基于深度神經壓縮的YOLO加速研究
2019-05-27 01:18:44陳莉君李卓
現代計算機 2019年11期
陳莉君,李卓
(西安郵電大學計算機學院,西安710100)
0 引言
從AlphaGo開始,深度學習漸漸進入業內研究者的視線。深度學習近些年大熱的主要原因是由于近些年設備的計算力的增加,尤其是圖形處理器(Graphics Processing Unit,GPU)對于浮點數運算的有力支持。YOLO[1]的提出了一種在目標識別領域新的方式,將檢測和回歸問題集合在一起,大大的增加了對于目標的檢測速度。但是,YOLO的網絡層數相較于傳統的網絡也增加很多,導致訓練和推理的計算量會大大增加。尤其是嵌入式設備和移動設備,這些設備可能并不能很好地支撐層數增加之后帶來的計算量增加。為了能讓更多的設備和更多的人用上和享受到深度學習給他們帶來的方便,對于深度神經網絡推理加速需求就漸漸增多了[2-4]。
國內外現有的研究結果中有一部分是利用并行化神經網絡進行加速,這樣可以將一個深度神經網絡并行化拆分,分布式運行這個模型。另外一部分是使用軟件加速深度神經網絡的例子。例如:EIE(Efficient Inference Engine)[5]這個軟件提出了一個推理引擎,對這個壓縮的網絡模型進行推理,并利用權重共享進行加速稀疏矩陣的相乘過程。DeepX[6]:用于移動設備上低功耗深度學習推斷的軟件加速器。Eyeriss[7]:用于深度卷積神經網絡的節能可重構加速器。針對深度神經網絡模型的壓縮,Kim等人在2015年提出了一種壓縮CNN模型的方法。Soulie等人在2016年提出一種在模型訓練階段進行壓縮的方法。首先在全連接層損失函數上增加額外的歸一項,使得權重趨向于二值,然后對于輸出層進行量化。
現有的加速方案都是基于大型GPU設備的。對于嵌入式和移動設備,加速的效果并不是很明顯。嵌入式和移動設備的硬件限制仍然是影響神經網絡發展的一個重要的因素。
針對上述問題,本文中主要對YOLO神經網絡進行壓縮,測試深度神經壓縮[8]中剪枝方式對于卷積神經網絡的模型減少和推理加速效果。
1 深度神經壓縮
深度神經網絡中通常會有過多的參數,存在大量的計算冗余的情況。這種情況將浪費設備的內存和計算資源,加大了嵌入式設備、低功耗設備和移動設備的消耗[9-11]。
深度神經壓縮(Deep Compression)存在四種方式,參數共享方法、網絡刪減方法、暗知識方法和矩陣分解方法。
參數共享的主要思路是多個參數共享一個值。通常實現的方法可以有很多選擇。例如Vanhoucke和Hwang等人使用定點方法江都參數精度,從而是值相近的參數共享一個值。Chen等人提出一種基于哈希算法的方法,將參數映射到相應的哈希表上,實現參數共享。Gong等人使用K-means聚類方法將錢全部的參數進行聚類,每簇參數共享參數的中心值。
網絡刪減用來降低網絡復雜度,防止過擬合。Han等人針對模型的訓練效果,然后在基于參數共享和哈夫曼編碼進一步對網絡壓縮。
在基于暗知識的方法中,Sau等人基于老師-學生學習框架對網絡進行壓縮。
基于矩陣分解理論,Sainath、Denil等人采用低秩分解對神經網絡不同曾的參數進行壓縮。Denton等人在神經網絡使用矩陣分解的方法加速了卷積層的計算過程,減少了全連接層的網絡參數,對于神經網絡進行壓縮。
深度神經壓縮主要表現在三個部分:存儲、訓練復雜度和推理復雜度。以上介紹的方法中,都有各自的優點和不足。參數共享方法、網絡刪減方法、暗知識方法和矩陣分解方法都可以有效的降低模型的存儲復雜度,但是在訓練復雜度和推理復雜度上沒有重要影響。暗知識方法雖然在三個方面都有比較好的表現,但是在準確率方面,相較于其他三種方法,會有較大的變化。
2 YOLO
YOLO屬于CNN,由卷積層、池化層和全連接層組成。與CNN不同的是,YOLO的輸出層不再是max函數,而是張量(Tensor)。
YOLO的訓練和推理過程和其他CNN存在不同之處[12],例如 R-CNN、Fast R-CNN和 Faster R-CNN 三種網絡。RCC、Fast R-CNN采用模塊分離的方式進行推理過程。在檢測目標的過程中,兩種網絡需要將待檢測的目標區域進行預提取,再將包含目標的區域進行卷積/池化操作提取特征,最后進行檢測行為。在Faster R-CNN中,使用 RPN(Region Proposal Network)代替R-CNN/Fast R-CNN中的選擇搜索模塊,將RPN集成到Fast R-CNN模塊中,得到一個統一的檢測網絡。但是在模型的訓練過程中,需要反復訓練RPN網絡和Fast R-CNN網絡。上述三種網絡最大的特點就是在推理的過程中,需要將待檢測的目標區域進行預讀取。預讀取會耗費大量的磁盤(內存)空間,會對一些嵌入式設備、低功耗設備和移動設備造成壓力。YOLO在設計的過程中就針對的進行了改進。
3 基于深度神經壓縮的YOLO加速
原始的YOLO模型在完成訓練后,模型大小達到200M,對于嵌入式設備和移動設備而言。200M的模型進行內存預讀,會對設備的性能造成較大的影響,所以論文主要從深度神經壓縮理論入手,對于YOLO進行修改,達到對于模型進行體積壓縮,改善其在嵌入式設備和移動設備上的表現[15]。針對YOLO進行深度神經壓縮,主要是以下步驟:
(1)權值修剪
(2)權值共享和量化
流程如圖1所示。
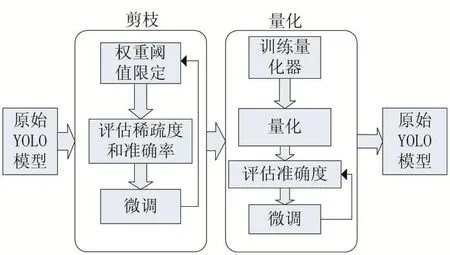
圖1 壓縮框架圖
3. 1 權值修剪
權值修剪[16]主要目的是保存YOLO中重要的鏈接來達到降低存儲數量和計算復雜度的目的。傳統的神經網絡訓練過程中,在神經網絡訓練之前,神經網絡的框架結構就已經被固定了。用戶只需要進行數據的輸入,就可以在迭代訓練后獲得需要的權重。但是這種固定框架結構的方式,導致不能在訓練的過程中,隨時對于神經網絡的結構進行優化。因此,常規訓練出的模型文件大小都不適合于部署在嵌入式設備或者移動設備上。YOLO常規訓練后的模型大小達到200M,對于嵌入式設備,將模型預讀進內存中,提供給推理過程使用,將會消耗設備的所有內存。所以,利用深度神經壓縮的剪枝思路,對于YOLO模型進行壓縮,是提高YOLO在各種設備上通用性的一個方式。剪枝過程分為四個步驟;
(1)通過訓練找到權重小于閾值的神經網絡鏈接;
(2)刪除權重小于閾值的神經網絡鏈接;
(3)重新對于神經網絡進行訓練;
(4)將修剪后的以 CSR(Compressed Sparse Row)方式存儲。
在訓練的過程中使用公式:
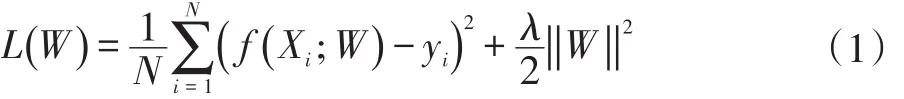
對權重進行計算,使一部分權重趨向于0,然后將小于閾值的鏈接剪枝。使用公式的目的是能夠減少在訓練剪枝過程中的過擬合現象,并且可以保持較高的精度。相對的,通常訓練過程中的Droupout概率也需要進行調整。在深度神經網絡訓練的過程中,Droupout主要是用來防止訓練出的模型數據有過擬合的現象。因為在上述的剪枝過程中,使用了L2正則進行過擬合的預防。所以,在重訓練的過程中,按照剪枝后的神經網絡數量進行對Droupout概率進行等比例的調整。初步剪枝之后將要進行對于本次鏈接層的一個重訓練。每一次的剪枝過后的重新訓練都是一個原子操作。重新訓練的目的是為了神經網絡模型有更好的精確度,以及更小的過擬合的可能。
剪枝之后的權重按照CSR方式進行存儲,CSR方式可以減少存儲元素位置index帶來的額外存儲開銷。按CSR方式轉換完成的稀疏矩陣,在存儲的過程中使用按位存儲的方式,存儲過程中,每一個非零元素都會進行標記。如果使用3bit形式進行存儲,每一個非零元素和另外一個非零元素之間的距離在標記后將會被檢查。如果一個非零元素和另外一個非零元素的超過8,則這個第八位的位置將會被填充一個0,這樣防止在使用按位存儲的時候出現數據的溢出。
3. 2 權值共享和量化
為了進一步的壓縮剪枝之后的YOLO,第二部將使用權值共享的方法[17],對于剪枝結束的權值,進行一個K-means聚類。

式(2)中,W代表權值C代表聚類。
聚類之后的結果代表著一類權值的聚類執行,這個質心的值將作為共享的權值進行存儲。最后存儲的結果是一個碼書和一個索引表。
K-means算法中,聚類的核心是聚類中心的選擇和初始化。常規的初始化方式有三種:
(1)隨機初始化
(2)密度分布初始化
(3)線性初始化
由于在神經網絡的訓練中,權值越大,對神經網絡精確度的影響越高,所以使用將權重排序后進行線性劃分的線性初始化較為合適。
本層的權重完成剪枝和共享之后,將執行神經網絡層與層之間的前向傳播和反向傳播。前向傳播時需要將每個權值用其經過聚類的中心進行代替,反向傳播時,計算每個聚類中權值的梯度,用來進行聚類中心的更新和迭代。
4 實驗結果與分析
實驗結果分析算法在經過深度神經壓縮之后壓縮率、準確率和執行速度。運行YOLO模型的設備為NVIDIA TX2嵌入式開發板。YOLO的訓練數據集為基于VoC2007和ImageNet的常見數據集。
4. 1 壓縮率
表1中展示了YOLO未壓縮和已壓縮之后的大小對比。
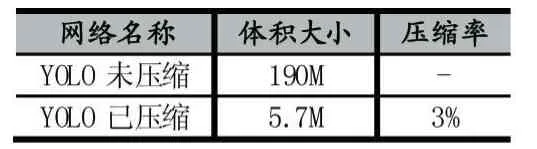
表1 YOLO壓縮體積對比
由表1可以看出,經過深度神經壓縮后的模型只有原模型的3%,減少了嵌入式設備和移動設備在預讀模型時的內存消耗,提高了模型預讀的速度。
4. 2 準確率
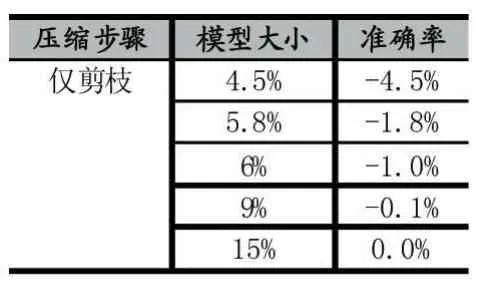
表2 僅剪枝YOLO模型大小和準確率
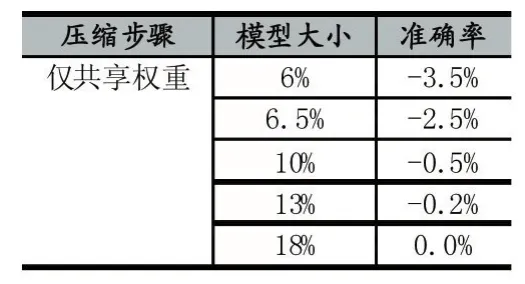
表3 僅共享權重

表4 剪枝+共享權重
從表2、3、4可以得到,準確率隨著模型體積的下降而下降。僅剪枝能達到的最低壓縮率為4.5%。僅共享權重最低壓縮率可以達到6%。剪枝和共享權重可以達到最低的壓縮率3%。
4. 3 運行速度

表5 壓縮YOLO在嵌入式設備上運行時間
表5可以看出壓縮網絡對比原始網絡,在嵌入式GPU設備上可以獲得5倍加速。
5 結語
本方案基于深度升級壓縮理論,提出了YOLO算法的改進方案。對于YOLO算法進行剪枝、共享權重、霍夫曼編碼等步驟。并且將壓縮后的YOLO算法部署到NVIDIA TX2上,進行目標識別實驗。實驗結果表明,經過優化的YOLO可以在原體積3%的情況下穩定運行,并且準確率相較于原模型只有-2%的差距。并且在嵌入式設備上獲得原模型5倍的加速效果。但是該實驗只是單純的進行L2范式的權重衡量,沒有做到多情況的權重衡量。并且K-means只選擇了線性初始化的情況。后期實驗可以進行優化,找到更好的剪枝方式和聚類方式[19-20]。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:26:08
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環保(2016年3期)2017-01-20 08:15:32
工業設計(2016年12期)2016-04-16 02:52:00
消費者報道(2014年7期)2014-07-31 11:23:57
