基于LSTM-RNN的質(zhì)子交換膜燃料電池故障檢測(cè)方法
2019-04-26 05:03:04王森雷衛(wèi)軍劉健張伯林
電子技術(shù)與軟件工程 2019年4期
文/王森 雷衛(wèi)軍 劉健 張伯林
1 引言
燃料電池是一種將燃料中的化學(xué)能轉(zhuǎn)化為電能的電化學(xué)設(shè)備。只要不斷的有氫氣和氧氣供應(yīng),燃料電池就可以源源不斷地輸出電能,并且反應(yīng)產(chǎn)物中只有純凈的水,而不含其它污染物,是真正意義上的清潔能源。根據(jù)電解質(zhì)和燃料的不同可以將燃料電池分為很多種,其中,質(zhì)子交換膜燃料電池(PEMFC)是非常有前景的燃料電池之一,尤其適用于移動(dòng)應(yīng)用場(chǎng)景。有效的故障診斷策略可以幫助PEMFC電堆在相對(duì)最佳和有效的條件下運(yùn)行,減緩燃料電池性能的下降,增加使用的可靠性和耐久性。因此,精準(zhǔn)的故障檢測(cè)方法具有非常重要的實(shí)際意義。
目前,對(duì)于PEMFC故障檢測(cè)的方法主要包括兩大類:基于推理的方法和基于分類的方法。基于推理的方法主要通過已知或部分已知故障和現(xiàn)象之間的因果關(guān)系,運(yùn)用邏輯推理進(jìn)行故障排查,如故障樹、模糊關(guān)系和專家系統(tǒng)等。這類故障檢測(cè)方法的可釋性強(qiáng),但是模型的準(zhǔn)確度與先驗(yàn)知識(shí)的正確性息息相關(guān)。同時(shí),PEMFC電堆內(nèi)部結(jié)構(gòu)越復(fù)雜,模型的構(gòu)建難度就越大,且模型的準(zhǔn)確度也會(huì)隨之降低很多。
基于對(duì)數(shù)據(jù)進(jìn)行分類的分類算法是近幾年來比較熱門的分類方法,以統(tǒng)計(jì)學(xué)為基礎(chǔ),通過分析各種PEMFC相關(guān)的歷史數(shù)據(jù)或特征參數(shù),對(duì)PEMFC電堆故障進(jìn)行分類預(yù)測(cè)。這類方法不再依賴于先驗(yàn)知識(shí),而是根據(jù)實(shí)際采集的數(shù)據(jù)進(jìn)行建模,屬于一種數(shù)據(jù)驅(qū)動(dòng)的故障檢測(cè)方式。同時(shí),這類故障檢測(cè)方法建模與電堆內(nèi)部結(jié)構(gòu)復(fù)雜程度無關(guān),簡(jiǎn)單快捷且成本低,因此,受到許多研究者的關(guān)注。常見的一些預(yù)測(cè)模型包括模糊聚類、支持向量機(jī)和神經(jīng)網(wǎng)絡(luò)等。其中模糊聚類、支持向量機(jī)等傳統(tǒng)機(jī)器學(xué)習(xí)方法的一般建模流程為數(shù)據(jù)預(yù)處理、特征提取和選擇、模型訓(xùn)練和驗(yàn)證。其中特征提取和選擇是獲得高準(zhǔn)確度模型非常關(guān)鍵的一步,提取和選擇的特征能否表征各類故障將直接影響分類超平面構(gòu)建的正確性,通常特征提取和選擇過程相對(duì)復(fù)雜且需要一定的領(lǐng)域知識(shí),難度比較大。相比傳統(tǒng)機(jī)器學(xué)習(xí)方法,神經(jīng)網(wǎng)絡(luò)是一種仿生物神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和功能的模型,可以自動(dòng)學(xué)習(xí)到故障分類相關(guān)的特征,建立相應(yīng)的預(yù)測(cè)模型,準(zhǔn)確度得到一定的改善。因此,神經(jīng)網(wǎng)絡(luò)在復(fù)雜的非線性系統(tǒng)的故障診斷領(lǐng)域得到了廣泛應(yīng)用。
近年來,深度學(xué)習(xí)技術(shù)得到迅速地發(fā)展,驚人的非線性擬合能力和出色的抽象挖掘能力使得這項(xiàng)技術(shù)的應(yīng)用領(lǐng)域不斷拓展。其中,循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)將時(shí)序的概念引入到網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)中,隱藏層之間的互連結(jié)構(gòu)反映出時(shí)間序列之間的相互影響關(guān)系,但是RNN存在著梯度消失、梯度爆炸和長(zhǎng)期記憶能力不足等問題 。長(zhǎng)短期記憶(LSTM)模型是RNN的一種變體,它通過在網(wǎng)絡(luò)中加入細(xì)胞結(jié)構(gòu)(cell)彌補(bǔ)RNN的不足,從而對(duì)時(shí)序數(shù)據(jù)具有更強(qiáng)地適用性。LSTM模型已經(jīng)被成功地應(yīng)用到許多不同領(lǐng)域的時(shí)序數(shù)據(jù)處理當(dāng)中。其中包括自然語言處理相關(guān)的語音識(shí)別、機(jī)器翻譯、情感分析等,醫(yī)學(xué)相關(guān)的時(shí)序 fMRI 數(shù)據(jù)分類、蛋白質(zhì)二級(jí)結(jié)構(gòu)序列預(yù)測(cè)等,媒體相關(guān)的視頻流數(shù)據(jù)分析,金融相關(guān)的股票指數(shù)預(yù)測(cè),環(huán)境相關(guān)的空氣污染物預(yù)測(cè)等等。而在工業(yè)領(lǐng)域也有少量相關(guān)研究證明了LSTM的適用性,文獻(xiàn)[12]將LSTM模型應(yīng)用于故障時(shí)間序列預(yù)測(cè),并在民航飛機(jī)故障數(shù)據(jù)上實(shí)驗(yàn)證明了LSTM預(yù)測(cè)模型的優(yōu)越性能。文獻(xiàn)[21]將LSTM模型應(yīng)用于鐵水硅含量預(yù)測(cè),發(fā)現(xiàn)LSTM模型預(yù)測(cè)誤差穩(wěn)定,比傳統(tǒng)的統(tǒng)計(jì)學(xué)及神經(jīng)網(wǎng)絡(luò)方法具有更好的預(yù)測(cè)精度。
相比其他分類器,LSTM主要具有以下三點(diǎn)優(yōu)勢(shì):
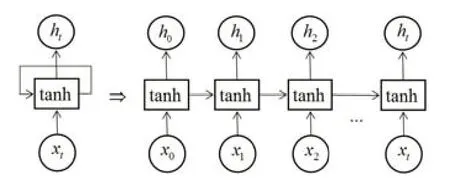
圖1:RNN網(wǎng)絡(luò)結(jié)構(gòu)圖
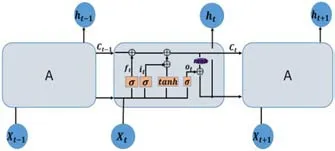
圖2:LSTM網(wǎng)絡(luò)結(jié)構(gòu)圖

圖3:質(zhì)子交換膜燃料電池故障檢測(cè)整體流程圖
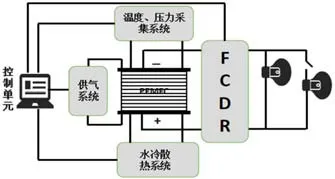
圖4:燃料電池系統(tǒng)結(jié)構(gòu)圖
(1)相比傳統(tǒng)推理的方法,LSTM能夠更加準(zhǔn)確且自動(dòng)地從數(shù)據(jù)中提取特征,模型構(gòu)建簡(jiǎn)單高效、高準(zhǔn)確度。同時(shí),LSTM學(xué)習(xí)的是數(shù)據(jù)集的概率分布,所提取的特征比經(jīng)驗(yàn)更符合數(shù)據(jù)本身的概率分布。
(2)相比傳統(tǒng)機(jī)器學(xué)習(xí)方法,LSTM是一種深度學(xué)習(xí)的方法,可以自動(dòng)學(xué)習(xí)到數(shù)據(jù)更深層次、更具體的特征,因而具有更好的非線性擬合能力和分類能力。
(3)相比于其它深度學(xué)習(xí)方法,屬于循環(huán)神經(jīng)網(wǎng)絡(luò)的LSTM具有長(zhǎng)久的時(shí)間記憶性,隱藏層的結(jié)構(gòu)設(shè)計(jì)體現(xiàn)了時(shí)間序列之間的相互影響關(guān)系,具有更好的時(shí)序數(shù)據(jù)處理能力。
利用LSTM-RNN在分析時(shí)序數(shù)據(jù)方面的天然優(yōu)勢(shì),本文提出將該方法應(yīng)用于質(zhì)子交換膜燃料電池故障檢測(cè),并進(jìn)一步地運(yùn)用貝葉斯優(yōu)化方法選取最佳LSTM模型參數(shù),以獲得簡(jiǎn)單快捷且具有更高準(zhǔn)確度的故障檢測(cè)方法。本文采集實(shí)際PEMFC電堆系統(tǒng)輸出的電壓、電流、母線電壓和母線電流四類數(shù)據(jù)展開實(shí)驗(yàn),無需嵌入其它復(fù)雜昂貴的傳感器監(jiān)測(cè),降低了故障檢測(cè)的成本。同時(shí),本文將LSTM模型與RNN、SVM及神經(jīng)網(wǎng)絡(luò)這三種常見的數(shù)據(jù)驅(qū)動(dòng)模型進(jìn)行實(shí)驗(yàn)對(duì)比。實(shí)驗(yàn)結(jié)果證明,LSTM 模型應(yīng)用于質(zhì)子交換膜燃料電池故障檢測(cè)的準(zhǔn)確度得到提升。
2 基于LSTM-RNN的質(zhì)子交換膜燃料電池故障檢測(cè)方法
本文將在這節(jié)內(nèi)容中描述LSTM-RNN 神經(jīng)網(wǎng)絡(luò)模型的結(jié)構(gòu)、LSTM-RNN應(yīng)用于質(zhì)子交換膜燃料電池故障檢測(cè)的方法和模型參數(shù)的調(diào)優(yōu)。
2.1 LSTM-RNN神經(jīng)網(wǎng)絡(luò)模型
RNN最關(guān)鍵的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)(如圖1所示)在于隱藏層的信息不僅傳遞到輸出層,還傳遞到下一時(shí)刻的隱藏層,從而允許信息的持久化。在訓(xùn)練網(wǎng)絡(luò)時(shí),每次誤差的反向傳遞不僅依賴于當(dāng)前的網(wǎng)絡(luò)狀態(tài),還依賴于之前的網(wǎng)絡(luò)狀態(tài)。這種互相影響的鏈?zhǔn)浇Y(jié)構(gòu)特征正好反映出時(shí)間序列之間的相互影響關(guān)系,進(jìn)而表現(xiàn)出對(duì)時(shí)間序列很好的適用性。
但是由于梯度消失的問題,RNN未能真正表現(xiàn)出長(zhǎng)久的時(shí)間記憶性,也就是在時(shí)間間隔增大時(shí),RNN會(huì)失去學(xué)習(xí)久遠(yuǎn)信息的能力。因此,有了LSTM模型的出現(xiàn)。
LSTM將簡(jiǎn)單的RNN細(xì)胞替換成具有存儲(chǔ)功能的LSTM細(xì)胞,具體結(jié)構(gòu)如圖2所示,由輸入門it,忘記門ft、輸出門ot和細(xì)胞狀態(tài)ct四部分組成。細(xì)胞狀態(tài)貫穿在整個(gè)鏈上,就像傳送帶一樣傳遞著信息流。三種門結(jié)構(gòu)則選擇性地讓信息通過,對(duì)網(wǎng)絡(luò)中的信息流進(jìn)行控制。其中,輸入門決定讓多少新信息加入到細(xì)胞狀態(tài)中;忘記門決定從細(xì)胞狀態(tài)中丟棄什么信息;輸出門基于細(xì)胞狀態(tài)決定最終輸出什么信息。各個(gè)部分的函數(shù)表達(dá)式如下:
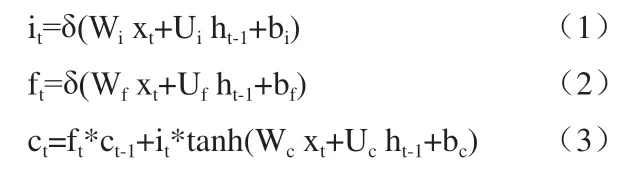

其中,it、ft、ot分別為輸入門、忘記門和輸出門;W為權(quán)值矩陣;U為隱藏層狀態(tài)權(quán)值矩陣;b為偏置項(xiàng);ct為t時(shí)刻的細(xì)胞狀態(tài);ht為t時(shí)刻的隱藏層狀態(tài);δ是激活函sigmoid。
2.2 基于LSTM-RNN的質(zhì)子交換膜燃料電池故障檢測(cè)方法
本文基于LSTM-RNN在分析時(shí)序數(shù)據(jù)方面的優(yōu)勢(shì),提出數(shù)據(jù)驅(qū)動(dòng)的質(zhì)子交換膜燃料電池故障檢測(cè)方法,以期獲得具有更高準(zhǔn)確度的分類器,算法的整體流程如圖3所示。
傳感器采集的數(shù)據(jù)是一種持續(xù)的動(dòng)態(tài)數(shù)據(jù),本文按選定時(shí)間窗口長(zhǎng)度L將所采集的數(shù)據(jù)分割成樣本序列。在t+1時(shí)刻,將傳感器采集到的數(shù)據(jù)進(jìn)行歸一化處理,消除不同維度之間的量綱影響。然后將歸一化后的數(shù)據(jù)與t時(shí)刻LSTM的輸出一起輸入到LSTM,重復(fù)此操作直到長(zhǎng)度為L(zhǎng)的數(shù)據(jù)都輸入到模型中。最后通過輸出層得到最終的分類結(jié)果,輸出層為softmax層,輸出樣本屬于各個(gè)類別的概率。
2.2.1 數(shù)據(jù)集介紹
本文通過采集質(zhì)子交換膜燃料電池電堆的輸出電壓、電流、母線電壓和母線電流四類數(shù)據(jù)。為了獲得質(zhì)子交換膜燃料電池不同運(yùn)行狀態(tài)的數(shù)據(jù),本文通過改變操作條件手動(dòng)引發(fā)電堆故障,例如,增加負(fù)載引發(fā)過載故障,設(shè)置電堆不同的工作溫度制造不同的溫度異常,改變電堆的工作壓力,制造不同的壓力異常。最終,根據(jù)電堆的不同運(yùn)行狀態(tài),將采集的數(shù)據(jù)分為正常、溫度異常、壓力異常、過載等,圖4為燃料電池電堆系統(tǒng)結(jié)構(gòu),圖5為燃料電池測(cè)試系統(tǒng)實(shí)物。
定義數(shù)據(jù)集格式為:[data,label]
其中,data為某種電堆運(yùn)行狀態(tài)的采集數(shù)據(jù);label為人工標(biāo)注的data所屬狀態(tài)類別。
定義data的格式為:[time_step,sensor]
其中,time_step為觀測(cè)時(shí)間窗口內(nèi)電堆運(yùn)行狀態(tài)的采樣點(diǎn)數(shù),維度為L(zhǎng);sensor為采集信息的種類,本系統(tǒng)由4種參數(shù)構(gòu)成,維度為4。
2.2.2 網(wǎng)絡(luò)訓(xùn)練
網(wǎng)絡(luò)訓(xùn)練指的是通過學(xué)習(xí)訓(xùn)練集中的數(shù)據(jù)分布獲取構(gòu)建網(wǎng)絡(luò)所需的所有參數(shù)的過程。首先,將訓(xùn)練集數(shù)據(jù)按式(6)進(jìn)行最大最小歸一化處理,其中xt為t時(shí)刻傳感器所采樣的特征向量,min(x)為訓(xùn)練集數(shù)據(jù)各維度最小值向量,max(x)為訓(xùn)練集數(shù)據(jù)各維度最大值向量。
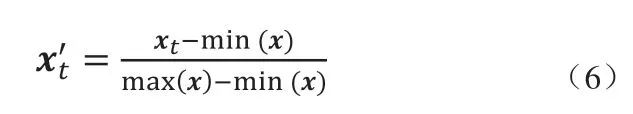
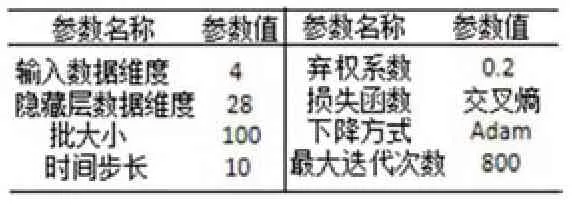
表1:LSTM參數(shù)設(shè)置表
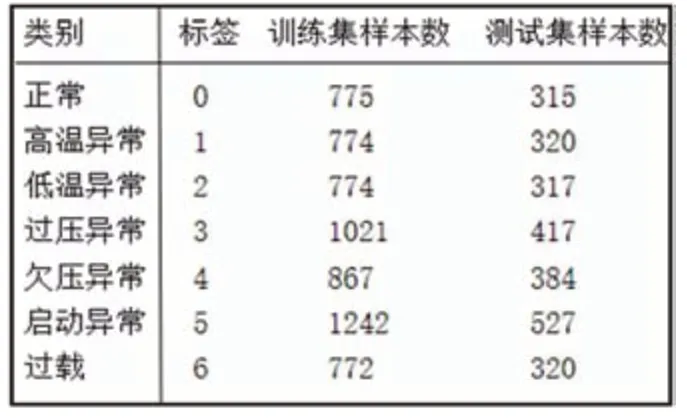
表2:數(shù)據(jù)集樣本類別分布情況表

表3:SVM參數(shù)設(shè)置表
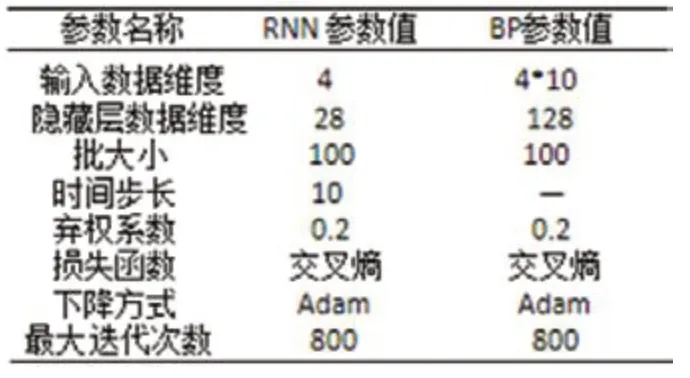
表4:RNN和BP神經(jīng)網(wǎng)絡(luò)的參數(shù)設(shè)置表

圖5:燃料電池測(cè)試系統(tǒng)實(shí)物
為了適應(yīng)LSTM隱藏層輸入的特點(diǎn),應(yīng)用數(shù)據(jù)分割的方法對(duì)訓(xùn)練集數(shù)據(jù)進(jìn)行處理,按時(shí)間窗口長(zhǎng)度L將數(shù)據(jù)分割成data形式的樣本序列,取時(shí)間窗口最后一個(gè)時(shí)刻的電堆運(yùn)行狀態(tài)為data對(duì)應(yīng)的label。
然后逐步將一組樣本序列對(duì)應(yīng)時(shí)刻的特征向量和上一時(shí)刻LSTM模型的輸出同時(shí)輸入到LSTM。在一組樣本序列輸入完畢后,由最終時(shí)刻的隱藏層輸出經(jīng)過權(quán)值矩陣計(jì)算得到網(wǎng)絡(luò)輸出y。再經(jīng)過softmax層將y映射成概率分布y',即樣本序列屬于不同類別的概率。假設(shè)原始網(wǎng)絡(luò)輸出y=[y1, y2, …, ym],m為樣本序列類別數(shù),那么經(jīng)過softmax處理后輸出y'=[y1', y2', …, ym'],計(jì)算公式如下:
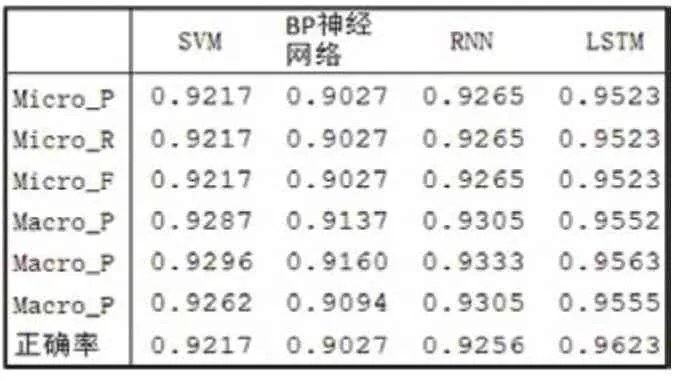
表5:不同算法的微平均、宏平均和正確率
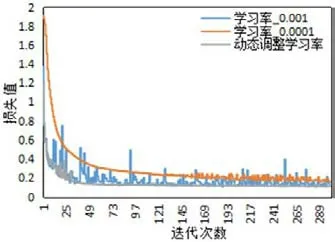
圖6:不同學(xué)習(xí)率的訓(xùn)練損失
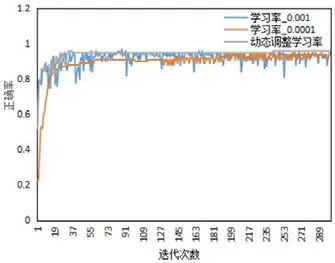
圖7:不同學(xué)習(xí)率的訓(xùn)練正確率
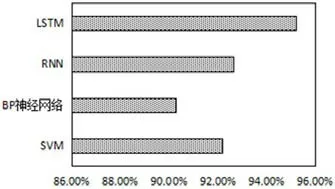
圖8:不同算法的模型正確率
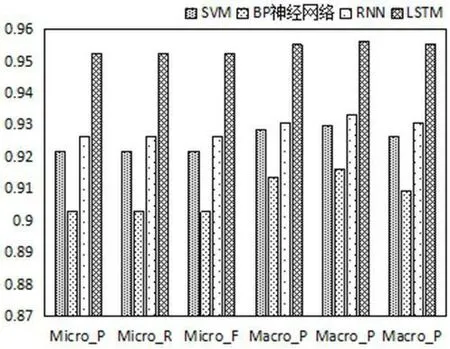
圖9:不同算法的宏平均和微平均
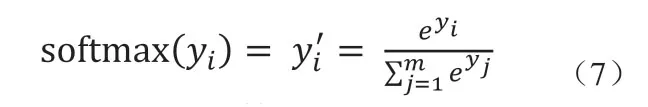
由于故障檢測(cè)屬于多分類問題,所以采用分類交叉熵函數(shù)(categorical crossentropy)作為誤差計(jì)算公式,表達(dá)式如下:

給定網(wǎng)絡(luò)隨機(jī)初始化種子seed、學(xué)習(xí)率learning_rate、隱藏層特征維度hidden_size、整體樣本迭代次數(shù)epoch和每次迭代批大小batch_size,以最小化損失函數(shù)為目標(biāo),計(jì)算誤差函數(shù)對(duì)權(quán)值矩陣的梯度,應(yīng)用Adam優(yōu)化算法不斷迭代更新權(quán)值矩陣,進(jìn)而得到最終的網(wǎng)絡(luò)模型。
2.3 模型參數(shù)調(diào)優(yōu)
超參數(shù)的設(shè)置是否合理極大地影響了模型的最終效果,包括對(duì)訓(xùn)練集數(shù)據(jù)概率分布的擬合程度和對(duì)未知數(shù)據(jù)預(yù)測(cè)的泛化能力。超參數(shù)調(diào)優(yōu)可以看作是以超參數(shù)為自變量的性能函數(shù)f(x)最優(yōu)化問題。

其中,x為某一超參數(shù)組合;A為超參數(shù)組合取值空間。
對(duì)于超參數(shù)調(diào)優(yōu)而言,目標(biāo)函數(shù)f(x)是未知的且為非凸函數(shù),因此,它又被認(rèn)為是一個(gè)黑盒優(yōu)化問題,即優(yōu)化的目標(biāo)函數(shù)通常不滿足凸優(yōu)化條件,無法通過求導(dǎo)或凸優(yōu)化方法求得最優(yōu)解。目前,在眾多機(jī)器學(xué)習(xí)超參數(shù)優(yōu)化方法中應(yīng)用較為廣泛的分別是網(wǎng)格搜索、隨機(jī)搜索和貝葉斯優(yōu)化。網(wǎng)格搜索的核心是通過遍歷搜索范圍內(nèi)所有的超參數(shù)組合確定最優(yōu)值。這樣的搜索方案雖然簡(jiǎn)單,但隨著超參數(shù)個(gè)數(shù)的增加,超參數(shù)的組合近似爆炸性增長(zhǎng),十分消耗計(jì)算資源和時(shí)間,所以不適用于超參數(shù)較多的情況。隨機(jī)搜索認(rèn)為在樣本集合足夠大的條件下,隨機(jī)采樣也可以找到目標(biāo)函數(shù)的全局最優(yōu)解或最優(yōu)解的近似。因此,隨機(jī)搜索不再遍歷所有超參數(shù)組合,而是以隨機(jī)選取的方式選擇超參數(shù)組合,并從選擇的組合中返回最優(yōu)結(jié)果。由于隨機(jī)因素的存在,隨機(jī)搜索的結(jié)果不太穩(wěn)定,可能出現(xiàn)效果特別好,也可能出現(xiàn)效果特別差。貝葉斯優(yōu)化算法的基本思想是基于數(shù)據(jù)使用貝葉斯定理估計(jì)目標(biāo)函數(shù)的后驗(yàn)分布,然后再根據(jù)分布選擇下一個(gè)采樣的超參數(shù)組合。相比于前兩個(gè)方法搜索的盲目性,貝葉斯優(yōu)化充分利用已知點(diǎn)的信息學(xué)習(xí)目標(biāo)函數(shù)后驗(yàn)分布,再基于超參數(shù)每個(gè)取值點(diǎn)的均值和方差,有目的的搜索下一個(gè)采樣點(diǎn)。如此不僅大大減少了采樣次數(shù)和尋優(yōu)時(shí)間,而且結(jié)果更易接近全局最優(yōu)。
在LSTM模型構(gòu)建時(shí)涉及眾多的超參數(shù),因此,本文采用貝葉斯優(yōu)化算法對(duì)模型的多個(gè)關(guān)鍵超參數(shù)進(jìn)行調(diào)整:以參數(shù)為自變量,最小化負(fù)的測(cè)試集正確率為目標(biāo)函數(shù),即最大化測(cè)試集正確率,選擇最佳結(jié)果作為參數(shù)設(shè)置,具體如表1所示。
學(xué)習(xí)率也是LSTM的關(guān)鍵超參數(shù)之一,它的設(shè)置極大地影響了網(wǎng)絡(luò)的收斂效果。如果學(xué)習(xí)率太小,網(wǎng)絡(luò)的收斂速度就非常慢;反之,如果學(xué)習(xí)率太大,網(wǎng)絡(luò)容易在局部最優(yōu)點(diǎn)附近來回跳動(dòng),導(dǎo)致不收斂。在網(wǎng)絡(luò)訓(xùn)練初期,損失函數(shù)下降得快,應(yīng)該設(shè)置大的學(xué)習(xí)率,而隨著網(wǎng)絡(luò)訓(xùn)練次數(shù)增加,損失函數(shù)下降的速度逐漸減緩,則應(yīng)該調(diào)整成小的學(xué)習(xí)率。因此,本文初始設(shè)置學(xué)習(xí)率為0.001,隨著訓(xùn)練迭代次數(shù)的增加,逐步降低學(xué)習(xí)率。
3 實(shí)驗(yàn)與結(jié)果分析
本節(jié)將使用實(shí)驗(yàn)采集到的數(shù)據(jù)驗(yàn)證質(zhì)子交換膜燃料電池電堆故障檢測(cè)網(wǎng)絡(luò)的性能,并把SVM、RNN和BP神經(jīng)網(wǎng)絡(luò)設(shè)為對(duì)照組,通過對(duì)比實(shí)驗(yàn)證明LSTM網(wǎng)絡(luò)應(yīng)用于電堆故障檢測(cè)的優(yōu)勢(shì)。
3.1 數(shù)據(jù)集準(zhǔn)備和評(píng)估指標(biāo)
3.1.1 數(shù)據(jù)集準(zhǔn)備
本文采集了約9萬個(gè)數(shù)據(jù),每個(gè)數(shù)據(jù)都包含電堆的電壓、電流、母線電壓和母線電流4個(gè)維度的值。根據(jù)電堆的運(yùn)行狀態(tài)對(duì)這些數(shù)據(jù)進(jìn)行人工標(biāo)注,包括正常、高溫異常、低溫異常、過壓異常、欠壓異常、過載和啟動(dòng)異常,共7種標(biāo)簽。綜合考慮故障檢測(cè)的及時(shí)性、穩(wěn)定性和時(shí)間消耗,本文將時(shí)間窗口長(zhǎng)度L設(shè)置成10,并按2.2.1節(jié)數(shù)據(jù)集格式存儲(chǔ)。數(shù)據(jù)集以7:3的比例隨機(jī)分成訓(xùn)練集和測(cè)試集,用訓(xùn)練集訓(xùn)練網(wǎng)絡(luò)模型,測(cè)試集測(cè)試訓(xùn)練好的模型性能,各個(gè)類別樣本分布情況如表2所示。
3.1.2 評(píng)估指標(biāo)
常見的二分類器評(píng)估指標(biāo)有準(zhǔn)確率(Precision,P)、召回率(Recall,R)以及這兩個(gè)指標(biāo)的調(diào)和函數(shù)F值(F-measure),計(jì)算公式為(10)~(12)。

其中,TP為正確預(yù)測(cè)為正樣本的個(gè)數(shù),TN為正確預(yù)測(cè)為負(fù)樣本的個(gè)數(shù),F(xiàn)P為錯(cuò)誤預(yù)測(cè)為正樣本的個(gè)數(shù),F(xiàn)N為錯(cuò)誤預(yù)測(cè)為負(fù)樣本的個(gè)數(shù)。
類似地,在多分類問題中則用這三個(gè)指標(biāo)的平均值做為分類器的評(píng)估指標(biāo)。根據(jù)平均值的計(jì)算方式不同,可以分為宏平均(Macroaverage)和微平均(Micro-averaging)。宏平均先計(jì)算每一個(gè)類別i對(duì)應(yīng)的準(zhǔn)確率Pi,召回率Ri和Fi值,然后求所有指標(biāo)的算術(shù)平均值Macro_P、Macro_R和Macro_F,計(jì)算公式為(13)~(15);微平均則先計(jì)算所有類別總的Micro_P和Micro_R,然后再計(jì)算Micro_F,計(jì)算公式為(16)~(18)。 電堆故障檢測(cè)屬于多分類問題,所以本文使用宏平均和微平均做為評(píng)估指標(biāo)。

其中m為類別數(shù),Pi、Ri和Fi的計(jì)算公式如(10)~(12)。
此外,本文還計(jì)算了模型的正確率(Accuracy),作為模型整體準(zhǔn)確度的一個(gè)評(píng)價(jià)標(biāo)準(zhǔn),計(jì)算公式為(19)。

3.2 對(duì)照實(shí)驗(yàn)設(shè)置
SVM是故障檢測(cè)領(lǐng)域常見的機(jī)器學(xué)習(xí)算法之一,以最大化支持向量到分類平面的距離為核心。為了解決數(shù)據(jù)非線性可分問題,SVM一方面引入懲罰因子和松弛項(xiàng),降低部分支持向量到分類平面距離要求;另一方面引入核函數(shù),隱性地將低維非線性可分特征映射到更高維線性可分特征空間中。RNN和BP神經(jīng)網(wǎng)絡(luò)均屬于深度學(xué)習(xí)領(lǐng)域的方法,其中RNN和LSTM一樣也是循環(huán)神經(jīng)網(wǎng)絡(luò),而BP神經(jīng)網(wǎng)絡(luò)是目前使用最廣泛的神經(jīng)網(wǎng)絡(luò)之一,能夠?qū)W習(xí)和存儲(chǔ)大量的輸入輸出映射關(guān)系,具有很好的非線性擬合能力。學(xué)習(xí)過程主要是通過反向傳播來不斷調(diào)整網(wǎng)絡(luò)的權(quán)值和閾值,使網(wǎng)絡(luò)的誤差平方和最小。
為了對(duì)比各方法在空間燃料電池故障分類方面的性能,SVM的參數(shù)設(shè)置也采用貝葉斯優(yōu)化方法進(jìn)行調(diào)整,將RNN和BP神經(jīng)網(wǎng)絡(luò)的關(guān)鍵參數(shù)設(shè)置與LSTM一樣。本文SVM參數(shù)設(shè)置如表3所示,RNN和BP神經(jīng)網(wǎng)絡(luò)參數(shù)設(shè)置如表4所示,其中BP神經(jīng)網(wǎng)絡(luò)使用sigmoid激活函數(shù)。
3.3 結(jié)果分析
本文測(cè)試了不同學(xué)習(xí)率對(duì)網(wǎng)絡(luò)收斂效果的影響,包括減少損失函數(shù)和提高模型正確率兩個(gè)方面。測(cè)試結(jié)果如圖6和圖7所示,從中可以看出學(xué)習(xí)率設(shè)置成過大的固定值0.001時(shí),網(wǎng)絡(luò)在局部最優(yōu)點(diǎn)來回跳動(dòng),損失函數(shù)和模型正確率都出現(xiàn)明顯的震蕩現(xiàn)象,網(wǎng)絡(luò)不收斂。相反,學(xué)習(xí)率設(shè)置成固定值0.0001時(shí),網(wǎng)絡(luò)收斂的速度明顯變慢且收斂效果不佳,損失值和正確率都不如動(dòng)態(tài)調(diào)整學(xué)習(xí)率的好。顯然,動(dòng)態(tài)調(diào)整學(xué)習(xí)率的效果最佳,初始學(xué)習(xí)率大,損失函數(shù)下降得快,正確率提升快,迭代一定次數(shù)后,調(diào)整成小學(xué)習(xí)率,網(wǎng)絡(luò)收斂更穩(wěn)定,且收斂結(jié)果更優(yōu)。
為了證明LSTM模型對(duì)空間燃料電池故障序列的分類性能,本文依據(jù)3.1的評(píng)估指標(biāo)和3.2的對(duì)照實(shí)驗(yàn)設(shè)置,進(jìn)行10次重復(fù)實(shí)驗(yàn),取測(cè)試集的平均值作為最終結(jié)果,記錄在表5中,對(duì)比結(jié)果如圖8和圖9所示。
從表5、圖8和圖9可以看出,LSTM的模型性能最佳,正確率達(dá)95%以上,比正確率第二的RNN高出近3%,宏平均和微平均也都在0.95以上,高于其它對(duì)比算法。同時(shí),可以看出RNN和SVM模型分類效果相近,BP神經(jīng)網(wǎng)絡(luò)的分類效果稍差些。結(jié)果證明,LSTM模型能夠充分挖掘空間燃料電池故障序列的特性,具有很強(qiáng)的時(shí)間序列適用性。
為了進(jìn)一步分析LSTM模型對(duì)不同故障的分類效果,本文測(cè)試了LSTM模型的混淆矩陣,橫軸為樣本的真實(shí)標(biāo)簽,縱軸對(duì)應(yīng)預(yù)測(cè)標(biāo)簽,結(jié)果如表6所示。
從表6可以看出,LSTM模型對(duì)故障1和6的分類正確率達(dá)100%,故障2的達(dá)99%以上,故障5的97%以上。相比于其它類別,標(biāo)簽值為3和4的分類正確率稍差,說明模型對(duì)過壓異常和欠壓異常數(shù)據(jù)特征挖掘不夠,區(qū)分能力稍弱。
進(jìn)一步地,本文測(cè)試了同為深度學(xué)習(xí)方法的LSTM、RNN和BP神經(jīng)網(wǎng)絡(luò)的模型訓(xùn)練情況,結(jié)果如圖10和圖11所示。
從圖10和圖11可以看出,針對(duì)訓(xùn)練集LSTM和RNN的訓(xùn)練效果相近,BP神經(jīng)網(wǎng)絡(luò)的效果較差。而測(cè)試集中,LSTM模型的正確率高出RNN近3%,宏平均和微平均也明顯高于RNN。由此,證明了本文的LSTM模型泛化能力比RNN強(qiáng),對(duì)數(shù)據(jù)特征表征更準(zhǔn)確,更真實(shí)地?cái)M合了數(shù)據(jù)的分布情況。
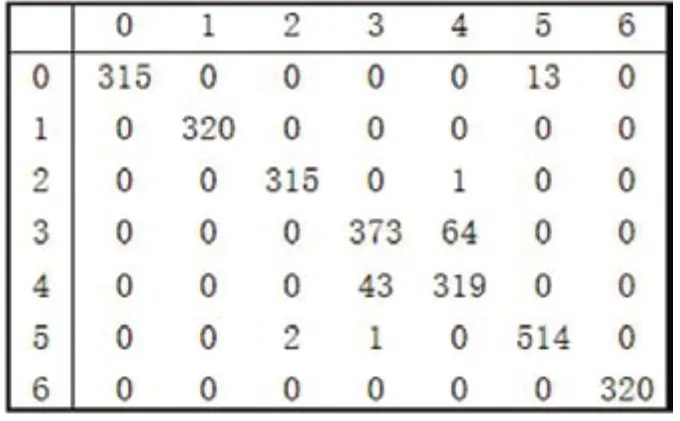
表6:LSTM模型混淆矩陣
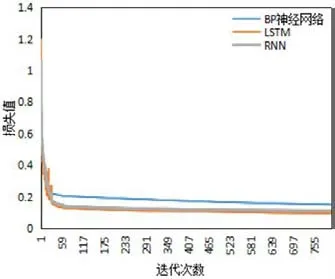
圖10:不同算法的訓(xùn)練損失
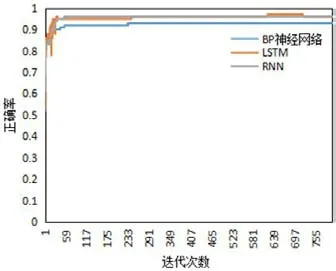
圖11:不同算法的訓(xùn)練正確率
4 結(jié)語
本文針對(duì)空間燃料電池故障序列的時(shí)間特性,利用LSTM模型對(duì)故障序列進(jìn)行分類檢測(cè)。實(shí)驗(yàn)證明,LSTM模型具有很好的時(shí)間記憶性,能夠充分挖掘故障序列時(shí)間特性。對(duì)比LSTM和其它算法的分類結(jié)果,可以看出LSTM的分類正確率、宏平均和微平均都是最優(yōu)的,并且LSTM比RNN具有更好的泛化能力,對(duì)數(shù)據(jù)集的分布擬合得更準(zhǔn)確。由此,說明了本文所提方法的可行性和優(yōu)越性。
另外,本文還證明了不同學(xué)習(xí)率對(duì)LSTM模型訓(xùn)練效果的影響,動(dòng)態(tài)調(diào)整學(xué)習(xí)率不僅可以加快模型的收斂速度,提高模型的穩(wěn)定性,而且可以使模型收斂到更優(yōu)的結(jié)果。同時(shí),本文還具體分析了LSTM模型對(duì)不同故障分類的效果,發(fā)現(xiàn)模型對(duì)過壓故障和欠壓故障的分類效果稍差,需要在后續(xù)工作中改進(jìn)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
