基于多種空間信息的高光譜遙感圖像分類方法
2019-05-23 08:45:04
中國空間科學技術 2019年2期
哈爾濱工程大學 計算機科學與技術學院 哈爾濱 150001
在高光譜影像分類中,如果僅使用光譜特征而未考慮空間信息,會使得分類精度較低,與實際地表覆蓋的連續性分布不相符。引入像素的空間信息,能夠對原始圖像數據進行更充分的挖掘和利用,獲得空間連續性較好且精度較高的分類結果。光譜-空間特征相結合已成為當前高光譜遙感圖像分類的研究熱點之一[1-2]。空譜分類的關鍵性問題在于如何提取紋理、形狀、對象、語義等空間信息,以及如何有效地融合光譜信息與空間特征[3-4]。
高光譜圖像分類中常用的空間信息主要分為紋理信息、數學形態學信息和鄰域信息3種。對于這3種空間信息的利用主要有兩種形式。第一種形式把空間信息表示成特征向量,然后和光譜特征向量融合組成新的特征,再進行分類。這種形式主要利用紋理信息和數學形態學信息[5-7]。文獻[5]提出了一種基于局部圖的特征融合方法,將光譜信息和優化后的圖像特征融合起來進行分類。文獻[6]采用SC-MK算法對高光譜圖像的過分割區域使用多核分類器分別對光譜信息和空間信息進行利用。也有研究者提出基于LBP的局部圖像特征提取框架,用于高光譜圖像分類,提取了Gobar特征和光譜特征進行融合。還有一些方法對用于學習圖像進行非監督分層稀疏表示提取特征,并輸入到分類器中進行分類[8]。第二種利用空間信息的方式是先進行分類,然后再用空間信息對分類結果進行優化。這種形式被稱為后處理,一般利用的是圖像的鄰域信息[9-10]。以上這兩種形式也可以結合在一起用來提高分類精度。
總的來說,高光譜圖像分類多采用光譜特征和空間特征,再利用支持向量機等方法進行分類[11]。目前的高光譜圖像空譜分類中,通常是利用某一種空間特征和一種光譜特征進行融合,然后進行分類,接著利用超像素分割結果帶有的鄰域信息對分類結果進行改善。這種方法能夠在一定程度上取得不錯的分類效果,但是存在一定的不足。首先,高光譜數據所含信息豐富,一種空間特征只能從一種角度去表達空間信息,并不能完整對圖像的空間信息進行描述,這導致高光譜數據的信息利用率仍然較低。第二,在后處理階段目前常用的做法是通過統計分類結果中每個超像素塊區域包含的相同標簽數目進行投票來確定。這種做法以超像素塊作為單位對空間鄰域信息進行利用,仍存在大量未達到投票閾值的像素并沒有受到空間鄰域信息的影響,空間信息利用率不高。
針對以上兩點不足,本文提出一種新型的結合多種空間信息的高光譜遙感圖像分類方法。為了解決單一特征描述能力的不足,本方法從紋理特征和數學形態學特征中各選一種具有代表性的特征和光譜特征進行融合,以提高特征的信息承載能力,為此,提出了一種自適應的特征融合方法,提高新特征的魯棒性。為了解決后處理中超像素鄰域信息利用不充分的問題,本方法利用超像素鄰域信息對融合后的新特征進行指導和校正,讓每個像素都能利用到超像素信息。
本文采用總體的分類精度(Overall Accuracy , OA)和Kappa系數作為識別精度的評價指標[12-13],對Indian Pines圖像,Salinas圖像進行驗證。試驗結果表明,多種空間特征融合的效果優于單一空間特征,用超像素信息進行特征校正的方法的效果優于用超像素信息進行后處理的方法。
1 空間特征提取與融合
1.1 差分形態學特征
開運算和閉運算是最基本的形態學操作。這兩個操作以結構元素(Structuring Elements,SE)為基礎去掉亮的或暗的細節,保留相對穩定的全局特征。此外,形態學操作能夠較好地保存形狀信息而不引入噪聲,隨著結構元素尺度的變化,則會產生不同的形態學操作。
形態學剖面(Morphological Profiles,MP)是由一系列形態學操作構成的。對于圖像I,假設OPSE(I)和CLSE(I)為使用SE元素的開操作和閉操作,則開運算和閉運算下的MP定義如下:
(1)
式中:λ為SE結構元素的半徑。圖像I進行一次開運算,得到圖像I′,I′的每個像素點的值表示圖像I對應像素點的一個特征值,用不同半徑的SE結構進行開運算就會得到不同的SE操作下的特征值,閉運算同理。隨著元素半徑的逐步增加,開運算和閉運算下MP的差分DMP定義如下:
?λ∈[1,n]}
?λ∈[1,n]}(2)
通常將DMPOP和DMPCL串聯構成一個新的向量DMP=[DMPOP,DMPCL]來表示圖像的明暗紋理特征。對于高光譜圖像,不同的層或降維后的不同層均可以提取DMP特征[13]。
1.2 Gabor特征
Gabor特征是一種紋理特征。因為紋理是由很多微小的紋理基元組合而成的,在紋理特征提取時應該著重考慮紋理的這些局部特征,所以現有的單層圖像紋理特征提取方法一般都基于窗口濾波的方法。即用一個大小固定的窗口在單層的圖像上移動,用這個窗口內除中心點以外的所有像素值的線性或者非線性組合來替換掉窗口中心點像素的值。窗口在整個圖像上按像素點依次移動計算,就能夠計算出圖像中所有像素點的紋理特征。
用Gabor濾波器提取圖像紋理特征時,和所有濾波器一樣,用一個窗口在單層圖像上移動進行卷積運算更新單層圖像像素的值。Gabor濾波器窗口模板是由Gabor核決定的,二維Gabor核函數如下:
(3)
式中:λ為波長;θ為方向;ψ為相位偏移;γ為空間縱橫比;b為帶寬;σ為Gabor函數的高斯因子的標準差。 Gabor核根據不同的尺度和方向有不同的選擇,并且每種核函數用于濾波都能提取到不同的紋理信息。在實際的應用中,一般選擇5方向和8個尺度總共40個核函數對圖像的一個波段進行濾波,每個像素能得到一個40維的紋理特征。
1.3 多種特征融合
為了提高特征的魯棒性,本文用多種空間特征進行融合,以差分形態學特征提取方法為基準,根據目標圖片自適應的找出近似最優差分形態學特征,然后再融合固定的Gabor特征和光譜特征。
差分形態學特征分類精度和不同大小的結構元素SE的數量息息相關,如果不同大小的結構元素SE的數量越多,則差分形態學特征的維數越大。令SE的數量為m,差分形態學特征的維數為d,兩者關系為d=2(m-1)。
不同維數的差分形態學特征最終的分類精度不同,為了選擇最優維數的差分形態學特征,算法對不同維數的差分形態學特征的分類精度進行比較,選擇最優精度的特征作為最優解。
算法用正方形作為結構元素,第i個結構元素的邊長li定義如下:
li=3+2(i-1)(4)
如果結構元素的邊長大于目標圖像的最短邊長,這樣的結構元素是沒有意義的。本算法用不同數量的結構元素提取差分形態學特征,然后進行取優。不同結構的數量不超過目標圖像最短邊長的一半。
目前Gabor濾波器提取特征一般都是取5個方向8個尺度共計40個核函數進行濾波處理,故本文也是采用40維的Gabor特征。首先對原始高光譜圖像進行PCA降維處理,對第一主成分進行Gabor濾波,得到一個40維的Gabor特征向量。因為根據經驗,光譜特征的識別精度比Gabor特征差,所以本文光譜特征的維數取Gabor特征的一半。
綜上所述,本文提出的多種特征之間的融合方法具體步驟如下:
第1步:根據輸入圖像的最短邊長,計算出最多能用多少個結構元素SE進行差分形態學特征提取。
第2步:用5個SE提取的特征進行分類,用10個SE提取的特征進行分類等等,每增加5個SE進行一次分類,一直到SE元素數量達到最大。
第3步:按步驟2選擇出最優差分形態學特征之后,把它和40維的Gabor特征、20維的光譜特征進行橫向融合,得到整個的融合特征向量。需要注意的是其中每一種特征都需要做數據歸一化,最后整個的融合特征向量需要再次歸一化。
2 方法介紹
2.1 超像素分割
在遙感領域,根據地理學第一定律可知,相鄰的像素之間表示同一種事物的可能性遠大于不相鄰的像素,這種領域的空間信息在很多應用上都有指導性的用途,而把圖像分割成很多包含相似視覺特征的超像素塊,恰好能很好描述這種信息。所以超像素分割越來越多的應用在圖像處理過程中,如圖像分割、目標定位和物體識別等。
簡單線性迭代算法(Simple Linear Iterative Clustering,SLIC)[14]是一種簡單、快速的超像素生成算法,能夠生成緊湊近似均勻的超像素塊。SLIC算法不僅可以分割彩色圖像,同時也兼容分割灰度圖像,而且在使用上也很方便,只需要設置很少的參數。SLIC的基本思想是K-means聚類,把特征相似的像素的歸為一類。但是和K-means不同的是,SLIC在聚類中加入空間位置的限制。
SLIC算法需要指定一個描述超像素塊緊密程度的參數。如果這個參數越大,超像素塊邊界越平滑,此時超像素形狀趨近圓形;如果參數值越小,部分超像素塊的形狀就會趨于扁平,并且邊界中會出現一些比較尖銳的角。對于圖像中紋理比較復雜的區域,超像素的邊界一般都比較尖銳,并且有很多長條形的超像素出現,此時需要一個比較大的參數值讓這些超像素趨于平滑;而對于圖像中紋理比較簡單的區域,超像素超像素塊一般比較圓潤,此時需要一個比較小的緊密度參數,讓超像素的邊界尖銳一些,更好地去描繪圖像的紋理信息。如果根據經驗來確定這個參數的大小,得到一個合理的值是很困難的,SLICO是SLIC超像素分割算法的改進算法,算法根據不同區域的紋理復雜度自動選擇一個合適的參數值,使圖像中的超像素塊更加規整統一,能夠避免形狀不規則導致的分割效果偏差。
2.2 超像素信息融合
超像素領域信息是一種重要的空間信息,目前文獻中一般利用超像素信息對分類結果進行后處理操作。具體操作是統計一個超像素中像素的標簽,如果相同標簽的數量占整個超像素塊總像素數量的比例大于一定的值,則把超像素塊中的所有像素標簽統一。這種按照超像素為單位的校正方法不能很好地把超像素信息利用到每個像素。本文通過把超像素信息和用于分類的特征進行融合,讓超像素信息能夠對每個像素都進行指導,具體做法如圖1所示,可描述為如下步驟:
第1步:按照超像素塊的位置,計算每一個超像素區域的高光譜特征均值。把超像素塊區域的特征看成向量集合xl={xn∈Rc,n=1,2,…,Nl},l=1,2,…,N,N為總的超像素塊的個數。Nl為第l個超像素塊中像素點的個數。第l個超像素塊區域特征均值計算如下:
(5)
(6)
式中:α為權系數,根據經驗值調整。
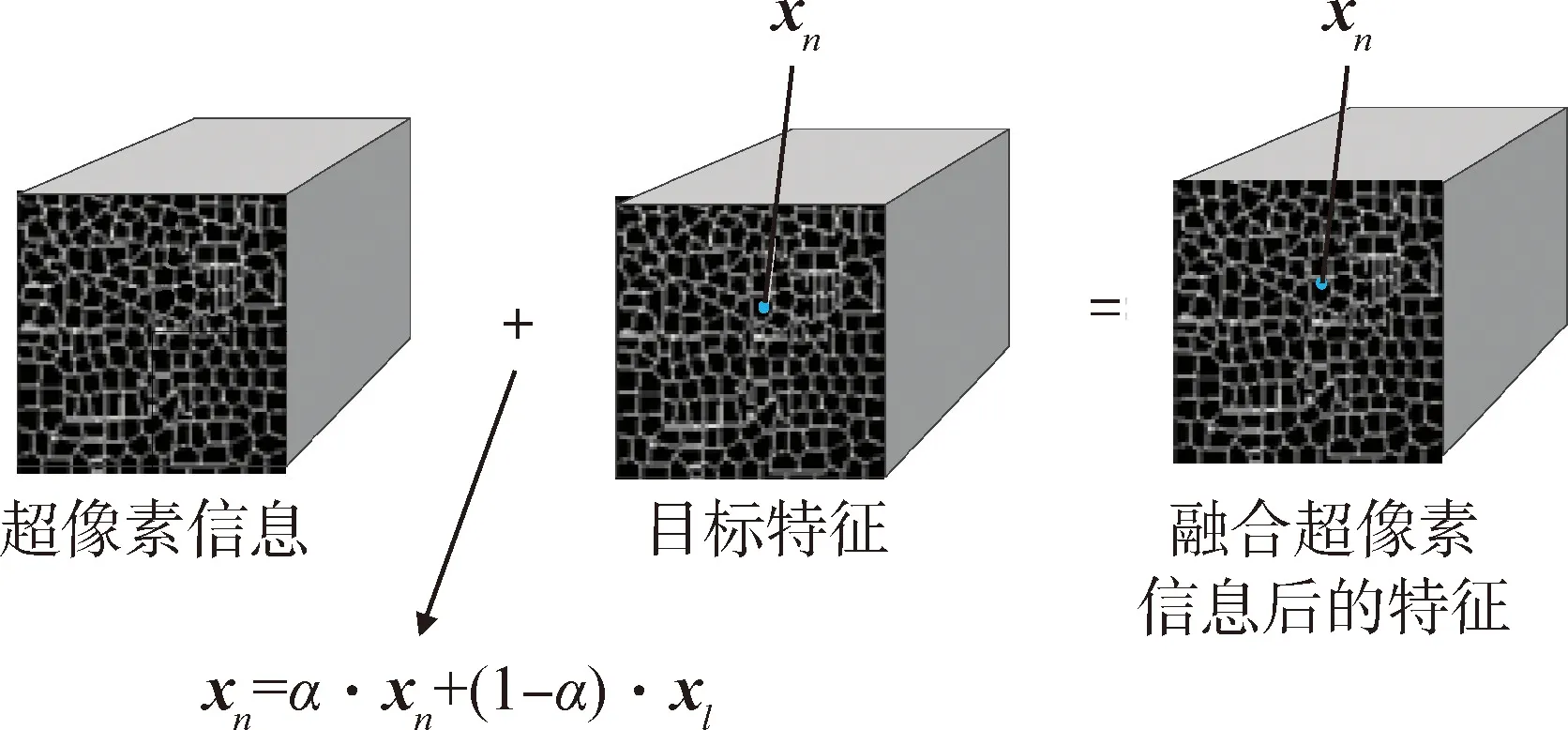
圖1 特征“平滑移動”示意Fig.1 Illustration chart of feature translation
平滑移動算法把超像素信息融入高光譜的每個像素特征向量中去,提高了分類結果的精度,使得分類結果中每個像素標簽的置信度都有所提高。此時,如果一個超像素塊區域中含有大量具有相同標簽的像素,則這個超像素塊中,其他類別標簽的像素屬于誤標像素的概率就高于平滑移動之前的誤標概率。
2.3 本文高光譜圖像分類算法描述
圖2展示了融合SLICO空間信息的多特征融合分類算法的框架。具體的算法步驟描述如下:
第1步,將高光譜圖像降為20維。
第2步,用光譜第一層主成份提取Gabor特征。取前20層主成份作為光譜特征。
第3步,按第1.3節介紹的方法選擇最優差分形態學特征。
第4步,把最優差分形態學特征與Gabor特征和光譜特征進行橫向融合,得到融合后的特征向量。
第5步,用SLICO算法對光譜的前3個主成份進行超像素分割。
第6步,超像素信息和所提取特征按第2.2節的算法進行融合。
第7步,用融合了超像素信息的新特征進行分類,并且把分類結果和第3步得到的最優差分形態學特征的分類結果進行比較,選擇較優的結果作為算法的輸出結果。
第8步,用超像素信息對第7步得到的最優結果進行后處理。
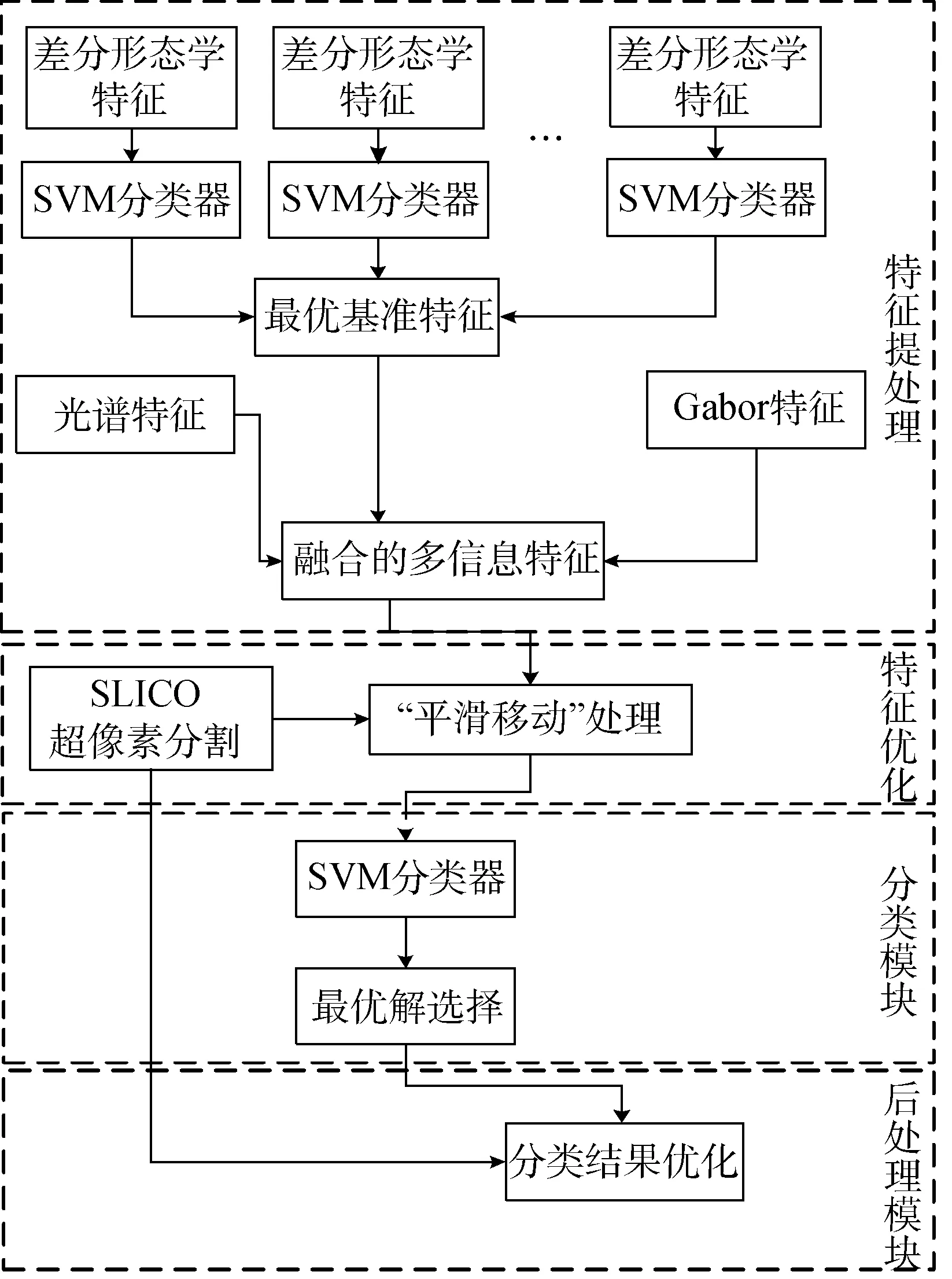
圖2 多特征融合分類算法框架Fig.2 Illustration chart of multi-feature fusion classification
因為遙感圖像的復雜多變性,多特征融合可能產生精度低于最優差分形態學特征進行分類的精度。為了避免這種情況,在第7步時對兩者結果進行比較,選擇最優解進行下述后處理。在第8步中再次利用SLICO超像素信息,根據超像素塊中各個像素點類別標簽的分布對分類結果進行糾正。
3 試驗結果
3.1 試驗數據集
本文用Indian Pines圖像進行試驗驗證。印第安農林數據集來自光譜儀Airbome Visible Infra-Red Imaging Spectrometer(AVIRIS),是1992年在印第安納州西北部印第安農林收集到的高光譜遙感圖像,具有20m的空間分辨率,包含144×144個像元,220個波段。由于噪聲和水吸收等因素除去其中的20個波段,剩余200個波段,包含16種植被,具體地物類別和樣本個數見表1,樣本總數10 366。

表1 Indian Pines圖像每種類別的樣本數
3.2 評價指標
在機器學習分類器的評價中,一般都需要輸出分類任務的混淆矩陣M:
(7)
式中:c為分類任務中類別個數。混淆矩陣的每一列代表了預測類別,每一列的總數表示預測為該類別樣本的數目;每一行代表了樣本的真實歸屬類別,每一行的樣本總數表示該類別的樣本實例的數目。所以mij表示實際上為第i類且預測為第j類的樣本的數量。
通過混淆矩陣,可以得到很多分類信息,但缺點是不直觀,在評價分類器性能時一般都是利用混淆矩陣中的數據計算出一些相對比較直觀的數據進行評價。在高光譜分類任務中,如果沒有特殊的任務需求,一般只關注分類的整體效果,不需要對一個特定的類別進行著重觀察,所以本文采取其中一個評價標準,即總體分類精度:
(8)
式中:N為所有測試樣本數量;mii為正確分類的樣本個數。
總體分類精度OA可以描述分類結果的整體性能,但在類別不平衡的情況下,OA有一定的局限性,比如一個樣本數量很少的類別,即使這個類別的所有樣本錯分,對OA的影響也很小。為此,本文中增加了另一個評價標準——Kappa系數:
式中:mi+為第i行的總觀測數;m+i為第i列的總觀測數。
在統計學中Kappa系數是用來度量兩個被觀測對象的一致程度,在高光譜分類中則用來度量樣本預測值和真實值之間的一致程度。Kappa值的取值在0~1之間,Kappa系數的值越大,說明預測結果和真實結果越接近,反之則說明預測結果和真實結果相差越大,分類效果則越差[15-17]。
3.3 試驗結果
為了驗證本文算法的有效性,分3個部分進行驗證。
(1)單一特征分類方法和本文方法的對比
為了驗證多特征融合的有效性,本節把只用Gabor特征、只用差分形態學特征和只用光譜特征的分類結果的OA和Kappa系數和本文方法的分類結果的OA和Kappa系數進行比較。試驗使用Indian Pines圖像,每一類訓練樣本抽取總體樣本的5%,且不少于10個樣本。為了排除干擾,本節所有試驗都不融合超像素信息,且不進行后處理操作。
表2展示了不同的差分形態學特征的分類的OA和Kappa系數。Indian Pines圖像大小為145×145×200像素,而第40個結構元素的邊長為83像素,長度已經大于Indian Pines圖像最短邊長的一半,所以結構元素取到35是合理的。結構元素數量取10的時候,所得到的差分形態學特征取的分類結果OA和Kappa同時達到最大,分別為0.951 765和0.945 01。
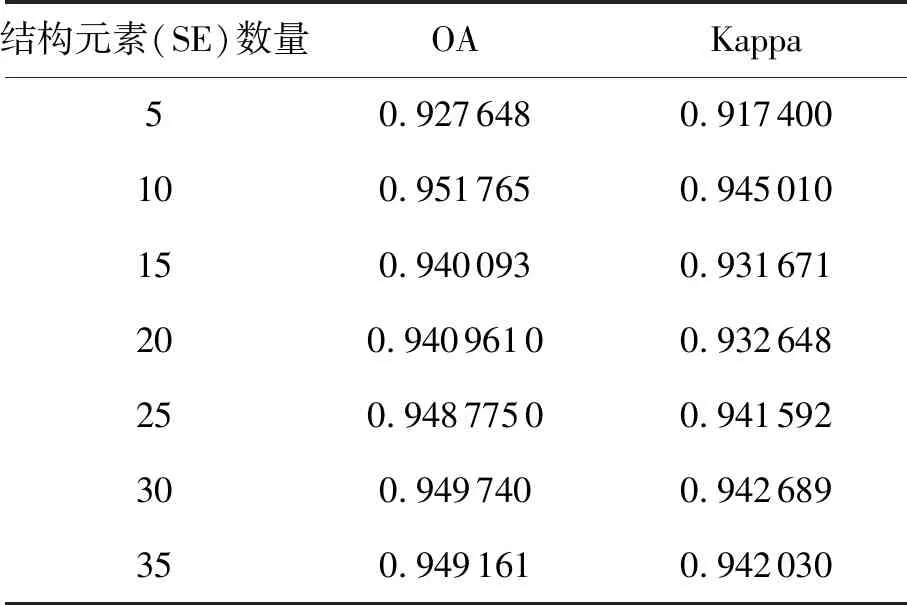
表2 Indian Pines圖像不同差分形態學特征的分類結果
表3給出了Indian Pines圖像不同特征的試驗數據,融合特征的OA和Kappa經過Gabor特征和光譜特征的修正,比表2中最優的差分形態學特征的OA和Kappa都有了提高。
圖3展示了Indian Pines圖像的不同特征的分類效果。圖3(a)為只用40維光譜特征得到的分類結果,圖中有大量的“椒鹽噪點”,圖3(b)為最優差分形態學特征得到的分類結果,整體效果較好,不同類別相鄰的區域存在部分誤分。圖3(c)為只用Gabor特征得到的分類結果。圖3(d)為用融合特征得到的結果圖。圖中標記了4個區域,正方形區域,橢圓區域,三角形區域和六邊形區域。對于正方形區域,最優差分形態學特征的分類結果圖3(b)有誤分情況,通過Gabor特征圖3(c)得到改正,使得融合特征圖3(d)得到正確的結果。對于橢圓區域,圖3(b)同樣部分誤分,通過Gabor特征和光譜特征得到改正。對于三角形區域,光譜特征對結果優化取到了很大的作用。對于六邊形區域,圖3(b)分類結果正確,Gabor特征和光譜特征的影響,融合特征圖3(d)在這個區域上部分誤分。
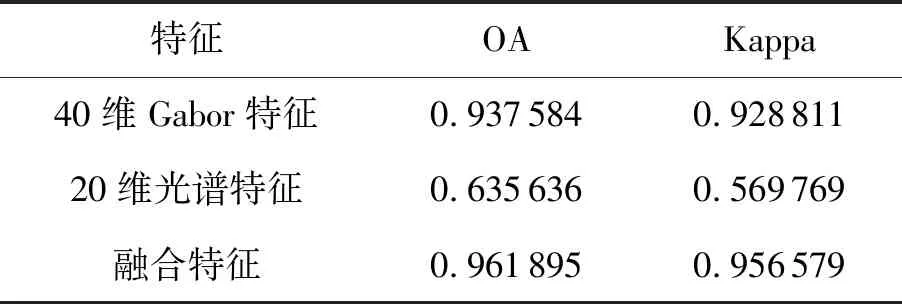
表3 Indian Pines圖像融合特征的分類結果
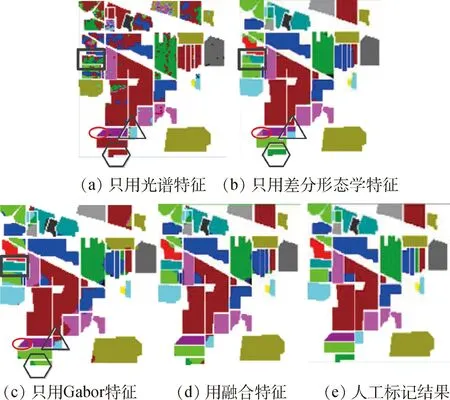
圖3 Indian Pines圖像不同特征的分類結果Fig.3 Classification result of different features of Indian Pines image
(2)特征和超像素信息融合的有效性驗證
本節試驗分別用Gabor特征,差分形態學、光譜特征和融合特征和超像素信息進行融合,然后用SVM進行分類。每一類樣本取5%作為訓練樣本并且每一類訓練樣本至少取10個。Gabor特征維數取40維,光譜特征取20維,差分形態學取10個結構元素,即54維特征,融合特征為3者的橫向融合。“平滑移動”比例系數α取0.7。
為了驗證融合超像素的方法優于后處理的方法。對比試驗設計為:用原始特征送入SVM分類進行分類,然后對結果進行后處理;特征融合超像素信息后送入SVM進行分類。訓練樣本、特征的選取和第一部試實驗相同。表4為兩種方法的對比結果,可以很明顯地看出對于所有的特征,融合超像素信息的方法均優于后處理的方法。
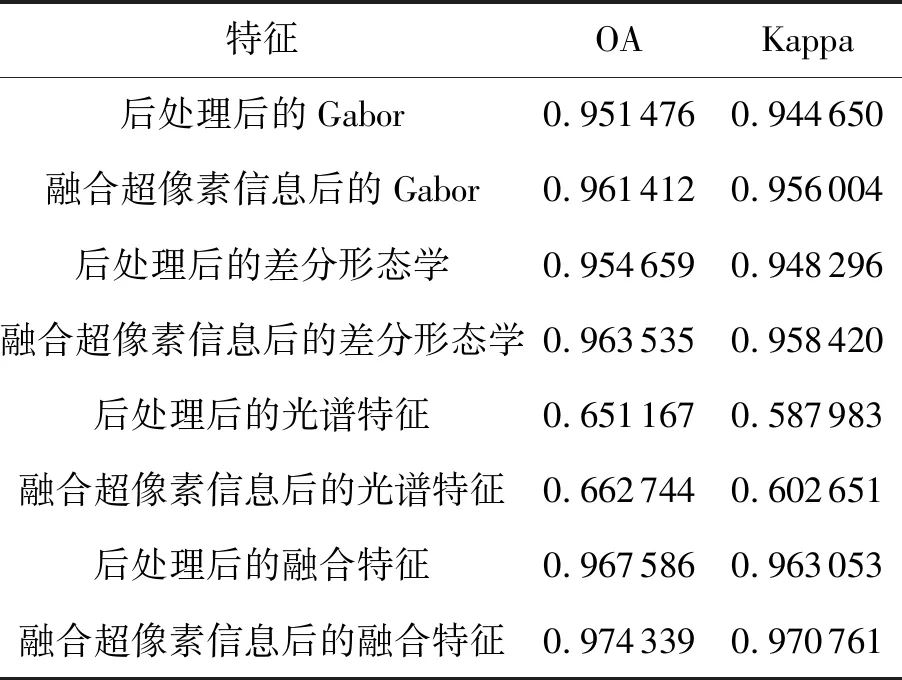
表4 融合超像素信息的分類結果
(3)和現有的空譜分類方法進行對比
選用了4個近年來提出的具有代表性的方法和本文算法進行了比較。對比方法為DTBS-SVM[18], BS-SVM[19], NLGD-SVM[20]和FS-SMLRSSAMRF[21]。4種方法都用Indian Pines圖像進行了試驗。訓練樣本取5%。表5給出了Indian Pines圖像上不同方法的試驗數據,從表中可以看出,無論OA還是Kappa,本算法都優于其他算法。
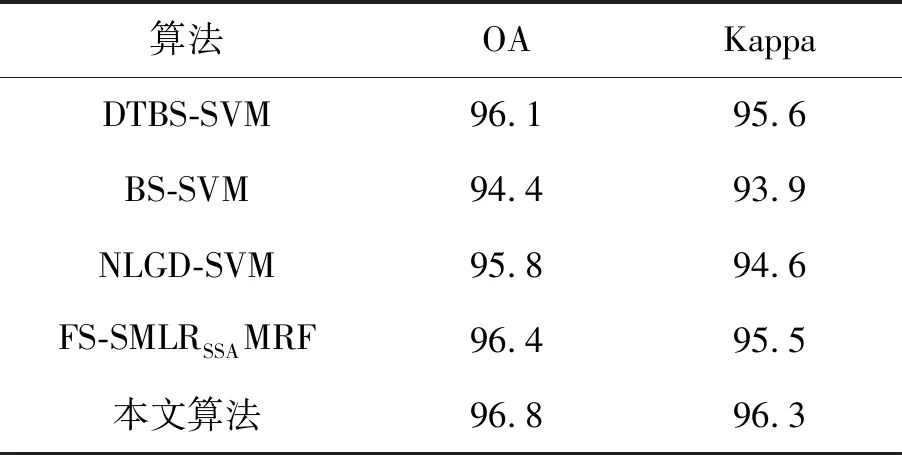
表5 Indian Pines圖像不同分類方法結果對比
4 結束語
本文提出了一種結合多種空間特征的高光譜分類方法。光譜特征、差分形態學特征和Gabor特征融合得到的新特征的分類結果并不一定優于其中一種特征分類結果的最優值,因此本文將最優差分形態學特征與Gabor特征和光譜特征融合,分類結果與最優差分形態學特征的結果進行比較,輸出較優的分類結果。通過試驗證明了該方法的有效性,評價指標OA和Kappa均有一定的提升。同時提出了一種用超像素信息對特征進行“平滑移動”的后處理方法,把超像素信息融入到每個像素特征向量中。進一步的研究方向是加深對特征融合的理解和研究,自適應地控制調節紋理特征和光譜特征的比例等。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
