軟件故障定位技術研究綜述
2019-05-27 08:38:36
計算機測量與控制 2019年5期
(北京控制工程研究所,北京 100081)
0 引言
在軟件調試過程中,故障定位是最耗時和費力的活動之一[1]。隨著當前軟件復雜度越來越高,迫切需要提高故障定位的效率,減少開發人員的工作量,降低開發過程的成本開銷。軟件故障定位是通過對源程序的語義和結構進行分析,結合程序執行情況和結果,幫助測試人員找到程序中的故障位置的過程。在故障定位的研究方法中依據是否需要運行程序的準則可以分為靜態方法和動態方法。前者指的是不運行待測程序,利用程序語句之間的依賴關系以及類型約束來研究程序中的故障位置;后者則是結合測試用例運行待定位的程序,對程序執行過程中的信息進行分析,利用程序動態執行信息進行定位。
本文調研了近幾年提出的一些代表性的故障定位技術,根據在進行定位時所利用的信息及定位方式進行分類并闡述其原理模型,并對不同方法的優缺點進行了對比。然后對測試用例程序集以及故障定位效率評價方法進行了介紹,最后對未來研究方向提出了展望。
1 故障定位技術
軟件故障在IEEE標準中被定義為‘計算機程序中不正確的步驟、過程或者數據定義 ’,我們研究的故障定位就是要找到引起軟件出錯的故障所在位置[2]。我們通常將故障描述為由于客觀因素或系統里包含一些系統問題使軟件在運行時出現得到的實際結果和預期輸出存在差異的情形。
在故障定位領域中,我們根據程序中包含的故障數目,將故障定位研究分成單故障定位和多故障定位。一般來說,多故障程序定位消耗的時間復雜度要高于單故障程序的時間復雜度,因此現在主要的研究重點大多是解決單故障程序的定位技術。本文首先介紹一些基于單故障程序定位的一些方法技術,然后列舉一些多故障程序定位的算法技術,最后從幾個方面對比單故障程序定位和多故障程序定位。
1.1 單故障定位技術
1.1.1 基于覆蓋的故障定位技術
該類方法首先將待測程序進行插樁處理,然后執行源程序,得到程序語句在所有測試用例下的覆蓋執行信息,最后利用各自的方法對執行信息進行分析計算并進行定位。Wong對語句和測試用例之間的關系提出了這樣的假設[3]:一條語句包含故障的概率和它被成功用例執行頻數成負相關,和它被失敗用例執行次數成正相關。也就是說,某一語句在失敗測試用例中出現的頻率越高,而在成功執行的用例中出現的頻數越少,則該語句含有故障的概率就越大。基于覆蓋的故障定位技術的方法不足之處是對測試用例的要求和限制十分嚴格,如果測試集中的測試用例數目過少,則會導致語句覆蓋不全面的情況;如果測試用例數目過多,以至于出現大量冗余用例,那么會使程序語句重復執行,會導致定位的精度降低[4]。另外大部分的錯誤語句都會既在失敗執行用例又在成功執行用例中出現,當對程序語句進行并集或者交集操作時[5],錯誤語句往往會被去掉,導致得到的集合為空集或者不包含故障語句[6]。
1.1.2 基于程序切片的故障定位技術
程序切片技術最初是Weiser提出的一種程序分解技術[7],它是根據一些特定需求而截取的程序語句片段集合。我們把程序輸出語句看成興趣點,將輸出結果變量看成興趣變量。根據構成方式,我們可以將程序切片劃分為靜態切片和動態切片兩種。前者是由包含和興趣點相關的興趣變量的所有語句組成,靜態切片大多和整個程序的規模一樣,因此利用靜態切片處理故障定位的效率不高。而動態切片則是在某一具體輸入的前提下包含對興趣點有影響的興趣變量的語句組成,和前者相比,切片規模更小,精度更高,定位效果有所提高。比較典型的基于程序切片的故障定位方法有下面幾種:(1)李必信[8]等人提出了一些基于程序切片的故障定位方法,并且得到了不錯的定位效果。(2)Zhang[9]等人采用基于動態切片的方法實現故障定位技術,主要思路是構造數據切片、全切片以及相關切片3種程序切片,然后在這3種切片基礎上縮小范圍,找到程序的故障位置。基于切片的定位技術優點在于可以簡化程序,將與故障無關的語句排除掉,降低了程序的復雜度,提高定位的效率。但是在大規模的程序中,我們得到的程序切片規模往往也很龐大,導致效率不能達到我們的預期;而且提取切片的過程有時相對比較繁瑣,增加算法的復雜性。
1.1.3 基于程序譜的故障定位技術
程序譜描述的是程序中的語句在執行過程中包含的執行信息與特征,通常用二維數組來表示,程序譜最初是Reps等人[10]在研究千年蟲問題時提出的。基于程序譜的故障定位技術由于其形式簡單、易于操作實現、存儲方便而且可以很清晰直白地將程序中所有語句在測試用例下的覆蓋執行信息以及測試用例的執行結果表現出來,為統計語句的可疑度值提供了便利的條件。由于在單故障定位方面有著較高的效率,很多學者提出了大量基于程序譜的故障定位方法,比較有代表性的有以下幾種方法:(1)虞凱[11]使用多程序譜模型進行軟件故障定位,在單程序譜的基礎上增加了依賴對的頻譜信息,構造兩個程序頻譜分別對應數據依賴和控制依賴對應的頻譜,然后計算語句總的可疑度,以實現定位操作;(2)He在其論文中使用構造層次譜的方法來進行故障定位[12],將整個程序分為函數層和語句層,在不同層次間構造對應的頻譜,然后進行定位;(3)Wong在程序譜的基礎上進一步提出構造語句的交叉表[13],并利用CrossTab方法來統計每條語句的可疑度,利用統計學的思想來完成故障定位操作。
但是基于程序譜的定位方法也存在一定的問題。由于程序譜僅考慮了每條語句的執行情況,并沒有將上下文語句之間包含的依賴關系進行分析,所以有時會出現定位到的結果并不是真正的錯誤語句,而是由于錯誤傳遞而產生非預期運行結果的相關語句。另外程序譜的構造需要大量測試用例,對測試用例的要求也相對較高。
1.1.4 基于模型的故障定位技術
基于模型的定位技術最初是Reiter提出的[14]。他使用了包含(SD,COMPS,OBS)的三元組結構來形式化的定義該方法。其中SD代表對源程序的描述,通常采用一階邏輯語句描述程序內各部分之間的關系及行為;COMPS代表了程序組件的集合;OBS則定位為根據輸入得到的觀測值,是有限一階語句的子集合[15]。Cleve和Zeller提出的Delta Debugging方法[16]首先通過調試環境獲取不同測試用例執行過程中的數據;在此基礎上,構建各個測試用例執行過程中的程序狀態圖;接下來采用圖挖掘算法識別成功和失敗測試用例的程序狀態圖之間的差異;最后通過這些差異進行故障定位。DeMillo[17]提出了一種用于調試的軟件故障分析模型。該方法在模型中定義了錯誤模式和錯誤類型,主要的思路是在程序運行過程中發現異常行為,就會根據對應的模式進行分類。根據已建立的故障模型的參考,就可以定位到程序中的故障位置。
該類方法通過代碼結構和上下文依賴關系構造故障模型,對程序的動態信息利用的比較充分,定位效果較高[18]。但是該方法也有一定的缺陷,首先建立故障模型需要大量的數學知識,同時模型建立以及推導過程也需要很多的時間。
1.2 多故障定位技術
在實際應用中,程序中往往不止包含一處故障,我們在使用針對單故障程序定位技術處理多故障問題時,會出現定位效果下降的問題。因此我們需要對多故障程序定位進行深入的研究是很有意義的。多故障定位技術的大致思想是將程序中的錯誤都“孤立”出來,使不同的錯誤都能夠在測試用例中有所體現,然后基于不同的方法找到暴露錯誤的語句,使這些語句能夠很快的被找到,從而實現多故障定位。很多學者提出不同的改進方法來實現多故障定位的需求。
李博[19]在虞凱提出的多程序譜的基礎上進行改進,使之可以處理多故障程序定位問題,改進的方向是在得到數據依賴和控制依賴譜后,進行計算時對得到的可疑度不是簡單的線性操作,而是先進行預處理后在求出總的可疑度值進行排序定位。而于全江在多故障環境下對程序譜故障定位技術的各個風險評估函數的定位效果進行研究[20],并提出對部分參數進行修改權重的方法來探究最優參數權重,從而實現多故障定位中良好的定位效果。相比于一般的基于程序譜的方法,文萬志在其論文中提出一種基于條件切片譜的方法來實現多故障程序定位技術[21],其定位精度和效果有所提高。除了利用程序譜的方法之外,一些研究人員提出可以結合數據挖掘的思想來解決多故障定位問題,并且取得了一定的進展。張澤林在其論文[22]中提出利用聚類分析的思想來處理測試用例,將不同故障進行隔離,然后分別進行定位。Cao采用基于Chameleon技術來實現軟件多故障定位的要求[23]。該技術先是將測試用例進行約簡,然后在對測試用例進行聚類操作,最后將分離開的所有故障單獨的進行定位。
多故障程序定位的難點在于程序中多個故障之間存在互相干擾疊加的問題,現有的傳統的處理單故障定位技術不能很好的解決這個現象,因此導致定位效果降低。很多學者提出的上述方法的本質目的都是希望和單故障定位一樣,可以單獨的處理每一個錯誤,從而提高多故障定位技術的效率。
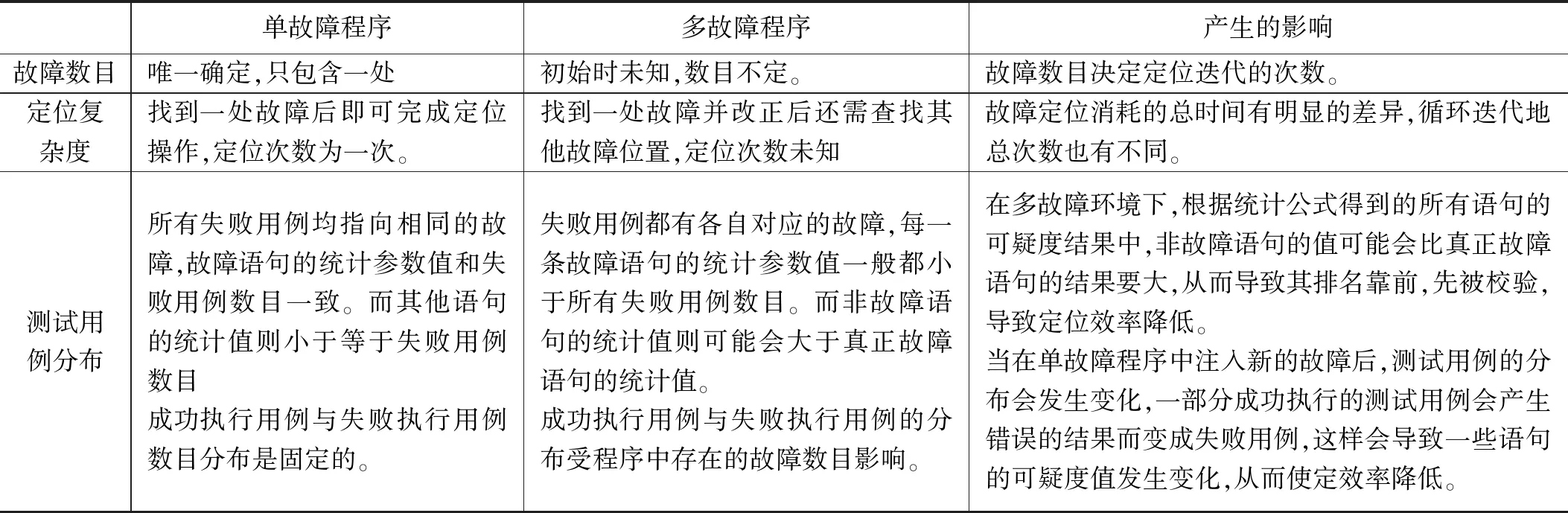
表1 單故障程序與多故障程序區別
1.3 單故障與多故障技術對比
單故障程序定位和多故障程序定位技術的差異在下表1中已經歸納總結出。現階段主要的研究重點集中在單故障程序定位,而后者由于其復雜度要比單故障定位高很多,因此提出的相應的定位技術方法比較少。
總的來說,兩者的差異主要是體現在對測試用例尤其是失敗執行用例的統計處理方面,故障數目的差異因而導致對應的測試用例也隨之不同,而就是這種不同造成在多故障定位中出現互相干擾影響的現象,進而導致定位效率下降,定位開銷增大。
2 測試用例程序集、評價方法
本章主要從以下兩個方面進行論述,首先介紹的是在軟件故障定位技術中使用的評測數據集,其中包含一些故障程序以及相應的測試用例,其中我們主要以Siemens程序集為例進行說明。其次我們論述的是在利用Siemens程序集的基礎上,對使用的故障定位方法給出的測試評價方法的討論,列出了一些常用的測試評價方法。
2.1 測試用例程序集
在當前故障定位技術研究領域中,應用廣泛的程序集是Siemens程序集,該程序集由7個程序組成,程序結構多樣性,通用性強,每個程序的代碼行數不超過600行,主要是基于C語言程序定位,后續加入針對Java、c++等常用語言的程序定位。該程序集是由西門子公司開發的,全部程序集可以從相應的網站中下載[24]。大部分程序中只包含一個故障,每個版本都對應大量測試用例。表2是該程序集的概要信息,其中包含程序名稱、故障版本數、代碼行數、可執行代碼行數以及測試用例數[25]。
表1中Siemens套件包含7個程序,每個程序都有正確源碼和若干帶有故障的源碼,一共有132個故障版本。print_tokens和print_tokens2是一些詞法分析的程序,replace是一些模式轉換的程序,schedule和schedule2是和調度功能相關的程序,tcas實現高度區分功能,tot-info實現信息估量功能。套件中程序的目錄結構都是一致的,具體目錄結構如下:
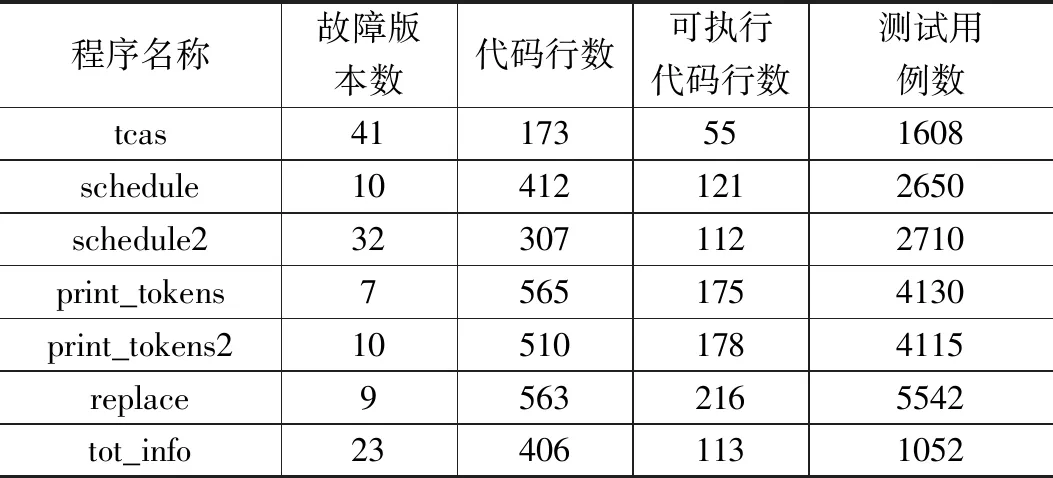
表2 Siemens測試套件概要
(1)source目錄:存放的是程序正確版本的源代碼。
(2)inputs目錄:存放的是輸入數據,但不是所有程序的該文件夾都有內容。
(3)versions目錄:存放的是程序各個故障版本的源代碼。
(4)scripts目錄:存放的是測試腳本,可以運行測試用例,得到的結果存放在對應輸出目錄中。
(5)outputs目錄:存放的是正確版本的輸出結果。
(6)newoutputs目錄:存放的是故障版本的輸出結果。
(7)testplans.alt目錄:存放的是所有的測試套件,其中包含universe文件,該文件包含一個測試用例集合,存放所有測試用例。
2.2 算法評價方法
軟件故障定位技術的目的是盡可能通過自動化過程實現故障的發現,減少測試人員的工作量。軟件定位結果的好壞可以通過發現故障過程需要檢查的語句數量進行評價。需要檢測的語句數越少,說明效果越好。
Jones和Harrold[26]提出了一種度量軟件故障定位有效性和效率的方法,使用發現故障所需要檢查的語句數進行評價。評價標準如公式(1)所示:
(1)
score中各個變量的含義為:|tested_entries|表示找到軟件故障需要檢查的語句數目;|executed_entries|表示執行測試用例中所有可執行語句數目。在定位過程中,不需要檢查的語句數目占所有語句的比例越大,說明定位效果越好。
在一種基于分塊切片的故障定位技術中,采用約減率RR(reduction ratio)來度量分塊切片的約減度[27],其評價方法如公式(2)所示:
(2)
上述公式中,BlockBWSlice代表的是根據興趣塊B和興趣變量集V逆向遍歷系統依賴圖而得到的靜態切片。在定位過程中,BlockBWSlice的規模越小,說明定位效果越好。
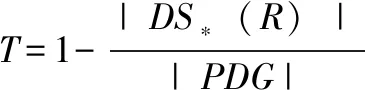
Zhang等人在衡量非參數檢驗的故障定位技術的有效性時,提出了基于謂詞排名的評分標準,也稱P-score[30]。基于謂詞可疑度降序排序給出故障報告,首先標記程序中和故障最接近的謂詞為故障最相關謂詞,然后定義錯誤定位技術的得分為檢查到故障最相關謂詞時,已檢查的謂詞占列表上所有謂詞的百分比[31]。
以上這些衡量故障定位效果的方法大多在單故障程序定位中有著很好的效果,但是在多故障領域,這些衡量標準評價效果一般。因此,Jones在論文[32]提出一種基于其提出的標準基礎上的延伸公式,即:
(3)
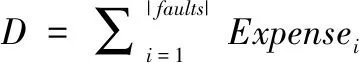
(4)
針對多故障定位的分析,Jones提出了4的評價方法,利用發現并修復軟件中所有故障需要檢查的語句數目占程序所有語句比例的總和來表示算法的效率,但是對于發現并修復軟件的時間成本沒有考慮。Jones在Score的基礎上擴展提出另外一種評價標準公式:
max{Expensef|fisfaultsubtaskatiterationi}
(5)
該標準利用發現并修復所有故障所需要的最小時間成本來表示定位的效率。
一般來說,大多數故障定位技術都是采用Jones提出的score法來評測方法本身的優劣,通過比較再找到所有故障前需要查找的語句數目來評價所使用的定位方法的有效性。而且評價的結果相對準確可靠,對提高定位方法的有效性提供了很大的幫助。
3 對未來研究方向的展望
針對軟件故障定位問題的研究已經取得了一定的進展,研究者提出了不同的方法來實現故障定位。仍然存在一些問題需要進一步研究,未來的工作方向可以從下面幾個角度入手:
1)大多數研究人員關注的重點是單故障程序,待定位的程序中只包含一處錯誤,而實際應用中,程序往往不只有一處故障,而且故障類型也有很大的差異,因此可以將關注點更多地聚焦在對多故障程序定位的研究上,對現有技術進行改進研究,來滿足多故障程序定位的需求。
2)在故障定位的方法中,測試用例的選取也是十分重要,如果測試用例數目太少可能會導致不能覆蓋到所有執行語句;而如果程序中有大量冗余的測試用例,則會導致可執行語句被大量重復執行,會對語句信息統計時造成干擾。因此在后續研究中,可以選擇對測試用例進行優化,以提高故障定位的效率。
3)目前在故障定位領域中,都是以Siemens程序集作為實驗的樣本,并沒有在其他平臺進行實驗,該程序集代碼量相對較小,不能涵蓋所有可能的故障。因此在后續研究中,可以選擇更大的程序集進行實驗研究,對故障種類也可以進行擴展補充。
4 結束語
本文首先分別從單故障和多故障兩個角度綜述了現有的故障定位技術,然后對這兩個方向進行了對比,提出兩者的差異。最后給出了測試用例程序集和算法評價方法,并對故障定位研究方向進行了展望。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年6期)2015-04-17 03:31:50
