基于特征遷移和實例遷移的跨項目缺陷預測方法?
2019-06-11 07:39:44劉望舒黃啟國
軟件學報 2019年5期
倪 超,陳 翔,2,劉望舒,3,顧 慶,黃啟國,李 娜
1(計算機軟件新技術國家重點實驗室(南京大學),江蘇 南京 210023)
2(南通大學 計算機科學與技術學院,江蘇 南通 226019)
3(南京工業大學 計算機科學與技術學院,江蘇 南京 211816)
軟件缺陷產生于開發人員的編碼過程,軟件需求理解不正確、軟件開發過程不合理或開發人員的經驗不足,均有可能引入軟件缺陷.含有缺陷的軟件在部署后可能會產生意料之外的結果或行為,嚴重時會給企業造成巨大的經濟損失,甚至會威脅到人們的生命安全.在軟件項目的開發生命周期中,檢測出內在缺陷的時間越晚,修復該缺陷的代價也越高.尤其在軟件發布后,檢測和修復缺陷的代價將大幅度增加.因此,項目主管借助軟件測試或代碼審查等軟件質量保障手段,希望能夠在軟件部署前盡可能多地檢測出內在缺陷.但是如果關注所有的程序模塊會消耗大量的人力物力,因此,軟件質量保障部門主管希望能夠預先識別出潛在缺陷程序模塊,并隨后對其分配足夠的測試資源.
軟件缺陷預測(software defect prediction,簡稱 SDP)[1-3]是其中一種可行方法,根據軟件歷史開發數據以及已發現的缺陷,借助機器學習等方法來預測出軟件項目內的潛在缺陷程序模塊.目前,大部分研究工作關注項目內的軟件缺陷預測(within-project defect prediction,簡稱WPDP)問題,即基于同一項目的數據完成軟件缺陷預測模型的構建和預測.通常,構建一個性能較好的缺陷預測模型需要大量的訓練實例,但是現實中收集并標注足夠多的訓練數據相當困難:一方面,一些新開發項目只含有較少的訓練數據;另一方面,標記數據需要耗費大量的人力和物力,且這個過程容易出錯.于是,跨項目軟件缺陷預測(cross-project defect prediction,簡稱CPDP)[4-11]問題被研究人員提出,其基于其他項目(即源項目)的歷史數據來構建軟件缺陷預測模型,然后在當前項目(即目標項目)上進行缺陷預測.然而,由于源項目和目標項目之間的數據分布在大部分時候都具有很大的差異性,這導致了在源項目上構建的模型在目標項目上很難具有良好的預測性能.因此,縮小源項目和目標項目之間的數據分布差異性,是設計跨項目缺陷預測方法需要重點考慮的問題.
針對該問題,本文首次同時從特征遷移和實例遷移角度出發,提出了一種兩階段跨項目缺陷預測方法FeCTrA(cross-project software defect prediction using feature clustering and TrAdaBoost).具體來說,在特征遷移階段,該方法借助聚類分析選出源項目與目標項目之間具有高分布相似度的特征;在實例遷移階段,該方法借助TrAdaBoost方法,基于目標項目中的少量已標注實例,從源項目中選出與這些已標注實例分布相近的實例.為了驗證FeCTrA方法的有效性,我們選擇具有代表性的、開源的、真實項目的Relink數據集和AEEEM數據集作為評測對象,以F1作為評測指標.首先,我們發現,FeCTrA方法的預測性能要優于僅考慮特征遷移階段或實例遷移階段的單階段方法;其次,與經典的跨項目缺陷預測方法 TCA+[12]、Peters過濾法[13]、Burak過濾法[14]以及DCPDP法[15]相比,FeCTrA方法的預測性能在 Relink 數據集上可以分別提升 23%、7.2%、9.8%和 38.2%,在AEEEM數據集上可以分別提升96.5%、108.5%、103.6%和107.9%.基于上述分析我們發現,FeCTrA方法不僅可以有效移除冗余特征和無關特征,而且可以從源項目中選出與目標項目分布更為相似的實例.此外,實證研究結果也初步驗證了FeCTrA方法的有效性.
本文的主要貢獻可總結如下.
(1) 提出了基于特征遷移和實例遷移的跨項目軟件缺陷預測方法FeCTrA,該方法可以有效地移除冗余特征和無關特征,并且可以從源項目中選出與目標項目分布相似的實例,從而有效減小源項目和目標項目之間的數據分布差異性;
(2) 在實證研究中考慮了基于實際項目的Relink和AEEEM數據集,深入分析了不同影響因素對FeCTrA方法性能的影響,為更好地使用FeCTrA方法提供了指導性建議;
(3) 通過將FeCTrA方法與Nam等人提出的TCA+[12]、Peters等人提出的Peters過濾法[13]、Turhan等人提出的Burak過濾法[14]以及Zimmermann等人提出的DCPDP法[15]進行比較,發現FeCTrA方法在預測性能上具有顯著優勢,這說明通過融合多種不同類型的遷移學習方法來解決CPDP問題值得關注.
本文第1節介紹軟件缺陷預測的研究背景和相關研究工作.第2節介紹 FeCTrA方法及其具體實現細節.第3節介紹論文的實證研究,包括研究問題、評測對象、評測指標、顯著性檢驗方法、實驗流程及其方法參數設置.第4節對實證研究結果進行詳細分析.最后總結全文,并對下一步研究工作進行展望.
1 研究背景與相關工作
1.1 軟件缺陷預測
軟件缺陷預測[1-3,16-21]是當前軟件工程數據挖掘領域的一個研究熱點[11,22-27].缺陷預測可以在軟件發布之前盡可能多地預測出潛在缺陷程序模塊,以便于合理分配測試資源,從而最終提高軟件質量.其主要包括兩個階段:模型構建階段和模型應用階段.模型構建階段主要包括如下3個步驟.
(1) 挖掘軟件歷史倉庫.目前可供挖掘與分析的軟件歷史倉庫包括項目所處的版本控制系統(例如CVS、SVN、Git)、缺陷跟蹤系統(例如Bugzilla、Mantis、Jira、Trac)或團隊開發人員間相互發送的電子郵件等.程序模塊的粒度根據實際應用場景的需要,可以設置為包、文件、類、函數或代碼修改等.
(2) 程序模塊的度量和標記.通過分析軟件代碼復雜度或開發過程特征,可以設計出與軟件缺陷存在相關性的度量元(metrics)[28].通過這些度量元,可以對程序模塊進行度量;隨后,通過分析缺陷報告可以完成對這些程序模塊的標記.
(3) 模型的構建.基于搜集的缺陷預測數據集,首先進行必要的數據預處理(例如特征選擇、數據取值歸一化、噪音移除等)[22,29-33],隨后可以基于特定的機器學習方法(例如Logisitic回歸、隨機森林、支持向量機等)完成模型的構建.
而在模型應用階段,當面對新的程序模塊時,在完成對該模塊的軟件度量后,基于已構造出的缺陷預測模型和具體度量元取值,可以完成對該模塊的預測,即預測為潛在缺陷模塊或無缺陷模塊.
1.2 跨項目軟件缺陷預測
目前,絕大部分軟件缺陷預測方法基于同一項目上的數據進行模型訓練和模型預測,這類方法被稱為項目內缺陷預測方法,而充足的標記數據是保障這類方法取得良好預測性能的前提.然而,對于剛開發的項目或者歷史遺留項目,可能難以獲取足夠多的標記數據,因此難以構建出具有良好預測性能的模型.針對這種情況,跨項目缺陷預測[5,12,15,34,35]應運而生.跨項目缺陷預測基于其他項目(即源項目)的標記數據進行模型訓練,并在當前項目(即目標項目)上進行缺陷預測.然后,由于源項目和目標項目之間存在較大的數據分布差異性,因此在源項目上訓練的模型在目標項目上未必能夠取得良好的預測性能[15].因此,設計新穎高效的跨項目軟件缺陷預測方法具有一定的研究挑戰性,研究人員針對該問題提出了多種解決方法.
Zimmermann等人[15]首先針對 CPDP的可行性展開了大規模的實證研究,然而研究結果并不樂觀.Turhan等人[14]提出了基于k近鄰的 Burak過濾法.具體而言,該方法首先計算出目標項目中實例與候選源項目中實例之間的歐式距離;然后為目標項目中的每一個未標注實例,從源項目中選出距離其最近的k(k為 10)個實例;最后,將所有從源項目中選出的實例構成訓練集.實驗結果表明,Burak過濾法雖然可以提升CPDP的性能,但是仍然低于WPDP方法.不同于Turhan等人從目標項目出發進行實例選擇,Peters等人[13]則認為源項目中的數據包含更多的信息,因此,他們提出了Peters過濾法.具體而言,首先針對源項目中的每個實例,從目標項目中識別出與之距離最近的實例并進行標記;隨后,對于目標項目中已標記的實例,從源項目中選出與之距離最近的實例并添加到最終訓練集中.Ma等人[36]則提出了TNB(transfer naive bayes)方法,他們認為,應該為源項目中與目標項目中實例相似的實例賦予更高的權重.Wang等人[37]則基于深度學習,從模塊代碼中自動學出語義表示.Chen等人[38]提出的方法則考慮從源項目中刪除帶有負面影響的實例.Xia等人[6]提出了兩階段框架Hydra,該框架引入了遺傳算法和集成學習,以獲取源項目和目標項目之間的共有信息.
一些研究人員針對異構CPDP問題展開了深入研究,該問題嘗試在源項目和目標項目間具有不同特征空間的情況下進行跨項目缺陷預測.針對該問題,Turhan等人[14]提出了一種簡單方法,即在構建CPDP模型時僅考慮源項目和目標項目之間共有的特征.顯然,這種方法存在兩點不足:首先,源項目和目標項目之間共有的特征通常較少,甚至有時候沒有;其次,僅考慮共有的特征會遺漏掉大量其他有用的信息.針對上述不足,He等人[39]首先提出了 CPDP-IFS方法.該方法將每一個實例視為向量,并計算其分布特征指標的取值,從而可以將目標項目和源項目中的實例映射到一個潛在空間,該潛在空間由實例的分布特征指標構成,從而確保 CPDP可以在同一個特征空間內進行.Nam等人[40]提出了HDP(heterogeneous defect prediction)方法,該方法包含特征選擇階段和特征映射階段.Jing等人[25]提出了 UMR(unified metric representation)表示,隨后,借助典型相關分析(canonical correlation analysis)來減少源項目和目標項目間的數據分布差異性.
除此之外,一些研究人員考慮使用無監督方法來解決CPDP問題.Zhong等人[41]使用k-means和NeuralGas方法對程序模塊進行聚類分析,然后,他們從每一個簇中選出典型模塊,并將一些統計信息(如特征的均值、最大值、最小值等)提供給專家,最終交由專家完成對簇的標記.Nam和Kim[27]提出了一種自動方法CLA.CLA方法會依據每個特征的中位數統計該實例含有的異常特征數,然后將具有相同異常數的實例劃分到同一個簇中,隨后將高于一定異常特征數的實例標記為有缺陷實例,否則標記為無缺陷實例.在 CLA方法的基礎上,Nam等人又通過特征選擇和實例選擇來移除數據集中噪聲,并提出了 CLAMI方法.Zhang等人[42]借助譜聚類(spectral clustering)方法,基于程序模塊間的連通性完成對數據集的劃分.最近,Yang等人[43]借助代價感知的評測指標進行性能評估時意外地發現,一些簡單的無監督方法比有監督方法可以取的更好的預測性能.隨后,Zhou等人[44]針對無監督方法(即ManualDown和ManualUp方法)展開了更大規模的實證研究.
1.3 遷移學習
近些年來,遷移學習(transfer learning)引起了廣泛的研究和關注[45-51].遷移學習是運用已存在的知識對不同但相關的領域問題進行求解的一種學習方法,該方法放寬了傳統機器學習中兩個基本假設:(1) 用于學習的訓練樣本與新的測試樣本需要滿足獨立同分布的假設;(2) 必須有足夠的已標記樣本才能訓練出一個好的分類模型.該方法旨在遷移已有的知識來解決目標領域中僅有少量有標記樣本數據甚至有時候沒有的學習問題.跨項目軟件缺陷預測可以視為遷移學習在軟件缺陷預測領域中的一個重要應用.
目前,遷移學習方法可以從兩個角度進行分類.基于“遷移什么”角度,已有方法可以細分為4類:基于特征的遷移學習、基于實例的遷移學習、基于參數的遷移學習和基于相關知識的遷移學習.基于“如何遷移”角度,已有方法可以細分為 3類:(1) 歸納式遷移學習:目標領域中有少量標注樣本;(2) 直推式遷移學習:只有源領域中有標簽樣本;(3) 無監督遷移學習:源領域和目標領域都沒有標簽樣本.表1總結了傳統機器學習方法和不同類型的遷移學習方法間的關系.
目前,跨項目缺陷預測主要從“遷移什么”的角度展開研究,其中,“基于特征的遷移學習”和“基于實例的遷移學習”是研究人員關注較多的方法,這也是我們主要考慮的角度.基于特征遷移學習的方法嘗試尋找在源領域和目標領域之間具有相同或者相似性質的特征,從而達到從源領域將知識遷移到目標領域.一些跨項目缺陷預測法方法[7,8,12,14,25,39,40]從這個角度展開研究.而基于實例的遷移學習方法則根據目標領域中數據的部分知識從源領域中挑選有價值的實例.這類方法通常對源領域中的實例進行選擇或權重設置.一些跨項目缺陷預測方法[6,13,14,36,38]從這個角度展開研究.但上述研究工作僅從單一角度將源項目中的信息遷移到目標項目中.本文將基于特征的遷移學習和基于實例的遷移學習相結合,提出了基于直推式遷移學習方式的FeCTrA方法.

Table 1 Relationship between traditional machine learning methods and different types of transfer learning methods表1 傳統機器學習方法和不同類別遷移學習方法的關系
2 基于特征遷移和實例遷移的缺陷預測方法FeCTrA
本節首先介紹基于特征遷移和實例遷移的跨項目預測方法FeCTrA的研究動機,然后對FeCTrA方法的整體框架進行描述,最后對框架內的特征間相關性和特征分布相似性的度量方法進行介紹.
2.1 研究動機
軟件缺陷預測基于項目的歷史數據構建模型,然后對新的軟件模塊進行缺陷預測.但在實際軟件開發過程中,新開發的項目可能沒有充足的訓練數據,或者一些遺留項目因為特殊原因而無法獲得足夠多的訓練數據.因此,構建一個具有良好性能的缺陷預測模型變得異常困難.于是,遷移學習被引入到軟件缺陷預測研究中,借助源項目中的歷史標記數據以解決目標項目訓練實例過少的問題.然而,由于源項目和目標項目之間存在較大的數據分布差異,使得在源項目數據上構建的缺陷預測模型并不能保證在目標項目上取得良好的預測性能.一方面,從特征角度而言,源項目中并不是所有的特征都與目標項目具有相似的分布,只有分布相似的特征才能輔助目標項目構建性能良好的缺陷預測模型;另一方面,從實例角度而言,源項目數據和目標項目數據本身源于不同的項目,因此通常情況下,源項目中的數據與目標項目數據的分布具有差異性.針對該問題,研究人員分別從特征遷移或者實例遷移的角度展開研究[6-8,12-14,36,38],并取得了一定成果,這充分證明了從特征遷移和實例遷移角度嘗試縮小源項目與目標項目之間數據分布差異性的可行性.然而,目前取得的效果并不令人十分滿意.為此,我們提出了兩階段跨項目缺陷預測方法FeCTrA,該方法通過同時考慮特征遷移和實例遷移,旨在縮小兩個項目的數據分布差異性.在特征遷移階段中,通過聚類分析,可以識別并移除無關特征和冗余特征;在實例遷移階段中,依據目標項目中僅有的少量標記數據,借助 TrAdaBoost方法[47],從源項目中選出與目標項目數據分布更相近的實例,從而解決訓練數據不足的問題.
2.2 方法框架
FeCTrA方法的框架如圖1所示,該方法包含兩個階段:特征遷移階段和實例遷移階段.
· 在特征遷移階段,為了能夠遷移有效的特征信息,FeCTrA方法首先移除源項目數據中的類標信息,然后將源項目和目標項目數據進行合并;隨后,對合并后的數據集基于特征進行聚類分析,從而把高度相關的特征聚集到同一個簇中;然后計算每一個特征在源項目數據和目標項目數據之間分布的相似性,以此作為排序依據,并對每一個簇中的特征進行降序排列;最后,從每一個簇中選取排名靠前的特征作為最終需要遷移的特征.
· 在實例遷移階段,刪除源項目和目標項目中不必要的特征,僅保留特征遷移階段選出的特征和源項目的類標特征;然后,利用TrAdaBoost方法[47],從源項目中選出與目標項目分布相似的數據來構建訓練數據集,并通過 Boost方法不斷迭代,增強基分類器的分類能力,得到若干基分類器,從而構成一個基于集成學習方式的跨項目缺陷預測模型.

Fig.1 Cross-project software defect prediction framework based on feature transfer and instance transfer圖1 基于特征遷移和實例遷移的跨項目軟件缺陷預測框架
2.2.1 特征遷移階段
為了更好地描述該階段,首先給出兩個定義:
定義1(特征間相關性(inter-feature correlation,簡稱IFC)).IFC(fi,fj)表示特征fi和特征fj之間的相關性,其中,i和j不相同.
IFC(fi,fj)的取值范圍是[0,1].IFC(fi,fj)取值越高,表明fi和fj之間的相關性越高.其中,當IFC(fi,fj)=0時,表明特征fi和特征fj之間完全獨立;當IFC(fi,fj)=1時,表明特征fi和特征fj之間完全相關.本文中使用的特征間相關性度量方法如第2.2.3節所述.
定義2(特征分布相似性(similarity of feature distribution,簡稱SFD)).SFD(fi)表明特征fi在源項目和目標項目上分布的相似性.
SFD(fi)的取值范圍是[0,+∞).SFD(fi)取值越大,表明該特征在兩個數據集上分布越相似.顯然,SFD(fi)取值越大越好.其中,SFD(fi)=0表明該特征在兩個數據集上分布完全不相似.本文中使用的特征分布相似性度量方法如第2.2.4節所述.
算法1中給出了特征遷移階段的詳細描述.該算法是對K-medoids算法的擴展,主要目標是找出K個最具有代表性的特征,這K個特征能夠使得各個簇之間的距離最大化并且簇內特征之間的距離最小化.在算法1中,其輸入是源項目數據S、目標項目數據T、需要選出的特征數m以及簇的個數k.算法的輸出是最終需要遷移的特征集合FS.
算法1.Feature Transfer Phase.


在算法1中,首先移除源項目和目標項目數據中的類標特征(第1行).然后,將過濾掉類標特征的源項目數據和目標項目數據進行合并,形成一個完整的數據集(第2行).隨后計算任意兩個不同特征之間的相關性IFC(fi,fj)以及同一個特征在兩個項目之間的分布相似性SFD(fi)(第3行、第4行).計算完這兩項指標之后,執行特征聚類、特征排序和特征選擇過程.在特征聚類過程中(第5行),IFC(fi,fj)指標被用來完成特征聚類,特征聚類的目的就是將初始的特征集合分配到k個簇中.在這些簇中,每一個簇里的任意兩個特征fi和fj(i≠j)都是高度相關的,但是兩個不同簇之間的特征相關度卻很低.整個聚類過程如下:首先,SFD(fi)指標將被用于完成k個簇中心的初始化.在此過程中,為了避免選擇不相關的特征作為初始化階段中的簇中心并提高聚類過程的收斂速度,我們首先選擇在源項目和目標項目中分布相似度最高的前k個特征,然后根據特征與這k個簇中心之間的相關度,依次指派每一個特征到與之相關度最高的簇中,直至所有特征都屬于一個特定的簇.接著重新計算各個簇的中心,按照相同的操作過程更新簇中心并重新指派各個特征到最相關的簇中.重復此過程,直至簇中心不在發生變化為止.在特征排序和特征選擇過程中(第6行、第7行),僅使用SFD(fi)指標完成.在該過程中,對于每一個簇中的所有特征進行排序后,從各個簇中選取特定的特征作為最終需要保留的特征,即最終需要遷移的特征.由于每一個簇的大小不盡相同,因此我們考慮了每一個簇的規模,并根據簇的大小從對應的簇中選出相應比例的特征.也就是說,從含有特征越多的簇中選取越多的特征,反之則越少.因此,將每個簇中特征根據SFD(fi)取值進行降序排序后,從每個簇中選取個特征.其中,m表示最終需要選擇的特征個數,n表示除類標以外的所有特征個數,|Ci|表示某個簇中含有的特征的個數.最后,匯集從所有簇中選擇的特征到FS中(第8行、第9行).
2.2.2 實例遷移階段
在實例遷移階段,FeCTrA方法使用 TrAdaBoost[47]來完成,即從源項目數據中挑選實例,以便有足夠多的數據用于構建在目標項目上具有良好預測性能的模型.TrAdaBoost嘗試從源項目中選出與目標項目中已經標注實例分布相近的實例,從而完成實例的遷移.TrAdaBoost是對Adaboost的一個改進,它是一個用于對源項目中的訓練實例設置權重的框架,與目標項目中實例分布相近的實例會被賦予更高的權重,反之則更小,從而可以在源項目中找到與目標項目中實例分布相似的數據.
算法2中給出了實例遷移的詳細描述.算法的輸入是經過特征遷移過濾后的源項目數據FSource、經過特征遷移過濾后的目標項目數據FTarget、基分類器Learner以及最大迭代次數N.算法的輸出是含有多個分類器的集成預測模型.
在算法2中,主要借助TrAdaBoost完成實例的遷移.TrAdaBoost需要使用目標項目中少量的標記實例,為了操作和表述方便,將經過特征過濾后的FSource記為Td,經過特征過濾后的FTargetlabeled記為Ts,經過特征過濾后的Ftargetunlabeled為S(第1行).其中,|Td|=n并且|Ts|=m.然后,為每一個已經標注的實例賦予初始權重(第2行).隨后進入TrAdaBoost的循環階段(第3行~第10行).在循環內部,設當前迭代的輪次為t,首先對Td和Ts中實例的權重wt做歸一化操作(第4行).其次,在Td和Ts數據上,調用分類器Learner構建一個分類假設ht(第5行).然后,用當前得到的分類假設去預測目標項目中已經標注的實例Ts,并計算預測錯誤率(第6行、第7行).當用得到的分類假設ht去預測實例Ts時,如果實例被預測正確的話,這意味著這個實例和目標項目中的實例具有相同的分布,否則表明它們有不同的分布.隨后,在 TrAdaboost中,根據錯誤率來更新調整訓練實例權重的因子(第 8行).最后,分別更新源項目數據和目標項目數據中已標注的實例的權重.這個方式可以減小分類錯誤的實例對訓練模型的影響,從而可以構建一個具有良好性能的跨項目缺陷預測模型.重復此過程N次,可以得到多個分類假設并進行集成.因此,該模型充分利用了所有基分類器的分類能力來對未知的實例進行預測(第11行).
算法2.Instance Transfer Phase.

2.2.3 特征之間相關性的度量方法
特征相關性度量是用來度量兩個特征fi和fj之間的關聯性.定義1中的IFC(fi,fj)是用于衡量兩個特征之間的關聯性.已有研究[52]表明,特征之間并不一定滿足線性關系.因此,使用非線性的度量方法來衡量兩個特征之間的關系更加合理.對稱不確定性(symmetric uncertainty,簡稱SU)是非線性度量中的一種典型的方法[53],本文在實驗中使用SU來計算兩個特征之間的關聯性的,即IFC(fi,fj)=SU(fi,fj).值得注意的是,本文提出的框架適用于可以計算兩個特征之間相關性的任何方法,因此具有可擴展性.
SU借助信息論中的熵,通過計算特征fi和fj之間的分布差異性來衡量彼此之間的關聯性.通過計算特征fi和fj的互信息,然后進行歸一化,可得到SU.計算公式如下所示:

其中,
(1)H(fi)表示特征的不確定度(即熵),其定義如下:

p(fi′)表示特征fi取一個特定值的先驗概率.
(2)IG(fi|fj)表示信息增益率.表示在給定特征fj的情況下,特征fi減少的量.其計算公式如下所示:

H(fi|fj)表示特征fj確定的情況下,特征fi的熵.其計算公式如下:
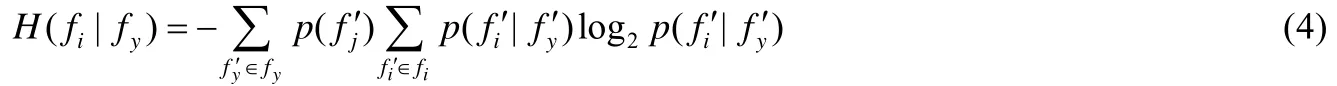
p(fj′)表示fj取一個特定值的先驗概率.由上述公式可知,信息增益率具有對稱性,即兩個特征在公式中出現的順序不會影響它們之間的信息增益率的計算結果.
2.2.4 特征之間分布相似性的度量方法
特征分布的相似性是用來度量一個具體的特征fi在兩個不同的數據集上的分布的相似性程度.定義2中的SFD(fi)用于衡量一個具體特征在源項目和目標項目數據集上的分布相似度.我們使用 K-S(Kolmogorov-Smirnov)檢驗來驗證兩組數據分布是否相似.這兩組數據是指兩個不同的數據集上相同特征對應的數據.K-S檢驗是一種非參檢驗,主要通過計算兩組數據之間是否具有顯著的差異來反映特征分布的相似度.在本方法中,我們將 K-S檢驗出來沒有顯著差異的情況定義為某特征在源項目和目標項目數據上分布相似程度.值得注意的是,本文提出的框架適用于可以計算一個具體特征在兩組數據上分布相似性的任何方法,因此具有可擴展性.
K-S檢驗是一種擬合度檢驗,用來判斷樣本的實際分布值與指定理論的分布是否吻合.當然,K-S也可以用來檢測兩個樣本分布是否具有顯著差異,也就是說兩樣本的分布是否相同.該方法通過兩個樣本的累計頻次數分布是否相當接近來判斷原假設H0是否為真.假如兩個樣本間的累計概率具有較大的分布差異,那么可以肯定兩個樣本取自不同的總體,則拒絕H0.
K-S檢驗首先提出兩個假設:H0:S1(x)=S2(x),H1:S1(x)≠S2(x).如果令S1(x),S2(x)分別表示第1個和第2個樣本觀察值的累計概率分布函數,那么得到K-S兩個樣本的雙尾檢測統計量為D=max|S1(x)-S2(x)|.如果對于每一對樣本值,S1(x)和S2(x)都能十分接近的話,則表明兩個分數的擬合程度很高,則有理由認為兩個樣本數據來自于相同的分布函數.這里,通常將顯著性水平p-value設置為0.05.因此,當計算出來的值大于0.05時則接受原假設H0,否則拒絕.
3 實驗設計
本節將對FeCTra方法的有效性展開實證研究,首先提出研究問題,從不同角度來探討FeCTrA方法在各類場景下的性能優劣,然后介紹實證研究中使用的數據集、性能評測指標和顯著性檢驗方法,最后介紹實驗流程及其方法參數設定.
3.1 研究問題
FeCTrA方法的目的是在目標項目內沒有足夠多訓練數據的前提下完成缺陷預測的任務.FeCTrA方法從分布的差異性入手,結合特征遷移和實例遷移來構造出對目標項目有用的訓練數據.一方面,特征遷移主要從源項目中選擇與目標項目中分布相似的特征,從特征角度降低分布差異較大對數據集質量的影響;另一方面,實例遷移主要使用TrAdaBoost方法,嘗試從源項目中選出與目標項目數據服從相似分布的實例,從實例角度降低分布差異較大對數據集質量的影響.為了驗證FeCTrA方法的有效性,本文提出如下4個研究問題.
· RQ1:FeCTrA方法是否優于已有的經典的跨項目缺陷預測方法?
目前,研究人員針對跨項目缺陷預測問題已經提出了多種方法,我們重點考慮TCA+[12]、Peters過濾法[13]、Burak過濾法[14]和Zimmermann等人[15]提出的方法.除此之外,我們還同時考慮了僅基于特征遷移的FeCTrA方法和僅基于實例遷移的FeCTrA方法.在FeCTrA方法中會存在很多影響因素,例如特征遷移階段的特征選擇比例、實例遷移階段的目標項目中標記實例比例以及方法考慮的分類器.在該研究問題中,我們基于RQ2到RQ4的分析結果,為這些影響因素設置最優取值.
· RQ2:在FeCTrA方法的特征遷移階段,特征選擇比例對FeCTrA方法的性能影響如何?
在特征遷移階段,FeCTrA方法嘗試通過聚類分析,從源項目中遷移與目標項目分布相似的特征.因此在該RQ中,我們想分析不同的特征選擇比例是否會對FeCTrA方法的性能產生影響.
· RQ3:在FeCTrA方法的實例遷移階段,目標項目中標記實例比例對FeCTrA方法的性能影響如何?
在實例遷移階段,FeCTrA方法需要使用少量目標項目中已經標注的實例.因此在該RQ中,我們想分析使用不同目標項目中的標記實例比例是否會對FeCTrA方法的性能產生影響.
· RQ4:使用不同的分類器對FeCTrA方法的性能影響如何?
FeCTrA方法內部需要提供分類器以完成預測模型的構建.在軟件缺陷預測領域中,被廣泛使用的分類器主要包括如下類型:基于概率的分類器、基于決策樹的分類器、基于函數式的分類器以及基于集成學習的分類器等.不同類型的分類器在不同數據集上的預測性能并不相同.因此,我們想分析不同類型的分類器是否會對FeCTrA方法的性能產生影響.
3.2 評測對象
在我們的實證研究中,使用了在軟件缺陷預測領域中被研究人員廣泛使用的數據集(即 Relink數據集和AEEEM數據集)[12,54-56].表2和表3列出了這兩個數據集的統計特征.

Table 2 Statistical characteristics of Relink datasets表2 Relink數據集的統計特征

Table 3 Statistical characteristics of AEEEM datasets表3 AEEEM數據集的統計特征
Relink數據集是由 Wu等人[56]搜集整理的,并且借助手工方式對數據集中的缺陷信息進行了確認.他們使用Understand工具(https://scitools.com)分析3個項目(例如Apache、Safe和ZXing),從源代碼中抽取出重要的軟件特征指標.Relink數據集有26個復雜度特征,這些特征主要基于代碼的復雜度和抽象語法樹,總體可以分為兩個大類:基于程序復雜度的特征和基于數量的特征.表4僅僅列舉了這26個特征中的7個特征并對其含義進行描述.Understand網站可以查詢到每個特征的具體含義.
AEEEM數據集是由D’Ambros等人搜集整理[57].AEEEM中的每一個項目都包含61個特征,其中,17個屬于與源代碼相關的特征,5個屬于與之前預測相關的特征,5個屬于與代碼變更熵相關的特征,17個屬于與源代碼熵相關的特征以及17個屬于與源代碼衰退相關的特征.更具體地說,AEEEM數據集包含線性衰減熵(LDHH)和權值衰退(WCHU).LDHH和WCHU已經被證實了對于缺陷預測是非常有用的.表5僅僅列出了AEEEM中的部分特征及其具體含義.

Table 4 Description of some feactures in Relink dataset表4 Relink數據集中部分特征的描述

Table 5 Description of some feactures in AEEEM dataset表5 AEEEM數據集中部分特征的描述
本文僅考慮同構類型的跨項目缺陷預測問題,即源項目和目標項目考慮了相同的特征集合.因此,FeCTrA方法僅在同一個數據集內部的項目間進行跨項目預測研究.例如在 Relink數據集中,FeCTrA方法可以使用Apache作為源項目,使用Safe或者ZXing作為目標項目,即Apache→Safe或者Apache→ZXing.但是對于Relink數據集中任一項目做源項目,AEEEM數據集中任意一項目的做目標項目這種情況,FeCTrA方法無法處理.例如,以Apache為例,Apache→{EQ,JDT,LC,ML,PDE}在FeCTrA方法中是不支持的.
3.3 評測指標
對于目標項目中任一實例經缺陷預測模型后會有 4種可能的輸出結果:當一個含有缺陷的實例被預測為有缺陷實例,記為TP(true positive);當一個不含有缺陷的實例被預測為有缺陷實例,記為FP(false positive);當一個含有缺陷的實例被預測為無缺陷的實例,記為 FN(false negative);當一個不含有缺陷的實例被預測為無缺陷的實例,記為 TN(true negative).基于以上這些可能的輸出結果,可以定義查準率(precision)、查全率(recall)以及F1度量(F1-measure).
· 查準率:在所有被預測為有缺陷的實例中,真正含有缺陷的實例所占的比例.

· 查全率:在所有真正含有缺陷的實例中,被正確預測為有預測的實例所占的比例.

·F1度量又稱為F1-Score,是綜合考慮查準率和查全率兩個指標的指標,其定義如下.

通常,在查準率和查全率之間有一個折中,一般來說,查準率高時,查全率往往偏低;而查全率高時,查準率往往偏低.然而,折中的方案很難與僅使用查準率或者查全率作為評價指標的預測模型進行比較.而F1是通過查準率和查全率的調和平均數計算而來,其綜合考量各方法在查全率和查準率上的整體性能表現,可以全面地反映方法實際性能的優劣.鑒于此,本文使用F1評價各方法的性能.
3.4 顯著性檢驗方法和反向差異的排名.
3.5 假設兩個分類器在特定的實驗方案下產
為了檢驗不同方法之間的性能差異是否顯著,本文考慮了被廣泛使用的Wilcoxon符號秩檢驗[58].該檢驗是無參的統計假設檢驗,也是t-檢驗的替代方案,其核心是忽略數據的符號,對兩個不同分類器在每一個數據集上取得的性能結果之間的差異進行排序,同時比較正向差異生了N組實驗數據,以di表示這兩個分類器在第i組數據上的性能差異,這N組差異將會根據差異的絕對值進行排序.如果兩者無差異,即di=0,則將它們兩者差異排名的平均值作為它們各自的排名.使用R+表明第2種算法優于第1種算法對應數據的排名總和,那么R-表示第2種算法劣于第1種算法對應數據的排名總和.當di=0時,則取所有di為0的數據對應的排名之和的一半.如果它們的個數是奇數,那么其中一個數據將會被忽略掉.R+,R-的定義如下.
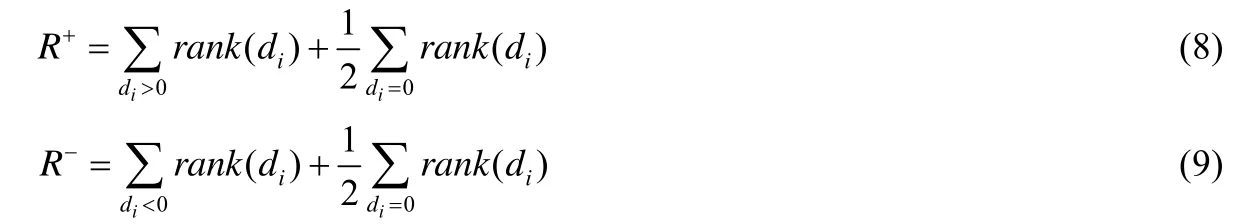
記T為R+,R-這兩者的最小值,即T=min(R+,R-).對于數據量大于25的數據集,下面的統計公式表示分布是接近于正態分布的.

當給定的顯著因子α=0.05時,如果z<-1.96,則空假設將被拒絕,即表明被比較的兩個分類器的性能是存在顯著差異的.關于Wilcoxon的更加詳細的描述,可參考文獻[58,59].
為了進一步比較兩種方法之間的性能,我們使用“Win/Draw/Loss”分析.在特定評價指標上,“方法 1vs方法2”的“Win/Draw/Loss”結果分析共有3種情況,即“方法1”的性能顯著好于、相似或者顯著差于“方法 2”的性能的次數.
3.6 實驗流程及其方法參數設定
為了評價 FeCTrA方法在跨項目缺陷預測中的性能,我們比較了 6種經典的跨項目軟件缺陷預測方法:(1) 只包含特征遷移階段的 FeCTrA 方法,記為 FeCTrA(FT);(2) 只包含實例遷移階段的 FeCTrA 方法,記為FeCTrA(IT);(3) Nam等人[12]提出的TCA+方法;(4) Peters等人[13]提出的Peters過濾法;(5) Turhan等人[14]提出的Burak過濾法;(6) Zimmermann等人[15]提出的方法,為了后續描述的方便,將其記為DCPDP(directly cross-project defect prediction)方法.
FeCTrA方法主要包括特征遷移和實例遷移兩個階段.在特征遷移階段,需要對特征進行聚類.而簇的個數和選擇的特征個數會對預測性能產生重要影響.已有的研究工作[60,61]表明,比較理想的簇的個數為,其中,M表示原始特征的個數.缺省情況下,遷移的特征個數為 40%×M.在實例遷移階段,需要目標項目中提供部分已標記的數據.缺省情況下,FeCTrA方法從目標項目中選出 10%的實例作為已經標注的實例.除此之外,TrAdaboost是一個不斷迭代的過程.研究表明[47],100次迭代可以使得模型的性能收斂.因此,FeCTrA方法將實例遷移階段的迭代次數設置為100.為了減少隨機性對實驗結果造成的影響,本文重復執行FeCTrA方法100次,并取均值作為最終結果.此外,當計算兩個特征的分布相似度時,本文使用R語言提供的K-S檢驗.
TCA+方法是對 TCA方法的一個擴展,主要包含兩個階段:正規化方法自動選擇階段和 TCA應用階段.DCPDP方法直接在源項目上構建缺陷預測模型,然后在目標項目上進行預測.Peters過濾法和Burak過濾法都是經典的基于實例遷移的跨項目缺陷預測方法.此外,在分類器的選擇上,本文使用軟件缺陷預測領域中被廣泛使用的Naive Bayes[7,60,62]作為默認分類器.FeCTrA方法和所有基準方法均基于weka軟件包編程實現.
在跨項目缺陷預測的實驗中,采取“一對一”的方式,即每次只選擇 1個項目作為源項目,選擇另一個項目作為目標項目.以Relink數據集中的Apache項目為例,其對應的源項目可以是Safe,或者是ZXing,但并不允許是兩個項目的融合.此外,對于 FeCTrA方法,需要同時使用源項目數據和目標項目中少量已經標注的數據作為訓練集.本文采用反轉的十折交叉檢驗處理方式.對于某一折劃分,采用如下的處理方法:使用源項目的所有標記數據和目標項目中一折(即 10%)已標記數據作為最終的訓練集,然后,在此數據集上構建一個跨項目的缺陷預測模型,最后對目標項目中未標記的九折(即 90%)數據進行預測.依次與目標項目中每一折數據結合構建訓練集,預測剩下的九折,從而得到十次結果.重復該過程10次,即可得到100次實驗結果.此外,為了確保所有項目的在相同的測試集上進行性能的公平評估,對于其他基準方法采取了相同的反轉十折處理方法.但是不同于FeCTrA方法,基準方法構建的訓練集并不包含目標項目中少量的標記數據(缺省10%),直接在把源項目數據作為其總體訓練集,然后預測目標項目中的未標記數據(缺省90%).
本文實驗在以下配置的臺式機上運行:操作系統:Windows 7,64位;CPU:Intel(R) Core(TM) i5-4590CPU@3.30GHz×2;內存:16G.
4 實證研究結果的分析
4.1 針對RQ1的結果分析
本文在 Relink數據集和 AEEEM 數據集上分別對 FeCTrA方法的整體性能進行了實證研究,使用 Na?ve Bayes作為基分類器,遷移的特征比例為 40%,選擇目標項目中標注的實例比例為 10%,并將 FeCTrA方法與 6種基準方法進行了比較.表6和表7分別給出了這些方法在兩個數據集上取得的F1均值.

Table 6 Comparison ofF1 among FeCTrA and six baseline methods on Relink表6 基于F1評價指標,FeCTrA與6種基準方法在Relink數據集上的平均性能比較
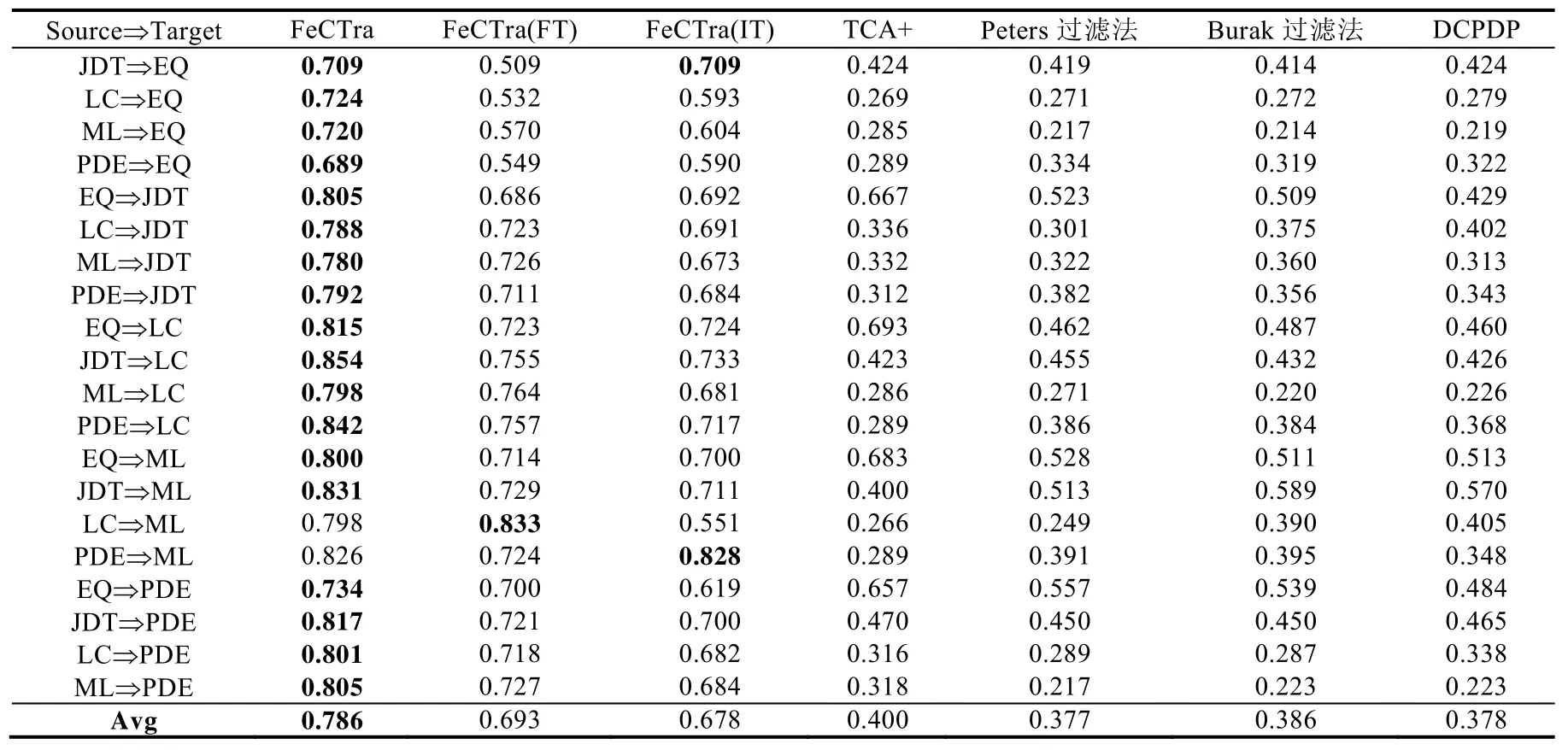
Table 7 Comparison ofF1 among FeCTrA and six baseline methods on AEEEM表7 基于F1評價指標,FeCTrA與6種基準方法在AEEEM數據集上的平均性能比較
在表6和表7中,第1列表示跨項目缺陷預測的具體場景,比如在表7中,JDT?EQ表示使用JDT作為源項目,EQ作為目標項目.接下來的3列表示本文提出的FeCTrA方法,由于FeCTrA方法包含兩個階段,因此我們使用FeCTrA,FeCTrA(FT)和FeCTrA(IT)分別表示同時使用特征遷移和實例遷移、僅使用特征遷移和僅使用實例遷移.最后 4列表示跨項目缺陷預測研究中已有的經典基準方法,即 TCA+、Peters過濾法、Burak過濾法和DCPDP.兩個表格的最后一行給出了每一種方法的整體平均性能.表格中每一行的最大值進行加粗表示.
從兩個表格的最后一行可以看出,基于Relink和AEEEM兩個數據集,與基準方法相比,本文提出的FeCTrA方法能夠取得更好的預測性能.
與FeCTrA(FT)方法和FeCTrA(IT)方法相比,FeCTrA方法在絕大部分的跨項目缺陷預測場景中都能取得更好的預測性能.例如,對于Relink數據集上的Safe?Apache,FeCTrA方法取得的F1均值為0.672,而FeCTrA(FT)方法和FeCTrA(IT)方法分別獲得了0.646和0.583,因此,FeCTrA方法與這兩種方法相比,其性能提升分別為4%和 15.3%.對于 AEEEM 數據集上的 LC?EQ,FeCTrA 方法取得的F1均值為 0.724,相對于 FeCTrA(FT)方法(0.532)和 FeCTrA(IT)方法(0.593),其性能提升分別為 36.1%和 22.1%.實驗結果表明,在跨項目缺陷預測中,將特征遷移和實例遷移進行結合,與僅考慮單個階段的方法相比,其能夠獲得更好的預測性能.
與 TCA+方法相比,在兩個數據集上,FeCTrA方法的性能要好于 TCA+方法.TCA+方法借助特征映射完成特征遷移,這與FeCTrA方法的第1階段比較相似,即與FeCTrA(FT)方法相類似.從實驗結果可以看出,絕大部分情況下,本文提出的特征遷移方法 FeCTrA(FT)要好于 TCA+方法.例如,在 Relink和 AEEEM 數據集上,FeCTrA(FT)方法分別獲得了0.630和0.693的性能,而TCA+方法僅獲得了0.518和0.400.這充分體現了在跨項目缺陷預測中特征遷移階段的重要性,有利于排除無關特征對實驗結果產生的影響.此外,相對于 TCA+方法,FeCTrA(FT)方法的性能更為穩定.例如在 Apapche?Safe場景中,TCA+方法能夠獲得令人滿意的性能(即0.727),而在LC?ML場景中,TCA+方法則難以獲得令人滿意的性能(僅0.266).因此在不同的場景下,TCA+方法的性能波動較大.
與Peters過濾法和Burak過濾法相比,在AEEEM數據集上,FeCTrA方法在所有的跨項目缺陷預測場景中都取得了最好的性能.而在 Relink數據集上,Peters過濾法和 Burak過濾法在部分場景下表現較好,如 Safe?Apache,Apache?Safe和Safe?ZXing這3個場景上.其可能原因如下:在Relink數據集上,各個項目的實例普遍偏少,而FeCTrA方法僅僅借助了目標項目中10%的實例,因此可用的信息較少;而Peters過濾法和Burak過濾法選出的實例較多,因此包含的信息也更多.但從整理來說,FeCTrA方法相對于 Peters過濾法和 Burak過濾法,其性能分別提高了7.2%和9.8%.
與 DCPDP方法相比,FeCTrA方法在兩個數據集上也幾乎取得更好的預測性能.總體而言,FeCTrA方法在Relink數據集上,其性能提升了38.2%;在AEEEM數據集上,其獲得的性能是DCPDP方法的兩倍.這些結果表明,在跨項目缺陷預測中,直接使用源項目數據中的所有特征和實例并不能保證可以得到更好的預測效果,而移除冗余特征、無關特征以及分布不相似的實例會顯著提升模型的性能.然而在Apache?ZXing場景下,DCPDP能夠獲得更好的預測結果.這可能是因為Apache和Zxing這兩個項目本身分布較為相似,所以DCPDP方法能夠取得更好的性能.
表8列出了FeCTrA方法與6種基準方法之間的Win/Draw/Loss比較結果.表格分為上下兩個部分,分別表示 Relink數據集中的項目和AEEEM數據集中的項目.表中的每一行表示以當前項目作為目標項目,其他的項目為源項目.例如,以EQ為例,則表示將EQ設置為目標項目,由剩下項目(即JDT,LC,ML和PDE)中可以選一個作為源項目.因為AEEEM數據集總共含有5個項目,因此會總共產生20個跨項目缺陷預測場景.從表8中不難看出,在Relink數據集上,FeCTrA方法最低可以取得33.3%(2/6)的勝算,即與Peters過濾法比較;在AEEEM數據集上,FeCTrA方法最低可以取得90%(18/20)的勝算.在大部分數據集上,FeCTrA方法優于僅考慮特征遷移或僅考慮實例遷移的方法.
此外,為了驗證 FeCTrA方法與基準方法間的性能差異是否具有顯著性,本文對實驗結果進行了 Wilcoxon符號秩檢驗,并設置顯著性水平α為0.05,具體結果見表9.基于表9可以發現,“FeCTrA vs FeCTrA(FT)”、“FeCTrA vs FeCTrA(IT)”、“FeCTrA vs TCA+”、“FeCTrA vs Peters過濾法”、“FeCTrA vs Burak 過濾法”和“FeCTrA vs DCPDP”的p值都小于0.05.這表明,基于顯著性分析,FeCTrA方法的預測性能要顯著優于其他6種基準方法.
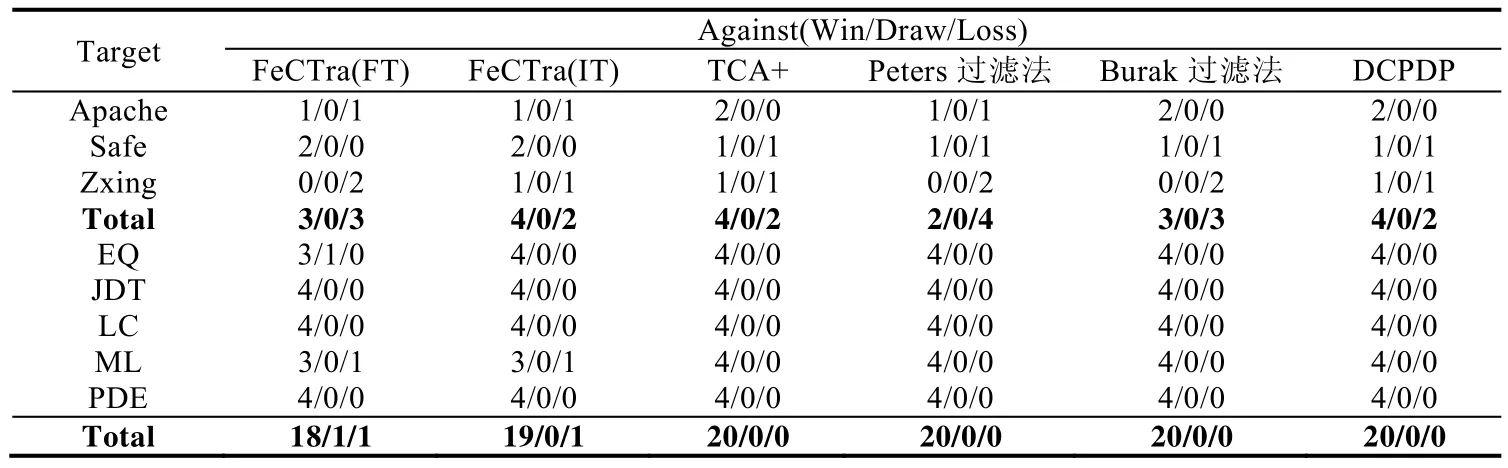
Table 8 Win/Draw/Loss of FeCTrA compared with six baselines on both datasets表8 FeCTrA方法與6種基準方法在兩個數據集上的WIN/DRAW/LOSS比較結果

Table 9 p-value of the wilconxon signed-rank test among baseline methods and FeCTrA表9 FeCTrA和基準方法間的顯著性檢驗結果
基于上述分析,在跨項目缺陷預測中,冗余特征、無關特征以及分布不同的實例均會影響跨項目缺陷預測模型的性能,而本文提出的FeCTrA方法通過同時考慮特征遷移和實例遷移,可以取得更好的預測性能.
4.2 針對RQ2的結果分析
為了分析特征遷移階段中特征選擇比例對FeCTrA方法性能的影響,我們將特征選擇比例從10%逐步增長到 100%,步長設置為 10%.圖2和圖3分別顯示了基于 Relink數據集和 AEEEM 數據集上,特征選擇比例對FeCTrA方法性能的影響.
在圖2和圖3中,x軸表示從源項目中遷移的特征數量占所有特征數量的比例,其取值從 10%逐步增長到100%,y軸表示FeCTrA方法基于該特征選擇比例取得的F1均值.我們對數據折線做了平滑處理.圖中每一條曲線表示一個具體的項目,為了便于區分,使用了不同顏色對曲線進行繪制.
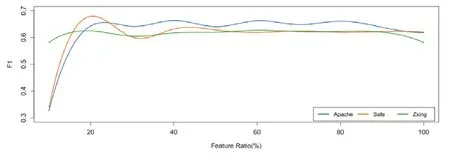
Fig.2 Impact on FeCTra by varying feature transfer ratio on Relink圖2 在Relink數據集上,遷移不同比例的特征對FeCTrA性能的影響
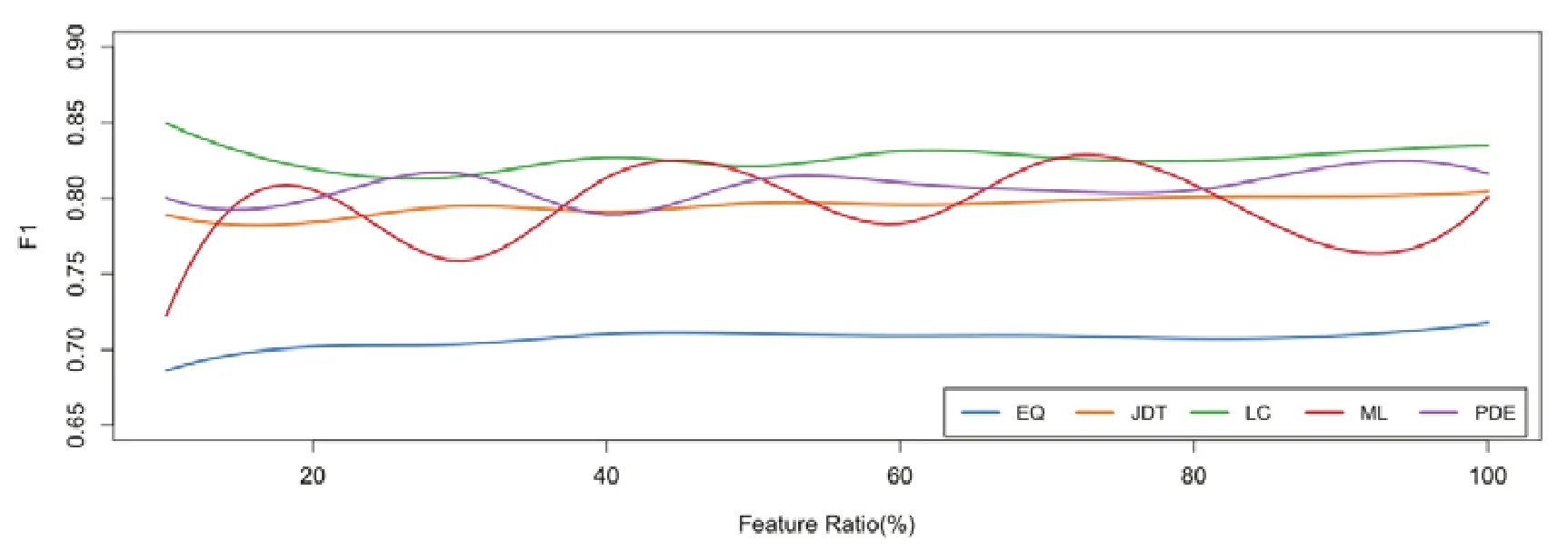
Fig.3 Impact on FeCTra by varying feature transfer ratio on AEEEM圖3 在AEEEM數據集上,遷移不同比例的特征對FeCTrA性能的影響
從圖2中可以發現,當特征選擇比例從10%增長到20%時,FeCTrA在各個項目上取得的預測性能在不斷提高;但是當特征選擇比例從 20%增加到 30%時,FeCTrA方法在各個項目上的預測性能都出現了不同程度的下降,其中在 Safe項目上,性能下降最為嚴重.這可能是由于選出的這些特征在目標項目上并不起到重要作用,而這些特征被挑選中可能僅僅是因為在數據分布上與源項目更接近而已;當特征選擇比例從 30%增加到 40%時,FeCTrA方法在各個項目上的預測性能又開始提升;隨后,當特征選擇比例不斷提高時,FeCTrA方法的預測性能并沒有持續提高,而是趨于穩定;甚至當選擇全部特征時,FeCTrA方法的預測性能反而出現下降.這說明:(1)從源項目中遷移所有的特征,并不能保證在目標項目上具有很好的泛化能力,這可能是冗余特征和無關特征的存在所引起,因此在遷移特征時,識別并移除上述兩類特征很有必要;(2) 遷移40%的特征能夠使得FeCTrA方法在Relink數據集上可以達到較高的預測性能.
從圖3中可以發現,隨著特征選擇比例的變化,FeCTrA在各個項目上的性能表現也在不斷變化.例如在EQ和 JDT項目上,FeCTrA方法的預測性能隨著特征選擇比例的增加而不斷提高,但是提高的幅度不大.這說明在這兩個項目上,當遷移的特征比例為20%~40%時,FeCTrA方法已經能夠挑選出最重要的特征.在LC項目上,當遷移的特征比例為10%時,FeCTrA方法取得的預測性能最高;隨著遷移特征比例的增加,FeCTrA方法開始出現下降,直至遷移的特征比例為40%時,FeCTrA方法的性能才趨于穩定.而對于ML和PDE項目,隨著遷移的特征比例不斷增加,FeCTrA方法的性能出現波動現象.具體來說,在 PDE項目上,FeCTrA方法在遷移的特征比例為30%時首次達到了最優效果,而在遷移的特征比例為 40%以后,其最好性能與最差性能的波動情況趨于穩定;在ML項目上,當遷移的特征比例大于20%時,FeCTrA方法的最好性能與最差性能幾乎保持不變,并且在遷移的特征比例為40%時首次達到最優性能.因此在AEEEM項目上,遷移的特征比例設置為40%是理想的選擇.
基于上述分析,在FeCTrA方法的特征遷移階段,從源項目中遷移40%的特征比較理想.
4.3 針對RQ3的結果分析
為了分析目標項目中標注實例比例對 FeCTrA方法預測性能的影響,本文主要假設目標項目中存在 5%,10%和20%的標注實例.選擇以上3種不同的標注實例比例主要有以下兩個原因.
(1) 標注實例是一個耗時耗力、成本高昂并且容易出錯的工作,但是使用有限的成本去標注少部分的實例是切實可行的,這也是本文研究FeCTrA方法的前提.但在目標項目中,標注的實例不宜過多,本文在實驗中將標注實例的比例上限設置為20%.
(2) 本文在模型性能評估時基于交叉驗證的方式,因此,選擇以上 3種標注實例的比例可以保證更好地進行交叉檢驗(即20折交叉驗證、10折交叉驗證以及5折交叉驗證).
圖4和圖5展示了不同的標注實例比例對FeCTrA方法預測性能的影響.
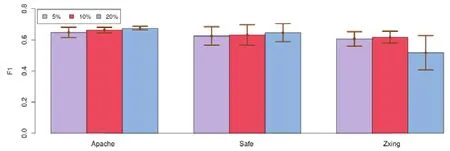
Fig.4 Impact on FeCTrA by varying labeled instance ratio in target project on Relink圖4 在Relink數據集上,目標項目中不同標注實例比例對FeCTrA方法預測性能的影響

Fig.5 Impact on FeCTrA by varying labeled instance ratio in target project on AEEEM圖5 在AEEEM數據集上,目標項目中不同標注實例比例對FeCTrA方法預測性能的影響
在圖4和圖5中,橫軸表示不同的項目,縱軸表示以某一項目為目標項目時,所有跨項目缺陷預測場景下得到的F1性能均值和標準差.為了便于區分,使用不同顏色表示目標項目中不同的標注實例比例.以Apache項目為例,當選擇目標項目中5%的實例作為已標注實例時,Apache可以被等分成20份,即可以執行20折交叉驗證.當選擇目標項目中 20%的實例作為已標注實例時,Apache可以被等分成 5份,即可以執行 5折交叉驗證.因此,每一個實驗結果是基于個數據所獲得.其中,P表示目標項目中標注實例的比例(例如P=5%),M表示可以作為源項目的個數(例如,當Apache為目標項目時,M=2),最后的10表示該交叉檢驗會重復執行10次.
從圖4中可以看出,在Apache和Safe項目上,隨著目標項目中標記數據的增加,FeCTrA方法性能的均值在不斷提高;然后,增加的幅度并不是很大.其原因可能是,在 Relink數據集上,各個項目內含有的實例數目普遍較少.例如,Apache項目僅有194個實例,Safe項目僅有56個實例,ZXing項目僅有399個實例.因此,增加5%~10%的實例比例并不會增加太多的標注信息.所以,FeCTrA在各個項目的性能表現相對穩定.而在 ZXing項目上:當標注實例的比例是10%時,FeCTrA方法獲得了最好的預測性能;當比例增加到20%時,性能反而有所下降.從圖5中可以看出,在JDT、ML和PDE項目上,隨著目標項目中標注實例的增加,FeCTrA方法的性能也逐漸提高.這主要是因為JDT、LC和ML這3個項目里含有的實例數較多.例如,JDT項目含有997個實例,ML項目含有1 862個實例,PDE項目含有1 497實例.因此,隨著標注實例比例的增加,可以被FeCTrA方法利用的實例信息就越多,性能自然越來越高.而EQ項目中含有的實例數較少,因此性能幾乎保持不變.在 LC項目中,當標注實例的比例為10%時,FeCTrA方法獲得了最好的性能;當比例增加到20%時,性能也有所下降.其原因一方面是數據集本身含有的實例較少(僅399個實例),另一方面可能是由于數據集本身質量不高所導致的.
基于上述分析,在FeCTrA方法的實例遷移階段,從目標項目中的選擇10%的標注實例比較理想.
4.4 針對RQ4的結果分析
為了研究不同類型的分類器對 FeCTrA方法的影響,本文考慮了軟件缺陷預測研究經常使用的分類器.其中,J48屬于基于決策樹的分類器,LR(logistic regression)和SVM(support vector machine)屬于基于函數式的分類器,NB(Naive Bayes)屬于基于概率的分類器,RF(random forest)屬于基于集成學習的分類器.圖6和圖7顯示了不同分類器對FeCTrA方法的影響.

Fig.6 Impact on FeCTrA by using different basic classifier on Relink圖6 在Relink數據集上,不同分類器對FeCTrA方法性能的影響
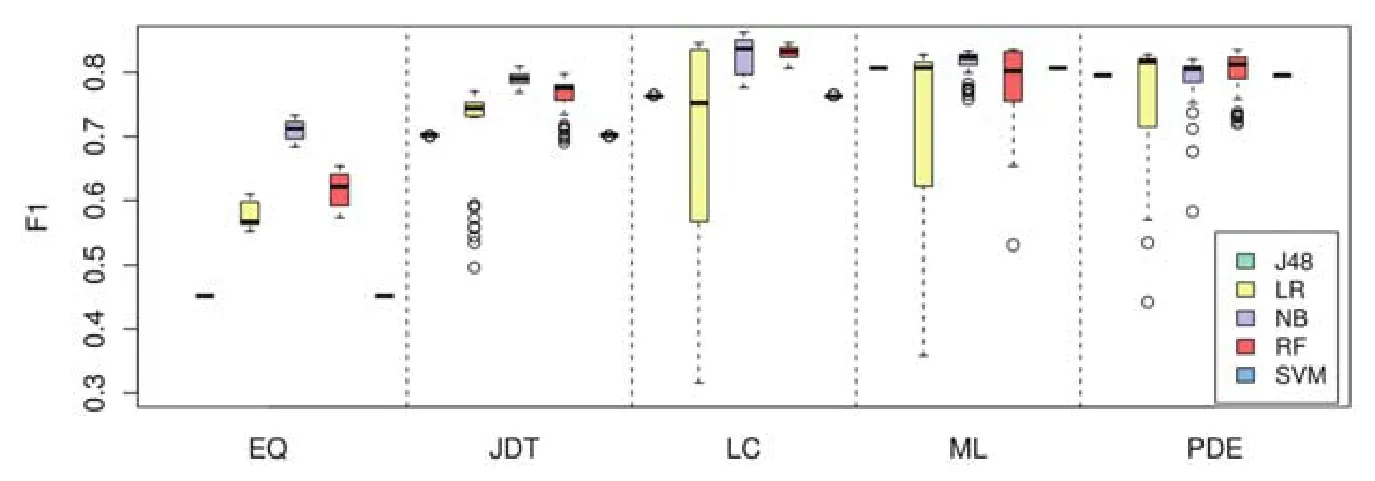
Fig.7 Impact on FeCTrA by using different basic classifier on AEEEM圖7 在AEEEM數據集上,不同分類器對FeCTrA方法性能的影響
在圖6和圖7中,橫軸表示數據集中不同項目的名稱,縱軸表示FeCTrA方法使用不同分類器后得到的F1值.為了便于區分,本文使用不同的顏色填充盒圖以表示不同的分類器.
從圖6中可以看出,在Relink數據集中的3個項目上,J48和SVM分類器的預測性能較差,在Apapche和Safe項目上,使用J48作為分類器得到的F1都小于0.5;而使用LR、NB和RF作為分類器得到的F1值相對較好,其中,NB分類可以取的最好的F1值.例如在Apache和Safe項目上,使用NB作為分類器得到的性能最高.
從圖7中也可以看出,除了 EQ項目,使用不同的分類器在不同的項目上得到的性能都相對較好,且性能也比較穩定.例如,除了LR在LC、ML和PDE上表現波動較大,其他分類器在各個項目上表現都比較穩定.此外,NB在EQ、JDT、LC和ML中表現最好;其次,RF也能獲得比較好的結果.
基于上述分析,不同類型的分類器對FeCTrA方法的性能會造成一定的影響,其中,NB分類器整體性能表現更好.
4.5 有效性影響因素分析
這一節主要分析可能影響到本文實證研究結論有效性的影響因素.具體來說,有以下幾個方面.
(1) 內部有效性主要涉及可能影響實驗結果正確性的內部因素,最主要的有效性影響因素是實驗代碼的實現是否正確.為減少重新實現各種基準方法過程中引入的人為因素的影響,我們使用了第三方提供的成熟框架,例如來自Weka中的機器學習包.此外,我們采用了跨項目缺陷預測開源工具CrossPare[63]提供的代碼,該工具已經實現了當前跨項目缺陷預測領域的一些經典方法.
(2) 外部有效性主要涉及實驗研究得到的結論是否具有一般性.為確保實證研究結論的一般性,我們選擇了軟件缺陷預測問題研究中經常使用的Relink數據集和AEEEM數據集.這兩個數據集累計包含了8個具有一定代表性的開源項目;同時,這些項目也覆蓋了不同類型的應用領域,可以確保研究結論具有一定的代表性.
(3) 結論有效性主要涉及使用的評測指標是否合理.本文重點考慮了F1指標,該指標是Precision和Recall指標的綜合衡量,在軟件缺陷預測領域被廣泛使用[6,7,64,65],因此可以更好地評估模型的綜合性能.
5 總結與展望
本文提出一種新穎的基于特征遷移和實例遷移的跨項目軟件缺陷預測方法 FeCTrA.該方法主要包含特征遷移和實例遷移兩個階段.在特征遷移階段,基于特征之間的關聯性,將已有特征進行聚類分析;隨后,基于特征在源項目和目標項目之間的分布相似性,將每個簇中的特征從高到低進行排序,并選出指定數量的特征,從而可以有效地移除無關特征和冗余特征.在實例遷移階段,使用 TrAdaboost技術,依據目標項目中少量的已標注實例,從源項目中挑選出大量與目標項目分布相同的實例構建訓練集,從而可以有效地縮小源項目和目標項目之間的分布差異.此外,本文基于Relink和AEEEM數據集對該方法展開了實證研究,并驗證了該方法的有效性.
本文仍存在很多值得探討的下一步工作.首先,FeCTrA方法在進行特征遷移時采用了聚類分析方式.在初始簇中心挑選不理想的情況下,可能需要花費很長的時間才能達到簇中心的收斂.本文在該階段挑選了在兩個數據集中分布最相似的前幾個特征作為初始簇中心.后續的研究需要分析考慮不同初始簇中心的選擇對整個方法性能的影響;其次,本文在特征遷移階段僅考慮了遷移特征的比例對方法性能的影響,下一步工作可以從特征的類別角度出發考慮特征遷移,即遷移何種類別的特征最有效;最后,需要將本文方法應用到實際的軟件測試過程中,如針對安卓應用的測試[66-68].部分研究工作[69]表明,有超過 90%的開發人員愿意采用缺陷預測工具.但是將缺陷預測應用于實際項目仍然存在一定的挑戰性:首先,大部分研究僅預測軟件模塊內部是否存在缺陷,而沒有提供相應的預測依據和修復建議;其次,大部分研究將程序模塊的粒度設置為類/文件,因此,即便能準確預測到軟件模塊內含有缺陷,仍然需要花費大量的時間去定位和修復這些缺陷.因此在實際的項目應用中,如果想得到開發人員的積極反饋,需要進一步完善缺陷預測工具,給出預測結果及理由、缺陷位置和修復建議等.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
