分布式異構數據庫數據同步工具?
2019-04-18 05:07:02徐梓薦
軟件學報 2019年3期
徐梓薦,葉 盛,張 孝
1(教育部數據工程與知識工程重點實驗室(中國人民大學),北京 100872)
2(中國人民大學 信息學院,北京 100872)
關系型數據庫的數據存儲方式一般有行式存儲和列式存儲兩種.對于行存儲數據庫,支持海量數據的高效更新,然而,當需要分析數據庫中隱含的信息時,就可能會涉及一些針對數據庫表中某一或某些屬性上的聚合,而這是行式存儲數據庫的不足.列式存儲數據庫對于海量數據更新沒有很高的處理效率,而對數據分析,特別是在某些屬性上進行分析,往往有很好的查詢優勢.如果能夠構建由行列數據庫共同組成的分布式數據庫系統,用行存儲數據庫接受來自業務線的數據,再通過數據同步將這些數據同步到列存儲數據庫中進行數據分析,就可以彌補數據庫的上述不足,為真實的業務場景提供一個優化的解決方案.
本文以 MySQL為對象,開展基于該數據庫的數據同步技術研究工作,主要實現了一款基于數據庫 Binlog的分布式數據庫中的數據同步工具 Cynomys.鑒于當前并沒有一種針對行存儲數據庫到列存儲數據庫的實時同步工具,本文提出了一種基于SQL還原的實現方法,利用標準的SQL語句避免底層數據庫引擎差異可能導致的無法進行數據庫同步的問題.
本文的主要貢獻包括:(1) 設計并實現了Binlog解析器BinParser以及還原器BinReducer,解析器解析并獲取Binlog的日志信息,還原器將BinParser解析的日志內容還原為可執行的SQL語句;(2) 提出了基于BinParser和 BinReducer的異構分布式數據同步方法 TD-Reduction,并開發了基于 TD-Reduction的數據同步工具Cynomys;(3) 針對ColumnStore的存儲結構提出了延遲提交(delay commit)的優化技術;(4) 本文針對Cynomys的性能、功能等方面做了大量實驗,結果表明該工具有效且能夠正常運行.
1 相關工作
對于分布式架構的數據庫及其數據同步解決方案,研究人員提出了若干種體系架構以及基于此的各類問題的解決方案,如:Stonebraker提出了一種廣域的分布式數據庫系統[1],Chen等人提出了一種基于分布式數據庫的在線數據分割方法[2],Google開發了可擴展、多版本、全球分布式和同步復制的數據庫Spanner[3],Wang等人提出了基于中間件的分布式數據同步技術[4].
在商用數據庫中,Oracle和SAP HANA都提出了解決異構數據存儲的方案.其中,Oracle在其12c版本中加入了解決異構數據存儲問題的新特性In-memory Option[5].在12c版本以前,Oracle所有的數據都是以行形式進行存儲的.該特性引入后,Oracle允許用戶將指定的表空間內所有的表以列形式存儲在單獨開辟的一塊內存空間In-memory Area中[6],從而在查詢分析數據時,對涉及某些屬性上聚合的查詢操作速度加快,并且這種雙格式架構多占用的內存開銷被控制在單一格式架構內存開銷的20%以內[7].SAP HANA是混合型的內存數據庫,它同時支持行存儲以及列存儲[8].與 Oracle不同的是,它需要在創建新表時指定行式或列式存儲,兩種不同的存儲架構使用不同的存儲引擎.這兩種商用數據庫的方案是針對行列存儲數據庫有不同的優勢所提出的數據存儲方案,而Cynomys則是將行存儲數據庫中的數據實時同步或者遷移到列存儲數據庫中,與以上兩種異構存儲的方案定位不同.
當前,常規意義上的數據遷移已經發展得較為成熟,解決方案也已經較為明確,例如基于負載均衡的數據遷移方法[9].而數據同步可以看做是實時的數據遷移過程.一般的數據同步可以基于數據庫日志[10,11]、觸發器[12]等,其中,以日志法最具代表性和可行性.然而由于不同數據庫的日志格式差別很大,可供日志分析的接口也有所不同,所以基于日志法的數據同步也局限于同種數據庫,甚至要求版本相同或相近,這限制了數據同步技術的發展.有人曾提出使用SQL還原的方法[13],但該方法是基于SQL Server觸發器實現的,人工干預程度大、維護困難.Cynomys的基于標準SQL語句進行數據同步的方法受到該工作的啟發.
在分布式環境下,許多數據庫或分布式系統如Google的Chubby,MegaStore,Spanner,Hadoop中的Zookeeper等,都依賴Paxos算法[14]來保證不同結點之間事務的一致性.Cynomys是一款數據同步工具,是從主數據庫(行存儲數據庫)到從數據庫(列存儲數據庫)的數據同步,需要保證的是同步操作前后數據的一致性,而非同步過程中事務同步執行的一致性.
MySQL提供了 Group Commit機制(https://dev.mysql/com/doc/refman/8.0/en/commit.html),在 MySQL的InnoDB引擎中,為了保證數據庫的事務持久性不被破壞,在每個事務被提交之前都會先刷redo日志,而redo日志是要刷到磁盤上的,在多事務并發的情況下會造成性能的瓶頸.總的來說,Group Commit是將多個并發的事務一次性寫入日志來減少 I/O,而 Cynomys的延遲提交機制是將一段時間內多個實現類似功能的事務合并在一起,以減少列存儲數據庫數據文件的訪問,從而提升同步性能.
2 Cynomys的關鍵技術
2.1 二進制日志Binlog
Binlog的全稱是Binary Log(https://dev.mysql.com.doc/internals/en/binary-log-overview),即二進制日志文件,是備份的基本要素之一,對于基于時間點的恢復更是必須的.一般而言,日志會比數據小很多,更適合于需要頻繁備份的場景.MySQL的Binlog從記錄格式上可以分成3種類型:Statement,Row,Mixed.其中,Mixed格式默認以Statement格式作為記錄格式,針對Statement格式不能準確描述的數據變化再以Row格式進行記錄,綜合了兩者的優點,適于本文的場景,即:在不依賴Master節點具體環境的情況下使用Statement格式,在依賴Master節點具體環境的情況下使用Row格式,保證基于Binlog的業務可以快速準確地開展.
2.2 Binlog解析器BinParser
Binlog提供的事件(event)類型復雜多樣,對各種事件歸納出若干種有重要特征的基本事件,針對這些事件再進行下一步的處理.本文將 28種事件類型歸納為 10種基本事件類型,并為每種基本事件類型設置相應的屬性,使得每種事件類型可以完整準確地表述自身的信息,10種基本的事件類型及其描述見表1.

Table 1 10 types of basic event表1 10種基本的事件類型
基于上述對Binlog事件類型的綜合歸類,形成了本文的解析規則算法.由于事件種類繁多,處理過程中難免會出現過多的分支.為了避免這種情況,在設計算法時本文采用了數據驅動[15]的編程方式.BinParser的算法偽代碼見算法1.
算法1.解析器(BinParser)算法.
輸入:Binlog;
輸出:Stringlog_info.


2.3 Binlog還原器BinReducer
Cynomys對Binlog的還原遵循最簡原則.所謂最簡原則,即對于Mixed格式中的Statement日志直接還原為原SQL語句,對于Row日志還原為能表述日志內容的最簡單的SQL語句(如圖1所示).

Fig.1 Flow chart of Binlog reduce圖1 Binlog還原示意圖
日志還原器BinReducer的算法偽代碼見算法2.
算法2.還原器(BinReducer)算法.
輸入:Stringevent;
輸出:StringSql.

具體還原步驟如下.
1) Cynomys監聽Master節點的數據變化,并依據第2.2節的解析規則對Binlog信息進行實時解析;
2) 針對不同的事件類型分別進行還原;
3) 對于QueryEvent,其中涵蓋了具體執行的SQL語句,實際上是以Statement格式記錄的日志信息,對此可以進行直接還原;
4) WriteRowsEvent,UpdateRowsEvent,DeleteRowsEvent等幾類事件,需要經過一定的處理,將其還原為SQL語句.
總的來說,根據最簡原則來進行 SQL還原的時候,如果事件信息中包含具體的 SQL語句,那么直接提取出SQL語句即可,如下面這個例子.
日志示例1

該事件中包含SQL語句,將該行insert into test(a) values(2)直接提取出來即可(對應算法2的第1行、第2行).如果沒有具體的 SQL語句,那么根據事件的類型信息以及包含的具體數據,將 SQL語句還原成 INSERT,UPDATE或者DELETE等DML語句即可(對應算法2的第4行~第6行),舉例如下.
日志示例2

該事件是WRITE_ROWS_EVENT,但該日志內沒有能夠直接提取出來的SQL語句,這種情況則需要通過正則表達式提取出事件信息中數據的變化,還原成原始或等價的SQL語句.該事件能夠還原出以下SQL語句:
insert into test values(1,‘c’), (2,’c’)
2.4 延遲提交
2.4.1 ColumnStore存儲模式
不同的數據庫引擎有不同的存儲模式,而根據存儲模式的不同,對目標數據庫的存儲結構可以優化數據加載的策略.行存儲主要應用在一些事務型數據庫,如 Oracle,MySQL,PostgreSQL等;而列存儲主要應用在分析型數據庫上,如 Mariadb ColumnStore,MonetDB[16],Infobright等.本文要解決的主要問題是從 InnoDB到ColumnStore引擎之間的數據同步,ColumnStore的存儲結構如圖2所示(https://mariadb.com/kb/en/library/columnstore-storage-architecture/):
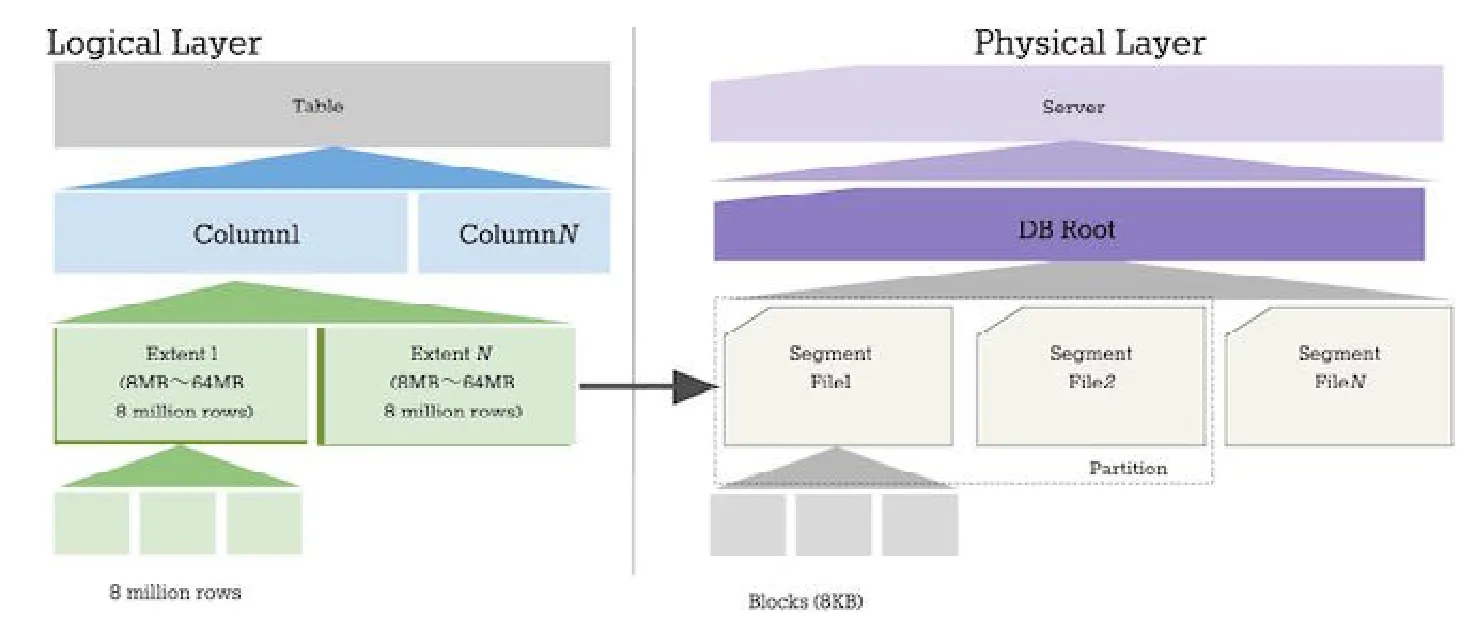
Fig.2 Structure of ColumnStore圖2 ColumnStore存儲結構
2.4.2 Delay思想
由于ColumnStore等列存儲引擎的特殊存儲架構設計,對于行存儲架構支持完善的SQL語句就會帶來同步速度不匹配造成的性能瓶頸等問題.
假設存在表Student(見表2),并且需要執行以下插入語句:
INSERT INTO Student (StuId, Lastname, Firstname, Score) VALUES (4, Lucy, Alex, 100);
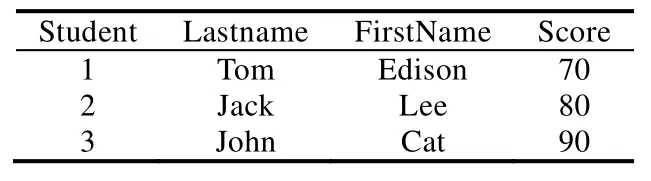
Table 2 Example of Student table表2 示例Student表
在行存儲數據庫中可以發現:插入一行新的數據十分簡單,只要再添加一條完整的記錄就可以,對于之前的記錄毫無影響.Student表信息在行存儲數據庫中存儲,那么其邏輯結構就如圖3所示的結構.而對于同樣的Student表,如果存在列存儲引擎中,那么其邏輯結構如圖4所示.在執行例子中的INSERT語句時,將會涉及到表中的每一列數據,首先取出 StuId所在的數據塊,插入新數據“4”,然后再取出 Lastname所在列,插入新數據“Lucy”,以此類推.而列存儲引擎在通常情況下都會對數據進行壓縮,每更新一次數據都會導致數據的解壓縮與再壓縮操作;同時,列存儲數據庫作為分析型數據庫,通常每張表都有較多的字段.可想而知,通過常規插入手段的性能是極差的.而當用戶基數大,用戶操作零散,在一些峰值情況下會產生大量用戶同時訪問一張表的情況,如果以先來先服務的形式逐一滿足用戶的請求,盡管主庫的數據一定會同步到備庫中,備庫的同步效率將會由于主庫的零散插入行為而大幅降低.

Fig.3 Example of row-based database圖3 行存儲數據庫數據組織示例

Fig.4 Example of column-based database圖4 列存儲數據庫數據組織示例
圖5是一般的同步處理過程,基本是一語句一提交.以這種方式進行事務提交,直接導致區間(extent)處在不斷的解壓縮與壓縮的狀態,降低了同步效率,在主庫InnoDB達到查詢峰值的時候,備庫ColumnStore基本屬于癱瘓狀態.基于行列存儲的差異,必須提出一種新的思路,以解決SQL語句在處理列存儲數據性能不足的問題.
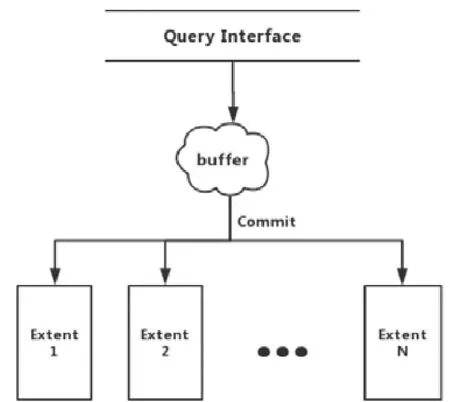
Fig.5 Flow chart of query processing圖5 一般查詢處理流程圖
MySQL的Group Commit目的是為了在并發的情況下通過將待commit的事務分組刷到redo日志中來減少I/O,而延遲提交則是為了緩解行存引擎和列存引擎在數據插入性能上的差異.通過binlog來進行行列同步的過程中,如果不引入延遲提交機制,那么行存作為數據源產生 binlog的速度會遠遠高于列存能讀取 binlog的速度.
假如將行存看做生產者,列存看做消費者,那么正常情況下,消費者是沒有辦法去完成消費生產者的內容的,這就導致消費者始終處于忙的狀態,且與binlog的差距越來越遠.延遲提交機制的實質是通過將大量的待提交的插入事務進行緩存,待到緩存區域達到一定的數據規模的時候再對這一批數據進行統一同步,通過一次解壓操作,將各列待插入的數據追加到相應的Extent中去.
舉例來說,假如行存有3個事務,都是往同一個表中插入數據.

對于行存儲數據庫來說,進行這3個事務的提交很快就能完成.但是對于列存儲數據庫來說,提交3個事務遠比提交 1個事務的代價高得多,因為列存儲數據庫的存儲結構與行存儲數據庫有本質區別.為了避免類似事務多次提交,延遲提交機制就是將一段時間內對同一表進行的操作進行歸并.比如,例子中的3個INSERT語句等同于以下語句:
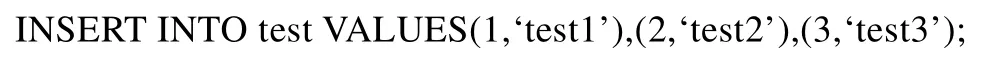
這樣就可以減少對列存儲數據文件的訪問次數和解縮/壓縮次數,提高列存吞吐量.
如圖6所示,Query Interface負責接收外界待插入的數據,在當前事務提交之前,Column Buffer會將數據進行緩存,緩存的大小由用戶根據實際需求決定.

Fig.6 Flow chart of delay commit圖6 延遲提交流程圖
相較于圖4所示的單語句提交的方式,延遲提交解決了列存儲數據庫由于存儲模式限制導致插入性能較差、在交易高峰可能導致癱瘓的風險.以批量的形式進行語句提交,減少了存儲引擎與磁盤的 I/O,也降低了ColumnStore本身的壓縮與解壓縮頻率,滿足了現實的交易場景.
2.5 數據同步正確性分析
對于數據同步工具來說,保證數據同步操作完成后目標數據庫(列存儲數據庫)表數據與源數據表中數據的一致性是最為重要的指標.下面簡單分析數據同步的正確性.
數據同步分為兩種情況.
· 第1種情況是只有一個用戶(進程).從實現的角度看,Cynomys實際上是設置了一個監聽器(listener),實時地監控日志文件的變化,一旦日志文件新增了事件,監聽器就會將這個事件捕捉并發送給解析程序BinParser,然后執行后續的 BinReducer等操作.如果用戶的請求中包含對同一表的 INSERT操作過多,Cynomys會采用延遲提交機制,在不超過Buffer Size的情況下,將這些INSERT語句保存到緩沖區中一起執行.單用戶情況下,數據同步的正確性實際依賴的是BinParser的解析以及BinReducer還原的SQL語句的正確性,只要上述步驟中的各個環節沒有錯誤,最后還原的SQL是正確的語句,同步到從數據庫中的數據就是正確的;
· 第 2種情況是多用戶(進程)并發的情況.多用戶并發的情況下,不同的進程會同時向日志寫入事件.Cynomys對日志監聽并還原 SQL是一個串行的操作,即使多用戶同時并發操作,解析事件的順序與Cynomys監聽到日志的順序相同.即使并發的情況下,也不會影響數據同步的準確性.
算法3.延遲提交算法.
輸入:Buffer_Size,Query;
輸出:null.

3 Cynomys整體架構及實現
3.1 總體架構
系統的架構總體分為日志解析、日志序列化、消息傳遞、SQL執行等幾個主要模塊.
Cynomys是一個典型的“生產者-消費者”模型,日志解析模塊就是整個工具的生產者,消息傳遞模塊充當緩沖區的作用,而最終的SQL執行模塊則是最后的消費者,如圖7所示.

Fig.7 Whole architecture of Cynomys圖7 Cynomys整體架構圖
日志解析模塊的作用是讀取并解析日志,將日志內容還原為SQL語句;序列化模塊的作用是為還原出來的SQL語句提供序列化支持;數據壓縮加密模塊的目的是應對可能出現的帶寬不足及網絡攻擊等問題;消息傳遞模塊主要是為了使消息能夠按照既定的順序或者規則進行傳遞,保證下游的應用不會因為消息傳遞不合理導致的錯誤;SQL執行模塊的作用是將先前模塊中得到的信息進行解壓縮、反序列化等操作,將還原出來的SQL語句在目標數據庫中執行,達到數據同步的效果.
3.2 日志解析模塊
在第2.1節中已經提到MySQL的Binlog屬于二進制文件,本身并不具有可讀性,因此對基于Binglog的異構數據庫同步,需先將Binlog中的內容解析成目標數據庫可執行的相關內容.
首先從日志解析模塊就進行事件的分類處理,Binlog解析器的一級子模塊可以分為 RotateEventParser,QueryEventParser和WriteEventParser這3個部分,分別解析更換binlog文件事件、解析statement的事件以及數據更新相關的事件.根據解析出來的事件類型,EventFilter會將所有的事件分成更詳細具體的事件類別,EventListener監聽器會實時監聽MySQL-Master節點的日志內容變化并通知業務線.具體解析流程如圖8所示.
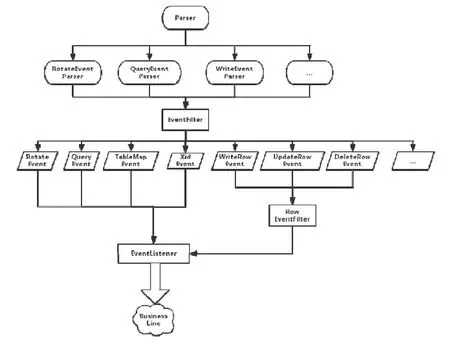
Fig.8 Flow chart of Binlog parser圖8 Binlog解析器解析流程圖
3.3 序列化模塊
數據或者對象狀態在分布式系統中的傳輸不可能直接以字符串的形式存在,必須根據一定的模式對數據進行序列化[17].
支持序列化的工具或方法有很多,例如Avro,Protocol Buffer,JSON等.Cynomys中選用Apache Avro作為序列化工具,主要是由于 Avro具有支持多樣數據結構、可持久化、支持 RPC(遠程過程調用)、能夠與動態語言簡單結合等特點.JSON在Avro中用來定義序列化模式文件,使用Avro的關鍵在于定義消息的模式,只要定義好消息模式并編譯保存,Avro就會根據定義的模式進行相應的序列化和反序列化.
在Cynomys中,定義一個JSON格式的模式如下所示.

在JSON定義的模式中,分別定義了一條消息的幾個域,為簡潔明了表述消息內容,選擇事務 ID(tid)、涉及的數據庫名(database_name)、涉及的表名(table_name)以及還原出來的SQL語句(SQL).經過序列化模塊產生的序列化文件會被傳送到下一個處理模塊進行進一步處理,序列化具體的流程如圖9所示.

Fig.9 Flow chart of serialization based on Avro圖9 基于Avro的序列化操作流程圖
3.4 其他模塊
除前面提到的日志解析模塊和序列化模塊外,Cynomys還包含數據壓縮加密、消息傳遞、SQL執行等模塊.在數據壓縮加密模塊中,本文所采用的GZip數據壓縮算法[18],用AES算法對壓縮包進行加密,RSA算法對AES算法的密鑰進行加密,與被加密的壓縮包一起發送到消息傳遞模塊.數據壓縮加密模塊的流程如圖10所示.在消息傳遞模塊中,本文選擇Redis作為消息隊列,基于Redis實現消息的發布/訂閱(簡稱Pub/Sub)模式[19].利用發布/訂閱模式,解決了被壓縮加密的消息包可能在網絡傳輸過程中丟失或者消息發送方和接收方處理效率不一致帶來的延遲等問題.

Fig.10 Flow chart of compression and encryption圖10 數據壓縮加密模塊流程圖
來自消息隊列中的消息,需由消費模塊對消息進行解密、解壓縮并反序列化后使用消息.Cynomys不會直接執行消息中的SQL語句,而是根據情況決定是否啟用延遲提交機制.
4 實驗評估與分析
本節內容旨在檢驗Cynomys的可用性、高效性、兼容性和正確性.在可用性實驗中,主要驗證Cynomys對數據庫基本操作的支持度以及Cynomys本身的穩定性;在高效性實驗中,主要驗證了延遲提交機制下Cynomys的INSERT性能;在兼容性實驗中,主要驗證了Cynomys的數據庫兼容性和運行平臺的兼容性;在正確性實驗中,主要驗證了多個事務并發情況下Cynomys同步數據的正確性.
4.1 環境配置
Cynomys的功能實驗、性能實驗在兩臺服務器上運行,其中,主服務器運行 MySQL等行存儲數據庫,備份服務器運行MariaDB ColumnStore等列存儲數據庫.所有實驗的測試數據均采用TPC-C或TPC-H基準測試數據集.具體的實驗環境參數見表3.

Table 3 Configurition of experiment表3 實驗環境配置
4.2 功能實驗
4.2.1 數據類型支持度
數據庫基本數據類型是支撐表元素的基礎,Cynomys對數據類型的解析是根據MySQL寫日志的規則,不同的數據類型對應不同的 ID,對字符串類型和非字符串類型分別解析.本文對 MySQL的各個基本數據類型都進行了相應的測試.實驗結果表明:Cynomys能夠完全支持 MySQL的基本數據類型(MySQL的基本數據類型:https://dev.mysql.com/doc/refman/8.0/en/data-type-overview.html),MariaDB,MonetDB的基本數據類型和MySQL一致.
4.2.2 操作類型支持度
本文用例中涉及的SQL語句大都與具體的數據直接相關,所以在實驗論證中只對DDL語句和DML語句進行實驗驗證證,而對DCL語句不做支持.實驗結果見表4,可以看出,Cynomys能夠支持所有DDL語句和DML語句.

Table 4 SQL statement support in Cynomys表4 Cynomys對SQL語句類型支持情況
4.2.3 系統穩定性
作為一個實時同步工具,對其穩定性要求一般較高,必須保證 7×24小時無間斷的穩定運行和快速響應.本實驗是將Cynomys部署在服務器上連續運行一周,在每天的4個時間點各發起一次同步請求,觀察Cynomys的表現并進行采樣,得出結論,Cynomys的穩定性達到了7×24小時及時響應,符合MySQL的運行狀態和同步要求,實驗結果見表5.

Table 5 Test table of operational stability表5 Cynomys運行穩定性測試表
4.3 性能實驗
性能實驗中,主要測試從行存儲到列存儲的同步效率,其中,列存儲數據庫選擇前面提到的 MariaDB ColumnStore.測試集選用的是TPC-C產生的模擬數據.
MariaDB ColumnStore主要用于分析型數據庫使用,所以Cynomys的同步只涉及INSERT,對UPDATE和DELETE性能不作要求,在性能實驗中,主要是要檢驗Cynomys執行INSERT的性能.
在測試Cynomys的INSERT性能時將啟用延遲提交功能,通過調整延遲提交的緩沖區大小,得到實驗數據如圖11所示.

Fig.11 Figure of DELAY buffer and INSERT effiency圖11 DELAY緩沖區大小與INSERT效率關系表
依據上述實驗結論,延遲提交確實可以提高 INSERT操作的同步性能.在內存容量充足的情況下,緩存的待插入數據越大,相應的同步效率越高.
根據 MySQL的現實場景,一般峰值的INSERT量在1 000條/s左右.由于表的列數對插入性能影響較大,所以對于延遲提交緩沖區大小的需要可依據表結構來確定.以一個擁有 20個字段的表為例,滿足峰值 INSERT的緩沖區大小設置為3 000左右即可.
從數據中還能看出另一個問題:隨著表的列數增加,INSERT操作效率的提升降低了.這是由于受測列式數據庫的特殊存儲結構,列式數據庫中每一列都對應一個文件,這樣的文件組織結構導致當表中的列增多時,會對性能有較大的影響.
4.4 兼容性實驗
兼容性實驗主要測試Cynomys在不同操作系統上是否能正常運行以及不同行列數據庫能否正常同步.
Cynomys采用JAVA語言開發完成,目的就是為了能兼容各個操作平臺.本節選取了當前主流的操作系統包括Windows 7,Windows 8,Ubuntu,CentOS等不同版本測試Cynomys在各個操作系統平臺的運行情況,實驗結果見表6.

Table 6 Experimental result of compatibility of Cynomys表6 Cynomys平臺兼容性實驗結果
從表6可以看出,Cynomys在當前主流操作系統上都能正常運行.此外,還對不同版本的行列數據庫進行了軟件兼容性實驗.Cynomys是基于Binlog實現的,因此所有基于Binlog且能執行標準SQL語句的行數據庫理論上都能運行,本節測試了MySQL與MariaDB(ColumnStore)的不同版本進行軟件兼容性實驗,實驗結果見表7.
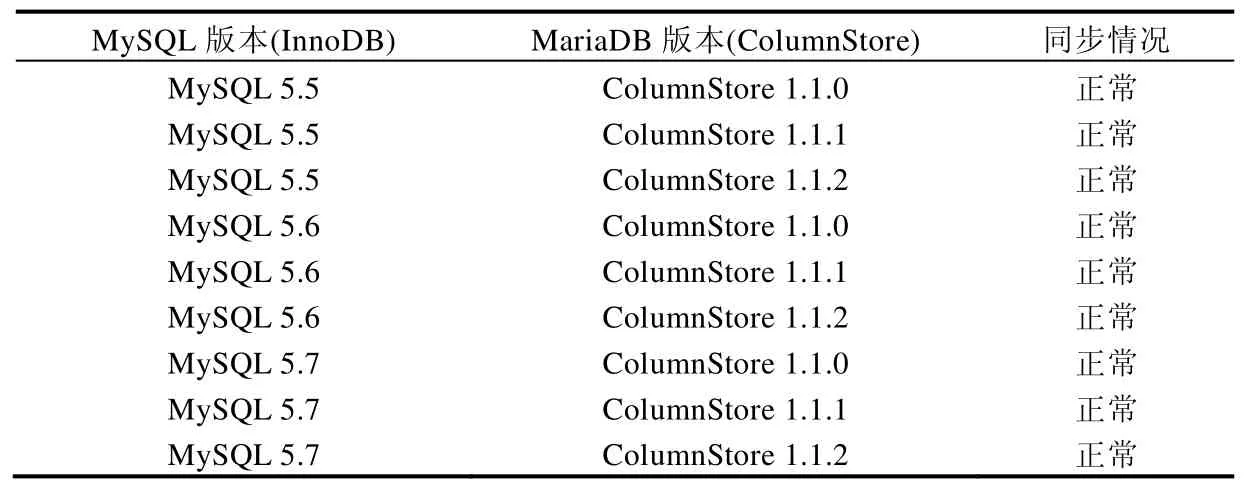
Table 7 Experimental result of compatibility of database in Cynomys表7 Cynomys數據庫兼容性實驗結果
除表7給出的MySQL和MariaDB外,還對其他列存儲數據庫如MonetDB進行了測試,在這些行存儲數據庫之間,Cynomys都能正常同步數據,不同列存儲數據庫對數據查詢時間的影響如圖12(以 MariaDB和MonetDB進行對比)所示.
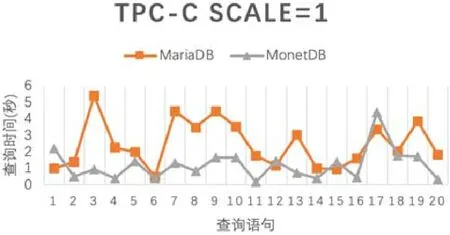
Fig.12 Influence of query time for different column-based database圖12 不同列存儲數據庫對查詢時間的影響
4.5 正確性實驗
正確性實驗主要測試在多用戶(進程)并發的情況下,Cynomys同步數據的準確性與源數據是否一致.本節實驗所選取的主數據庫為MySQL5.6,列數據庫為MonetDB11.27,數據集為TPCH-DBGEN生成的TPC-H數據中的LINEITEM表的前100萬條數據.
實驗假設有4個用戶同時對MySQL寫入共100萬條數據,每個用戶寫入25萬條.從MySQL寫入數據一共用時5.68s,由于Cynomys對列存儲數據庫SQL語句提交的優化,數據寫入MonetDB的速度與MySQL寫入的速度幾乎是同步的,僅用6.12s.實驗為采樣實驗,測試采樣為30%,50%,100%的情況下,數據響應速度與數據同步的準確率.對比是否與原數據相同采用將所有字段進行拼接,比較與原數據的字符串是否相同的方法.同步實驗準確性結果如圖13所示.

Fig.13 Accuracy of synchronization圖13 同步準確性實驗
實驗結果顯示,在不同采樣大小的情況下,Cynomys同步到從數據庫的數據都能與源數據保證完全一致的準確性,驗證了第2.5節中對數據同步正確性的說明分析.
5 總 結
在當前分布式系統得到廣泛應用的背景下,本文提出了一種利用數據庫所提供的 Binlog機制,設計了日志解析器BinParser和日志還原器BinReducer.為了應對分布式場景,也為工具實現了包括序列化、壓縮加密、消息分發等一系列的工作.同時,針對列存儲數據庫本身在INSERT性能上存在的不足,提出了延遲提交的思想.基于以上各項技術實現了同步工具 Cynomys,用于同步行存儲數據庫和列存儲數據庫之間的數據.該方法彌補了不同存儲模式的異構數據庫之間無法進行實時數據同步的空白,解決了從分布式行存儲數據庫到列存儲數據庫的同步問題,且在實驗中表現出了良好的性能.
此外,目前Cynomys只支持部分版本的MySQL數據庫,在MySQL5.6之后,由于Binlog引入了CRC校驗,Cynomys對于如何適應CRC校驗并沒有給出解決方案,所以對于最新版本的MySQL數據庫使用場景還不能做到同步,需要人為地對高版本MySQL進行配置才可以.這也是未來需要改進的方面.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
