深度哈希卷積網絡在圖像檢索中的應用
2019-04-16 07:56:02王華秋
重慶理工大學學報(自然科學) 2019年3期
王華秋,郎 帥
(1.重慶理工大學 兩江人工智能學院, 重慶 401135;2.重慶理工大學 計算機科學與工程學院, 重慶 400054)
針對互聯網上圖像和視頻數據的爆炸式增長,大規模的視覺搜索已經在人工智能[1]和計算機視覺[2]中得到廣泛應用。考慮到用戶對快速檢索的需求,對于大規模圖像資源,有必要探索圖像檢索的方法,其目標是在查詢圖像中返回包含同一類的圖像。哈希方法作為近似最近鄰(ANN)尋找方法,對于大規模圖像檢索十分有效,本文著重研究用于大規模圖像檢索的哈希函數。
因查詢速度快和存儲成本低,目前已有各種哈希方法用于生成圖像的緊致二進制碼[3-8]。利用異或運算計算漢明距離,將高壓縮的數據加載到主存儲器,使得緊致二進制碼的相似性搜索得以快速實現。現有的哈希方法分為數據獨立和數據相關兩類。數據獨立的哈希方法通常使用隨機映射生成二進制碼,例如位置敏感哈希(locality-sensitive hashing,LSH)[3],而數據相關的哈希方法通過從盡可能多地保留數據結構中學習哈希函數。數據相關方法根據是否有監督信息大致分為兩組:無監督[3,5,9-11]和監督[6-7,12-14]。由于二進制碼的優質性,本文著重研究監督圖像的哈希方法。
大多數現有哈希方法的性能取決于所使用的視覺特征。傳統上,圖像通常由人工設計視覺特征描述,如Gist、HoG、LBP等。然而這些人工設計視覺特征有時不能很好地揭示圖像的表達信息,限制了圖像檢索的性能。因此,提出了一些基于其他特征的哈希方法[8,15-18],例如卷積神經網絡(CNN)提取特征。文獻[8]首先根據訓練圖像上的成對相似性學習二進制碼,然后根據哈希碼學習哈希函數和圖像表示。深度哈希通過最小化二進制碼與深層網絡的輸出特征之間的量化誤差來生成哈希碼[15]。深度監督哈希方法學習緊湊二進制學習代碼,以便對大規模數據進行高效的圖像檢索[18]。
鑒于卷積神經網絡具備良好的學習能力,本文利用神經網絡提取圖像特征來提高圖像檢索的性能。
1 相關工作
目前學習型的哈希法大致分為以下兩種:無監督哈希和監督哈希。
無監督的方法是指僅利用沒有標簽的圖像來學習哈希函數。該類別的主要策略包括:隨機映射[3],量化誤差最小化[5],重建誤差最小化[9]和基于圖的哈希[10]。文獻[11]進一步探索了無監督哈希學習的底層共享結構。
監督方法是指利用標簽信息學習更緊致和區分性的哈希碼。Liu等[6]提出了基于內核的一種哈希方法(KSH),最小化類內差距同時最大化類別間差距。Kulis等[7]提出了通過最小化輸入與其對應的哈希碼之間的平方誤差來學習哈希函數。Heo等[12]提出了基于超球面的一種哈希方法,將原始空間分為球體內部和外部兩部分。
上述人工設計視覺特征方法限制了圖像檢索的性能。近年來,深度視覺特征在各種視覺任務中取得了優異的表現,目前一些深度哈希方法[8,15-21]已被提出。特征學習對于圖像檢索十分重要,一個框架中可以同時學習特征和哈希函數。Xia等[8]建議分兩個階段學習哈希函數。首先,通過對基于圖像標簽獲得的相似性矩陣進行因式分解學習二進制碼。然后,基于二進制碼和圖像標簽學習哈希函數和神經網絡。由于矩陣分解會占用大量存儲而不能處理大規模圖像,文獻[15]提出了最小化實值特征與其相應二進制碼之間的量化誤差的方法。在文獻[19]中,保留成對相似性以同時執行特征學習和哈希學習。Lin等[21]在CNN中引入了潛層,用于學習圖像表示和一組哈希函數。在文獻[22]中,保留成對相似性以同時執行特征學習和哈希學習。
與上述不同,本文利用圖像的標簽信息提出了一種單階段的方法。利用深度網絡的模型來預測圖像標簽,同時生成二進制碼。分類誤差和量化誤差用于得到更好的特征表示。
2 本文方法
本文提出了用于圖像檢索的方法,該方法是在統一的框架中最小化分類誤差和量化誤差的深度哈希。深度神經網絡框架如圖1所示。本文利用深度神經網絡尋求多層次非線性變換以獲得圖像的特征表示。本文中深度神經網絡的最后是兩個全連接層,最后一層有k個節點,其中k是所需哈希位的長度。最后一層預測圖像的標簽并生成哈希碼。分類誤差和量化誤差共同調整神經網絡。所提出的方法可以學習哈希函數,該哈希函數根據標簽信息為具有相同或相似語義內容的圖像生成相同或相似的二進制碼。在MNIST和CIFAR-10兩個圖像集上的實驗表明:本文提出的方法在圖像檢索性能上優于其他幾種主流方法。
本文的目標是學習圖像的緊致二進制碼,學習到的深度網絡表示可以很好地預測圖像的標簽,還可以直接計算二進制碼。因此,所得的二進制碼能夠保持圖像的標簽語義信息,使得二進制碼在圖像檢索中具有緊致性和區分性。
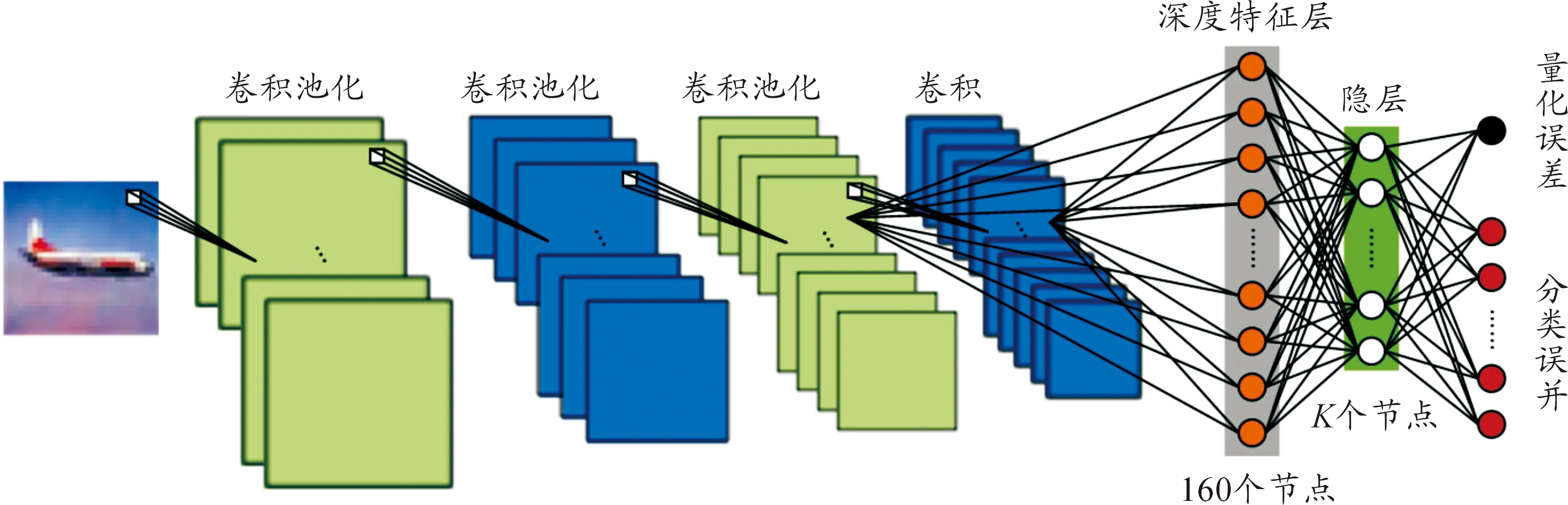
圖1 深度卷積神經網的框架
2.1 深度哈希函數
受深度學習在物體識別和圖像檢索等各種視覺任務中優秀表現的啟發,本文通過探索深層架構提出了深度哈希學習框架。為簡便,本文直接利用具有強大特征提取能力的卷積神經網絡(CNN)。如圖1所示,所利用的深層網絡有4個帶著最大池化的卷積層分層提取特征,然后是兩個全連接的層:深度特征層和隱層。由于第4層比第3層提取的特征更全面,深度特征層全連接到第3個卷積后的池化層和第4個卷積層以獲得多尺度特征。
考慮由N個圖像表示的訓練集X=[x1,x2,…,xN]∈Rm×N,給定xi∈Rm是第i個訓練圖像,m是描述特征的維度,設Y=[y1,y2,…,yN]∈RC×N表示訓練圖像的標簽矩陣,C表示類別的數量。如果第i個圖像屬于第j個類別,則Yij=1,否則為0。基于學習的哈希方法旨在學習哈希函數為每個圖像生成緊致的二進制向量。即學習哈希函數:X→B∈{0,1}K×N,其中,K是所需二進制碼的位數。
為了學習哈希函數,將隱層H的輸出特征再量化為所需的離散值。因此,隱層H上的節點數被設置為k,其中k是所需哈希位的長度。假設深度特征層得到的圖像特征pi∈R1×n表示輸出n維向量,隱層H表示為
fi(pi)=Wipi,i=1,2,…,k
(1)
其中,Wi∈Rn×k為H層的權重矩陣。
在隱層用Sigmoid激活函數,將數據映射到(0,1)的范圍內,表示為
(2)
其中zi=fi(pi)。
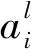
hi=(z1,z2,…zi)T,i=1,2,…,k
(3)
預測的哈希位可以通過以下函數得到:
(4)
其中sign(*)是對向量或矩陣的逐元操作。
2.2 損失函數的定義
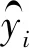
(5)
其中hi是所提出的深度神經網絡對第i個圖像的學習表示。
分類的損失函數可表示為
(6)
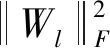
(7)
其中Iij是一個指標變量,如果Yij=1則Iij=1,否則為0。
為了得到二進制碼,本文使用符號函數將實值特征量化為二進制碼。為了形式化量化誤差,用H和B表示隱層的輸出和預測的二進制矩陣。理想的二進制矩陣可以通過B=sign(H)計算。由于上述等式過于理想,一般不成立,因此本文提出通過H和B之間的差異來學習B,使學習的二進制矩陣B和實值矩陣H之間的量化損失最小:
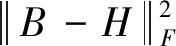
(8)
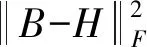
通過對隱層的輸出加以上述約束,預期學習的實際值H能很快接近1或0。理論上,它能夠在量化之前降低那些實際值約0.5的錯誤分類率,提高圖像檢索性能。
為了學習有判別的哈希函數,本文研究了上述兩個方面,并把學習特征、哈希函數及分類放入統一的框架中。本文的整體損失函數如下:
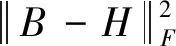
(9)
其中:γ是控制量化的重要參數;β是控制正則化的權重。將式(9)表示如下:
(10)
為了學習所提出的模型,本文采用子梯度下降法為局部最優解設計迭代優化算法,給出了J關于WH的梯度公式:
(11)
(12)
其中η是學習率。神經網絡的參數可以根據文獻[15]計算并更新。
在訓練階段,不必使用其他任何預訓練的網絡,直接使用隨機梯度下降訓練小批量大小為50的網絡。一旦學習了所提出的網絡,就可以通過量化隱層H處特征表示得到新圖像的哈希碼。
2.3 網絡架構及初始化方案
所用網絡有4個卷積層和3個最大池化層及2個全連接的層(深度特征層和隱層)。為了實現所提出的方法,設置這些層的大小,本文所用的神經網絡的設置見表1。
根據深度學習的教程對所用的網絡權重參數進行初始化。隱藏層權重的初值依賴于在激活函數對稱區間上的均勻采樣結果。
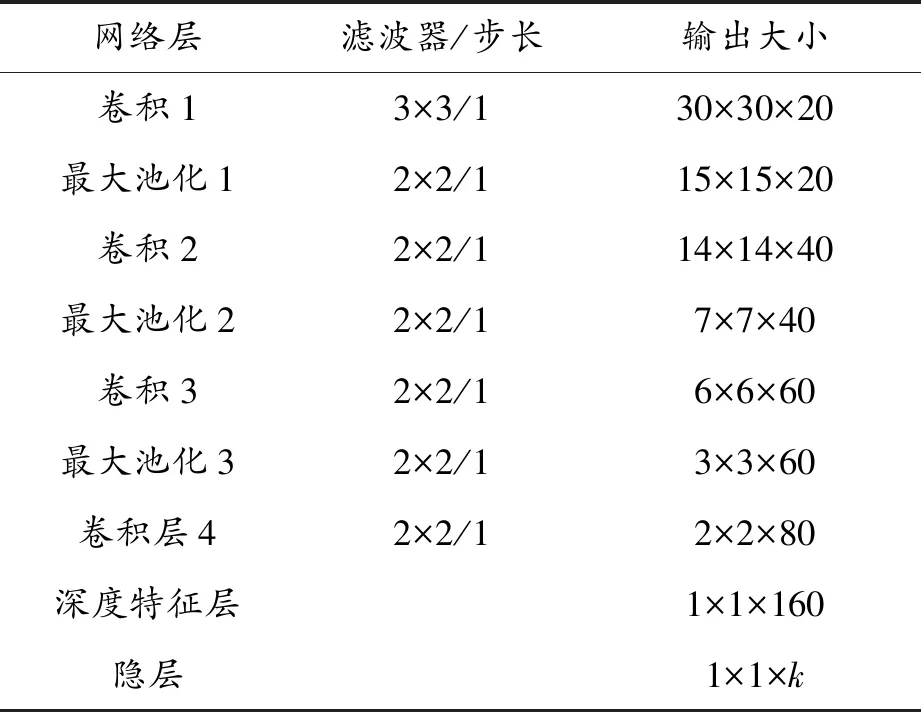
表1 提出的神經網絡中的層的大小
3 實驗結果分析與應用
為驗證所提出方法的有效性,在MNIST和CIFAR-10兩個圖像集上模擬實驗。MNIST圖像集包含了70 000張大小為28×28的灰度圖像,由0~9組成的10類手寫體數字。其中包含了60 000張手寫體訓練圖像集和10 000張手寫體測試圖像集。CIFAR-10圖像集包含了60 000張大小為32×32的彩色圖像,由車、馬等組成的10個分類。從每個類別中隨機選取5 000張圖像作為訓練集和1 000張圖像作為測試集。
3.1 實驗設置
實驗環境:64位Windows10系統,內存12 G,主頻2.50 GHz,Intel(R) Core(TM)i7-6500U CPU處理器,開發軟件為Matlab 2016b。
為了評估所提出方法的檢索性能,實驗對比其他幾種主流哈希方法。例如,無監督的哈希方法:LSH[3](隨機生成位置敏感的哈希函數),SH[4](通過將原空間中的相似性保持到漢明空間中的相似性來學習哈希函數),ITQ[5](最小化數據映射到二進制值的量化誤差,生成表達能力很強的哈希碼);監督的哈希方法:KSH[6](監督核哈希模型,通過最小化相似對上的漢明距離,同時最大化不同對上的漢明距離來學習哈希函數),BRE[7](通過最小化輸入距離和重構漢明距離之間的誤差的平方損失來構造哈希),以及利用深度學習與哈希技術相結合的哈希方法CNNH[8](首先是從訓練圖像上成對的相似性來學習哈希碼,然后根據學到的哈希碼學習哈希函數)。
對于淺層學習方法LSH、SH、ITQ、KSH、BRE,在MNIST和CIFAR-10兩個圖像集上的每個圖像分別由512維GIST特征向量表示。對于深度學習的方法CNNH和所提出的方法,直接使用原始圖像像素來描述視覺內容。
本文采用漢明排序和哈希查找。漢明排序是指計算查詢與數據庫中的圖像之間的漢明距離,然后根據漢明距離從列表的頂部返回圖像。哈希查找是指查找表在查詢圖像的小漢明半徑r內的圖像集。依據返回圖像和查詢圖像是否有相同的標簽信息評估檢索性能結果。在漢明排序中,計算前M個返回圖像的準確率。在哈希查找中,設置r=2,假如沒有返回圖像,那么相應的準確率為零。此外,平均查準率(MAP)用于評價檢索方法的整體性能指標。本文根據每個測試查詢圖像的漢明距離對所有圖像進行排序,從中選取前M個圖像作為檢索結果,然后計算所有測試圖像的MAP值。為了能更好地展示所提出方法在圖像檢索上是可行有效的,給出了在不同位數下top-k的檢索準確率、查準-查全率(P-R)和不同位數下漢明距離小于2的準確率上的檢索性能比較結果。常用如下公式:
(13)

(14)

(15)
所有比較方法中,有一些超參數需要提前設置。本文采用交叉驗證方法調整和選擇超參數。本文中的超參數β和γ在MNIST和CIFAR-10兩個圖像集中都設置為β=γ=10-3,學習率η設置為0.005。
3.2 實驗結果與分析
首先,通過實驗從前M個圖像的MAP來評價比較方法在圖像檢索中的整體性能。對MNIST和CIFAR-10兩個圖像集,M設置為1 000,哈希碼的長度設置為12、32和48。從表2、3給出的不同方法的MAP值的結果可以看出:與其他幾種主流方法相比,本文方法具有顯著優勢,采用標簽信息的監督方法優于無監督方法。與淺層哈希方法相比,具有良好表示能力的深層架構的CNNH和本文方法表現較好,顯示了深層特征的優點,與現有的研究結果一致。最后,與CNNH相比,由于本文方法考慮了分類誤差和量化誤差,MAP值明顯更高。特別地,在CIFAR-10數據集中MAP比CNNH方法提高了15%左右。獨特的框架帶來了大的改進,包括特征學習,哈希函數學習和分類同時進行,這3項任務可以相互促進,以改善結果。以上結果證實了所提出方法的有效性。
圖2、3分別給出了在MNIST和CIFAR-10數據集上的其他檢索性能比較曲線,得出與表2、3類似的結論。本文方法明顯優于其他幾種主流哈希方法,這是因為所提出的方法同時考慮了最小化的分類誤差和量化誤差,學習到的哈希碼具有判別力。
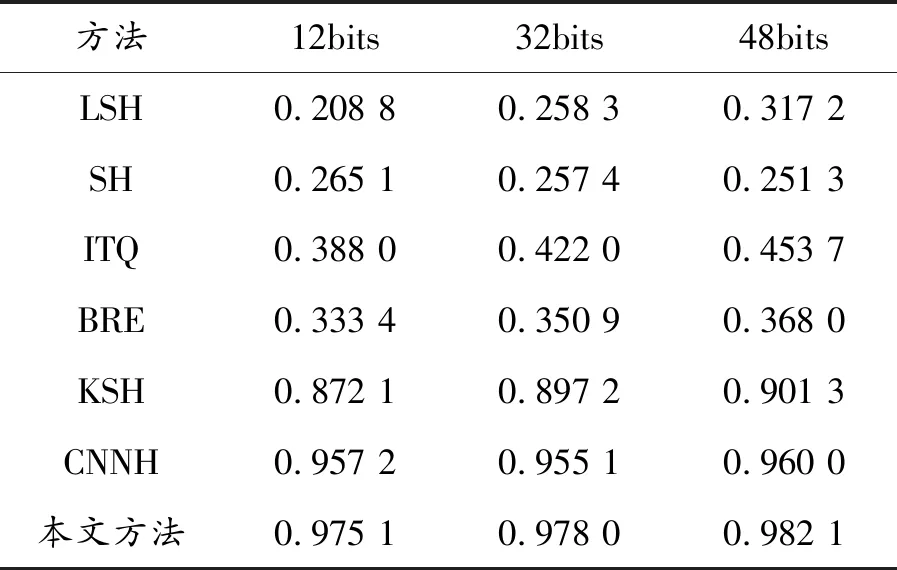
表2 數據集MNIST上不同哈希碼位的MAP值
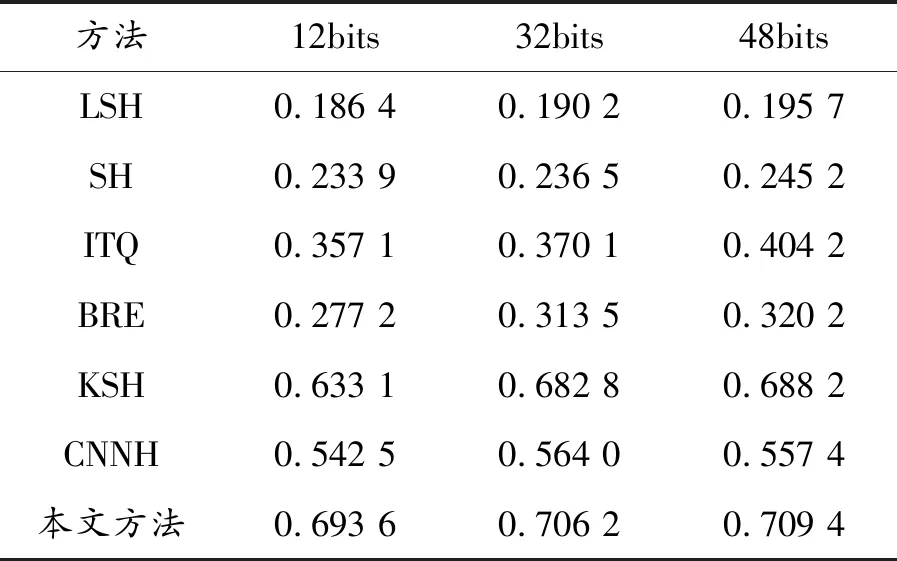
表3 數據集CIFAR-10上不同哈希碼位的MAP值
參數γ通過交叉驗證來調整分類誤差和量化誤差的相對重要性,且當MNIST圖像集的γ=10-2,CIFAR-10數據集的γ=10-3時獲得最佳結果。可以得出:為了發現有判別力的信息,分類標準比量化損失更重要。
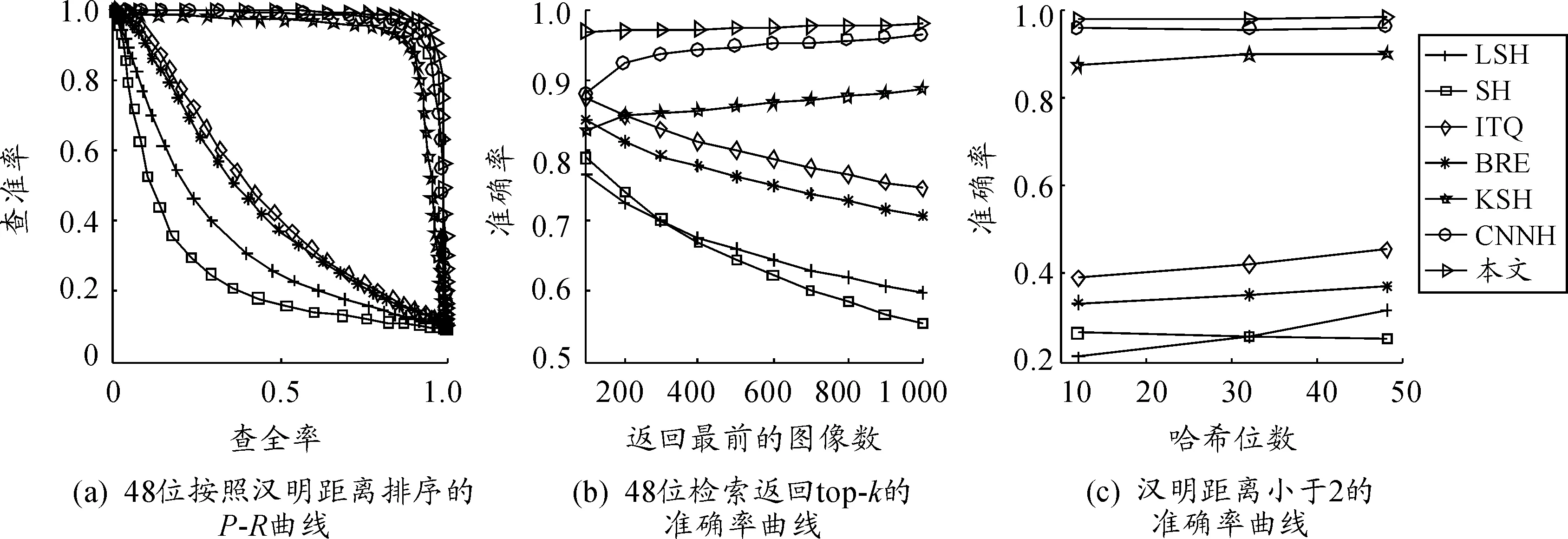
圖2 在數據集MNIST上的對比結果
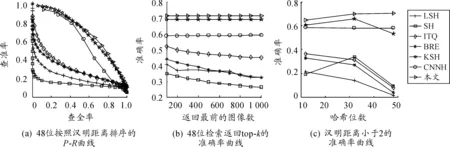
圖3 在數據集CIFAR-10上的對比結果
根據表2、3以及圖2、3的實驗結果,可以得到以下結論:① 該方法在MNIST和CIFAR-10這兩個圖像集上實現了最佳性能;② 深度神經網絡哈希方法的結果優于人工設計視覺特征的淺層方法;③ 所提出的深度哈希方法優于另外一種CNNH的深度哈希方法;④ 實驗結果顯示有監督的哈希方法優于無監督方法。上述實驗結果表明:在同一個學習模型中統一學習哈希函數和分類是有效、合理的。由監督信息學習的哈希碼可以更好地獲得圖像之間的語義結構,從而得到更好的檢索效果。
3.3 本文在圖像檢索中的應用
利用深度哈希卷積神經網絡能夠較好地提取圖像的特征,實現圖像之間的相似度計算,進而返回與檢索圖像相似度較高的圖像。本文將該方法用于Metel多媒體教學資源平臺的圖像檢索中。
3.3.1 Metel多媒體教學資源平臺的特點分析
Metel多媒體教學資源平臺(http://www.metel.cn/)是全球最大的高校課程資料庫。在該平臺的圖像資源里,有很多專家教授的人臉圖像,他們的課程放在Metel平臺上等待學生學習。
通過調研發現學生們很少訪問該網站,老師提醒可以到某些數字資源平臺上去看英文資料,學生由于沒有發現感興趣的課程而逐漸淡忘了。一方面是學識淵博的教授,另一方面是知識相對貧瘠的學生,在這種情況下開發一個以人臉搜索為主的Metel多媒體教學資源圖像檢索系統,使學生可以從海報、網站等渠道通過拍照、下載等方式獲得教授的照片,然后通過圖像檢索系統和教授的照片檢索到該教授的課程資源,從而快速認識教授,了解教授,然后順理成章地學習教授的課程。
3.3.2 圖像檢索系統流程
本檢索系統支持基于深度卷積神經網絡的圖像檢索。圖像檢索流程如圖4所示。
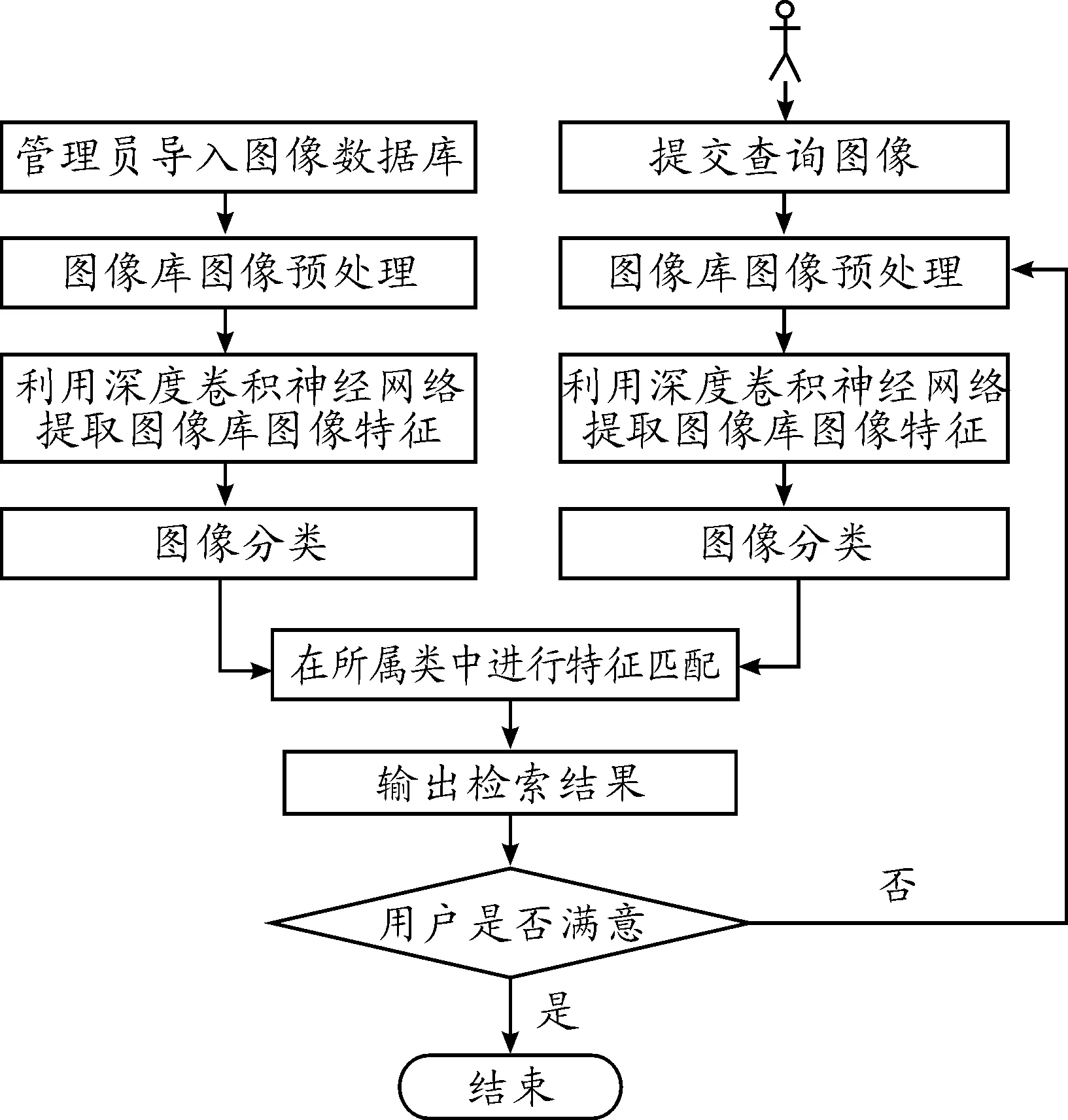
圖4 圖像檢索流程
在圖像檢索完成后,用戶選擇任一檢索結果,可以看到該圖像鏈接的互聯網上的內容。Metel多媒體教學資源平臺檢索結果及相關鏈接如圖5所示。
3.3.3 圖像檢索應用性能評價
由于圖像檢索的匹配準則的選擇具有很強的主觀性,因而需要一個指標體系來評估圖像檢索系統性能的優劣,本系統采用常用的查全率和查準率作為性能指標。由于一次檢索并不能反映系統的檢索性能,因此,根據每次的檢索結果,統計檢索結果和圖庫中同類圖像的數目,計算出每次檢索結果的查全率和查準率,再對多次檢索后得到的查全率和查準率進行平均化處理,得到平均檢索性能。Metel多媒體教學資源平臺的平均檢索性能如圖6所示。

圖5 檢索結果及相關鏈接
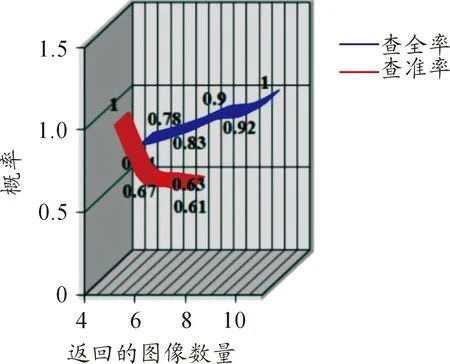
圖6 平均檢索性能
4 結束語
本文提出了一種基于分類誤差和量化誤差的深度哈希模型,采用共同學習判別特征表示和緊致二進制哈希碼,通過優化定義的分類誤差和量化誤差的目標函數,學習的哈希碼具有很強的判別力,提高了圖像的檢索性能。在MNIST和CIFAR-10兩個圖像集上的實驗結果表明:本文方法與其他幾種主流哈希方法相比具有更好的檢索性能。最后將本文提出的深度卷積神經網絡應用于Metel多媒體教學資源平臺的圖像檢索中,表明檢索性能較好。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
