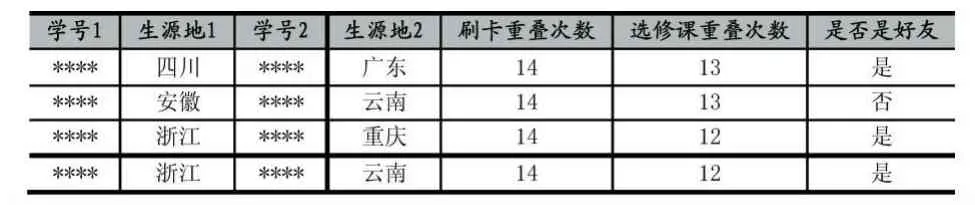
表1 部分整合后的數據表
1.2 預測算法
針對不同的分類問題需要選擇不同機器學習算法。例如,樸素貝葉斯這樣的高偏差低方差型分類算法,適用于樣本數量較少的小訓練集。但是隨著數據量的增大,KNN這樣的低偏差高方差分類算法將具有優勢。RapidMiner是現如今數據挖掘和預測分析領域最流行的解決方案之一[2]。它可以不通過編程完成機器學習預測的工作,內置多種算法,選擇數據集后可以立刻可以進行算法測試。本文選用RapidMiner對算法進行測試和選擇,測試了樸素貝葉斯、KNN、決策樹、SVM四種方法。最終考慮到預測的精確率和召回率,以及選擇不同表現類型的算法的需求,選擇了決策樹和SVM兩種算法進行預測,前者可以毫無壓力地展示特征間的關系,后者能夠十分良好地避免過擬合問題。
決策樹算法采取通過 Python的NumPy、Scipy、Sklearn等模塊進行實現[3],再自行配置和優化的方案。由于數據集存在不均勻的正負樣本分布的情況,也就是說,好友對數作為正類,非好友對數作為負類,樣本數量差距大。引入了糾偏數對大類(負類)進行隨機選擇和抽樣處理,以平衡兩者的比例差距。程序包括數據讀入、標簽轉換、拆分訓練集與測試集、選擇劃分標準、剪枝、訓練、畫決策樹、測試、打印結果幾個部分。數據讀入是把整合后的數據讀入,存儲特征和標簽到x、y矩陣中;標簽轉換是把“是否是好友”中的“是”與“否”標簽轉換為Sklearn能夠處理的“1”與“0”;拆分訓練集與測試集是將讀入的數據以二八比例拆分為訓練集(80%)和測試集(20%)。選擇劃分標準時,選擇信息增益作為劃分標準,Sklearn的決策樹采用CART算法,經過這樣的配置后,相當于實現了ID3算法;剪枝的目的是避免決策樹生長的節點過多導致過擬合問題;訓練后生成模型,并以圖片的形式導出決策樹到PDF;測試后,打印出詳細的精確率、召回率,決策樹預測結果如表2所示。
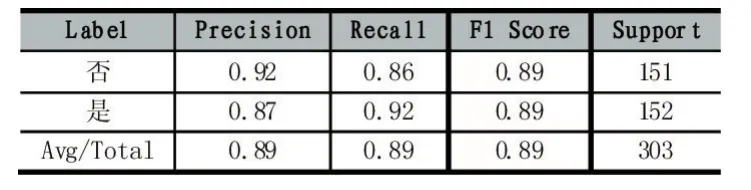
表2 決策樹算法測試結果示例
其中,Label為標簽值,即是否是好友分類的類別。Support為測試集中真實的正負樣本數量,Avg/Total為精確率、召回率、F1分數的平均值和真實測試樣本數量的總數。在所有評估指標中,隨機一次測試的數值都是高于85%的,這充分說明決策樹算法對本課題數據預測的有效性。
SVM算法的實現與決策樹算法類似,不過加入了Matplotlib模塊進行繪圖,另外程序不包括選擇劃分標準、剪枝、訓練、畫決策樹部分,但是加入了SVM核函數選擇和作圖的部分。選擇了包括線性核函數、多項式核函數、徑向基核函數、Sigmoid核函數這四種常用的核函數[4]。在圖1中,每張小圖的橫坐標為刷卡重疊次數,縱坐標為選修課重疊次數。藍色部分劃分為非好友,棕色部分劃分為好友,一個小圓對應一條記錄。我們可以明顯地觀察到Sigmoid核函數的分界存在較大問題,線性核函數和多項式核函數分界較好,但徑向基核函數分界最佳,如表3所示,隨機一次測試的所有平均評估指標數值都是高于85%的。
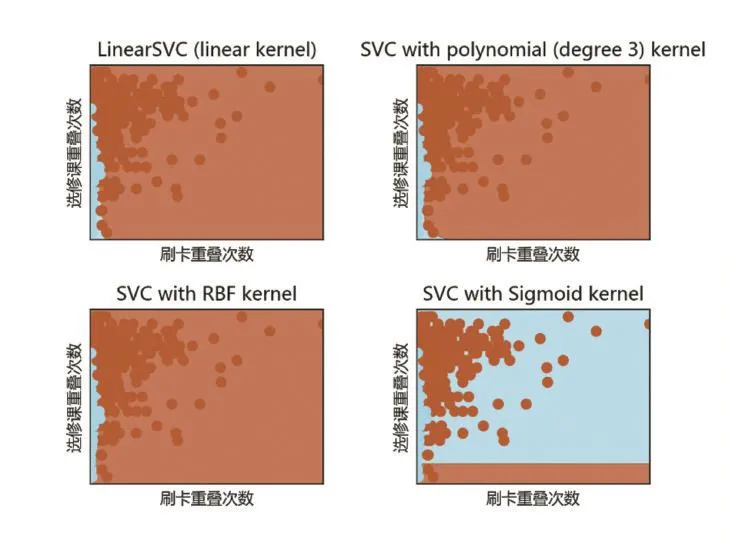
圖1 SVM核函數測試圖
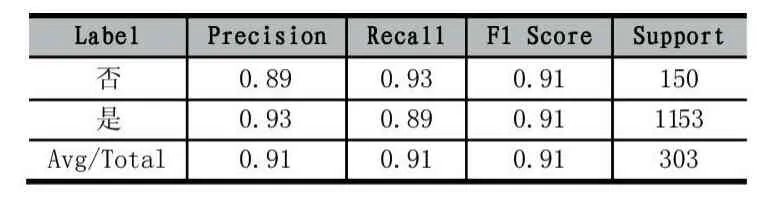
表3 徑向基核函數測試結果示例
2 學生關系可視化
通過實驗,完成了力引導關系圖和環狀關系圖這兩種關系圖。組織并可視化了大學生之間的社會關系,呈現不同人群的信息,為了解不同的人群提供了快速瀏覽交互,如圖2和圖3所示,其中圖2左下圖為鼠標放于節點上,右下圖為鼠標放于兩節點的連線上,圖3右圖為鼠標放于節點上。圖中的每個節點以學號代表了一個學生。通過多次可視化數據分析,賦予不同社會關系一定權重的策略,能夠發現力引導關系圖中節點的分布較為緊密。具有好友關系的人,同時會具有同性、老鄉、同專業同學、同班同學的社會關系,呈明顯的正相關性。而是否是同年出生對是否是好友幾乎無影響。這一結論在環狀關系圖中同樣可以得到驗證。根據結論逆向分析,如果兩個大學生都是女性,那么她們在寢室等地方接觸的機會將更多,也更容易選擇瑜伽這樣女性學生較多的課程;如果兩個大學生是老鄉,那么他們能夠用方言交流,飲食和生活習慣類似,對于家鄉的感情也會讓他們更可能在老鄉會等組織相遇;同專業同學、同班同學長期一起學習,接觸時間多;結合上述分析,具有這一類社會關系的人都會更可能成為好友。而同是年級相同或相近的大學生,是否年齡相近不會成為好友關系的阻礙。因此,從關系圖中得出的結論,符合社會習慣。
3 結語
隨著數據科學的流行和發展,大數據相關業務積累了足夠的信息量,如何借助機器學習和數據可視化挖掘這些數據,增強用戶個性化服務效果,已經越發受到信息技術學術界和工業界的重視。本文預測大學生可能存在的好友關系,結合可視化分析,對社會關系的影響因素進行發現。本文對多種機器學習算法進行比較,選擇了決策樹算法和以徑向基函數作為核函數的SVM算法進行實現。之后將預測預處理的數據和預測結果相關的數據和網絡爬蟲抓取的生源地省份經緯度等數據整合,繪制了好友關系圖,交互式分析數據。機器學習預測的平均精確率、召回率、F1分數等指標均高于85%,預測結果的可信度較高。最后,通過可視化分析,得出了好友關系與是否是同性、是否是老鄉、是否是同專業或同班同學存在一定聯系,并且是否是老鄉這一特征的權重較大的結論。

圖2 力引導關系圖

圖3 環狀關系圖
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
