面向高維特征和多分類的分布式梯度提升樹?
2019-04-18 05:07:20江佳偉符芳誠邵鎣俠
軟件學報 2019年3期
關鍵詞:特征
江佳偉,符芳誠,邵鎣俠,崔 斌
1(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
2(北京郵電大學 計算機學院,北京 100876)
梯度提升樹(gradient boosting decision tree,簡稱 GBDT)是一種使用 Boosting策略的集成機器學習算法.集成機器學習算法通常使用Bagging,Boosting,AdBoost等策略[1,2],基本思想是訓練多個弱分類器來生成更準確的結果.GBDT使用的 Boosting策略通過依次學習多個弱學習器不斷地提升性能,梯度提升樹使用樹模型作為弱學習器.梯度提升樹算法在分類、回歸、排序等諸多問題上取得了優異的性能[3-5],在學術界和工業界中被廣泛地使用[6],也是例如Kaggle等數據競賽中最受歡迎的算法之一.在大數據時代,由于單機的計算能力和存儲能力有限,無法有效地處理動輒達到TB甚至PB級別的數據,因而需要在分布式環境下設計和執行梯度提升樹算法,分布式梯度提升樹算法因而成為目前的研究熱點.
梯度提升樹算法的訓練主要包括3個關鍵過程.
1) 建立梯度直方圖.對于給定的損失函數,對輸入的訓練數據,計算它們的梯度,將所有的梯度數據組織成梯度直方圖的數據結構;
2) 尋找最佳分裂點.根據建立的所有特征的梯度直方圖,計算出樹節點的最佳分裂點,包括特征和分裂特征值;
3) 分裂樹節點.根據計算出的最佳分裂點來分裂樹節點,建立子節點,根據分裂點將訓練數據劃分到子節點上,并回到步驟1)開始下一輪迭代.
在分布式環境下設計機器學習算法,有數據并行和特征并行兩種策略:數據并行將訓練數據集按行進行切分,每個計算節點處理一部分數據子集;而特征并行將訓練數據集按列進行切分,每個計算節點處理一部分特征子集.已有的分布式梯度提升樹系統,例如MLlib[7],XGBoost[8],LightGBM[9,10]等,通常使用數據并行策略在分布式環境下訓練.目前,沒有工作系統性地比較數據并行和特征并行策略的優劣,數據并行是否在所有情況下都能取得最佳的性能,是一個仍然未被討論和解決的問題.
筆者發現,在多種情況下,采用數據并行的分布式梯度提升樹算法會遇到性能瓶頸:一方面,在梯度提升樹算法所處理的多種問題中,多分類問題由于較高的計算復雜度和空間復雜度,采用數據并行的梯度提升樹算法目前無法在分布式環境下有效地處理;另一方面,隨著各行業的飛速發展,數據的來源越來越多,因而數據集的特征維度越來越高,這樣的高維特征給數據并行的梯度提升樹算法帶來了新的挑戰.為了解決以上存在的問題,本文關注在高維特征和多分類問題下如何高效地訓練分布式梯度提升樹算法.
在分布式環境下訓練梯度提升樹算法時,數據并行和特征并行采用不同的方式:數據并行策略將訓練數據集按行切分到計算節點,計算節點建立局部梯度直方圖,然后通過網絡匯總計算節點的局部梯度直方圖;特征并行策略將訓練數據集按列切分到計算節點,計算節點建立梯度直方圖并計算出最佳分裂點,然后通過網絡交換分裂結果.由于梯度直方圖的大小與特征數量和類別數量成正比,對于高維和多分類問題,數據并行需要通過網絡傳輸大量的梯度直方圖,因而存在性能不佳的問題.相比之下,特征并行需要通過網絡傳輸的數據只與數據量大小有關,因而更適合高維和多分類的場景.
為了使用梯度提升樹算法高效地求解高維和多分類問題,本文提出了一種基于特征并行的梯度提升樹算法FP-GBDT.通過從理論上比較數據并行和特征并行,本文證明特征并行更適合高維和多分類場景,然后設計了特征并行的分布式梯度提升樹算法.本文的貢獻可以總結如下:在提出代價模型的基礎上,從理論上比較了數據并行和特征并行兩種訓練策略的開銷,證明對于高維和多分類數據集,特征并行具有較小的網絡開銷、內存開銷和可擴展性;提出了基于特征并行的分布式梯度提升樹算法FP-GBDT.首先,設計了一種分布式矩陣轉置方法轉換數據表征;然后,在建立梯度直方圖時使用了稀疏感知的方法;最后,在分裂樹節點時提出了比特圖壓縮方法來減少數據傳輸;通過與現有分布式梯度提升樹算法進行詳盡的實驗比較,證明了FP-GBDT算法的高效性.
本文第 1節介紹梯度提升樹算法的預備知識和相關工作,包括算法模型和訓練方法.第 2節從理論上比較數據并行和特征并行的開銷.第3節介紹FP-GBDT算法的細節.第4節給出實驗對比結果.第5節總結全文.
1 預備知識及相關工作
在本節中,主要介紹研究對象梯度提升樹算法的模型和訓練方法.其中,第 1.1節介紹數據集表征,第 1.2節簡要介紹梯度提升樹算法,第1.3節介紹梯度提升樹的訓練方法,第1.4節介紹分布式梯度提升樹的研究進展.
1.1 輸入數據集
1.2 梯度提升樹算法概述
梯度提升樹算法是基于樹的集成機器學習方法[8],梯度提升樹算法會依次訓練多個回歸樹模型.在一棵樹中,從根節點開始,每個樹節點需要給出一個分裂規則,此分裂規則包括分裂特征和分裂特征值,根據分裂規則將數據樣本切分到下一層的子樹節點,最終,每個數據樣本xi被分配到一個葉子節點,葉子節點將其上的數據樣本預測為w.與決策樹不同之處在于:梯度提升樹的葉子節點給出的是連續值,而不是類別,在訓練完一棵樹之后,將w加到每個數據樣本的預測值上,然后以新的預測值開始訓練下一棵樹.梯度提升樹累加所有樹的預測值作為最終的預測值[1]:
其中,T是樹的數量,ft(xi)是第t棵樹的預測結果,η是一個叫學習速度的超參數.
圖1展示了梯度提升樹算法的例子,目的是預測一個購物網站上用戶的消費能力.
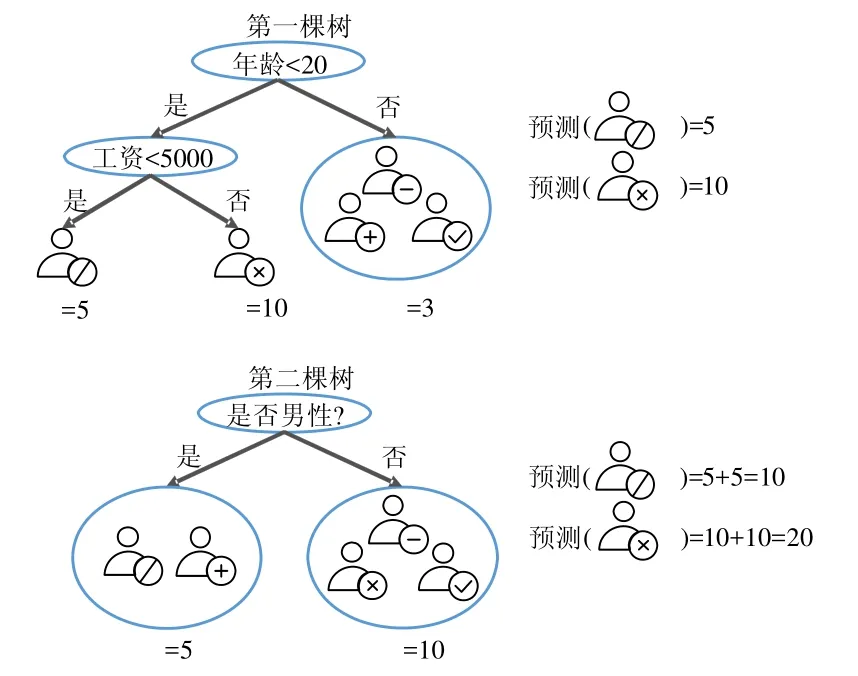
Fig.1 An example of gradient boosting decision tree圖1 梯度提升樹算法示例
第1棵樹使用年齡是否小于20和工資是否小于5 000作為分裂規則,得到第1棵樹的預測值,并以此更新數據樣本的預測值;接著,以新的預測值開始訓練第2棵樹,第2棵樹以是否為男性作為分裂規則,得到第2棵樹的預測值.最終的預測值為兩棵樹的預測值之和,例如,標識為“/”的用戶,預測值為5加上5,等于10.
1.3 訓練方法
梯度提升樹算法是有監督機器學習算法,其目標是最小化一個目標函數,對于梯度提升樹來說,在建立第t棵樹時,需要最小化以下的代價函數:
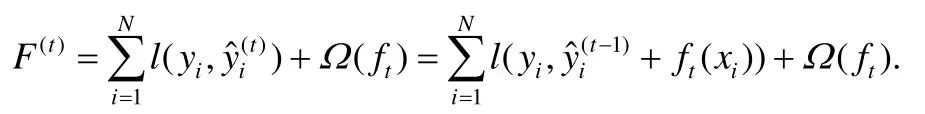
這里,l對于真實值和預測值給出損失,例如,logistic損失,square損失.Ω是正則項,可以避免過擬合.依照XGBoost的選擇[8],選擇如下的正則項:
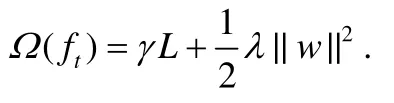
L是樹中葉子節點的數量,w是葉子節點的預測值組成的向量,γ和λ是超參數.LogitBoost算法用二階近似來擴展F(t):
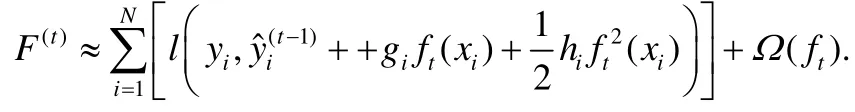
這里,gi和hi是數據的一階和二階梯度:.用Ij={i|xi∈leafj}代表屬于第j個葉子節點的數據樣本的集合,去掉常數項之后,可以得到F(t)的近似表達:
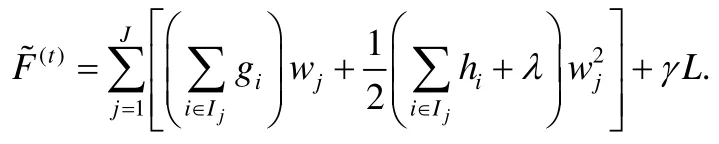
根據以上的公式,第j個葉子節點的最佳預測值和最佳目標函數是:
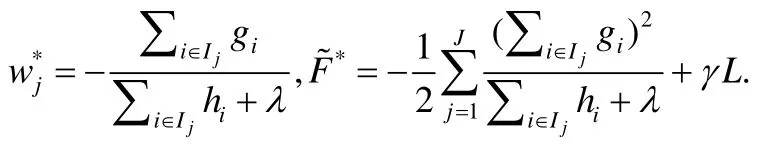
以上的結果假設已經知道樹的結構和數據樣本的分布,可以遍歷所有可能的樹結構和數據樣本分布來找到最佳的解.但是這種方法的計算復雜度太高,在實際中不可行.因此,現有的方法采用一種貪心的方法,從根節點開始逐層地分裂樹節點,見算法1.
算法1.訓練梯度提升樹的貪心分裂算法.
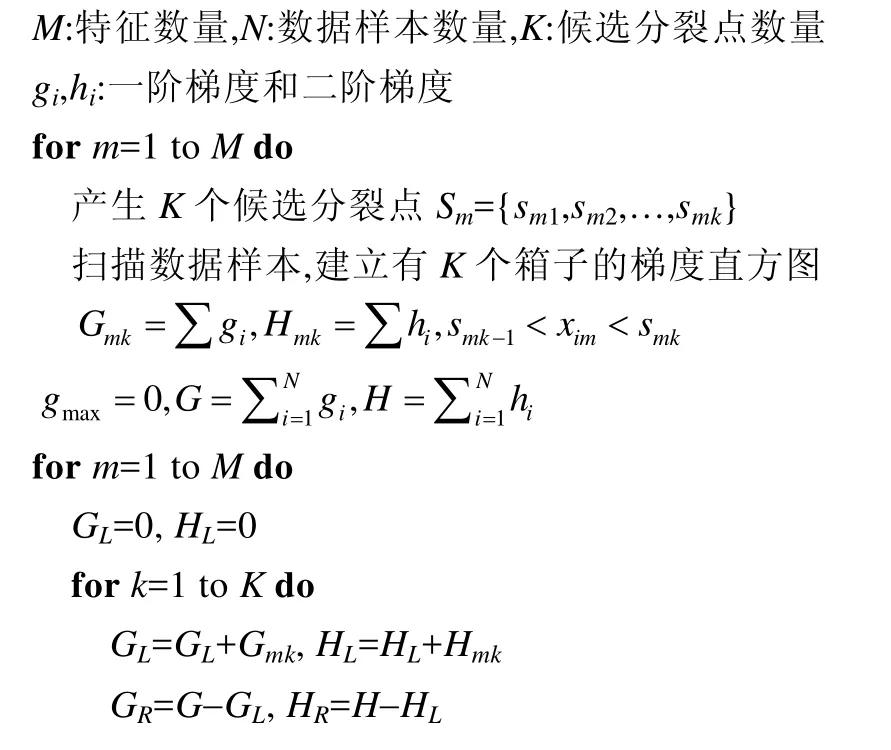

輸出增益最大的分裂結果
在計算一個樹節點的最佳分裂點時,首先對每個特征計算出K個候選分裂點,然后掃描一遍所有數據樣本,用梯度數據建立梯度直方圖.例如:Gmk對應第m個特征,累加所有對應特征值處在第k-1和第k個候選分裂點之間的數據樣本的一階梯度;Hmk以同樣的方式累加二階梯度.建立完所有特征的梯度直方圖之后,根據下面公式找到代價函數增益最大的分裂結果:
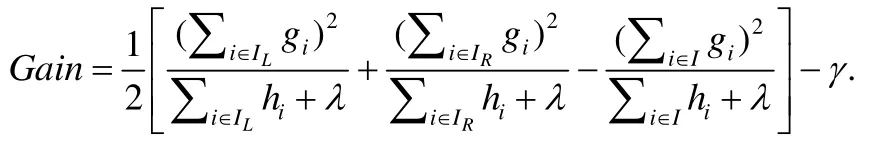
這里,IL和IR代表分裂之后的左子節點和右子節點.選擇候選分裂點有多種方式,精確的方法依據每個特征對所有數據樣本進行排序,然后選擇所有可能的分裂點.但這種方法需要反復地排序,在數據量很大時,計算開銷和時間開銷過于昂貴.另外一種叫分位數據草圖的方法使用基于概率的近似數據結構,對每個特征產生對應特征值的近似分布[11].經典的分位數據草圖的算法是GK[12],基于GK的變種有DataSketches[13]和WQS[8]等.
梯度提升樹算法中,兩種避免過擬合的方法是衰減和特征下采樣:衰減方法在累加樹的預測值時乘以一個叫做學習速度的超參數η;特征下采樣方法對每棵樹采樣一個特征子集,這種方法被證明能夠加快訓練速度和提高模型的泛化能力.
1.4 分布式訓練
目前已經有一些研究工作提出了分布式梯度提升樹算法,例如 XGBoost[8],LightGBM[10],TencentBoost[14],DimBoost[18]等.XGBoost由華盛頓大學的研究者提出,采用數據并行的訓練模式,在單個計算節點上將數據集按列切分,以列存塊的形式存儲數據樣本,為每個特征值增加一個指針指向其屬于的數據樣本,這樣帶來了很大的額外內存開銷.XGBoost提出了一系列的優化方法,包括一種對數據加權的分位數據草圖算法、一種稀疏感知的尋找分裂點算法、一種將列存塊存儲到磁盤的塊壓縮和塊切分的算法.LightGBM由微軟亞洲研究院的研究者提出,默認采用數據并行的訓練模式,提出了深度優先的策略.實驗證明,這能夠提高準確率.除了數據并行之外,LightGBM 也實現了特征并行.但是這個簡單的實現不支持數據集按列切分,需要在每個計算節點上存儲完整的數據集,這在超大規模數據和真實的工業界環境中是不可行的.TencentBoost和DimBoost由北京大學和騰訊聯合設計,采用數據并行的訓練模式,利用參數服務器[16-18]架構分布式存儲算法模型,以支持高維度的數據集,在建立梯度直方圖階段提出了稀疏感知的算法,只需要讀取數據樣本中的非零特征;同時,用高效的并行機制加速梯度直方圖的建立,在尋找最佳分裂點階段提出了量化壓縮算法減少梯度數據的傳輸.針對參數服務器的特殊架構提出了兩階段的方法,在參數服務器端計算局部最佳分裂點,在計算節點端匯總得到全局最佳分裂點.可以看到,目前的分布式梯度提升樹算法的系統基本都采用數據并行的訓練方式,或者實現的特征并行方式在實際中不可行,不能有效地處理本文針對的高維特征和多分類問題.
2 并行策略比較
將一個串行的機器學習算法并行化,首先需要設計如何將數據樣本在多個計算節點之間分配.常用的并行策略包括數據并行和特征并行.假設訓練數據集是一個矩陣,每一行是一個數據樣本,數據并行按行切分數據集,這樣,每個計算節點負責一個數據子集.與此相對應的,特征并行按列切分數據集,每個計算節點負責一個特征子集.
本節將針對內存開銷和網絡開銷兩個方面,從理論上比較運用兩種并行策略的分布式梯度提升樹算法,并針對本文研究的高維和多分類問題選擇合適的并行策略.為了形式化地描述結果,本文中用到的符號定義見表1,其中,訓練數據集是一個N×D的矩陣,N是數據樣本的數量,D是數據樣本的特征數量;集群中有W個計算節點,梯度提升樹模型包含T棵樹,每棵樹有L層,每個特征的候選分裂點的個數是q;對于多分類問題,用C來表示類別數量.

Table 1 Definition of symbols表1 符號定義
2.1 梯度直方圖大小
梯度提升樹算法的核心操作是建立梯度直方圖和尋找分裂點.梯度直方圖的大小與3個因素有關.
1) 特征維度D.由于需要為每種特征建立兩個梯度直方圖(一階梯度直方圖和二階梯度直方圖),因而梯度直方圖的總數量與2D成比例;
2) 候選分裂點的數量q.一個梯度直方圖中箱子的數量等于候選分裂點的個數;
3) 類別數量C.在多分類問題中,每個梯度數據是一個向量,表示在所有類別上的偏微分,因此,梯度直方圖的大小與C成比例.二分類是一個特例,二分類時C=1.
綜上,一個樹節點的梯度直方圖大小為Sh=8×2×D×q字節,其中,8字節表示一個雙精度浮點數的大小.
2.2 內存開銷
梯度提升樹訓練中的一個技巧是,只要樹節點之間不存在數據重疊,就可以同時處理多個樹節點,代價是存儲更多的梯度直方圖.對于目前普遍采用的逐層訓練的方式,樹的同一層的樹節點之間不存在數據重疊,因而可以同時被處理,樹的深度最大為L,因此,同時處理的樹節點的最大數量是2L-1.
使用數據并行策略時,每個計算節點需要建立所有待處理樹節點上每個特征的直方圖,因此,每個計算節點上梯度直方圖的內存開銷最多是Sh×2L-1.但是用特征并行時,每個計算節點只需要負責計算一部分特征的梯度直方圖,因此內存開銷是Sh×2L-1/W,與數據并行相比要低得多.
2.3 通信開銷
當使用數據并行時,主要的通信開銷是梯度直方圖的匯總.盡管目前存在多種在分布式環境下聚合數據的分布式架構,例如 MapReduce[7],AllReduce[8],ReduceScatter[10],Parameter Server[14-17]等,但是每個計算節點至少需要通過網絡傳輸本地存儲的梯度直方圖,因此,一棵樹需要傳輸的梯度直方圖的大小至少是Sh×W×(2L-1).
當使用特征并行時,由于每個計算節點上存儲著一個特征的全部特征值,因此,梯度提升樹算法不需要在計算節點之間匯總梯度直方圖.但由于按列切分數據集,在尋找最佳分裂點時,每個計算節點從本地存儲的梯度直方圖中計算出一個局部最佳分裂點,然后從所有計算節點中選擇出一個全局最佳分裂點,這樣的代價是只有一個計算節點知道數據樣本的分裂結果,也就是數據樣本被分到左子節點還是右子節點.這樣,在完成樹節點分裂之后,此計算節點需要向其他計算節點廣播數據樣本的位置(左子節點或者右子節點),帶來了一定的通信開銷.這部分的通信開銷與數據樣本的數量成正比,因此當樹的深度增大時,通信量保持不變.綜上,一棵樹的總通信開銷是4×N×W×L字節,其中,4字節表示32位整型數的大小.這樣簡單地實現存在的問題是,直接用整型來發送數據樣本的位置開銷較大.為了解決這個問題,本文提出將數據樣本的位置編碼為比特圖,每個比特代表一個數據樣本的位置,0代表左子節點,1代表右子節點.這種方法能夠顯著降低通信開銷,對于一個L層的樹,總的通信開銷是字節.
2.4 分析結果總結
根據之前的分析結果,使用數據并行策略最多需要Sh×2L-1的內存開銷和Sh×W×(2L-1)的通信開銷,特征并行需要Sh×2L-1/W的內存開銷和的通信開銷.
下面以公開數據集 RCV1-multi為例,定量地比較兩種策略的內存開銷和通信開銷.RCV1-multi數據集有53.4萬個樣本、4.7萬個特征和53個類別,使用8個計算節點建立深度為7的樹,候選分裂點的個數設置為100,每棵樹上梯度直方圖的大小是 3.7GB.當使用數據并行時,建立一棵樹的內存開銷最大是 118.4GB,通信開銷最差情況下總共是 1.8TB;當使用特征并行時,建立一棵樹的內存開銷是 14.8GB,通信開銷是 3.8MB.由此可見,對于高維和多分類問題,特征并行與數據并行相比,在通信開銷和內存開銷上明顯更為高效.
3 算法介紹
本節首先從整體上介紹本文提出的算法FP-GBDT,然后分別詳細介紹FP-GBDT的關鍵技術.
3.1 整體介紹
圖2是FP-GBDT整體工作流程,主要包括以下幾個關鍵步驟.
(1) 訓練數據集存儲在分布式文件系統上,例如 HDFS,GFS,Ceph等,默認的存儲方式是按行切分.FPGBDT從分布式文件系統上加載訓練數據集到計算節點,讀入內存中;
(2) FP-GBDT對訓練數據集執行數據集轉置操作,將原本按行切分的數據集轉換為按列切分的方式,以特征行的方式存儲在計算節點上;
(3) 每個計算節點獨立地建立梯度直方圖.為了有效地處理普遍存在的高維稀疏數據,本文提出了一種稀疏感知的方法來加速梯度直方圖的建立;
(4) 建立完梯度直方圖之后,每個計算節點從本地的梯度直方圖中找出一個局部最佳分裂點,然后通過一個主節點從所有候選中找到全局最佳分裂點;
(5) 產生全局最佳分裂點的計算節點執行分裂樹節點的操作,并產生數據樣本在樹中的位置;然后,使用一種比特圖的壓縮方法發送數據樣本的位置給其他計算節點.
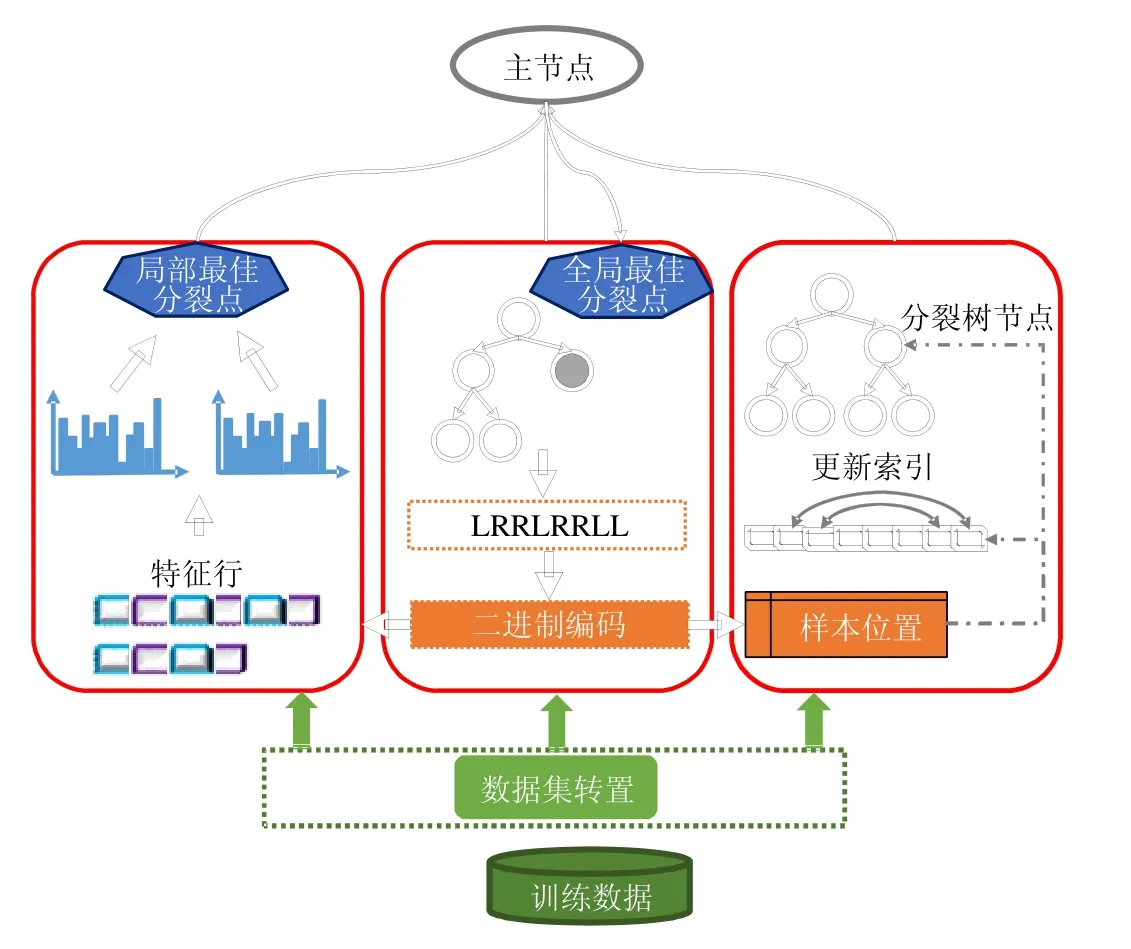
Fig.2 Framework of FP-GBDT圖2 FP-GBDT的架構
3.2 數據集轉置
原始的訓練數據集由多行組成,每行包含了一個數據樣本的特征和標簽.目前的數據集常常是稀疏格式,因此經常將數據樣本的特征存儲為鍵值對的形式,其中,鍵是特征索引、值是特征值.數據集常常按行切分并存儲在分布式文件系統上,例如HDFS等,這種存儲格式天然不適合特征并行,因為特征并行需要在單個計算節點上匯總一個特征的所有特征值.為了解決這個問題,需要在梯度提升樹算法執行之前對訓練數據集進行轉置操作,將按行存儲的數據集轉換為按列存儲的方式.本文設計了一種高效的分布式數據集轉置算法,如圖3所示.

Fig.3 Distributed dataset transposition圖3 分布式數據集轉置
本方法的計算流程包括4個步驟.
(1) 計算數據樣本的偏移.為了唯一標識每個數據樣本,每個計算節點將本地數據樣本的數量發送給主節點,然后,主節點從全局上統計數據樣本的數量,給每個計算節點發送一個全局偏移值,限定了每個計算節點上數據樣本標識范圍.這樣,每個數據樣本的標識就等于計算節點的全局偏移加上本地偏移;
(2) 轉置數據集.每個計算節點對本地的數據樣本進行轉置操作.原始的數據集由樣本行組成,每個樣本行存儲著(特征索引,特征值)的鍵值對.本節的數據集轉置方法將這種數據表示方式轉換為特征行,每個特征行存儲著一個特征出現的所有位置,也就是(樣本索引,特征值)的鍵值對,表示此特征在每個數據樣本中的非零值,這里的樣本索引根據上一步產生的樣本偏移計算而出;
(3) 重切分特征行.由于一個特征的特征值可能存在多個計算節點上,因而每個特征在多個計算節點上存在局部特征行.本方法通過MapReduce操作重切分所有計算節點上的局部特征行,使得每個特征的所有局部特征行在一個計算節點行進行匯總,形成此特征完整的特征行.通過這個操作,每個計算節點負責一個特征子集,存儲著這個特征子集中所有特征的特征行,由(樣本索引,特征值)的鍵值對組成;
(4) 廣播樣本標簽.主節點從所有計算節點收集數據樣本的標簽,然后廣播給計算節點.這些標簽被每個計算節點用來計算數據樣本的梯度.
3.3 建立梯度直方圖
在數據集轉置之后,每個計算節點使用特征行來建立梯度直方圖.首先掃描特征行,為每個特征建立分位數據草圖,然后使用數據草圖產生候選分裂點,具體而言,使用一組 0~1之間的分位值,例如{0,0.1,0.2,…,1.0},從分位數據草圖中查詢出每個特征的候選分裂值.
特征并行策略下,一個計算節點包含了某個特征所有出現的特征值,而數據并行策略下,一個計算節點只包含了某個特征的部分特征值.因此在特征并行策略下,一個樹節點建立梯度直方圖的操作比數據并行策略的計算量更大.由此可見:針對特征并行的特點,設計高效的機制來加速梯度直方圖的建立是非常有意義的.
· 稀疏感知的建立梯度直方圖方法.
建立梯度直方圖需要直接處理數據樣本,要達到優化的目標,應該考慮數據樣本的特點.在實際應用中,很多真實的數據集常常是稀疏的,一個數據樣本中只有一部分非常少的特征有非零值.傳統的建立梯度直方圖的方法需要數據樣本的所有特征值,包括值為零和值非零的特征,因此計算復雜度是O(N×D),這里,N是數據樣本的數量,D是特征數量.對于數據量大、特征維度高的情況,這樣的計算復雜度過高.考慮到稀疏的數據特點和存在的問題,一個直觀的想法是,能否利用數據稀疏性來加速梯度直方圖的建立.基于這樣的思路,本文提出一種稀疏感知的建立梯度直方圖的技術,如圖4所示,主要技術細節如下所述.
(1) 在讀取數據樣本之前,假設數據樣本的所有特征值都為 0.一般情況下會認為特征值為非零是正常情況,特征值為0是異常情況,但真實情況是,數據樣本中大部分特征值為0,從概率的角度來看,特征值為0是大多數情況,而特征值為非零是極少數情況.基于這樣的觀察,本方法在讀取數據樣本之前,假設它們所有的特征值都為0;
(2) 累加數據樣本的梯度.經過數據集轉置之后,每個計算節點上保存著所有數據樣本的標簽,使用數據樣本的標簽和預測值,計算數據樣本的梯度,接著累加所有的梯度;
(3) 將梯度和增加到零桶中.一個特征的梯度直方圖中,每個桶包含特征值的一個區間,這里將零桶定義為包含特征值為零的桶.本方法的第 1步中假設所有特征值都為零,這樣應該將每個數據樣本的梯度放入零桶中,因此,本方法將第2步求得的梯度和加到每個特征的梯度直方圖的零桶中;
(4) 重定位非零特征值.依次讀取特征行存儲的非零特征值,根據特征值的大小找到對應的梯度直方圖的桶,然后將此特征值對應的數據樣本的梯度加到此梯度直方圖桶中;同時,為了保證梯度直方圖的正確性,從零桶中減去此數據樣本的梯度.
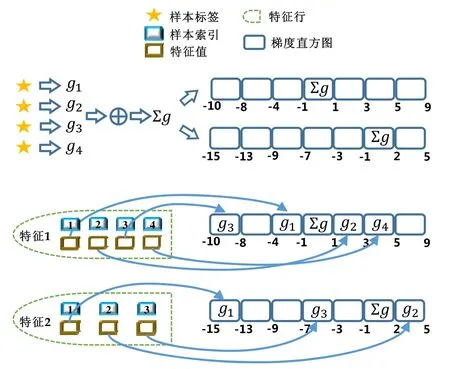
Fig.4 Sparsity-aware histogram construction圖4 稀疏感知的建立梯度直方圖方法
· 計算復雜度分析.
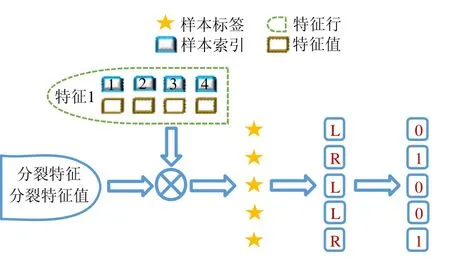
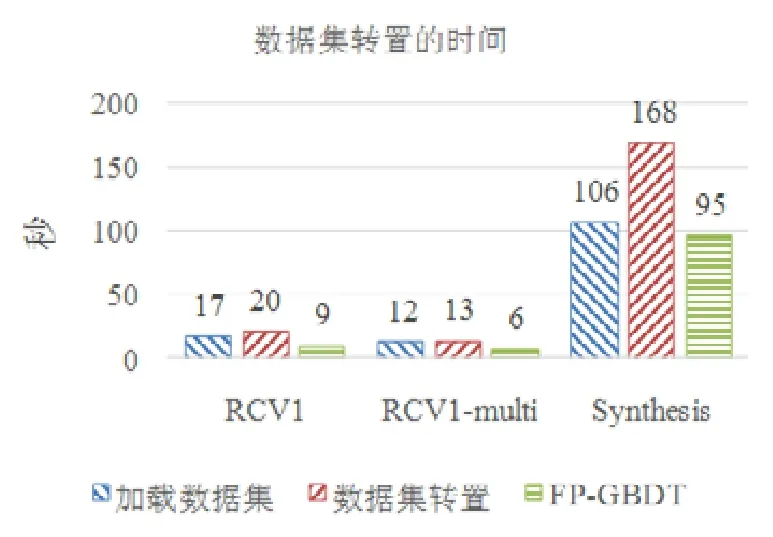
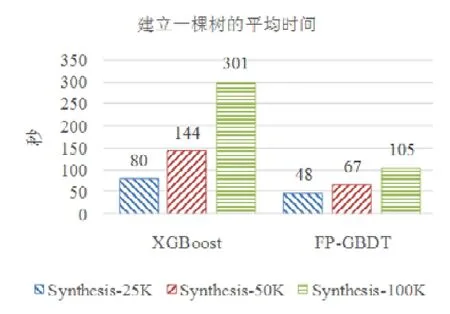
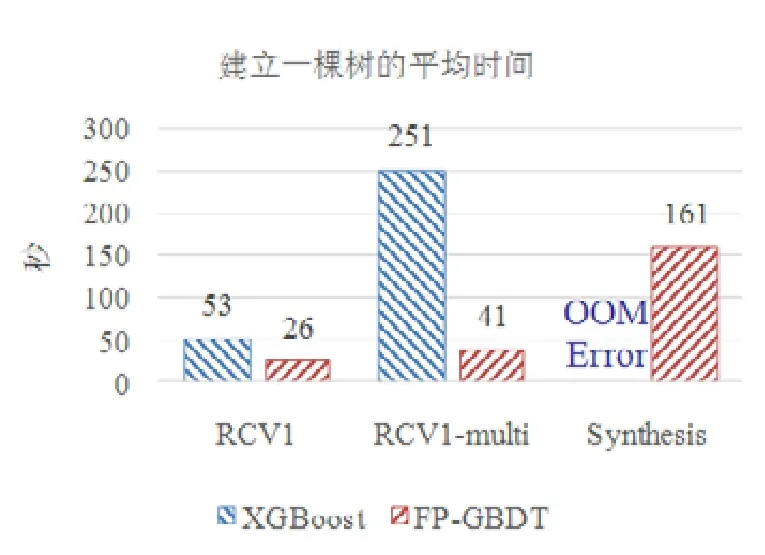
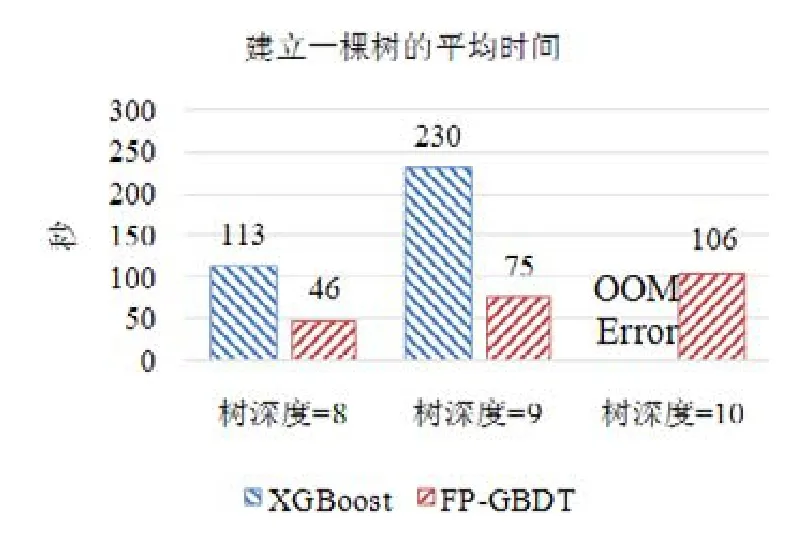
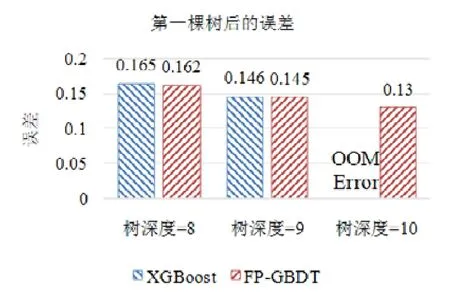
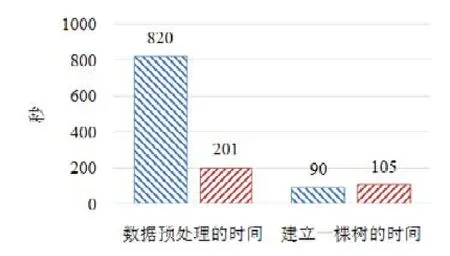
使用本文提出的稀疏感知建立梯度直方圖的方法,首先需要掃描一遍數據樣本計算梯度和,然后將梯度和加到每個特征的梯度直方圖的零桶中,最后掃描一遍非零特征值.這樣的計算復雜度是.這里,N是數據樣本的數量,D是特征的數量,W是集群計算節點的數量,d代表一個數據樣本中非零特征值的平均數量.與傳統方法的計算復雜度O(N×D)相比,由于d< 找到一個樹節點的最佳分裂點后,下一步是分裂樹節點.使用特征并行策略時,某個計算節點產生了全局最佳分裂點,樹節點的分裂結果(數據樣本的位置)也只有此計算節點知道,因而,此計算節點需要將數據樣本的位置廣播給其他計算節點.為了減少通信開銷,本文設計了一種比特圖的方法來壓縮數據樣本的位置,如圖5所示. Fig.5 Bitmap compression圖5 比特圖壓縮方法 · 比特圖壓縮. 如果使用整型的表達方式,廣播數據樣本位置的通信開銷是4×N×W字節.一個數據樣本的位置是左子節點或者右子節點,因此,本方法使用一個比特圖來二進制編碼樣本位置,左子節點編碼為 0,右子節點編碼為 1.使用這種方法,通信開銷降低為N×W/8字節,帶來了32倍的提升.當其他計算節點接收到比特圖后,逐個比特地讀取,然后更新數據樣本在樹中的位置. 除了能夠節省通信開銷,特征并行相比數據并行還有另外一個優勢:當樹的層數加深時,同層樹節點的數量指數增長,數據并行策略下通信開銷也會指數級增長;而使用特征并行策略時,樹的一層的通信開銷與樹節點的數量無關,樹深度的增加不會造成通信開銷的增加. 本節通過詳盡的實驗來驗證FP-GBDT算法的有效性. · 原型實現. FP-GBDT在Spark[19]的基礎上實現,數據存儲在HDFS上,機器學習任務提交到一個8節點的Yarn[20]集群上.每個機器配置了4個E3-1220 v3 CPU,32GB內存和1Gb網絡. · 數據集. 本文的實驗使用了3個數據集,見表2.RCV1[21]和 RCV1-multi[22]是兩個公開的文本分類數據集[23],樣本數量分別為69.7萬和53.4萬,特征數量均為4.7萬,RCV1有2種類別,RCV1-multi有53種類別.Synthesis是一個人造數據集,包含1千萬個樣本和10萬個特征.Synthesis是一個二分類數據集,用來評估本文提出的優化方法的效果和特征維度的影響,RCV1和RCV1-multi的特征相同而類別數量不同,被用來評估類別數量的影響. · 基準方法. 如前所述,目前有多種分布式梯度提升樹算法的實現,例如Mllib,XGBoost和LightGBM等.本文基于兩個原因選擇 XGBoost作為數據并行策略的代表:第一,XGBoost是目前使用最廣泛的分布式梯度提升樹系統;第二,XGBoost有基于Spark實現的版本,因而實驗對比是公平的. · 超參數. 除非另外聲明,對RCV1和RCV1-multi數據集選擇L=7,對Synthesis數據集選擇L=8,計算節點數量W=10.對于其他超參數,候選分裂點數量q=100,學習速度η=0.1,特征采樣率設為1.0,樹的數量設為100. Table 2 Datasets表2 數據集 本節的實驗用來評估本文提出的優化方法,驗證它們的有效性,這些優化方法包括數據集轉置、稀疏感知建立梯度直方圖和比特圖壓縮. · 數據集轉置. 首先展示分布式數據集轉置方法的性能,實驗數據如圖6所示,從HDFS上加載3個數據集的時間分別是17s、12s和 106s.使用簡單的直接數據集轉置,在 RCV1,RCV1-multi和 Synthesis數據集上需要的時間分別是20s、13s和168s;而FP-GBDT執行數據集轉置的操作,在3個數據集上的耗時分別是9s、6s和95s,相比原始的數據集轉置方法,速度得到了最高 2倍的提升.雖然相比于數據并行的策略,FP-GBDT帶來了額外的時間開銷,但是在后面的實驗中將顯示,FP-GBDT顯著提升了整體的性能. · 稀疏感知建立梯度直方圖. 當使用稀疏感知的方法時,對Synthesis數據集,建立樹的根節點的梯度直方圖的時間是9s.但是當不使用這種方法時,在1h之內無法完成建立根節點的梯度直方圖,原因是需要讀取一個數據樣本的所有特征. · 比特圖壓縮. 找到最佳分裂點后,處理分裂樹節點的任務時,FP-GBDT廣播數據樣本的位置時使用比特圖的壓縮方法.本實驗在 Synthesis數據集上訓練梯度提升樹算法,建立一棵樹的總時間開銷中分裂樹節點需要 18s;當使用了比特圖壓縮方法后,此部分時間開銷降低為8s,帶來了2倍的速度提升. Fig.6 Effects of dataset transposition圖6 數據集轉置的效果 4.3.1 FP-GBDT與XGBoost的性能對比 本節的實驗比較FP-GBDT與XGBoost,FP-GBDT使用特征并行策略,XGBoost使用數據并行策略,下面分別評估特征數量、類別數量等因素對結果的影響. · 特征數量的影響. 本文提出的FP-GBDT適合高維特征的數據集,為了評估特征數量對于實驗結果的影響,本文使用Synthesis數據集的一部分特征子集,例如Synthesis-25K代表使用Synthesis數據集前2.5萬個特征,Synthesis-100K代表Synthesis數據集的全部特征.分別用FP-GBDT與XGBoost在Synthesis的多個數據子集上訓練梯度提升樹算法,FP-GBDT與XGBoost對比的實驗結果如圖7所示.當特征數量從2.5萬增加到5萬和10萬時,XGBoost建立一棵樹的時間從80s增加到了144s和301s,性能分別下降了1.8倍和3.7倍.原因是特征數量增大1倍時,梯度直方圖的大小也增加 1倍,XGBoost使用數據并行,通信開銷線性增大,從而造成性能幾乎線性下降;FPGBDT的性能下降較小,分別慢了1.4倍和2.2倍,FP-GBDT使用特征并行,通信開銷與特征數量無關,樹的每一層的開銷一樣,因而只會受到計算開銷增大的影響.總的來說,特征數量增大時FP-GBDT比XGBoost更加高效. · 類別數量的影響. 如前文所分析,對于多分類問題,類別數量對梯度直方圖的大小有直接的影響.為了更好地顯示結果,本實驗選擇了兩分類的RCV1數據集和53分類的RCV1-multi數據集,同時又將RCV1-multi的53類合并為5類.用8個計算節點對這3個數據集訓練梯度提升樹模型,圖8顯示了實驗結果,統計了建立一棵樹的平均時間.在2分類上的RCV1數據集上,XGBoost平均需要53s訓練一棵樹,而FP-GBDT只需要26s,訓練速度快了2倍,所以FP-GBDT的收斂速度比 XGBoost快得多.在 5分類的RCV1-multi數據集上,XGBoost需要251s訓練一棵樹,FP-GBDT只需要41s,快了6.1倍.類別增加到5類時,梯度直方圖的大小增大了5倍,XGBoost的性能下降了接近5倍,而FP-GBDT只慢了1.5倍,這說明FP-GBDT更適合多分類問題.當使用53類的RCV1-multi數據集時,FP-GBDT訓練一棵樹需要 161s,而 XGBoost出現了內存溢出(out of memory,簡稱 OOM)的錯誤,這證明了XGBoost使用的數據并行策略的內存開銷較大.總的來說,FP-GBDT比XGBoost更適合多分類任務,特別是類別數量較大的情況. Fig.7 Impact of feature dimensionality圖7 特征數量的影響 Fig.8 Impact of class number圖8 類別數量的影響 · 樹深度的影響. 接下來的實驗將評估樹的深度對性能的影響.一般來說,樹的深度越大,訓練時間越長,模型準確率更高.本實驗在RCV1數據集上訓練梯度提升樹算法,逐步地增加樹的深度,實驗結果顯示在圖9和圖10中. 深度增大時,XGBoost和 FP-GBDT的誤差均下降,證明更深的樹可以提高模型的準確率,代價是訓練時間的增大.當樹的深度從8增大到9時,數據并行策略下梯度直方圖的大小增大1倍,因此,XGBoost的運行速度慢了2倍;繼續將樹的深度增大到10時,XGBoost出現了內存溢出的錯誤. 與此相對應,FP-GBDT使用特征并行,能夠高效地處理更深的樹,樹的深度增大時,每一層的通信開銷保持不變,因此性能下降較為平穩,在可接受范圍之內;同時,FP-GBDT的內存開銷較小,樹的深度增加時沒有出現資源不足的情況. Fig.9 Impact of tree depth (time to build one tree)圖9 樹深度的影響(建立一棵樹的平均時間) Fig.10 Impact of tree depth (error after the first tree)圖10 樹深度的影響(第1棵樹后的誤差) 4.3.2 FP-GBDT與LightGBM的性能對比 如第1.4節所述,LightGBM也實現了一個特征并行的梯度提升樹算法,但是LightGBM的實現需要每個計算節點上已經存有完整的數據集,訓練時,LightGBM 將整個數據集加載進內存,這樣,LightGBM 不需要進行數據集轉置的處理,也不需要在節點之間廣播分裂后數據樣本的位置.嚴格意義上,這不是一種真正的特征并行方式,在真實的應用中,單機的內存常常無法存儲完整的數據集;在真實的環境中,數據集常常以存儲在分布式文件系統上,LightGBM在這種情況下無法工作.因此,LightGBM的特征并行實現無法用在實際中. 但是為了給出更加全面的結果,本節使用Synthesis數據集比較了FP-GBDT和LightGBM的性能,實驗設置與之前的實驗保持一致.由于LightGBM無法從分布式文件系統讀取數據,首先使用hadoop fs命令從HDFS上下載到每一個計算節點上,在所有計算節點下載完成之后,在每個計算節點上啟動 LightGBM,從 HDFS下載數據集加上本地讀取數據的總時間是LightGBM的數據預處理的時間. 圖11給出了實驗結果,FP-GBDT的數據預處理(包括加載數據集和數據集轉置)時間是201s,而LightGBM需要 820s來對數據進行預處理,比 FP-GBDT慢了 4倍多;在訓練階段,FP-GBDT建立一棵樹的平均時間是105s,LightGBM需要90s;在內存開銷方面,LightGBM由于需要在每個節點上存儲完整的數據集,因此每臺機器上消耗了30GB的內存,是FP-GBDT的內存開銷的6倍.總體來看,LightGBM單棵樹的速度略快.這主要是因為每個計算節點加載完整的數據集,從而避免了通過網絡傳輸數據樣本的分裂位置;很多工業界的數據集大小常常達到 TB級別,單個計算節點的內存顯然無法存儲這樣大的數據集;對于存儲在分布式文件系統上的數據集,LightGBM 首先需要將數據集下載到每個計算節點上,這帶來了很大的開銷.因此,對于較小的數據集和實驗室級別的環境,并且資源較充裕時,LightGBM 是一個不錯的選擇;但是對于較大的數據集和真實的生產環境,LightGBM常常是不可用的,而FP-GBDT的適用性很廣,更加適合大數據時代的需求和發展趨勢. Fig.11 Performance comparison of FP-GBDT and LightGBM圖11 FP-GBDT與LightGBM的性能對比 本文研究面向高維特征和多分類問題的分布式梯度提升樹算法.根據一個嚴格的代價模型,比較了數據并行策略和特征并行策略,證明了特征并行策略更適合高維和多分類場景;基于理論分析的結果,本文提出一種使用特征并行的分布式梯度提升樹算法FP-GBDT.FP-GBDT首先利用對數據集進行分布式轉置,轉換為特征并行需要的數據表征;在建立梯度直方圖時,FP-GBDT設計了稀疏感知的方法;在分裂樹節點時,FP-GBDT使用一種比特圖壓縮的方法傳輸數據樣本的位置.實驗結果顯示,FP-GBDT與使用數據并行的 XGBoost相比,性能的提升最高達到6倍以上,證明了特征并行的FP-GBDT在高維和多分類問題上的高效性.3.4 分裂樹節點
4 實驗對比
4.1 實驗設置

4.2 優化方法有效性
4.3 性能對比
5 總 結
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
