基于關鍵屬性匹配的高校人員信息整合研究
2019-04-23 03:29:52,,,,
微型電腦應用 2019年2期
, , , ,
(同濟大學 1.教育技術與計算中心;2.海洋科學技術研究中心;3.信息化辦公室,上海 200092;4.電子與信息工程學院,上海 201804)
0 引言
我國高校信息化經過30年左右的快速發展,逐步重視業務流程優化和服務整合以適應智慧校園建設的需求[1]。由于缺乏統一標準、系統分散管理,造成數據不一致和不完整[2,3]。高校信息化需要通過有效的數據治理手段進一步提高數據質量,實現數據資源在各業務部門的有效整合和共享,使高校變得更加智慧和敏捷[4,5]。
為有效解決當前高校信息化中的數據質量問題,主數據管理受到重視,較好地實現了數據的深度共享和價值發現[6-8]。所謂主數據是信息系統中描述核心業務、實體并且在不同業務系統間共享使用的數據,是企業內部能夠跨業務、跨系統重復使用的高價值數據[9]。高校信息化圍繞“人”、“財”、“物”產生了大量的數據,而“人”的數據是最基本最核心的主數據。因此,同濟大學在進行主數據管理時也從人員出發,設計適合高校人員的主數據模型[10]。高校的人員類型較一般企業復雜,同一個人同時存在多種身份,同時人員管理上也很分散,造成系統數據分散和重復,同一個人在不同的業務系統中,用不同的ID號表達。不同部門信息化管理水平的不同,也使得人員信息的質量參差不齊。只有人員信息經過整合后,才能使高校真正從以業務為核心向以人為核心的轉化成為可能[11]。
將不同業務系統中以不同方式記錄的人員數據,通過一定的算法識別為現實世界中的同一個人,是人員信息整合的基礎。可疑重復處理作為主數據管理的關鍵技術之一,通過設置匹配關鍵元素或預置算法發現可能重復的記錄[12]。高校人員的關鍵屬性包括姓名、證件類型、證件號碼、學號/工號等,本文在深入分析這些關鍵屬性及其各種組合下出現的數據質量問題,提出一種基于關鍵屬性匹配的高校人員信息整合方法,對人員賦予唯一編號標識,在實踐中取得很好的應用效果,并促進高校人員的主數據管理工作。
1 高校人員數據的現狀
高校人員指在高校中學習和工作過的學生和教職工,高校人員數據是由學校相應管理部門納入業務管理系統的人員基本數據,諸如:人員的基本信息、學業信息、崗位信息等。
高校分而治之的管理以及各部門管理力度不一,使得高校中人員數據分散,缺乏統一的人員信息模型,沒有進行一體化管理,造成數據質量問題。主要體現在以下幾個方面:
(1) 人員數據來源多個系統且使用不同的主鍵標識
目前高校人員管理的主要部門為:人事處、教務處、研究生院、留學生辦公室,分別對應管理:教職工、本科生、研究生、留學生,分別對應不同的管理系統,并使用不同的學號或工號(下稱“學工號”)作為主鍵標識。
(2) 同一人員在不同階段角色不一
同一系統中同一人不同階段存在多個身份,如:研究生系統中不同的培養層次,如碩士生升入博士生,同一個人有不同的學號對應;人事系統中,從博士后、到派遣人員、到編制類人員或高研院人員,同一個人不同階段有不同的工號對應。同一人同一身份在不同系統中,如本科長學制學生,在完成學業申請碩士學位前會以同一學號進入研究生系統,同一身份同時存在于兩個系統。不同時期擁有相同的身份,如未取得學位的博士生幾年后重新考取繼續博士學位攻讀,博士生階段就有不同的學號對應。
(3) 源頭數據錄入帶來的數據質量問題
源頭數據甚至是關鍵數據都可能出現重復、不一致、不完整的情況。如:姓名拼寫錯誤,證件號等關鍵信息為空,簡體或繁體,縮寫或全稱,重復分配學工號,文本字段的不規范填寫等。
(4) 歷史數據遺留帶來的數據質量問題
高校的人員管理系統已經運行多年,早期存在一些數據質量相對較低的人員信息,特別是人事系統中,上百年的教職工信息以及并校等原因,使得有些人員的關鍵信息不完整、不準確,且無從追查。
高校數據治理中最重要的一環是人員數據的治理,而人員信息的整合是數據治理的第一步。
2 高校人員信息整合的方法
人員數據是高校所有核心數據中的主數據,是學校所有業務運行的基礎,其數據質量的好壞直接影響到對師生管理和服務水平的提高。
2.1 總體思路
將一個人多個系統中不同階段的多個身份,通過算法將其識別為同一個人,并用校內唯一的人員唯一編號PID(Person ID)予以標識,即將人次轉化為人,根據設計的一體化人員信息模型,對其全生命周期進行管理,將不同階段的信息作為其全生命周期的一個片段,即達到人員整合的目的,如圖1所示。

圖1 高校人員信息整合的總體思路
2.2 問題分析
解決思路的關鍵在于從現有紛繁復雜的人員信息中判斷是否為同一個人。從圖1看出同一個人的學工號并不唯一,只能作為重要參考信息。而作為人員的關鍵屬性如身份證、姓名等理論上是可以唯一確定的,但是因各種數據質量問題使得判斷依據變得復雜。
(1) 姓名問題
相同的證件號,在不同系統甚至同一個系統中,姓名存在各種差異,如同音字、生僻字用符號或拼音代替、少數名族姓名中間點等等。
(2) 證件號問題
除很多由于歷史遺留問題或留學生護照號獲取有延遲,造成證件號為空的情況外,對于有證件號的數據,也存在身份證號不是15或18位的、年份生日不合規的、含有特殊字符的等問題。
(3) 復合問題
從姓名、證件號單一來看,數據都是規范的,但將數據綜合起來分析時,會發現較多的問題,諸如:兩人共用證件號、兩人共用學工號、同一個人在不同系統中的證件號不同等。
2.3 算法流程
針對前文所述的數據特點和數據質量的現狀,提出人員信息整合的原則:1)定期獲取業務系統的人員數據,并獲得增量變化數據;2)選取關鍵屬性進行組合判斷:姓名+證件號+證件類型+學工號;3)在算法中多層次考慮組合屬性數據質量可能造成的影響判斷的因素;4)算法能處理相對規范化的情況,對于個別異常情況的數據,增加可疑數據人工處理的環節;5)歷史無從確認的數據,對于關鍵屬性不全的,為其執行一次性的初始化算法,當其后續信息不再改變時,這些歷史人員不再納入算法。
根據這些原則,人員整合的算法流程分為3個步驟實施。如圖2所示。
(1) 數據預處理
數據倉庫每天從源頭系統中獲取增量數據,檢查數據關鍵信息的完整性,對證件號進行必要的規范化處理,梳理出具備條件進入下一環節的數據,其過程如圖3所示。
(2) 基于關鍵屬性匹配的人員唯一性識別
采用人員的關鍵屬性:姓名、證件類型、證件號碼(下稱“名”、“類”、“號”)作為基本的判斷條件,輔以學工號作為補充判斷依據,詳細過程如圖4所示。

圖2 高校人員信息整合的算法流程
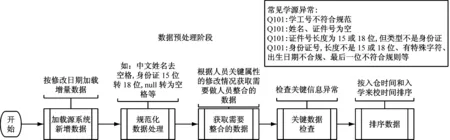
圖3 高校人員信息整合數據預處理

圖4 基于關鍵屬性匹配規則的人員識別
將不同階段用不同身份標識的一個人識別為同一個人,整合后將為其分配唯一編號PID,區別于源業務系統中的學工號(源業務系統為管理需要為人員分配的ID號,下稱“SID”)。
人員整合后,將產生一個完整的PID列表存放一個人的PID及對應的關鍵屬性(即PID信息表,下稱“info表”),另外還有一個表達PID和SID之間關系的列表(即PID與SID關聯表,下稱“rela表”)。通過這兩個列表,可以將人的所有信息表達完整。
對于所有的人員,正常流程主要有兩類,一類是全新的人,第一次進入某一個人員系統,在關鍵組合信息規范完整的情況下,算法為其分配一個新PID;一類是新的身份,諸如升學本校研究生、留校任教、轉編等環節,在關鍵組合信息規范一致的情況下,算法將現有PID和新SID進行關聯。
流程中的異常分支,主要用于處理和識別非正常的情況,如證件號、學工號被共用,錄入時證件號、姓名等關鍵字段不一致等。算法中將這些無法自動識別的信息記錄到異常表中,進入可疑處理環節。
(3) 可疑數據人工處理
對于算法無法處理的異常問題,將其詳細展示并進行人工處理,如圖5所示。由專門人員進行核查,確認需要新增的人員為其分配新的PID,確認是原先存在的人員,將信息合并到原PID中。對于錯誤的信息,則提交源頭系統修正,對于無效的信息,則將異常記錄忽略。
對于與源頭確認修改正確的人員數據,實現合并、失效、更新等操作,將確定正確的修改直接作用到人員整合結果集中。如:當源頭修改了一個現有人員(PID、SID已有)的證件號時,算法拋出Q202異常,并將異常詳細信息展示出來。異常信息經過源業務管理員確認,若是該人員修改了證件號,則將新證件號關聯到原PID上;若是該SID給了一個新進人員使用,則為該人員分配一個新PID,將證件號與新PID進行關聯;若是本次證件號修改為一個誤操作,則將該異常忽略,不做任何改動。
經過人工確認后的異常,如果是需要源系統修改的問題,源頭管理人員操作修改后的數據將進入下一輪的算法整合,正確的修改便直接作用到人員整合結果集中。
主要問題包含:1)數據完整性不夠:如身份證號為空或不符合規范,這類問題須源頭將數據進行完整化后再行處理。2)源頭糾錯產生的各種異常情況需要確認:如源頭發現同一個人分配了多個工號后,將其中一個工號重新分給了另外一個新進校人員等。此類非常規性問題,需要數據源頭進行確認后進行對應操作。3)全量檢查異常問題:源頭系統中人員或歷史數據經過人員整合步驟后,并未為其生成PID的情況。有些異常數據由于師生離校時間太長,源業務管理人員也無法確認其數據的正確性,這些數據將保留在異常數據歷史表中存放,管理人員可方便地在平臺上查看,待時機成熟時再行處理,如圖5所示。

圖5 可疑數據處理
3 高校人員信息整合的實踐效果
以同濟大學為例,從2014年開始建設數據倉庫,現已將所有重要業務系統的重要數據都入倉,并每天抽取一份全量數據,人員整合方案便是建立在數據倉庫的基礎上進行的。
通過人員整合算法,第一步對學校所有在系統中管理的人員實施整合,截止2017年10月20日,將原有的234 519人整合為205 732人,效果如圖6所示。

圖6 高校人員信息整合效果
一個人在校園生活中存在的多個身份也能直觀地展示出來,如圖7所示。
結合人員整合的運維功能,從運維平臺界面上可以直觀地查看每天整合完成的情況,如圖8所示。
4 總結
人員信息整合后形成的人員“黃金視圖”,是精確的、完整的、可信任的人員信息,是提供個性化、精細化、精準服務的基礎。同濟大學于2015年開始引入同心云平臺,成為了學校正式使用的官方云平臺,其中聚集著各類師生的服務應用,有專門針對教師的、有針對學生的、有向全體開放的、有只對研究生開放的等等,這些應用統一通過整合后人員對外提供接口,自動識別用戶是否為該應用的合法用戶。除此之外,整合后的人員信息還正在用于支撐學校的身份認證系統、校級的綜合性應用、校友的精準服務等。
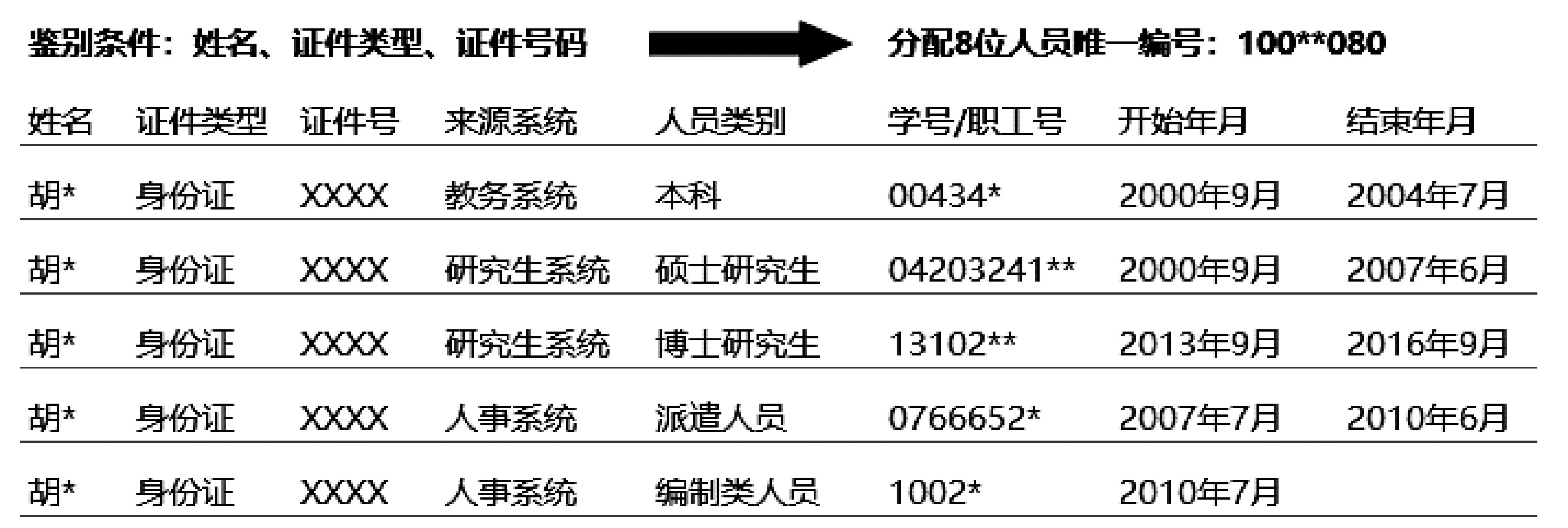
圖7 高校人員的多重身份展示效果
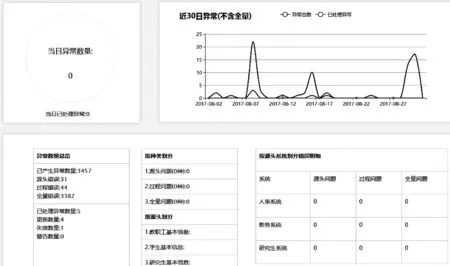
圖8 高校人員信息整合運維平臺
目前人員信息整合還是數據治理的第一步初探工作,焦點主要集中在梳理人員既有數據,致力于形成一套經過整合可信賴的人員庫,目前已經基本達到該既定目標。但人員信息整合和數據治理的目標還遠遠沒有達到,接下來主要從以下兩個方面進一步探索:1)與主數據管理相結合,在人員信息的產生環節就進行人員整合,減少產生數據質量問題的源頭,從而形成更加有效的整合機制;2)探索逐步形成數據治理閉環機制,從數據的產生、整合處理、應用各環節形成閉環,完善數據處理的管理規范,從而長效地促進治理體系和治理能力的提升。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
NBA特刊(2014年7期)2014-04-29 00:44:03
中國商人(2013年1期)2013-12-04 08:52:52
祝您健康(1987年3期)1987-12-30 09:52:32
