級聯卷積網絡在無人機視覺定位的應用?
2019-05-07 06:29:54丁鵬程于進勇柳向陽
艦船電子工程 2019年4期
丁鵬程 于進勇 王 超 柳向陽
(海軍航空大學 煙臺 264001)
1 引言
近年來,得益于深度學習在特征提取中取到的巨大成就,目標檢測作為計算機視覺的主要部分得到了迅猛的發展。不同于傳統目標檢測中人工提取特征,深度學習特征自提取可以有效克服傳統方法對設計者經驗的要求,對環境光影的影響有較好的抑制作用,對目標檢測的發展起了重要的推動作用。如今,深度學習在目標檢測中主要分化出以Fast R-CNN[1],Faster R-CNN[2]為代表的兩階段檢測網絡和以 YOLO[3],SSD[4]為代表的單階段檢測網絡。前者先劃分候選區域進行特征提取,之后進行分類和回歸定位,后者采取端對端的形式直接進行分類和回歸。比較而言,以Faster R-CNN為代表的兩階段目標檢測檢測精度更高,本文也將此網絡作為研究重點。
將深度學習的高精度檢測引入無人機視覺定位,是未來發展的趨勢。將基于深度學習的目標檢測網絡替代無人機視覺定位中的圖像處理模塊,檢測出目標在像素坐標系中的位置,經過投影轉換可以得到無人機的位置信息。為了使目標檢測網絡更好的應用在無人機視覺定位,本文根據無人機視覺定位的特點,將研究重點放在提高網絡精度,特別是小目標檢測的精度,之后根據無人機實時性的特點,研究提高網絡速度的方法。
為了讓Faster R-CNN更加適應無人機視覺定位的要求,加入Inception改善網絡結構,通過設計級聯R-CNN,語義級聯以及級聯激活函數,提出了級聯卷積網絡,可以明顯提高網絡的檢測精度,特別是小目標的檢測精度。選定飛行實驗區域,制作自己的數據集UVNLD(UAV Vision Navigation Location Dataset),通過投影關系進行坐標轉換得到無人機的位置信息,提出了一整套無人機視覺定位算法,并驗證了算法的可行性。
2 網絡結構
2.1 Faster R-CNN網絡結構
Faster R-CNN引入RPN(Region Proposal Networks)網絡,使區域提取、分類、回歸等任務共用卷積特征,實現特征共享。RPN采用全卷積層來代替全連接層,可以使網絡不受輸入圖片大小的限制。卷積在特征層上利用k個不同的矩形框進行區域提取,可以同時輸出所有矩形框的特征,如圖1。分類層用于判斷該區域為前景還是后景,回歸層預測區域的中心,并得到對應的坐標[x,y,w,h]。
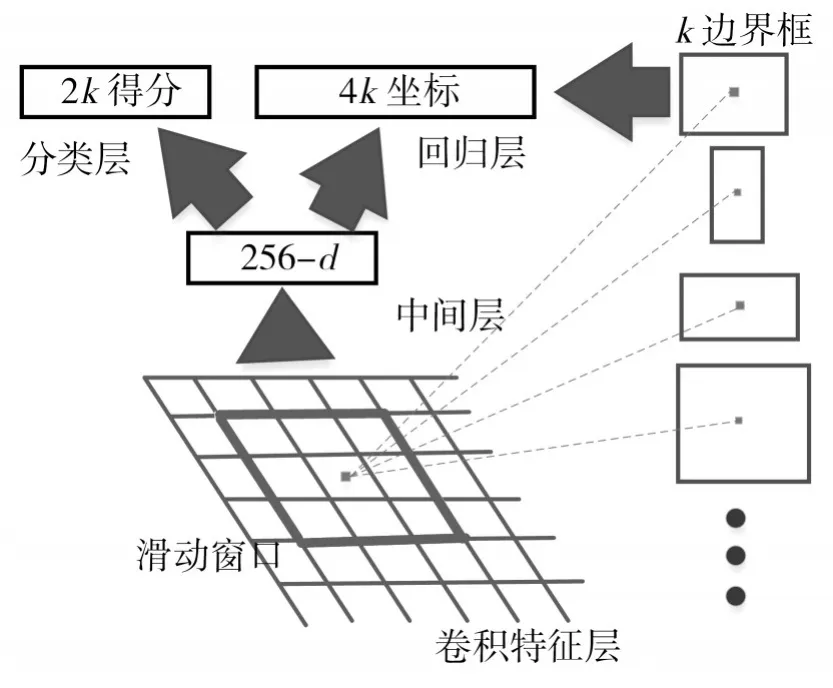
圖1 RPN結構
2.2 網絡結構改進
當網絡進行目標檢測時,為了提高網絡的魯棒性,必須同時考慮小目標和大目標的情況。根據GoogleNet[5]等相關研究,當圖像中既有大目標信息,又有小目標信息時,可以控制大小不同的卷積核進行特征提取,即Inception結構。這里,我們設計如圖2所示的Inception結構。
在檢測精度上,當網絡學習大目標時,卷積網絡需要足夠大的感受野,我們將Faster R-CNN中的5×5卷積核替換成兩個3×3卷積核,使感受野略有增加。在小目標學習過程中,1×1卷積核可以增加網絡的非線性,在保留上一層感受野的同時,減慢輸出特征感受野的增長,有利于小尺度目標的捕捉。
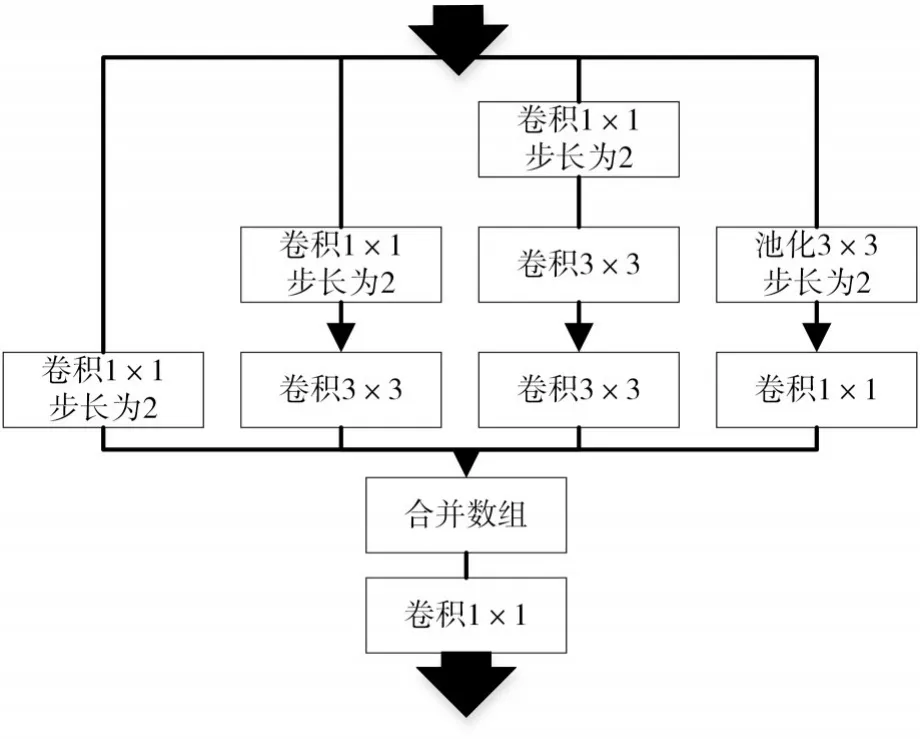
圖2 Inception結構
在網絡計算速度上,3×3網絡的引入可以使每個過程的參數從25降低到18。而設置步長為2的1×1網絡,可以使網絡的特征圖變為原來的一半,顯著減低了網絡的計算量。
3 級聯卷積網絡
3.1 級聯R-CNN
目標檢測網絡的評價函數IoU(Intersection-over-union)是指模型產生的目標窗口與原來標記窗口的交疊率,即檢測結果(Detection Result)與真實標記(Ground Truth)的交集比上它們的并集,表達式如下:
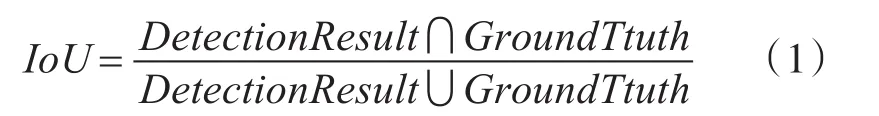
雙階段檢測網絡,如R-CNN[6]、R-FCN[7]等,都會對提取的候選區域進行分類和回歸。分類過程中,每個候選區域都會根據事先設定的IoU的值分為正樣本和負樣本。回歸任務中,網絡不斷地向正樣本的邊界框回歸。所以,一個好的IoU的設定,對網絡的訓練和驗證具有重大影響。
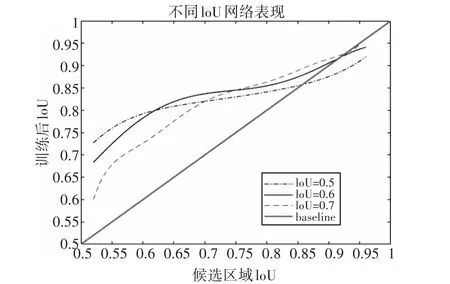
圖3 不同IoU的網絡表現
如圖3所示,橫軸是候選區域的IoU,縱軸是經過回歸訓練后得到的新的IoU,不同的線條代表不同的IoU訓練出來的檢測器。整體來看,三條曲線趨勢表明IoU越高,檢測器的回歸性能越好。在0.55~0.6之間,IoU為0.5的檢測器性能最佳,在0.6~0.75和0.75以上區間,分別是IoU為0.6和0.7的檢測器性能最佳。可以看出,當候選區域自身的IoU值與訓練的IoU值相近時,檢測器的性能最佳。傳統的目標檢測網絡,通常采用一個固定的IoU設定值,如當IoU為0.5時,大于0.5的都會被認作是正樣本,但是網絡對于0.6~0.95的候選區域表現較差。提高IoU為0.7,雖然對于0.75以上的候選區域變現較好,但是0.7的IoU值會導致正樣本的數量急劇減少,網絡訓練時過擬合嚴重,最終檢測結果反而不如0.5的設定值。
為了解決以上問題,我們采用級聯R-CNN網絡結構[8]。由圖3可知,網絡經過訓練,IoU的值會增加。與圖4(a)Faster R-CNN相比,我們將多個不同的檢測器根據IoU的值串聯起來,如圖4(b)。本文,我們設定了IoU分別是0.5,0.6和0.7的三個級聯檢測器,每個檢測器的輸入源自上一層檢測器邊界框回歸后的結果。
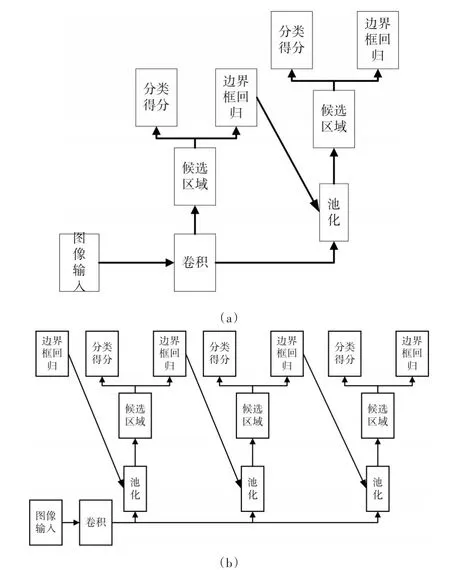
圖4 級聯R-CNN網絡結構
通過這種設定,網絡可以充分利用各類正樣本的圖像信息,一定程度上可以減少正樣本的浪費和流失,使得檢測網絡適應各種目標的檢測情況,提高網絡的檢測精度。
3.2 語義級聯
通過上述改進,可以提高網絡整體的檢測精度,但是,針對小目標這種特殊任務,網絡的檢測效果提升不明顯。通常,為了更好地識別大小不同的物體,特征圖像金字塔[9]是一個常見方法。低層圖像的特征語義信息比較少,但是位置信息準確,高層的特征語義信息豐富,通過多尺度融合,可以更好地表達圖像信息。
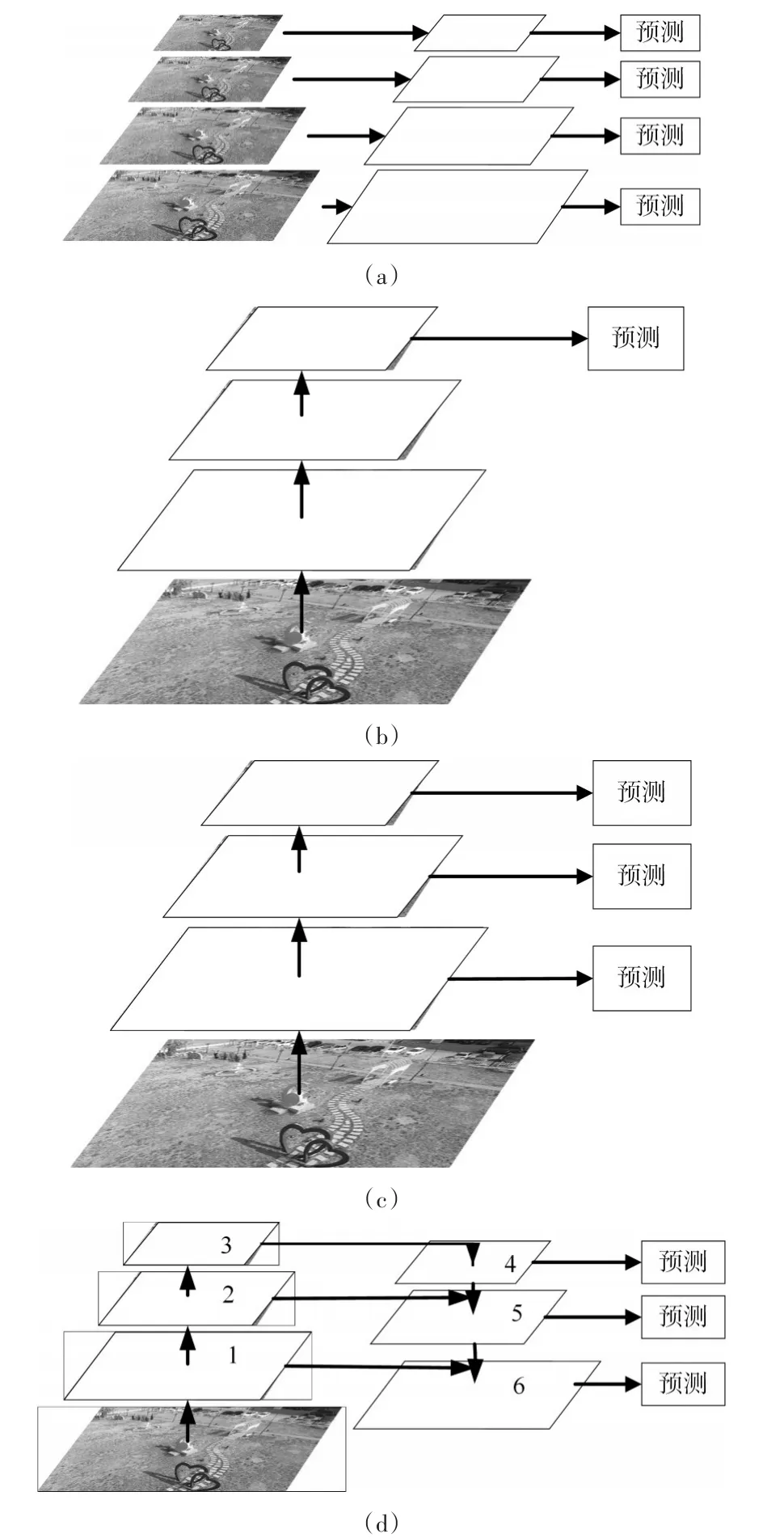
圖5 幾種特征融合
特征圖像金字塔如圖5(a)所示,將圖像化成不同大小尺寸,對每一個尺寸的圖像生成各自的特征并進行預測。雖然可以保證特征提取的完備性,但是時間成本太大[10],實用性差。圖 5(b)是利用卷積網絡自身的特性,對圖像進行卷積和池化處理,生成不同尺度的特征圖,通過高層的語義網絡進行預測[11]。傳統的 SPP Net[12],Fast R-CNN[1]和 Faster R-CNN[2]也都采用這種方式。通過這種方式,網絡速度快,內存占用小。但是由于忽略了低層網絡的細節信息,網絡精度有待提高。融合了不同特征層語義信息的網絡框架[4]被提了出來,如圖5(c)。但是,因為網絡中大部分都是低層網絡提供的信息,網絡的弱特征太多,導致網絡的魯棒性差。
基于上述原因,我們借鑒Lin等[13]思路,采用如圖5(d)所示的特征金字塔網絡(Feature Pyramid Network),將自底向上和自頂向下的路徑進行橫向信息融合。比如,將第四層采用1×1卷積層的上采樣操作結果與第二層降維操作的結果相加,經過3×3卷積操作后輸入到第五層網絡進行分類和回歸。通過將高分辨率、低語義信息的低層特征和低分辨率、高語義信息的高層特征融合,每一層特征圖都可以根據分辨率的不同分別做對應分辨率大小的目標檢測,同時這種連接幾乎不會增加網絡額外的時間和計算量,只是在基礎網絡上增加了跨層連接。
3.3 級聯激活函數
為了更好地將網絡用在無人機視覺定位,必須要考慮網絡的實時性問題。ReLU[14]自提出以來,由于可以有效緩解梯度消失、計算方便快捷等原因迅速成為最常用的激活函數。但也存在著成對現象,即低層卷積層的濾波器存在著嚴重的負相關性,隨著網絡變深,負相關性減弱[15]。所以,在網絡的前半部分,ReLU會在訓練過程中抵消部分負響應,造成卷積核冗余。
為了解決這個問題,借鑒Hong等[16]研究,引入級聯激活函數C.ReLU(Concatenated Rectified Linear Units)。定義:
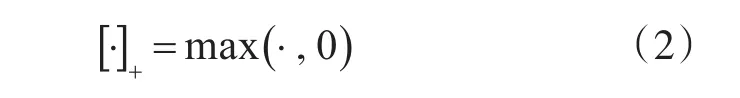
則
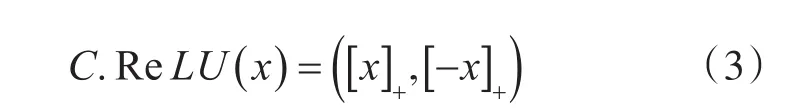
為了抵消成對現象,根據C.ReLU構造如圖6所示結構。將輸出通道減少一半,通過將激活函數額外做一次取反,等價于將輸入相位旋轉180°,從而實現原來的輸出總量,在不改變精度的情況下減少一半的運算量。
4 無人機視覺定位
4.1 投影原理
無人機對獲取的圖像檢測目標,根據目標實際位置和圖像中的位置,經過投影關系和坐標轉換獲得無人機位置信息。根據像素坐標系(u ,v ),圖像坐標系相機坐標系(xc,yc,zc),可得經典無人機投影變換方程為
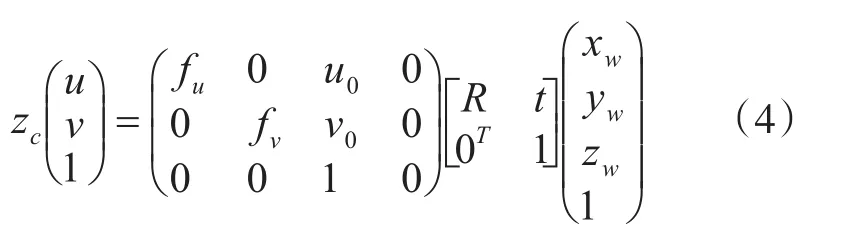
其中,(u0,v0)是圖像坐標系原點在像素坐標系中的坐標。 f為焦距,fu=f/dx,fv=f/dy。三維正交旋轉矩陣R和平移變換向量t為世界坐標系中的點到相機坐標系的變換矩陣。
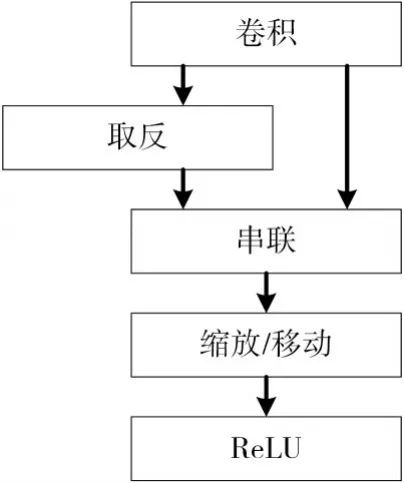
圖6 C.ReLU結構
然而現實中,攝像機鏡頭存在嚴重的畸變,尤在遠離圖像中心處,像差比較明顯。為了提高計算精度,需要考慮無人機鏡頭畸變。本文根據張正友標定算法[17],運用萊文貝格-馬夸特方法[18]解決多參數非線性系統優化問題,從而確定相機參數和畸變系數,實現畸變矯正、圖像校正和最終三維信息恢復。
4.2 無人機視覺定位算法
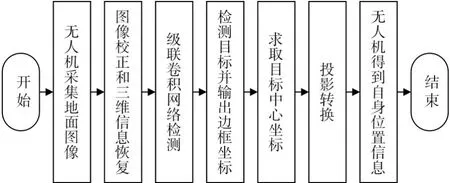
圖7 無人機視覺定位算法流程圖
通過將級聯卷積網絡的目標檢測融入到視覺投影,代替傳統圖像處理模塊,可以得到無人機的位置信息[19]。本文中,無人機通過識別已知位置信息的目標得到無人機自身位置信息。該算法流程圖如圖7所示。
1)無人機在高空飛行時,對地面圖像進行采集。
2)將當前拍攝圖像經過張正友標定算法進行圖像校正和三維信息恢復。
3)將校正后的圖像輸入級聯卷積網絡。
4)級聯卷積網絡將檢測到的目標分類,并以方框框出的形式標注出目標在圖像中的位置,同時得到方框四個頂點像素坐標。
5)根據四個頂點的像素坐標,得到目標中心在圖像中的坐標。
6)利用投影轉換和已知目標的位置信息,可以得到無人機自身位置信息。
5 對比仿真實驗
5.1 實驗數據與配置
以煙臺市芝罘區為中心的海邊區域作為研究對象,采用無人機進行數據采集。為了提高模型的適應性和魯棒性,采集了10類特征比較明顯的目標在不同觀測角度和飛行高度下的圖像,通過旋轉、調整亮度、加入噪聲等方法擴大樣本,模仿Pascal voc2007數據集的構造過程,得到自己的數據集UVNLD。UVNLD數據集包括10類目標的正樣本,每類2000幅。其中訓練樣本每類1000幅,測試樣本每類1000幅,共計20000幅。
在64位的ubuntu14.04系統,安裝了CUDA 8.0,cuDNN 5.0和python 2.7的環境下,我們選用caffe框架訓練本文網絡模型。CPU為Intel(R)Core(TM)i7-6770K@4.00GHz×8,GPU為NVIDIA GTX1080,8G內存。
5.2 仿真對比
5.2.1 幾種網絡精度對比
表1是為了驗證本文所提級聯卷積網絡在目標檢測中的性能,進行的幾組在數據集UVNLD的檢測結果。其中,R表示加入了級聯R-CNN的網絡,F表示加入了語義級聯的網絡,級聯卷積網絡則是本文提出的目標檢測網絡,通過在Faster R-CNN基礎上修改網絡Inception結構,引入級聯R-CNN和語義級聯的網絡。這里,檢測任務的評價指標是AP(Average Precision),定義如下:
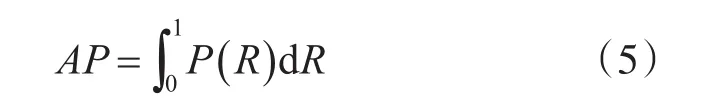
其中R為召回率,P為精度。
分別訓練和測試四種網絡,得到UVNLD數據庫的測試結果,見表1。我們可以看出,通過加入級聯 R-CNN,無論是 AP50,AP75還是 AP,網絡精度都得到了明顯的提高。這種級聯檢測器比單獨檢測器效果好的多,此外,經過多個檢測器后,候選區域的IoU也會提高,可以增加高IoU區域的正樣本數量,對于網絡的過擬合有明顯抑制作用,確保網絡在高IoU檢測器區間的精度。進一步對比APS和APM可以看出,語義級聯對小目標的檢測提升明顯,通過增加上下文信息,融合高層底層語義信息后,增加了特征映射的分辨率,即在更高層的特征上可以獲得更多與小目標相關的有用信息。
通過上述改進,級聯卷積網絡可以顯著提高網絡檢測小目標的精度,整體精度更是達到了87.9%。部分檢測結果如圖8所示,所得邊界框與真實邊界框平均誤差為2,滿足了網絡的設計要求。
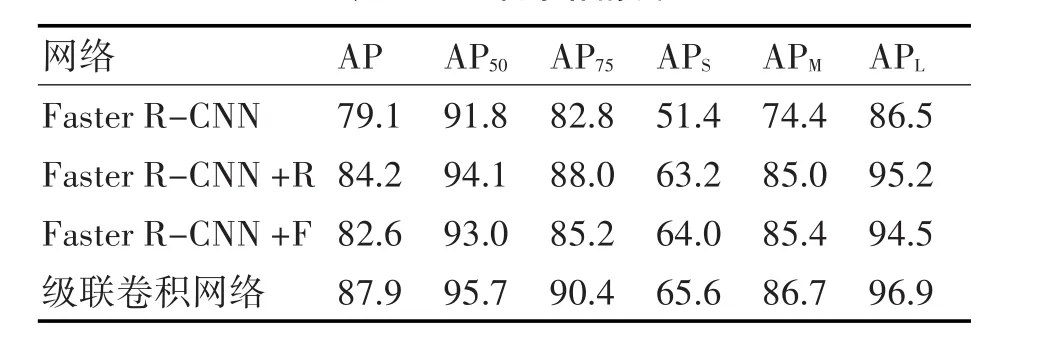
表1 幾種網絡精度
5.2.2 級聯激活函數對速度的影響
通過上述方法,網絡的精度有了極大的提到。但是,無人機視覺定位除了滿足精度要求,還要保證網絡的實時性。本文測試了兩種傳統Faster-RCNN以及是否使用了級聯激活函數的級聯卷積網絡。這里評判標準ms是指網絡檢測運行的平均時間,以毫秒為計。

表2 不同高度下無人機定位精度
加深網絡層數,對網絡的精度有很大提升,但也會導致網絡檢測速度的大幅下降,見表2。僅僅是將卷積子網絡從VGG16改為ResNet101,網絡速度就有了明顯的下降。在網絡結構中,通過引入Inception結構等,可以一定程度降低網絡運行時間,但是網絡的速度依舊遠不達要求。
引入級聯激活函數后,每層網絡都可以減少一半的計算量,特別是隨著網絡層數的增加,對卷積網絡指數級參數增加有了極大的抑制,效果明顯,降低了網絡對硬件的要求。
5.3 無人機飛行實驗
為了檢驗目標檢測網絡應用于無人機視覺定位的效果,我們在UVNLD數據集上又增加了驗證集圖片,在保證無人機特定高度下,收集相機拍攝角度分別為45°,60°,90°的圖片若干張,同時記錄無人機的當前實際位置信息。根據上述步驟,將驗證集圖片導入,對比網絡求取的無人機位置信息與預先記錄的無人機實際位置信息,得到表3。

圖8 部分檢測結果圖
表3結果表明,通過引入目標檢測網絡代替傳統的圖像處理模塊,進行無人機視覺定位,基本可以實現無人機定位誤差在0.3m以內,滿足無人機視覺定位的需求。特別是當無人機相機垂直角度采集數據時,網絡正確檢測的區域準確率更是達到了91.1%,定位誤差縮小到0.22m,滿足無人機視覺定位的要求。
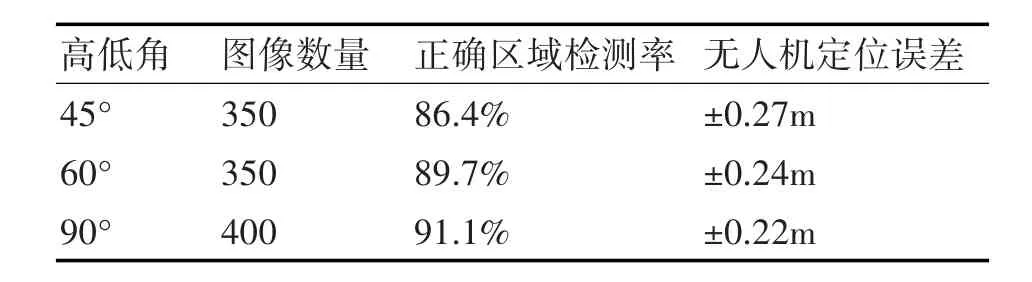
表3 不同高度下無人機定位精度
無人機在相機不同高低角對正確區域檢測率和無人機定位誤差的影響,主要體現在相機非垂直拍攝時,目標在圖像會有一定的投影誤差。高低角越低,投影誤差越明顯,目標檢測框誤差也會越大,進而影響無人機的定位誤差。適當提高無人機拍攝高度,可以一定程度上減小投影誤差的影響,從而提高無人機定位結果。
6 結語
本文在Faster R-CNN網絡的基礎上,通過引入Inception結構,設計級聯R-CNN,語義級聯和級聯激活函數,提出了級聯卷積網絡,既可以提高網絡在各個候選區域的檢測精度,又可以重點解決小目標檢測問題,對網絡的整體檢測精度有了較大的提升。經過在煙臺當地數據采集并自建數據庫學習,級聯卷積網絡對圖像的目標檢測精度穩定在87.9%。將此網絡引入無人機視覺定位,代替傳統圖像處理模塊,在考慮相機畸變的情況下,設計了一整套無人機視覺定位算法。試飛實驗表明,無人機視覺定位誤差穩定在0.3m以內,滿足無人機視覺定位的要求。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
