基于協同過濾的發型推薦算法
2019-05-27 01:18:52張帥賈年
現代計算機 2019年11期
關鍵詞:用戶
張帥,賈年
(西華大學計算機與軟件工程學院,成都 610039)
0 引言
隨著計算機技術和互聯網技術的飛速發展,當今社會已然進入了信息爆炸時代。便利的互聯網和日益普及的移動終端極大地提高了人們獲取信息的速度,但是互聯網上的信息量增長迅速,因為信息量極大的原因,用戶有時候很難快速地找到自己想要的或者感興趣的信息[1]。因此,推薦系統應運而生。為了能夠讓用戶在短時間內迅速得到自己想要的信息,推薦系統通過對互聯網上海量的信息經過過濾整合,結合用戶自己的興趣偏好等信息,通過推薦算法的計算,最終將用戶最有可能感興趣的信息及時的推薦給用戶,提高了用戶上網的效率[2]。經過多年的完善和細化,推薦算法越來越成熟,一般的推薦算法主要包括基于內容的推薦算法、混合推薦算法和協同過濾推薦算法[3]。
進入21世紀后,人們的生活水平越來越高,因此大家對自己的生活質量的要求也越來越高,其中的一個例子就是對發型的要求。愛美之心,人皆有之,大家都希望剪一個適合自己的發型讓自己看起來更加帥氣或美麗。社會在進步,美發行業也在進步,各種理發店越來越多,各種發型也越來越多,在面對眾多發型選擇時大家總會束手無策。
針對上述問題,本文結合協同過濾算法,將個性化推薦技術應用于發型推薦,根據用戶的興趣偏好,為用戶提供個性化的發型推薦,對協同過濾推薦算法進行了進一步的研究。
1 協同過濾算法
推薦算法的種類很多,在目前應用最廣泛、比較成功的所有的推薦算法中,協同過濾算法在其中占據一席之地。協同過濾算法于1992年由Golderg、Nicols和Terry等學者首次提出這個概念,但是當時并沒有將此算法運用地很好,近些年因為互聯網的迅速發展,有了海量的信息供我們使用,協同過濾算法開始大展身手[4]。
協同過濾算法的主要思想是對于具有相同或相似的興趣愛好的用戶們,其中某一個用戶喜歡某一個物品,那么另一個用戶也可能會喜歡這個物品,則就將此物品推薦給后者。協同過濾算法大致可以通過三個步驟達到推薦效果:第一步,數據建模,構建一個比較精確的用戶偏好模型;第二步,計算用戶間的相似度,生成目標用戶的鄰居集合;最后一步是根據生成的鄰居集,產生TOP-N個推薦數據[5]。
一般來說,我們將協同過濾算法分類為基于用戶、基于項目以及基于模型的推薦算法這三種類型[6]。
(1)基于用戶的協同過濾推薦算法主要是通過計算用戶與用戶之間的相似度,將得到的相似度進行大小排列后得到與目標用戶喜好相似度最高的用戶,根據此相似度最高的用戶的喜好來為目標用戶推薦其最有可能感興趣的物品。
(2)基于項目的協同過濾推薦算法主要是通過計算已評價項目和待遇測項目的相似度,將相似度作為權重,加權其他已評價項目的評價分數,得到預測項目的預測值。
(3)基于模型的協同過濾推薦算法主要是通過對用戶——項目評分矩陣進行分析和數據挖掘后,建立目標用戶的評分預測模型,根據目標用戶的歷史評分數據分析其興趣偏好,最后來對目標用戶未評分的項目進行評分預測。此算法可以適當地解決推薦算法中的數據稀疏性和冷啟動的問題[7]。
2 基于協同過濾的發型推薦算法
2. 1 算法步驟簡述
本文發型推薦的算法的實現主要分為以下幾個步驟:
輸入:輸入顧客——發型的評分矩陣R。
輸出:顧客i對未評分發型的預測評分S(i,h)。
(1)使用余弦相似度計算目標顧客i與其他所有顧客的相似度 sim(i,Ua),i≠Ua,Ua∈U,U為所有顧客的集合。
(2)生成顧客 i的最近鄰居集合 Ni={N1,N2,N3,...,Nk},i不屬于 Ni。
(3)得到顧客i對未評分發型h的預測評分S(i,h)為:
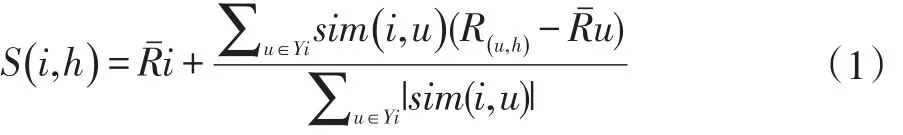
其中Rˉi和Rˉu分別為顧客i和顧客u對所有發型的評分的平均分,R(u,h)是顧客 u對發型 h的評分。
算法的執行流程如圖1所示。
2. 2 數據獲取
本文中所有的信息數據獲取來自西華大學周圍的數十家理發店的顧客。設定用戶對每種發型的喜好程度為5分制,最喜歡為5分,最不喜歡為1分,男生不對女生發型做出評價或者女生不對男生發型做出評價以0分定義。在一個多月時間內,總共獲取到近300位顧客對20多種發型的喜好評分數據。

圖1 推薦算法流程圖
2. 3 數據建模
在任何的一個推薦系算法中,都是根據用戶對某一些對象的偏好程度來為用戶產生推薦。因此,用戶偏好模型的構造是推薦算法能否成功的關鍵[8]。推薦質量的好與壞很大程度上取決于用戶偏好模型表示用戶偏好的能力。
用戶偏好模型的建立依賴于搜集到的用戶信息,這些信息的獲取方法主要包括顯示獲取和隱式獲取兩種[9]。顯示獲取主要是取決于用戶顯示的對一些商品的評價的高低來表達用戶的興趣;隱式獲取主要是用戶在網站上的一些行為如瀏覽時間、瀏覽頻率等來表達用戶的興趣。本文采取的是顯示獲取用戶興趣偏好的方法。
本文通過建立用戶——項目評分矩陣,對采集到的實驗數據進行建模,將推薦系統表示為二維的顧客——發型評分矩陣R(U×H)。其中ui∈U為用戶集合,hj∈H為發型集合,矩陣中的元素rij∈R代表某一用戶對某一發型的評分。
2. 4 用戶相似度計算
對于協同過濾算法而言,如何計算目標用戶與其他用戶之間的相似度是該算法的一個重點之處。一般的用戶相似度計算方法主要有余弦相似度、歐氏距離、皮爾森相關系數以及Jaccard距離等[10]。本文使用的是基于余弦相似度的算法,算法公式如下:

其中cos(θ)的值越接近1,就代表夾角越接近零度,也就是兩個向量越相似,即兩個用戶的興趣偏好相似度越高。舉例如下:
(1)首先從采集的數據中取一些數據定義一個顧客——發型評分的矩陣R,如表1。
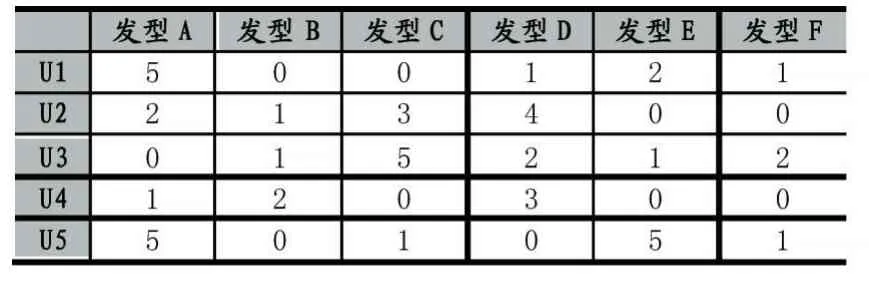
表1
(2)接下來利用上述的公式(2)對矩陣R中的數據進行運算,得到矩陣Rcos,如表2。
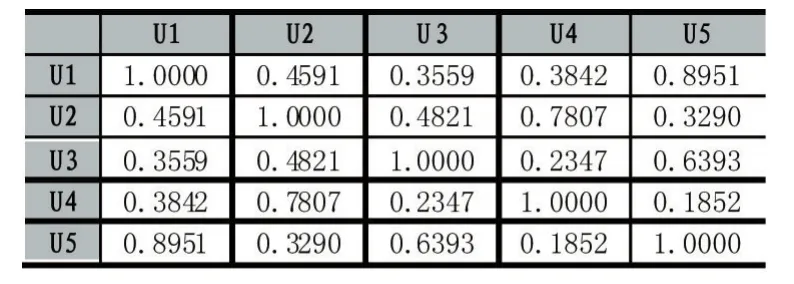
表2
矩陣Rcos就是基于理發店顧客的相似度矩陣。
2. 5 鄰居集的生成
依據推薦算法,對每一個目標用戶u最終都會產生一個根據相似度大小排列的鄰居集合Ni={N1,N2,N3,...,Nk},u不屬于 Ni,從 N1到 Nk表示用戶 u與鄰居用戶Ni的相似性大小的值從大到小的排列。
根據研究數據表明,鄰居集和大小k的取值會影響算法的精確度,k的取值過于大或者過于小都會影響到推薦的精確度,根據研究k的值一般為
2. 6 推薦結果生成
2. 7 實驗結果及分析
推薦結果生成主要分為以下兩個步驟:
第一步是對目標用戶的鄰居集即上述所說的集合Ni進行搜尋,通過使用TOP-N方法選出排名靠前的n個用戶作為目標用戶實際可供選擇的鄰居用戶。
第二步是根據相似度最高的鄰居用戶對某一物品的評分來預測目標用戶可能的評分。
本文所有的實驗數據均來自西華大學周圍的數十家理發店的顧客親身評分。從采集到的數據中拿出180名顧客的評分數據作為訓練集數據,將剩余的95名顧客的評分數據作為測試集來測試算法的準確性。
為了驗證推薦結果的好壞,本文采用平均絕對誤差MAE作為測評標準。平均絕對誤差通過計算目標用戶的預測評分與實際的用戶評分這兩者之間的偏差來衡量預測的準確性,MAE值越小,也就意味著推薦的效果越好,越符合目標用戶的偏好。具體的公式如下:

其中N是用戶——項目矩陣中所有未評分的發型的數目。Pi是系統對發型i的評分預測值,Ti是顧客——發型評分矩陣中元素的值。MAE的值越小,則意味著該推薦系統預測目標用戶的評分就越準確。
實驗結果表明:95個測試集用戶的平均MAE=0.49。測試結果較為滿意,因此,該算法可行性很高。因篇幅限制,表3列舉了10個測試集用戶的MAE。

表3 MAE值
3 結語
針對當下時代進步,社會進步,人們越來越注重自己的形象,所以導致發型行業飛速發展,各式各樣的發型層出不窮,大家不能很好地選擇一個自己喜歡的發型的情況,本文利用從理發店收集到的真實數據研究了基于協同過濾的發型推薦算法,通過對采集到的數據使用協同過濾算法進行處理后,實現了對目標用戶推薦符合其偏好的發型。實驗結果表明,協同過濾算法可以應用于發型推薦。下一步的工作是考慮到發型師的因素,每個顧客有自己的脾氣和性格,所以會更喜歡符合自己脾氣性格的發型師,接下來的工作就是實現為顧客推薦符合自己脾氣性格的發型師,并由此發型師來為顧客打造一個顧客自己喜歡的發型。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
