基于數據驅動的全工況下燃氣輪機基準值確定
2019-04-28 10:18:02顧煜炯韓旭東朱俊杰黃元平
自動化儀表 2019年4期
關鍵詞:模型
王 仲,顧煜炯,韓旭東,朱俊杰,黃元平
(1.華北電力大學能源動力與機械工程學院,北京 102206;2.廣東粵電中山熱電廠有限公司,廣東 中山 528445)
0 引言
燃氣輪機因其啟停靈活、污染物排放水平低等優勢,近年來在我國得到飛速發展,裝機容量有了顯著提升[1]。目前,為了保證燃氣輪機運行的安全性,常參照制造廠商給出的等效運行小時數安排維修計劃。這種維修方式沒有考慮機組的實際運行狀態,設備既有可能提早發生故障,也有可能在運行狀態良好的情況下維修部件,增加了電廠的運維成本[2]。因此,燃氣輪機運行調整與維修決策方案的制定依據機組的實際運行狀態,其中的關鍵在于機組基準值的確定。
傳統的基準值確定方法一般有兩種:一種是以設計值作為基準值,另一種是以最近一次的性能試驗值作為基準值。這兩種方法普遍存在的問題是燃氣輪機在設計與性能試驗時的工況與實際工況存在一定的偏差[3]。隨著信息技術、數據庫技術和先進測量技術的飛速發展,工業過程積累了海量的運行數據。近年來,國內外不少學者嘗試用數據驅動方法進行發電機組能耗分析與運行優化研究。趙歡等利用模糊C均值聚類方法確定典型負荷鄰域區間內火電機組特征參數的基準值[4]。Andrew Kusiak等利用聚類算法解決了火電機組歷史運行狀態模式分類問題,建立了不同工況下參數之間的關系[5]。其直接從歷史數據中獲取信息,避免了復雜數學模型的建立,并且能夠全面、真實地反映機組的實際運行水平。然而,由于燃氣輪機參與調峰運行,所以其工況復雜多變,運行數據的模式多樣。現有的文獻在進行數據挖掘前,沒有考慮燃氣輪機數據的特點。
針對燃氣輪機多工況下基準值確定的問題,本文提出了一套基于數據驅動確定全工況下燃氣輪機基準值模型的方法。首先,對歷史數據樣本進行穩態篩選;其次,根據邊界條件對燃氣輪機進行工況劃分,確定典型工況下參數的基準值;最后,選用某實際燃氣輪機的實際運行數據,驗證模型的有效性。
1 燃氣輪機基準值模型的提出
燃氣輪機的歷史運行數據反映了真實的運行狀態。燃氣輪機在實際運行過程中工況多樣,涉及穩定狀態與非穩定狀態、不同邊界條件下的運行狀態以及自身健康狀態的好壞差異等。因此,在通過歷史數據挖掘燃氣輪機基準值之前,需要對數據進行有序的梳理。首先,以功率為特征變量,利用區間估計的方法,篩選歷史運行數據中的穩態工況;然后,以功率、環境變量為特征邊界條件,利用K-均值聚類算法,劃分穩態工況;最后,在此基礎上,對每個工況下變量的樣本建立多元高斯混合模型,以熱耗率最低為目標選擇該工況下的基準值。
基于數據驅動的燃氣輪機基準值模型如圖1所示。
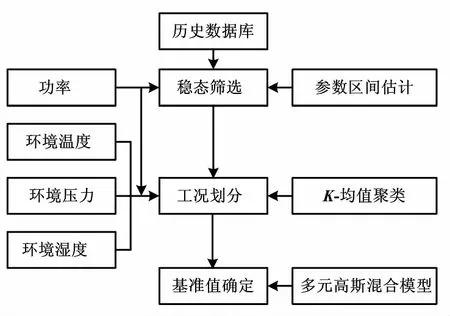
圖1 基于數據驅動的燃氣輪機基準值模型
1.1 穩態篩選
為了滿足電網負荷調度的需求,燃氣輪機快速地調整燃料供給與其他運行參數。在此過程中,產生了非穩態工況。燃氣輪機參數的測量值可以視為真實值和噪聲值的疊加。當燃氣輪機處于穩態工況下,參數的真實值保持不變。測量值的變化主要是由隨機誤差引起的。當燃氣輪機處于非穩態工況下,參數的真實值發生急劇變化,甚至在短時間內產生很大偏移量。機組的非穩態工況直觀地反映在輸出功率的變化上,輸出功率隨時間呈單調遞增或遞減的特點[6]。因此,選用輸出功率作為穩態判別的特征變量,其表達式為:
(1)
式中:pt為t時刻功率的測量值;μ為功率的真實值;m為功率的變化速率;ε為功率的隨機誤差,服從正態分布。
由式(1)可以看出,穩態與非穩態工況的區別在于功率變化速率是否等于0。為了便于對m值大小進行估計,計算相鄰兩個時刻功率的差值Δp,如式(2)所示。
Δp=pt-pt-1=m+(εt-εt-1)
(2)
因為隨機誤差ε服從正態分布,因此統計量Δp的期望等于m。根據時間序列的性質,m可以用時間窗口內樣本統計量的均值估計,如式(3)所示。
(3)
式中:h為采樣時間窗口內的樣本數目。
為了保證估計的可靠性,采用區間估計的方法,確定樣本功率差值的期望值m。如果估計的區間范圍包括0,則認為機組有很大可能在該時間段內處于穩態工況;否則,認為機組處于非穩態工況。
1.2 工況劃分
燃氣輪機運行參數變化的原因可以歸結為兩類:一是運維可控類,包括運行調整不當、可維護類故障以及傳感器故障;二是不可控制類,包括邊界條件變化等。在確定參數基準值之前,需要對歷史數據進行工況劃分,隔離邊界條件變化對參數的干擾。對于發電用燃氣輪機而言,機組的輸出功率由電網控制。因此,選用大氣溫度、大氣壓力、大氣濕度、燃機功率4個變量作為邊界條件,對穩態篩選后的歷史數據進行工況劃分。
聚類算法本身不需要建立復雜的函數模型,依據相似性對數據分類。作為聚類算法的典型代表,K-均值算法具有高效、快速的特點,被廣泛應用于大規模數據進行聚類[7]。K-均值算法的基本原理是:首先,從數據樣本中隨機選取K個點作為初始的聚類中心;其次,計算并比較其他數據點到K個聚類中心點的距離,并對距離大小進行排序,將樣本點劃分到距離最近的聚類中心所在簇;待所有點分類結束后,重新計算每簇樣本數據的平均值,將其作為新的聚類中心。不斷重復上述過程,直至準則函數收斂,如式(4)所示。
(4)
式中:E為所有樣本點的平方誤差的總和;xj為第i類的第j個樣本點;mi為第i個聚類子集的聚類中心。
K-均值聚類算法的聚類效果依賴于聚類數的選擇。聚類數目過少,樣本的特征不能夠全面表征;聚類數目過多,又會將異常噪聲數據當作正常類別進行處理,從而導致誤分類。因此,采用silhouette準則確定K-均值聚類算法的最佳聚類數,將樣本點silhouette準則系數平均值最大時所對應的K值作為最佳聚類數[8]。
1.3 基準值的確定
多元高斯混合模型(multivariate Gaussian mixture model,MGMM)是一種半參數的概率密度估計方法。它融合了參數估計法與非參數估計法的優點,不局限于特定的概率密度函數形式[9]。
如果模型中子模型足夠多,則其能夠以任意精度逼近任意的連續分布。MGMM的概率分布形式如式(5)所示。
(5)
(6)
式中:X為參數變量;q為子模型個數;ωq為第q個子模型模型的權重系數;φq(X|θq)為第q個子模型的概率密度函數。
MGMM的參數估計采用經典的最大期望值(expectation maximum,EM)算法。EM算法是一種迭代算法,適用于含有隱含變量概率模型的參數估計[10]。
MGMM的子模型個數會影響模型的回歸效果,故選用赤池信息評價準則(Akaike information criterion,AIC),確定最佳子模型個數[11]。AIC建立在熵的概念上,提供了一種權衡模型復雜度與擬合數據優良的評價辦法,其定義如式(7)所示。
AIC=2q-2ln(L)
(7)
式中:q為子模型個數;ln(L)為模型的對數似然函數。
2q作為懲罰模型復雜度的引入,有助于降低模型過擬合的風險。隨著子模型個數的增加,AIC的值會先減小再增大。綜合考慮模型的回歸精度與復雜度,選擇AIC最小時對應的子模型個數作為最佳子模型個數。
2 算例驗證
選用某實際發電用燃氣輪機進行基準值模型的驗證。從電廠的廠級實時監控信息系統(supervisory information system,SIS)中采集燃氣輪機10天的歷史運行數據,測點變量如表1所示。設置采樣間隔為1 min,共計14 400組樣本點。
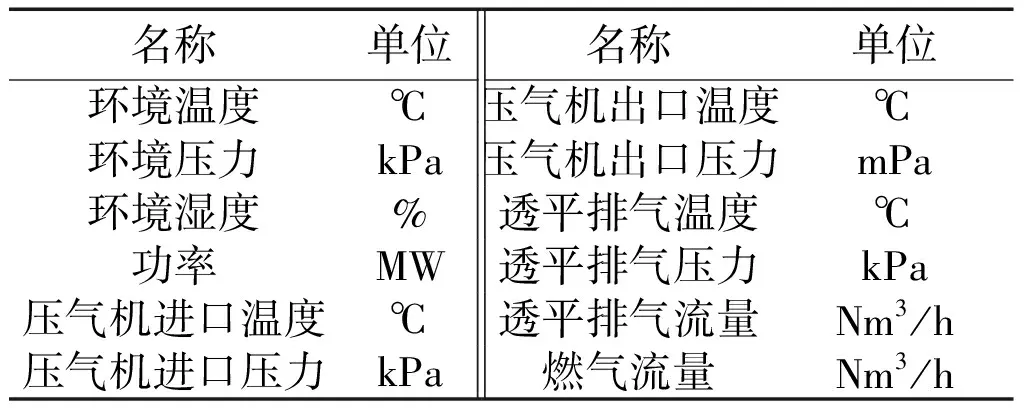
表1 SIS中采集的測點變量
2.1 歷史數據的穩態篩選
首先,利用功率變化速率m區間估計的方法,對14 400組歷史數據進行穩態篩選。其中,設置采樣時間窗口長度h=20,區間估計的顯著性水平α取0.05。穩態篩選后,共有13 541組樣本被劃分成穩態。穩態篩選前后燃機功率對比如圖2所示。
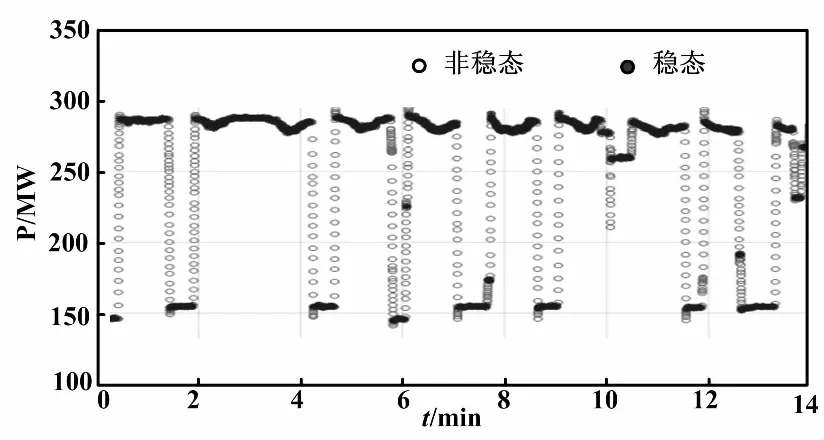
圖2 穩態篩選前后燃機功率對比圖
2.2 穩態工況的劃分
針對穩態工況樣本,利用K-均值聚類算法劃分工況。為了確定最佳聚類數,依次計算不同聚類數目(2~30)下樣本silhouette的平均值。當聚類數目是24時,silhouette值最大,等于0.62。因此,劃分后24類工況對應的邊界條件如表2所示。
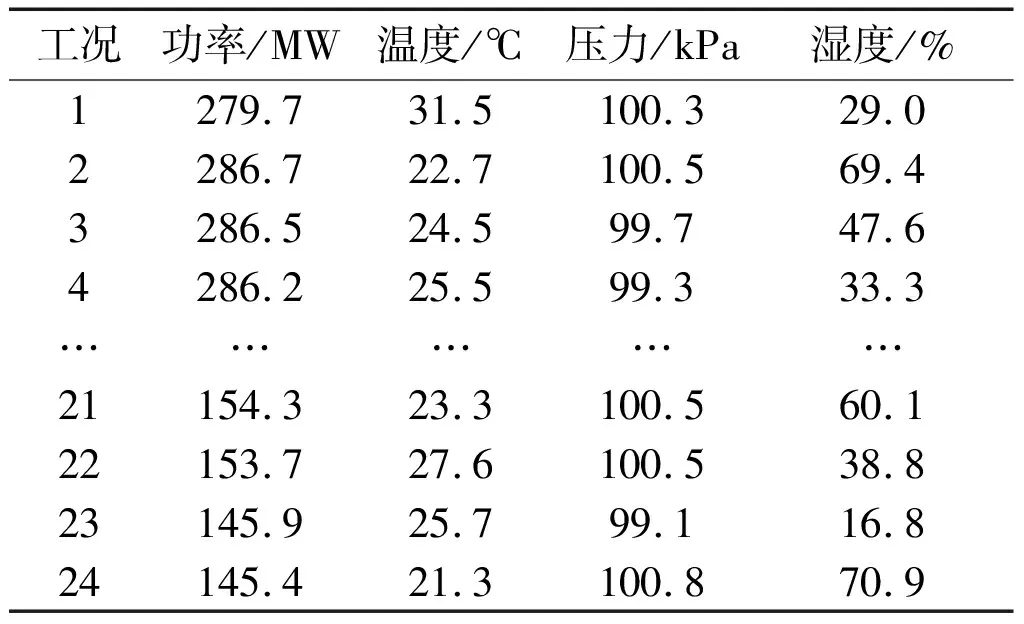
表2 24類工況邊界條件
2.3 典型工況基準值的確定
利用MGMM確定每個工況下的參數基準值。以表2中第1類工況條件為例(即功率為279.7 MW,環境溫度為31.5 ℃,環境壓力為100.3 kPa,環境濕度為29%)進行具體說明。計算2~30個不同子模型數目下MGMM的AIC值,如圖3所示。當MGMM子模型數目是8時,對應的AIC最小,用五角星表示。綜合考慮MGMM復雜度和擬合精度,第1類工況條件下MGMM的子模型個數為8。
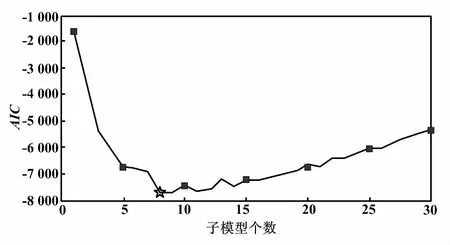
圖3 不同MGMM子模型個數的AIC值
第1類工況條件下的MGMM擬合結果,即 MGMM回歸的概率密度如圖4所示。圖4中,以壓氣機出口壓力和透平排氣溫度作為特征變量,縱坐標為參數對應的概率密度。其中,坐標軸數值是歸一化之后的值。比較不同子模型的期望,選擇熱耗率最低時對應的子模型參數期望值作為基準值,即9 554.57 kJ/kWh。同理,依次確定其他23類工況下參數的基準值。
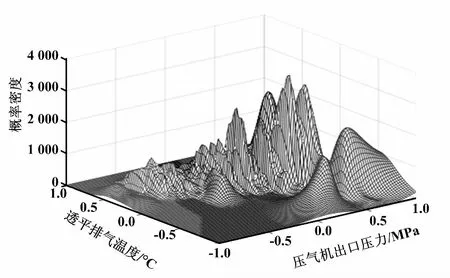
圖4 MGMM回歸的概率密度
24類工況條件下熱耗率的基準值如表3所示。
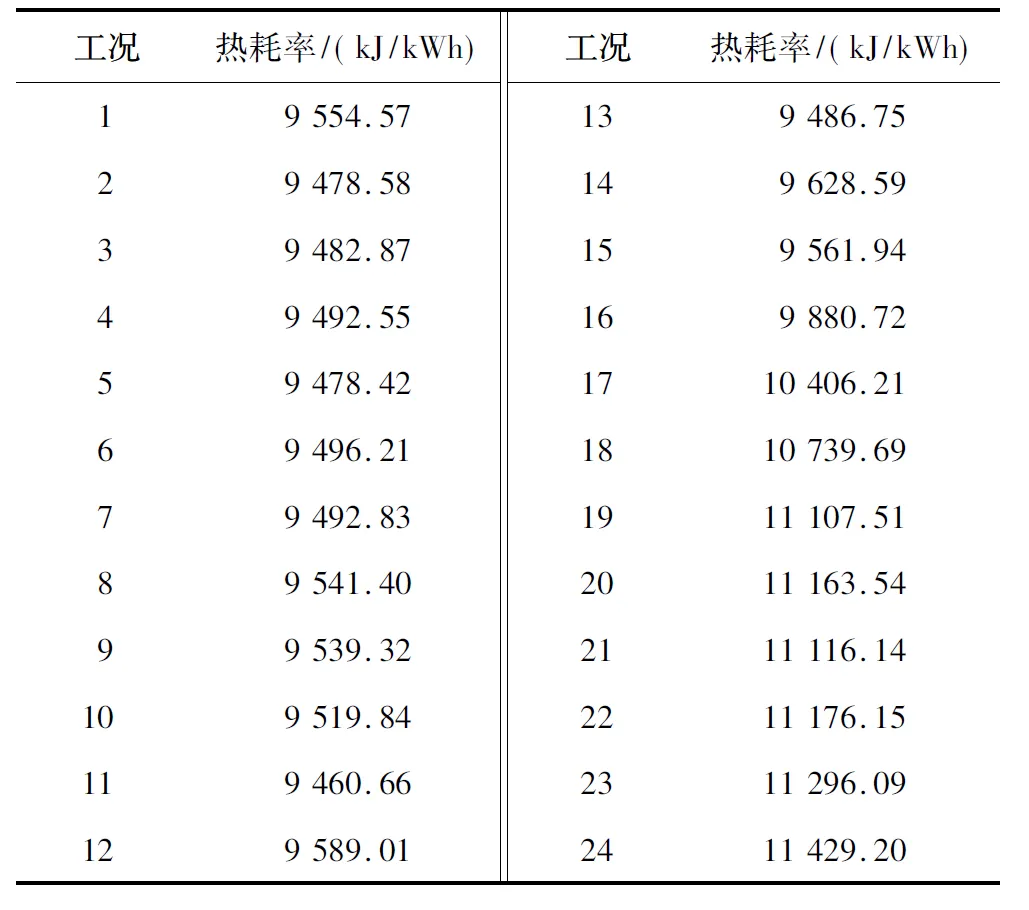
表3 24類工況條件下熱耗率的基準值
3 結束語
本文提出了一種基于數據驅動確定燃氣輪機基準值的模型方法。通過對歷史運行數據進行分析、建模,建立全工況下參數的基準值模型。該研究方法的優勢主要有以下幾點。
①對燃氣輪機的歷史運行數據進行信息挖掘,使得參數的基準值符合機組的實際運行水平,有利于指導機組運行優化和故障診斷。
②在模型建立前,對歷史數據進行穩態篩選和工況劃分,有效排除了燃氣輪機在非穩態工況以及邊界條件的影響。
③在基準值求解過程中,考慮了隨機誤差以及參數之間的耦合特性的影響,建立多元高斯混合模型,以熱耗率最低對應的子模型期望為基準值,保證了基準值的可達性。
在今后的工作中,將進一步研究燃氣輪機基準值的動態模型,并積極拓展基準值在優化調整以及故障診斷中的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
