改進的SSD航拍目標檢測方法?
2019-04-18 05:07:12許晏銘朱永英王鵬乾魯明羽
軟件學報 2019年3期
裴 偉,許晏銘,朱永英,王鵬乾,魯明羽,李 飛
1(大連海事大學 環境科學與工程學院,遼寧 大連 116026)
2(大連海事大學 信息科學技術學院,遼寧 大連 116026)
3(大連海洋大學 海洋與土木工程學院,遼寧 大連 116023)
近年來,目標檢測和識別技術一直是業界研究的熱點.目標檢測技術主要有兩種研究方向:1) 基于傳統方法的目標檢測.主要步驟為目標特征提取、訓練分類器、輸出結果,對標注的訓練樣本進行特征提取并將其送到分類器中進行訓練;2) 基于深度學習的目標檢測.
目前,基于深度學習的目標檢測主要分為基于候選區域的目標檢測算法和基于回歸的目標檢測算法:
基于候選區域的目標檢測算法的計算過程是:首先,根據區域選擇算法從輸入圖像中提取出N(N遠大于真實提取出的目標個數)個感興趣區域(region of interest,簡稱 ROI);然后,利用多層卷積神經網絡(convolutional neural network,簡稱 CNN)對上述的感興趣區域進行特征提取,對提取到的特征進行分類;最后,利用 Boundingbox回歸器對輸出窗口進行更正,得到最終結果.2014年,Girshick提出了 Region CNN[1](R-CNN)目標檢測算法;2015年,Girshick提出了Fast R-CNN[2]和Faster R-CNN[3];2017年,何凱明提出了基于Faster-RCNN框架的Mask R-CNN[4]目標檢測算法等.
上述的基于候選區域的目標檢測算法雖然精度很高,但實時性差,而不使用 RPN(region proposal network)網絡的目標檢測方法在速度方面更具優勢,即基于回歸的目標檢測算法:對于給定的輸入圖像,直接在圖像的多個位置上回歸出這個位置的目標邊框以及目標類別.Redmon在2016年提出了YOLO[5]目標檢測算法.隨后,在此基礎上,作者提出了改進版的YOLOv2[6].2016年,Liu提出的SSD[7]算法結合了YOLO速度快和Faster R-CNN候選區域的優點,SSD在不同特征圖上進行分割,然后采用類似RPN的方式進行回歸,在VOC2007數據集上最高可達到74.3%的準確率,處理速度為46幀/s.該算法不僅保證了檢測速度,也提高了檢測的準確率. 2017年提出的DSOD[8]基于SSD算法引入DenseNet[9]思想,mAP(mean average precision)為77.7%,與SSD300相當,但檢測速度為17.4幀/s,較SSD300的46幀尚有較大差距[10].2017年,Jeong提出Rainbow SSD[11]算法對傳統的SSD算法進行了改進,一方面利用分類網絡增加了不同特征層之間的關聯度,有效減少了重復區域;另一方面增加了特征金字塔中的特征圖的個數,使其適用于小目標檢測,其 mAP達到了 77.1%,同時,速度也提高到 48.3幀/s,效果比較明顯.但該算法在融合不同特征層的特征信息時覆蓋了整個網絡結構,這樣勢必會引入冗余信息,增加了計算的復雜度.2018年提出的YOLOv3[12]算法通過多級預測方式改善了小目標檢測精度差的問題,同時,采用簡化的residual block取代了原來1×1和3×3的block,為無人機目標檢測的應用場景的落地提供了更多的可能.
無人機技術的快速發展,使得無人機地面目標檢測技術已成為計算機視覺領域的重要研究方向,無人機在軍事偵察、交通管制等場景中具有普遍的應用價值.國外很早便開展了針對無人機檢測跟蹤系統的研究.1997年,美國就啟動了VSAM(video surveillance and monitoring)項目,在高處架設攝像機對地面目標進行全方位的檢測和跟蹤.2006年,美國DAPRA部門設計了一套無人機監控系統COCOA,該系統能對無人機下視的車輛、行人等目標進行實時的檢測、識別和跟蹤,捕獲目標的連續運動序列,使用幀間對齊技術對運動序列進行背景補償,然后對其進行背景建模并最終實現運動目標的跟蹤[13].Ibrahim 于 2010年提出了 MODAT(moving objects detection and tracking)系統,使用SIFT特征進行航拍目標的檢測和跟蹤[14].
雖然國內該方面的相關研究起步較晚,但發展速度很快[15].2008年,張恒設計了一套無人機平臺運動目標檢測和跟蹤系統,能對無人機拍攝圖像進行特征提取,并對機載相機運動進行自適應消除[16].譚熊等人于 2011年提出了基于區域的航拍目標跟蹤算法,該算法計算速度快、精度高,能滿足實時運算的要求[17].2013年,董晶等人設計了一套地面運動目標實時監測及跟蹤系統,提取特征點進行運動目標的檢測,并將檢測和跟蹤相結合來進行移動目標的定位,適用于誤檢和目標跟蹤失效的情況[18].湯軼等人設計的無人機視頻中,運動目標檢測與跟蹤系統使用RANSAC算法對背景運動進行補償,粒子群優化算法進行目標中心位置的定位,該思路確保了算法的準確性和實時性[19].
無人機產業發展日益蓬勃,其應用領域仍在不斷拓展.但無人機在執行軍事偵察、消防、救災、搜救等實時任務時,目標檢測的精度和實時性決定了無人機飛行任務是以機毀人亡,還是以生命財產的延續而結束,成敗就在一瞬間.受到負載、續航、航行環境、計算力等限制,無人機目標檢測在這方面的研究進展緩慢,已成為制約無人機發展的瓶頸問題之一.當前,無人機目標檢測算法面臨以下難點和問題[20].
(1) 無人機快速移動的不穩定性造成航拍圖像具有圖像模糊、噪聲多、運動目標可提取的特征信息少、易出現重復檢測、目標誤檢等問題;
(2) 無人機從制高點進行圖像采集時,圖像中的檢測目標一般較小,易出現小目標漏檢情況;
(3) 隨著無人機的不斷移動,外界環境(比如光照、云、霧、雨等)的變化將會導致圖像中目標特征的劇烈變化,增加了后續特征提取的難度[21];
(4) 無人機目標檢測算法需要快速準確地檢測出運動目標,因此算法應滿足實時計算的要求.
針對無人機場景下目標分辨率低、目標遮擋和光照變化等導致的可提取特征不多的問題,本文在 SSD目標檢測算法的基礎上對原始基準網絡VGG-16[22]進行替換,提出了基于深度殘差網絡(deep residual network,簡稱Resnet[23])的航拍目標檢測方法(R-SSD),增強網絡的特征提取能力;同時,針對SSD算法目標重復檢測和小樣本漏檢問題,本文為特征提取層選取高層的語義信息和低層的視覺信息進行特征融合,提出一種基于特征融合的航拍目標檢測方法(CI-SSD).
1 SSD快速檢測原理
SSD的速度優勢在于:該算法是在前饋CNN網絡的基礎上實現的,把網絡的計算量封裝在一個端到端的單通道中.針對單枚輸入圖像,SSD會產生多個固定大小的Bounding Box和框中對象類別的得分,然后進行非極大值抑制(non-maximum suppression,簡稱NMS)操作,得到最后的預測結果,顯著提高了檢測速度.網絡前半部分為基礎網絡,主要用來進行圖像分類;網絡后半部分為多尺度卷積層,卷積層尺寸逐層減少,主要用于多尺度下目標特征的提取和檢測.
SSD網絡中的任何一個特征層都使用一組卷積過濾器與輸入進行卷積操作,產生一系列固定的預測集合,該集合包括預測目標框的4個偏移量和21個種類的置信度得分.
每個特征圖都與一組不同尺度的默認邊界框相綁定,在每個單元格中,預測結果為相對于默認邊界框的位置偏移和類別得分.如在某個已知位置的k個邊界框中,每個邊界框都需計算相對于當前位置的4個坐標偏移量和c個類的分數,因此每個位置都有(c+4)×k個過濾器,對于m×n的輸入圖像,該操作總計會產生k×m×n×(c+4)個結果.如圖1所示:圖1(a)為含有真實坐標框的輸入圖像,圖1(b)和圖1(c)分別是尺度為8×8和4×4的特征圖.

Fig.1 SSD framework for detection圖1 SSD的檢測結構
在進行卷積操作時,每個位置都需要進行默認框(如圖1(b)和圖1(c)中4個不同寬高比的邊界框)的計算,預測所有類別的得分和坐標偏移值.
SSD算法中,目標損失函數的思想類似于 MultiBox[24],但 SSD將其擴展為可處理多個類別的目標函數.代表針對類別p,第i個默認框和第j個真實框的結果保持一致;表示不一致.則表示對于類別p的第j個真實標簽框,可能有多個默認框與之匹配.總的目標損失函數為

其中,N為與真實標簽框相匹配的默認框的個數,Lloc和Lconf分別為位置和置信度的損失量,α為兩者的權重,x為輸入圖像,c為目標類別,l為預測框,g為真實標簽框.
2 殘差網絡模型
2.1 殘差網絡
深度殘差網絡(ResNet)是在2015年ILSVRC(ImageNet Large Scale Visual Recognition Challenge)大賽上由微軟亞洲研究院(MSRA)何凱明團隊提出的一種卷積神經網絡,該網絡贏得了當年圖像分類、檢測、定位和分割的第 1名.如圖2所示,隨著網絡層數的增加,網絡結構的特征提取能力越來越強,識別錯誤率也越來越低.ResNet在ImageNet數據集上可達到3.57%的識別錯誤率,遠低于VGG網絡和人眼實測的錯誤率,這為后續的殘差網絡替換提供了研究基礎.殘差網絡最深可達152層,與傳統網絡相比,深度網絡帶來了更好的泛化能力,同時還具有更低的復雜性.

Fig.2 Top-5 error rate (%) of ILSVRC over the years圖2 ILSVRC歷年的Top-5錯誤率(%)
2.2 殘差網絡的學習策略
殘差網絡引入了一種殘差學習框架來應對傳統網絡的退化問題.如圖3所示,該學習策略對多層的殘差映射進行擬合,H(x)稱為幾個網絡層堆疊的期望映射,x為當前堆疊塊的入口,relu激活函數的使用縮短了學習周期.假設n個非線性層可近似地表達為某個復雜函數(殘差函數),則把堆疊的網絡層擬合成另一個映射F(x)=H(x)-x,那么最終的基礎映射便為H(x)=F(x)+x.與通過疊加網絡層來擬合期望的原始映射相比,盡管這兩種方式都能近似得到殘差函數,但殘差映射更容易調優.通過構建殘差學習,殘差網絡可將多個非線性連接的系數逼近零來近似成更優的期望映射.
圖3中,公式H(x)=F(x)+x可由帶有跳躍連接(跳過一層以上的層間連接)的前饋神經網絡來實現,跳躍連接執行恒等映射并將計算結果添加至其指向的輸出層,這種計算方式沒有導入其他系數,計算量沒有明顯的增加.殘差學習框架的引入,可大幅降低提取特征的重復度,減少網絡模型的計算量.這種跨層共享參數和重復利用中間特征的方式,可解決層數增加之后出現的性能退化問題.

Fig.3 Comparison of common structure and residual structure圖3 普通結構和殘差結構對比
2.3 殘差網絡的結構設計
SSD使用的基準網絡VGG16的結構如圖4(a)所示,用3×3的卷積核來增大網絡的感受野范圍,用多個包含過濾器的卷積層來減少參數的引入和提高網絡的擬合能力.VGG16共16層,網絡的前半部分為卷積層的疊加,后半部分為全連接層,最后為進行歸一化的Softmax層.

Fig.4 Comparison of network architectures圖4 網絡結構對比圖
圖4(b)所示為Resnet-50的網絡結構,圖中虛線框為不同層塊的殘差結構,ResNet中的每個卷積塊都包含不同數目的殘差單元,每個殘差單元進行3次卷積操作.殘差網絡使用身份快捷連接(identity shortcut connection)進行卷積層的跨連,它解決了網絡層數加深但檢測精度不升反降的問題.與傳統 VGG相比,殘差網絡具有更少的濾波器和更低的計算代價,這也是將基準網絡替換為殘差網絡的原因.
3 基于殘差網絡的航拍目標檢測算法
3.1 前置網絡替換
用于圖像分類的標準神經網絡稱為前置網絡(base network),前置網絡的理論基礎是生成模型,生成模型可自適應地從輸入圖像中學習重要特征,這在很大程度上解決了某些模型(如傳統的全連接網絡)特征提取能力不足的問題.但生成模型提取到的特征信息冗余太多,有用信息提取困難.因此,通過前置網絡對輸入數據進行特征提取,為后續網絡層提供輸入信息,可加快后續訓練速度,提高網絡的表達能力.
ResNet通過引入殘差學習來提高模型的檢測性能,合并n個堆疊塊,進而構造一個殘差學習模塊.構造塊定義為

其中,x和y分別為當前計算層的輸入和輸出,函數F(x,Wi)代表當前網絡想要學習的殘差結構.如圖3所示,第1層公式F=W2σ(W1x)中,σ為Relu激活函數;第2層則通過快捷連接來執行F+x操作.公式(2)中的輸入向量x和函數F的維度應保持一致,否則,我們需要對輸入向量x執行線性投影來實現維度匹配:

對無人機下視目標圖像采集速度和機載硬件計算能力進行綜合考慮,本文選用Resnet-50殘差結構進行網絡替換.選取的特征提取層為 conv2_x(分別使用大小為 1×1×64,3×3×64,1×1×256 的卷積核),conv3_x(分別使用大小為 1×1×128,3×3×128,1×1×512 的卷積核),conv4_x(分別使用大小為 1×1×256,3×3×256,1×1×1024 的卷積核),conv5_x(分別使用大小為 1×1×512,3×3×512,1×1×2048 的卷積核),conv7_x,conv8_x,conv9_x.Resnet中的身份快捷連接沒有增加額外計算量,因此,我們可以公正地對原始網絡和殘差網絡進行實驗對比.圖5為原始的SSD和經過網絡替換的R-SSD的網絡結構對比圖.

Fig.5 Comparison of SSD network and R-SSD network圖5 SSD網絡和R-SSD網絡對比
3.2 訓練參數設置
(1) 選擇默認框參數
為了能對不同尺度的目標進行正確檢測,某些算法將輸入圖像轉為不同的尺度,然后對轉換后的圖像進行處理,并將檢測結果進行融合[25,26].使用若干個不同輸出尺寸的特征圖進行預測,同樣可以得到上述的輸出結果,而且在端對端的單一網絡中可以進行參數的共享傳遞,轉換效率更高.
在一個卷積神經網絡中,位于不同層的特征圖有著不同大小的感受域(特征圖上輸出的某個節點,其對應的輸入圖像中的某塊區域).在此處采用的策略是默認框不用一對一的與特征圖的感受域相映射,不同位置的默認框對應不同的區域和目標尺寸.假設用來預測的特征圖有m個,則每個特征圖中默認框的尺寸為

其中,Smin為網絡結構中最底層的默認框尺度,值為0.2;Smax為最高層的默認框尺度,值為0.95,不同層以一定規則間隔排序.默認框的寬高比取值ar∈{1,2,3,1/2,1/3},則每一個默認框的寬、高分別為

(2) 確定匹配策略
在生成R-SSD檢測模型時,需要為每個真實標簽框都選擇默認框與其進行匹配.原始的MultiBox匹配思想是從所有的候選默認框中為每一個真實標簽框找到一個最高的Jaccard(用于比較樣本之間的相似性和差異性)重疊值,該方法確保了每個真實標簽框都有一個與其匹配的默認框.本文的匹配策略是在MultiBox思想的基礎上將 Jaccard重疊系數調整為 0.5,這一調整弱化了學習過程,允許網絡模型自適應地計算多個默認框的重疊情況,而不只限于Jaccard重疊率最高的那個默認框.
(3) 選擇損失函數
在進行模型訓練時,始終存在一個目標函數,算法持續對該函數進行優化,直至損失值最低,這個目標函數稱為損失函數.損失函數用來衡量網絡模型的輸出值和真實值yi的差異程度,損失函數的目的是使損失值最小化,其公式為

本文基于深度學習框架Caffe[27]建立了R-SSD訓練模型,通過對比實驗選擇了Softmax作為損失函數,其公式為

其中,Sj為類別j的得分,yi為目標的真實標簽.不同類別上的目標分值離散程度越高,損失值越低,模型性能越好.針對航拍數據特點,對公式(8)進行如下變形可進一步提高精度:

通過計算損失函數Li,得到一個用于分類的Softmax模型.
3.3 總體流程圖
在訓練階段,首先對輸入的目標圖像進行預處理操作,包括數據增強和圖像去霧等,然后對輸入圖像中的目標信息進行標注,得到真實目標的位置信息和類別信息,再進行模型的訓練,生成最終的R-SSD目標檢測模型.
在檢測階段,每枚測試圖像都生成N個可能包含目標的框圖,利用訓練階段生成的R-SSD模型對其進行真實坐標偏移和所屬類別得分的計算,每枚圖像都會得到N個分類結果,再利用非極大值抑制算法輸出最終結果.整體流程如圖6所示.
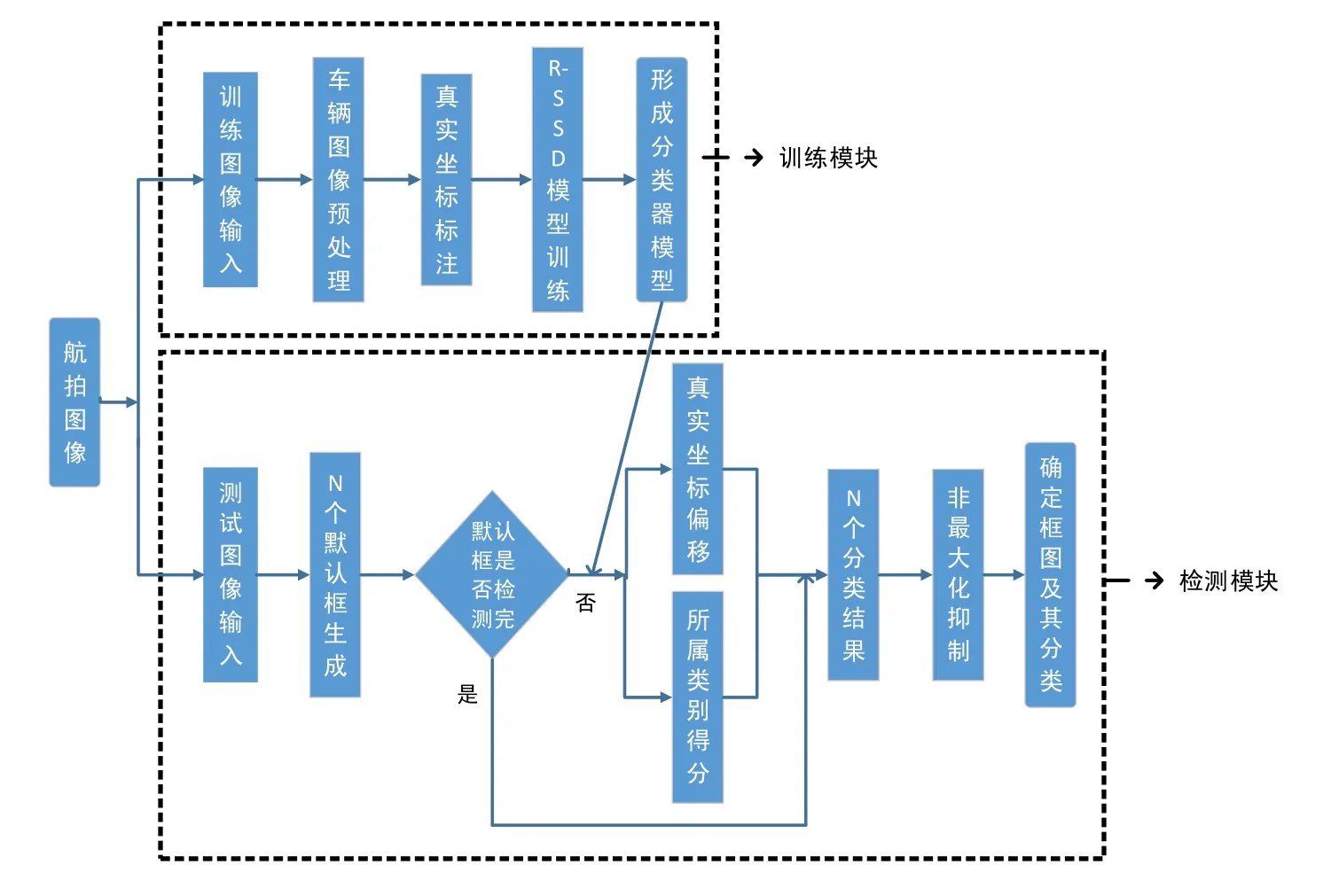
Fig.6 Flow diagram of object detection based on aerial photography圖6 航拍目標檢測流程圖
4 基于特征融合的航拍目標檢測算法
上一節提出了一種基于殘差網絡的航拍目標檢測算法 R-SSD,使用 Resnet-50網絡替換原始前置網絡VGG-16,在原始SSD算法的基礎上提高了精度,但實時性差,還存在誤檢、小目標漏檢、重復檢測的問題.傳統的SSD目標檢測算法在速度和精度方面表現出色,充分利用了多卷積層的優勢來對目標進行檢測,對目標的尺度變化具有較好的魯棒性.但SSD網絡結構的缺點是對小目標漏檢,如圖7所示,每個卷積層都當作后續分類網絡的輸入,即每個層對應一個目標的尺度,忽略了層與層之間的關聯關系.如圖7中的conv4_3特征層,從該層開始,隨著網絡層數和深度的增加,卷積層的尺度逐步減小,表征能力越來越強,語義信息也越來越豐富,但底層的conv4_3沒有利用高層的語義信息,導致檢測小目標效果較差.因此,本文利用特征融合技術對該網絡進行改進.

Fig.7 SSD extra feature layer圖7 SSD提取特征層
4.1 空洞卷積操作
當把圖像輸入到用于分割的FCN網絡[28]時,FCN網絡會先進行卷積操作再進行池化(通過縮小圖像尺寸來增大感受野范圍)操作,然后將池化后尺寸變小的圖像進行上采樣增大到原始圖像尺寸進行結果預測.但在圖像尺寸縮小再增大的過程中,池化層會造成圖像部分信息的缺失.如果沒有池化層,高層網絡中尺寸較小的卷積層其感受野范圍也相對較小,缺少圖像的整體特征,模型學不到全局信息;如果加上池化層,圖像原有的信息特征會遭受損失,降低模型的精度.所以我們采用空洞卷積方法(dilated convolution)[29]來解決這一問題,空洞卷積在不損失信息的前提下加大了卷積層的感受野范圍.SSD結構的缺點在于缺少圖像的全局信息,利用空洞卷積進行特征下采樣可以改善小目標檢測精度不高的問題.
圖8(a)是卷積核大小為3×3、擴張(dilation)為1的空洞卷積操作,該操作等同于卷積操作,3×3的點狀區域為當前卷積的感受野范圍.圖8(b)是卷積核大小為3×3、擴張為2的空洞卷積操作,即一個7×7的區域但只有9個點和 3×3大小的卷積核發生了卷積操作,其余點的權值為 0.雖然該操作的卷積核大小只有 3×3,但與圖8(a)相比,感受野范圍擴大到了7×7.執行空洞卷積之后感受野的大小為

其中,擴張值為當前卷積核中每個計算點的半徑.如圖8(b)中擴張值為2,則Fdilation=7×7.

Fig.8 Dilated convolution operation圖8 空洞卷積操作
本文將圖7中不同層之間的相互關系考慮在內,較低層的特征圖通過空洞卷積操作連接到較高層的特征圖上,并對其進行尺度歸一操作,保持通道數目不變,改進之后的結構如圖9所示.

Fig.9 Extra feature layer after dilated convolution圖9 空洞卷積操作之后的提取特征層
4.2 反卷積操作
為了讓訓練模型學到更多的上文信息,對分類特征層執行反卷積(deconvolution)[30]操作,卷積操作可以用來對高維向量進行低維特征的計算.圖10(a)是輸入尺寸為5×5、濾波器大小為3×3、步長為2、擴充為1的卷積計算過程,輸出尺寸為3×3.反卷積操作剛好相反,它可以將低維的局部特征映射成高維向量,因SSD網絡結構中高層(低維特征)的特征圖含有豐富的語義特征,我們可對其進行反卷積操作映射到低層網絡中,用來增強卷積層的表征能力.圖10(b)為卷積操作所對應的反卷積過程,其輸入尺寸為3×3.在給定的特征單元之間進行0值的插入上采樣,然后采用步長間隔為1的3×3的濾波器進行反卷積計算,反卷積的輸入輸出關系為

其中,s為移動步長,i為輸入的特征大小,k為濾波器大小,p為擴充值.例如圖10(b)中i為3,s為1,k為3,p為0,則Fdecon=5×5.

Fig.10 Convolution and deconvolution operation圖10 卷積與反卷積操作
上采樣的方式將語義信息更強的高層特征融入到低層特征圖中,增強了網絡的辨識度.反卷積操作不僅增加了特征圖大小,也使低層特征可以學到更為豐富的語義信息.在原始SSD網絡的基礎上,將較高層的特征圖通過反卷積操作連接到較低層的特征圖上,并對其進行尺度歸一操作,保持通道數目不變,改進之后的結構如圖11所示.

Fig.11 Extra feature layer after deconvolution圖11 反卷積操作之后的提取特征層
4.3 網絡結構
原始SSD算法沒有計算不同尺度特征層之間的映射關系,在對同一目標進行檢測時,SSD會生成多個不同尺度的預測框,對小目標檢測效果差.本文提出的CI-SSD網絡結構在SSD目標檢測算法的基礎上進行了改進,保留了該算法的前置網絡VGG-16,將conv4_ci,conv7_ci,conv8_ci,conv9_ci,conv10_ci,conv11_ci作為預測的特征層.CI-SSD充分利用了不同特征層之間的相互關系,用空洞卷積操作將低層的特征圖和高層的特征圖融合,可顯著提高分類網絡的感受野范圍,有利于模型學習到更多的全局信息;反卷積操作將高層的特征圖和低層的特征圖融合,有助于低層特征層進行小目標的檢測,增強了模型的語義表征能力.這種連接方式使 CI-SSD網絡可在同一特征層上將目標的不同尺度考慮在內,增強模型的泛化能力.
如圖12所示,conv4_ci特征層由512個38×38的特征圖組成,其中:前256個特征圖是由conv4_3經過卷積運算生成的,所用的卷積核大小為 3×3,步長為 1,擴充為 1,特征圖尺度未發生變化;后 256個特征圖是由 conv7經過反卷積上采樣操作生成的,所用的卷積核大小為2×2,步長為2,擴充為0,特征圖尺度擴大一倍.

Fig.12 CI-SSD object detection network圖12 CI-SSD目標檢測網絡
conv7_ci特征層由1 024個19×19的特征圖組成,其中:前256個特征圖是由conv4_3經過空洞卷積下采樣運算生成的,所用的擴張值為 2,卷積核大小為 3×3,步長為2,擴充為 2,特征圖尺度減少一倍;中間的512個特征圖是由conv7經過卷積運算生成的,所用的卷積核大小為3×3,步長為1,擴充為1,特征圖尺度未發生變化;后256個特征圖是由conv8_2經過反卷積上采樣操作生成的,所用的卷積核大小為3×3,步長為2,擴充為1,特征圖尺度擴大一倍,其余特征層類似.conv7_ci的多層融合如圖13所示.

Fig.13 Multi-layer fusion of conv7_ci layer圖13 conv7_ci層的多層融合
為使conv4_3層和conv8_2層的特征圖尺寸與conv7層相同,我們對conv4_3層進行下采樣空洞卷積操作,對conv8_2層進行上采樣反卷積操作,然后使用3×3的卷積層學習融合特征.因VGG-16基礎網絡的低特征層與高層數據維度分布差距較大,直接融合效果不好,所以加入BN層(batch normalization layer)進行歸一化處理,3個特征圖在融合之前進行激活操作,最后使用1×1的卷積核進行降維操作,生成最終的特征融合層.
5 實驗及結果分析
第5.1節介紹實驗的運行環境及算法評估指標;第5.2節為基于殘差網絡的航拍目標檢測算法R-SSD的對比實驗;第5.3節為基于特征融合的航拍目標檢測算法CI-SSD的對比實驗.
5.1 實驗環境及算法評估指標
實驗運行環境見表1.
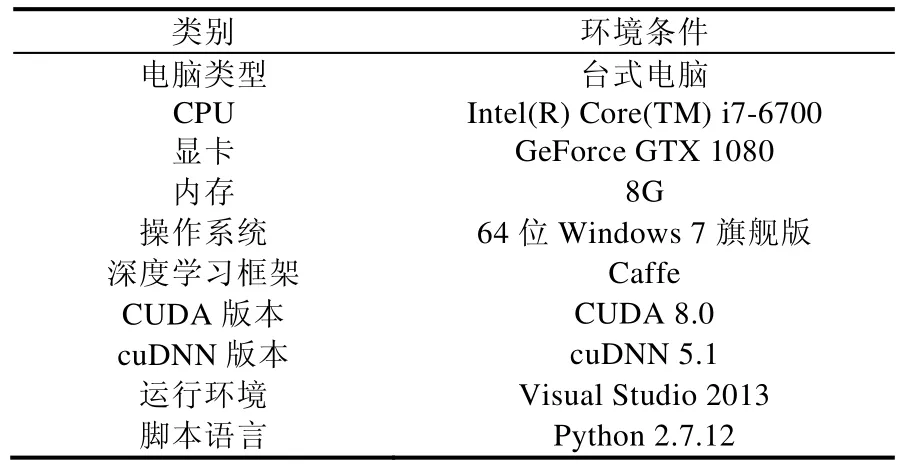
Table 1 Runtime environment of this experiment表1 實驗運行環境
本文所用的算法評估指標如下所述:mAP由精度、召回率和平均值這3部分組成.
· 精度 P(precision)也稱正確率,廣泛應用在信息檢索領域.正確率指返回結果中相關類別占總返回結果的比例,定義為正確率=返回結果中相關類別的數目?總返回結果的數目;
· 與正確率一同使用的是召回率 Recall,召回率指返回結果中相關類別占總的相關類別的比例,定義為召回率=返回結果中相關類別的數目?總的相關類別的數目;
· 由正確率和召回率可求出每一類別的AP曲線,再對所有類的AP取平均值,即可求得mAP:

其中,N代表測試集中圖像數,P(k)表示識別k枚圖像的精度值,Δr(k)表示識別圖像枚數從k-1變化到k時Recall值的變化量,m為所有圖像的類別數.
本文所用的實驗數據來自UAV123(包括行人和車輛共13.7G)[31],VEDAI(1 270枚圖像)[32]等公共數據集和大疆M100無人機在大連海事大學心海湖附近拍攝的圖像數據(1 600枚),將數據分為汽車、卡車、船、飛機、行人等5個類別,訓練樣本如圖14所示,其中,訓練樣本為19 256枚,測試樣本為3 000枚.

Fig.14 Training image sample圖14 訓練圖像示例
訓練參數設置見表2.

Table 2 Training parameter setting表2 訓練參數設置
5.2 基于殘差網絡的航拍目標檢測實驗
(1) 前置網絡替換實驗
前置網絡主要用來進行特征提取,并將產生的目標特征傳遞到后續的卷積層中進行模型訓練.針對航拍圖像目標尺度小、分辨率低等問題,我們將原始SSD算法的前置網絡VGG-16替換為Resnet50,對輸入圖像進行歸一化處理,并增加特征提取層數來提高特征提取能力.前置網絡VGG-16和Resnet50的具體結構見表3,其中,每個單元塊的值為選擇的特征提取層和對應的輸出尺寸.

Table 3 Pre-network parameter comparison table表3 前置網絡參數對比表
如圖15所示,使用Resnet50網絡的模型與原始SSD算法相比具有更高的mAP值,尤其在卡車、飛機這兩類數據集上精度提升比較明顯.

Fig.15 Comparison of detection accuracy of different models圖15 不同模型的檢測準確率對比
表4統計了使用不同基礎網絡(VGG-16和 Resnet50)的兩種算法在無人機數據集上的目標檢測結果,測試集為包含5大類別的3 000枚圖像.使用Resnet50作為前置網絡的R-SSD模型取得了85.2%的mAP.兩個模型在檢測較大物體時(如飛機、卡車等)都有較高的準確率,在識別飛機這一類別上,R-SSD模型達到了最高的mAP值,為88.6%,高于SSD模型的86.4%,提高了2.2%.這是因為Resnet50網絡層更深,特征提取能力更強,檢測效果也更好.對于行人這一類,兩個模型的表現都不是很好,因無人機下拍攝的行人目標較小,發生形變,不利于特征的提取和表達.

Table 4 R-SSD object detection results表4 R-SSD目標檢測結果
(2) 默認框參數實驗
默認框的參數設置直接影響著模型處理不同尺度目標的檢測性能,默認框橫寬比r的分布也會影響目標的檢測準確率.當r分布較為集中時,網絡計算負擔加重但檢測精度卻沒有明顯的提升;當r分布較為分散時,模型的表征學習能力不足.為了測試不同尺寸和橫寬比的默認框對模型的影響,本文設計了如下實驗.
如圖16所示,橫坐標為使用的默認框橫寬比的集合,例如,r=[1/2,1,2]時表示針對當前輸入圖像采用的默認框的橫寬比分別為1/2,1,2(如圖17所示,實線框為目標的真實坐標框,虛線框為選取的默認框的范圍).因R-SSD模型使用了7個卷積層作為后續目標分類網絡的輸入,所以圖16中的4條折線分別代表了當前選取的卷積層使用的不同默認框的個數,其中,折線[3×7]代表7個卷積層中默認框的個數都為 3,即默認框橫寬比分布為[1/2,1,2].當默認框個數n和默認框橫寬比分布r取值為([3,5×6],[1/3,1/2,1,2,3])和([5×7],[1/3,1/2,1,2,3])時mAP值較高,準確率分別為85.2%和85.4%.但采用[5×7]分布的模型與[3,5×6]相比需額外計算6 272個檢測框,這增加了計算復雜度,但性能卻只提高了0.2%,得不償失.因此,本文選擇的默認框參數見表5.

Fig.16 Comparison of detection accuracy of different default boxes aspect ratio圖16 不同默認框橫寬比的檢測準確率對比

Fig.17 Sample of default boxes aspect ratio圖17 默認框橫寬比樣例

Table 5 Model detection results表5 默認框的數量及橫寬比
(3) 綜合性能對比
為了綜合評估模型的檢測能力,本文將R-SSD模型與SIFT+SVM和Faster R-CNN等目前較為流行的檢測算法進行對比,得到的結果見表6.

Table 6 Accuracy comparison of different methods表6 不同方法的準確率對比
從表6可以看出:本文改進的方法無論在原始數據集(未進行數據增強)還是在增強的數據集上都取得了較好的檢測效果,分別取得了 82.5%和 85.2%的準確率,準確率比傳統方法高出近 30個百分點.但在速度方面,R-SSD沒有SSD和傳統方法速度快,這是由于R-SSD為了提高特征提取能力,增加了特征提取層數,犧牲了算法速度.圖18為 R-SSD算法的部分實驗截圖,圖中的矩形框為模型預測的目標全局位置,矩形框左上方為預測的類別和分值.

Fig.18 Detection result of R-SSD algorithm圖18 R-SSD算法檢測結果圖
圖19分別為R-SSD算法的目標誤檢圖、小樣本漏檢圖和目標重復檢測圖.

Fig.19 Error detection result of R-SSD algorithm圖19 R-SSD算法的誤檢結果圖
5.3 基于特征融合的航拍目標檢測實驗
(1) 目標類別檢測實驗
CI-SSD算法的類別檢測結果如圖20所示,與傳統的SSD算法相比,CI-SSD目標檢測算法在各個類別的檢測精度上均有了大幅度的提升,其中,行人類別的準確率提升最為明顯,提高了6%.這是因為CI-SSD網絡結構融合了高層特征向量的語義信息和低層特征向量的位置和邊緣信息,使得模型在保持原有檢測精度的前提下對行人等小目標檢測具有更強的適應性.

Fig.20 Comparison of detection accuracy of different models圖20 不同模型的檢測準確率對比
表7統計了SSD和CI-SSD兩種算法在無人機數據集上的目標檢測結果.本文的CI-SSD目標檢測算法的準確率達到了87.8%,較SSD算法提高了3.6%,較上一節的R-SSD算法提高了2.6%.

Table 7 SSD and CI-SSD object detection results表7 SSD和CI-SSD目標檢測結果
(2) 特征融合實驗
為驗證本文特征融合的有效性,設計了以下幾組對比實驗.
· 第1組為SSD-Diconv:在CI-SSD網絡結構的基礎上去掉反卷積上采樣,保留特征圖空洞卷積下采樣操作,網絡結構如圖9所示;
· 第2組為 SSD-Deconv:在CI-SSD網絡結構的基礎上去掉空洞卷積下采樣,保留特征圖反卷積上采樣操作,網絡結構如圖11所示;
· 第3組為 SSD-Pooling:在CI-SSD網絡結構的基礎上去掉反卷積上采樣和空洞卷積下采樣操作,用池化層進行特征圖下采樣操作.
改進后的CI-SSD算法與SSD-Diconv,SSD-Deconv,SSD-Pooling結果對比如圖21所示.

Fig.21 Comparison of experimental results圖21 實驗結果對比
由圖21可以看出,SSD-Diconv,SSD-Deconv和 SSD-Pooling在檢測精度方面表現均優于 SSD,其中,SSDDeconv表現最為優秀,達到87%的準確率,這說明高層的語義和低層的邊緣紋理等信息均能提高模型的檢測精度.其中,SSD-Deconv精度高于SSD-Pooling,說明本文采用的空洞卷積操作與池化操作相比,在進行特征融合時保存了更多的圖像信息.實驗結果表明,本文提出的基于特征融合的航拍目標檢測算法 CI-SSD準確率最高,為87.8%.
(3) 綜合性能對比
為了評估CI-SSD算法的綜合性能,本節將CI-SSD與SSD,R-SSD進行對比實驗,結果見表8.本文改進的方法無論在原始數據集上還是在增強數據集上都取得了最高的檢測精度,分別為 84.1%和 87.8%.在速度方面,因需要進行不同特征層的信息融合,速度略有下降,但高于R-SSD算法的處理速度,滿足實時性的要求.

Table 8 Comprehensive comparison of different methods表8 不同方法的綜合對比
圖22為部分實驗截圖,測試數據集與上節相同,圖中的矩形框為模型預測的目標位置,矩形框左上方為預測的類別和分值,不同的邊框顏色代表不同的目標分類.

Fig.22 Comparison of detection result between R-SSD and CI-SSD圖22 R-SSD和CI-SSD的檢測結果對比

Fig.22 Comparison of detection result between R-SSD and CI-SSD (Continued)圖22 R-SSD和CI-SSD的檢測結果對比(續)
圖22(a)中,R-SSD誤將地標建筑檢測成車,CI-SSD糾正了這一誤標.在圖22(b)中,針對卡車這一目標,R-SSD將其檢測為卡車和車,出現了重復檢測,而 CI-SSD沒有出現該錯誤.圖22(d)中,R-SSD漏檢了上方小車,CI-SSD成功將其檢測成車.與傳統 SSD目標檢測算法相比,CI-SSD算法檢測精度更高,尤其在小目標物體的檢測上更有優勢.實驗結果表明,本文改進的算法有效提高了無人機圖像中目標檢測的準確率.
6 總 結
針對無人機目標檢測分辨率低、遮擋、小目標漏檢、重復檢測、誤檢等精度低下問題,本文在 SSD算法的基礎上,用表征能力更強的殘差網絡進行基準網絡的替換,用殘差學習降低網絡訓練難度,提高目標檢測精度;引入跳躍連接機制降低提取特征的冗余度,解決層數增加出現的性能退化問題;引入不同分類層的特征融合機制,把網絡結構中低層視覺特征與高層語義特征有機地結合在一起.算法的準確率達到了87.8%,較SSD算法提高了3.6%.實驗結果表明,圖像預處理、特征融合能夠提高目標檢測的精度,滿足實時性要求;增加網絡層次和深度雖能提高目標檢測的精度,但是計算量的增加嚴重影響了目標檢測實時性.接下來,將裁減基礎網絡,優化特征融合的程度,以期進一步提高檢測精度和實時性,促進無人機核心技術的快速發展.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
