基于卷積內部進化機制與特征融合的人臉識別算法的研究
2019-05-17 07:42:34黃奧云程賓洋孫家煒
現代計算機 2019年10期
黃奧云,程賓洋,孫家煒
(四川川大智勝軟件股份有限公司,成都 610045)
0 引言
近年來,深度神經網絡作為計算機視覺里最熱門的技術之一,被廣泛應用于圖像分類、物體檢測、人臉識別等領域,并取得了顯著的成果。文獻[1]提出了基于卷積神經網絡的人臉識別算法,將一張對其后的人臉圖片截取后輸入到一個包含9 個卷積層的神經網絡,最后經過Softmax 輸出結果。該方法在人臉公開數據集LFW 上達到了99.77%的識別率。文獻[2]采用GoogLeNet 和Triplet Loss,將人臉映射到歐氏空間的特征向量上,計算人臉特征的間距,最后通過距離的大小來判斷人臉的類別。該方法在人臉公開數據集LFW上達到了99.63%的識別率。
為了獲得更好的識別效果,一方面,采用更大的數據集,目前公開的人臉數據集有CASIA-WebFace、CelebFaces+、VGG face dataset 和 MSCeleb-1M,等等;另一方面,設計更加優秀的深度神經網絡和采用更加合理的訓練方法,如文獻[3]提出了Maxout 激活函數,實現了對噪聲的過濾和對有用信號的保留,該算法在一個相對較小的模型下性能有一定的提升。文獻[4]針對人臉識別算法提出了Angular Margin Loss,將角度邊緣置于余弦函數內部,這一約束使得對整個分類任務的要求變得更加嚴苛,此外,該算法還改進了ResNet 網絡結構的block 層,使其更適合訓練人臉圖片;數據方面,剔除了噪聲數據,在MegaFace 數據集上的識別率達到了98.36%。
本文針對低質人臉圖片的識別,基于深度神經網絡和訓練方法,提出了基于卷積內部進化機制的殘差網絡結構與模型加權的人臉識別算法。在加深網絡深度的同時,保持了網絡的簡單性,并且采用了內部進化機制,對神經元響應進行了篩選,在網絡中添加殘差模塊,并引入權重因子,對輸出的單個特征分別賦予不同的權值,最后對多特征進行加權融合,提升了識別性。該算法在公開人臉數據庫和多場景人臉數據測試表明,該算法對光照、人臉姿態和表情變化、面部遮擋物、年齡變化等低質人臉數據具有較高的魯棒性。
1 人臉數據預處理
1.1 基礎訓練數據構成
基礎訓練數據主要由兩類數據構成,第一類數據包含各類人臉公開數據集,真實現場采集人臉圖像,這類圖片的特點是雜亂,涵蓋了高分辨率和低分辨率的圖片,各種場景如光照條件、人臉姿態和表情變化、面部遮擋物、年齡變化等屬性的人臉圖像,這類圖像數據樣本類別較大,從而滿足了在訓練過程中對各類低質圖像魯棒性的要求。第二類數據是法定身份證件低質人臉圖像,由法定身份證件低質人臉圖像和若干現場采集人臉圖像構成,這兩類人臉圖像數量較大,但其缺點是樣本不均勻。
1.2 數據擴展
研究表明,要取得更好的識別精度和魯棒性,基于深度學習的人臉識別的訓練數據在構成上應滿足:a.樣本類別數大(基礎數據滿足)。b.每類樣本的樣本數均勻(數量一致)且應包含各類情況的人臉圖像。基礎數據不能滿足b 條件,應進行擴充。本研究通過鏡像圖,添加光照,模糊化,加噪等方法對基礎數據進行擴充,使得樣本數均勻且包含多類情況下的人臉圖像,其效果圖如圖1 所示。

圖1 人臉數據擴展處理方法
1.3 數據裁剪
研究表明,要取得更好的識別精度和魯棒性,訓練數據一定要滿足數據量大和樣本均勻兩個要求。之前的研究對數據進行了充分的擴展,主要包括鏡像、加噪、模糊處理、加光照等,滿足了訓練要求。本研究在原有擴展數據集的基礎上,對數據集進行了裁剪。通過裁剪,去除了訓練樣本中的噪聲,使得訓練數據盡可能干凈,因此減少了噪聲對識別率的負面影響,對識別率有一定的提升作用。數據裁剪具體的處理步驟為:
(1)以人臉左右眼中心位置為中心進行裁剪。
(2)以人臉鼻尖位置為中心進行裁剪。
(3)以人臉左右嘴角中心位置為中心進行裁剪。
(4)每個裁剪的類別分別對應一種特征子向量。
裁剪人臉數據樣本如圖2 所示。

圖2 人臉數據裁剪處理方法
2 人臉識別算法
2.1 卷積內部進化機制的實現
卷積神經網絡采用激活函數來實現非線性,主要有 Tanh、Sigmoid、ReLU 函數等。Tanh 的特點是在特征相差明顯時的效果會很好,但在實際訓練數據和現場采集數據中,由于光照、姿態、表情、年齡變化等各種原因,往往包含很多模糊的數據。Sigmoid 函數的優點是在特征相差比較復雜或是相差不是特別大時效果比較好,但該函數收斂緩慢,反向傳播時,很容易出現梯度消失的情況,從而無法完成深層網絡的訓練。ReLU 收斂速度快,但很容易出現梯度消失的現象。
達爾文生物進化論認為自然選擇是進化的主要機制,通過進化,優勢物種和個體被保留了下來,弱勢物種和個體被淘汰掉。目前,一些傳統的遺傳算法通過模擬自然選擇和遺傳學機理的生物進化過程,從而可通過模擬自然進化過程來獲得全局中的最優解。
本研究根據進化過程中的相關方法,創新性地采用內部進化機制來實現非線性,將Feature Maps 突變為多組神經元,在進化的過程中篩選出最佳響應,最后形成新的Feature Maps;通過進化我們得到的是神經元響應最佳的結果,因此使得神經網絡對優勢特征更加敏感,相對于 Tanh、Sigmoid、ReLU 等激活函數,基于進化機制能有效去除噪聲信號并保留有用信號,具有較強的魯棒性和泛化能力,內部進化機制原理如圖3 所示。當一個卷積層的輸入用如下式表示時:

其中 n={1,…,2N},W 和 H 分別表示 feature map的寬和高。進化機制將輸入的feature map 突變為多個子feature map,經過內部進化,最后得到一個最佳的feature map,其原理可用如下公式表示:
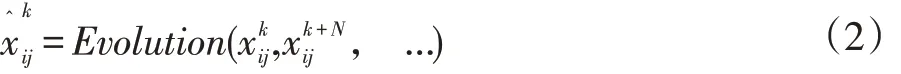
1≤ k ≤ N,1≤ i ≤ H,1≤ j ≤ w ,其中,輸入的卷積層的通道是2N。
通過進化,我們從輸入的feature map 得到了輸入信息的最佳神經元。

圖3 內部進化機制示意圖
2.2 殘差模塊的設計
深度學習對于網絡深度遇到的主要問題是梯度消失和梯度爆炸,傳統對應的解決方案則是數據的初始化(normalized initialization)和(batch normalization)正則化,但是這樣雖然解決了梯度的問題,深度加深了,卻帶來了另外的問題,就是網絡性能的退化問題,深度加深了,錯誤率卻上升了,基于以上原因,文獻[5]提出了一種具有殘差結構的深度神經網絡結構,該網絡結構能很好地解決上述激活函數在網絡訓練時所帶來的退化問題,并且該結構易于優化,提高網絡的性能。基于ResNet 的基本單元設計方法[2],本研究創造性地將兩個基于進化機制的卷積網絡層,組成一個基本的殘差模塊,使得網絡的性能也提升了。
基于卷積內部進化機制的殘差網絡具體實現結構如圖4 所示,該結構構成深度卷積網絡的一個結構層。多個結構層串聯(級聯)構成了特征提取的深度卷積神經網絡,經過這樣設計的深度卷積神經網絡,在特征提取方面更加豐富,從而使得識別準確率有了大大提升,其特征提取過程如圖5 所示。
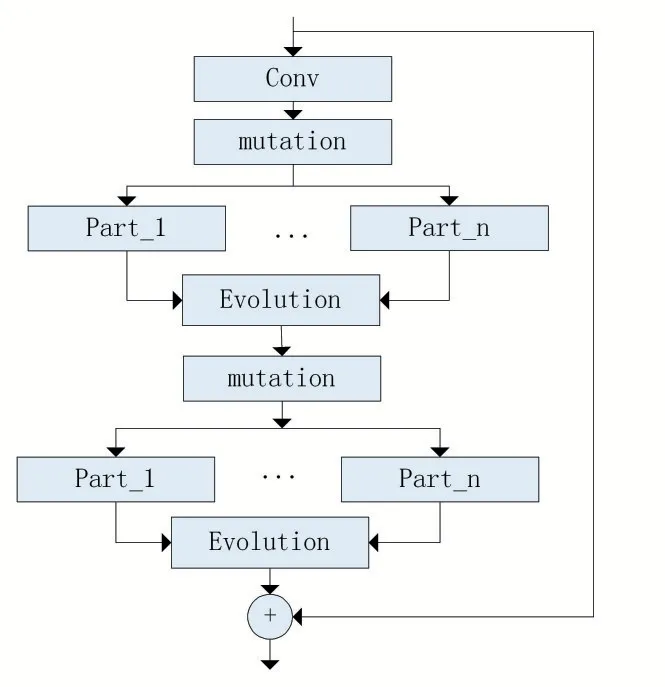
圖4 殘差模型示意圖
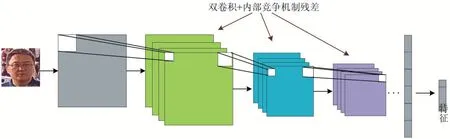
圖5 特征提取示意圖
詳細的神經網絡結構共13 個卷積層,進化機制和池化層連接在兩個卷積層之間,最后是全連接層并輸出類別數,為了防止在訓練過程中出現過擬合,在全連接層后加入了Dropout 層。訓練數據集是經過人臉對齊的大小為150×150 的人臉灰度圖片,訓練時,首先將圖片的大小裁剪成96×96,作為卷積層的輸入,最后經過全連接層,輸出一個256 維的特征,經過Softmax 層最后輸出該人臉圖片所屬類別。
3 訓練
3.1 訓練策略
為了驗證算法的可靠性,本研究基于人臉公開數據庫和多場景采集真實人臉數據共440 萬人臉數據,基于公開深度學習框架PyTorch 訓練與測試。Dropout參數設置為0.75,momentum 設置為0.9,weight decay 設置為1e-6,初始學習率設置為0.01,之后隨著迭代次數的增加衰減到1e-5。訓練時,分別以眼睛、鼻子、嘴角為中心,裁剪出大小為96×96 的圖片,并對其進行灰度處理,然后分別送入深度神經網絡對其進行訓練,最后得到9 個對應的模型。
3.2 模型融合
研究實驗表明,相對于深度神經網絡的單模型的特征提取,多模型提取的信息更加豐富和穩定[5]。模型融合是用于組合來自多個預測模型的信息以生成新模型的模型組合技術。通常,融合后的模型因為它的平滑性和突出每個基本模型在其中執行得最好的能力,并且抹黑其執行不佳的每個基本模型,所以其最終效果將優于每個單一模型。本研究訓練模型按照對應的權值拼接起來組成一個高位度的新模型,經過測試,相比于單一模型,模型拼接所得到的識別率較單一模型提升了3-4%左右,該步驟具體流程如圖6 所示。
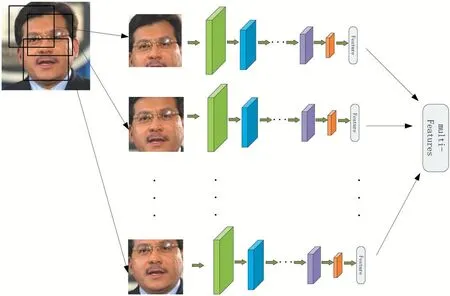
圖6 模型融合示意圖
4 測試與分析
為了驗證該算法的有效性,分別在公開人臉數據集和多場景采集數據集上進行了測試。
測試時,人臉特征比對采用余弦相似度,余弦相似度公式為:
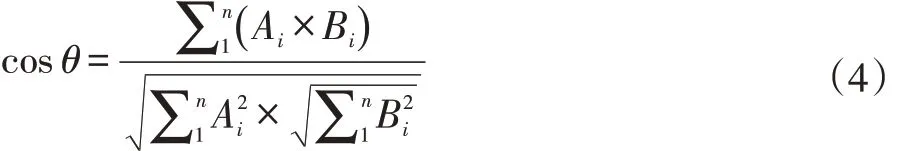
余弦值的范圍在[-1,1]之間,值越趨近于1,代表兩個向量的方向越接近,為同一個類別的概率越大;越趨近于-1,它們的方向越相反,為同一個類別的概率越小。測試樣本如圖7 所示。
4.1 測試數據集介紹
本文測試的公開人臉數據集是LFW 數據集。該類標準人臉數據集共收集了5749 類人臉類別共計13233 張人臉數據。其中,大約1680 個人包含兩個以上的人臉。該數據集被廣泛用于測試人臉識別算法的性能。
另一部分測試數據集來自標準身份證件照片和現場采集的人臉數據。Test1 數據集包含3139 類共84245張人臉圖像,該類人臉數據光照干擾明顯,部分數據出現面部遮擋物,因此噪聲特別大;Test2 數據集包含5996 類共19433 張人臉圖像,該類人臉數據中有一定的年齡跨度,因此該類數據特征較不明顯;Test3 數據集包含299類共2298 張人臉圖像,該類人臉數據的特點是人臉表情變化豐富;Test4 數據集包含2380 類共23295 張人臉圖像,該類人臉數據集涵蓋了高分辨率,低分辨率的人臉數據。部分測試數據集如圖8 所示。

圖7 測試樣本

圖8 部分測試數據集
4.2 結果分析
分別測試了基于內部進化機制的深度神經網絡在人臉公開數據集LFW 上的效果,并與公開的當今最流行的人臉算法測試結果做對比,其結果如表1 所示。從表中可以看出,本研究所提出的算法效果明顯好于其他算法。其中,Model1 和Model2 表現出了最好的成績,在整個LFW 數據集上的識別率最高達到了100%,比現階段公開的算法的測試結果提高了0.23%。通過以上對比可以得出,基于內部進化的深度神經網絡的性能好于其他網絡。證明了本算法的可行性和有效性。
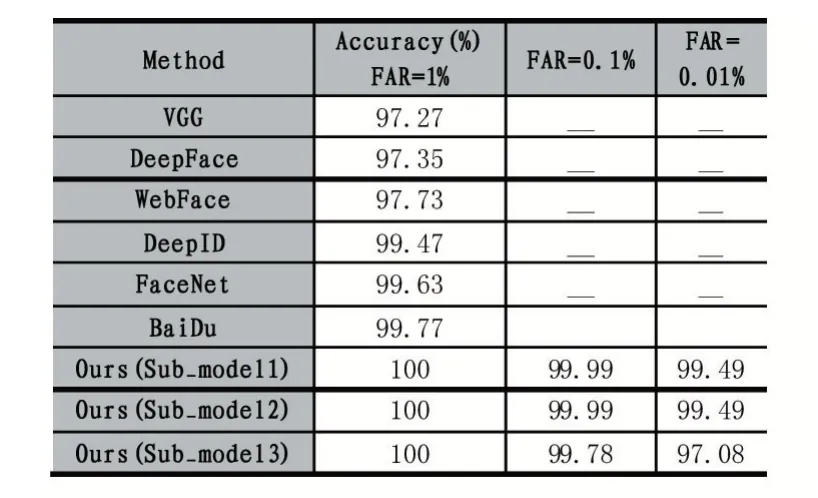
表1 不同網絡結構在LFW 的測試結果
單模型和多模型在多場景低質采集人臉數據集上的測試結果如表2 所示。除第一個測試數據集包含了部分訓練數據外,其余三個數據集的數據均不包括在訓練數據集內。單模型在四個數據集上皆表現出優異的成績;融合后,識別率相較于單模型又提升了1-5%。
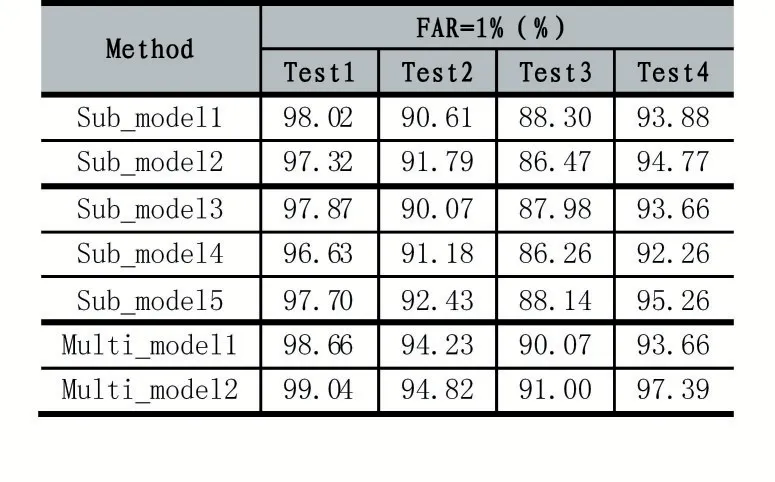
表2 低質數據集測試結果
以上測試結果表明,相比于其他人臉識別算法,基于內部進化機制的深度卷積神經網絡與模型加權的人臉識別算法無論在標準人臉還是低質人臉數據都具有較高的識別率,本算法適用于各類場景的人臉識別,具有較高的魯棒性和實用性。
5 結語
本文基于卷積神經網絡設計了一種全新的網絡結構,即基于卷積內部進化機制的深度卷積殘差網絡結構;同時,在訓練和測試階段提出了特征提取和加權模型融合的方法。經過測試,本文提出的算法無論在公開人臉數據集或由于光照條件,人臉姿態和表情變化、面部遮擋物、年齡變化等表現出的低質人臉圖像,皆表現出較高的識別率。測試結果表明,本文提出的人臉識別算法具有較高的魯棒性和實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
