軟件開發活動數據的數據質量問題?
2019-06-11 07:40:10涂菲菲周明輝
軟件學報 2019年5期
涂菲菲,周明輝
1(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
2(北京大學 信息科學技術學院,北京 100871)
軟件開發支持工具(例如問題追蹤系統、版本控制系統)已被廣泛應用于開源和商業軟件的開發中,這些軟件開發支持工具在使用過程中產生了大量的數據,這些數據統稱為軟件開發活動數據.軟件開發活動數據覆蓋范圍非常廣,例如代碼提交[1]、功能需求的討論[2]、開發者在集成開發環境中的操作步驟[3]等.軟件開發活動數據被廣泛應用于軟件開發過程中的各種決策,例如比較不同軟件方法之間的效果[1]、估算開發者的生產效率[4]、預測軟件質量[5].
軟件開發活動數據的廣泛使用,使其數據質量受到了越來越多的關注.如果軟件開發活動數據存在質量問題,這可能使得基于問題數據的方法、軟件產生的結果存在偏差,甚至無效.例如,Kim等人[6]在利用問題追蹤數據智能化預測任務完成時間的工作中,將問題報告被標記為“已解決”的時間點視為該任務完成的時刻.然而Zheng等人[7]發現:任務完成的時間存在問題——開發者在完成任務后可能并不會及時將問題報告標記為“已解決”,而是在之后清理問題追蹤系統時,通過腳本進行批量處理,即“任務完成時間”并不能真正代表任務被解決的時刻.因此,Kim等人的結果存在偏差.
雖然已有一些研究工作注意到了數據質量問題[7-9],但文獻中往往只隱式地提及這些數據質量問題,缺乏對這些數據質量問題進行綜合分析的工作.并且數據質量問題并沒有引起足夠的重視,多數工作并不會提及其數據處理的細節,例如數據獲取來源、數據質量情況、數據預處理步驟等.為了揭示潛在的數據質量問題,以更好地幫助軟件開發活動數據的應用,本文主要研究回答以下兩個問題.
1)軟件開發活動數據可能存在哪些質量問題?
2)如何發現和解決軟件開發活動數據的質量問題?
本文通過文獻調研和訪談,并基于自有經驗對數據進行分析,總結出 9種潛在的數據質量問題,覆蓋了數據產生、數據收集、數據使用等3個階段,并提出方法以幫助對數據問題的發現和修正.
本文第1節主要介紹相關背景.第2節介紹本文的研究方法.第3節從數據質量問題覆蓋的3個階段出發,對軟件開發活動數據的質量問題進行詳細介紹.第 4節總結發現和解決軟件開發活動數據質量問題的方法.最后對本文工作進行總結并展望未來工作.
1 背景介紹
常見的軟件開發活動數據包括問題追蹤數據和版本控制數據.
· 問題追蹤數據是指在項目開發過程中出現的各種缺陷以及新增加的功能需求等的解決過程留下的數據,每個缺陷或者功能需求被稱為一個問題(issue).每個問題都包含一些特定信息,如誰發現的這個問題、這個問題被分配給誰來解決、這個問題的當前狀態、這個問題的優先級等等.問題報告的數量能在一定程度上反映代碼的質量,問題報告的解決速度能夠反映開源項目的活躍程度等,因此,問題追蹤數據對于分析軟件項目的最佳實踐具有重要意義.
· 版本控制數據是指代碼庫每一次變更的歷史數據,每次代碼更新都被稱為一個代碼提交(commit).每次代碼提交記錄了修改的原因、誰做了修改、修改了什么.版本控制數據不僅記錄了當前的代碼庫,還記錄了整個代碼庫演化的過程,這些數據對于分析項目的歷史、當前狀態以及未來都非常有價值.
1.1 問題追蹤數據
問題追蹤系統主要用于幫助開發人員追蹤軟件缺陷和需求,目前最常見的問題追蹤系統有 Bugzilla和JIRA等.
對于每個問題報告,問題追蹤系統記錄了報告的基本信息和報告的歷史活動兩部分.
· 第1部分是報告的基本信息,主要包括序列號、報告標題、報告人(reporter)、問題描述(description)、報告當前的狀態(status)、處理意見(resolution)、問題產生的環境等信息,如圖1所示.
· 問題追蹤數據具有一個特點:問題報告的信息有可能隨著時間而發生改變.例如,一個問題被報告到問題追蹤系統之后,會被其他人評論,會被調整優先級,在問題解決之后其狀態會被標記為“已解決”狀態,甚至在關閉之后被重新打開.這些操作都會使該問題報告的信息發生變動.因此,問題報告的第二部分是報告的歷史活動,如圖2所示.表中的每一行記錄了對報告的一次修改,記錄的內容包括修改人(who)、修改時間(when)、修改域(what)、修改前的值(removed)和修改后的值(added).
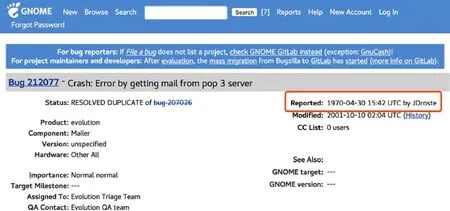
Fig.1 Basic information of issue report of #212077 in Gnome圖1 Gnome項目的212077號問題報告的基本信息
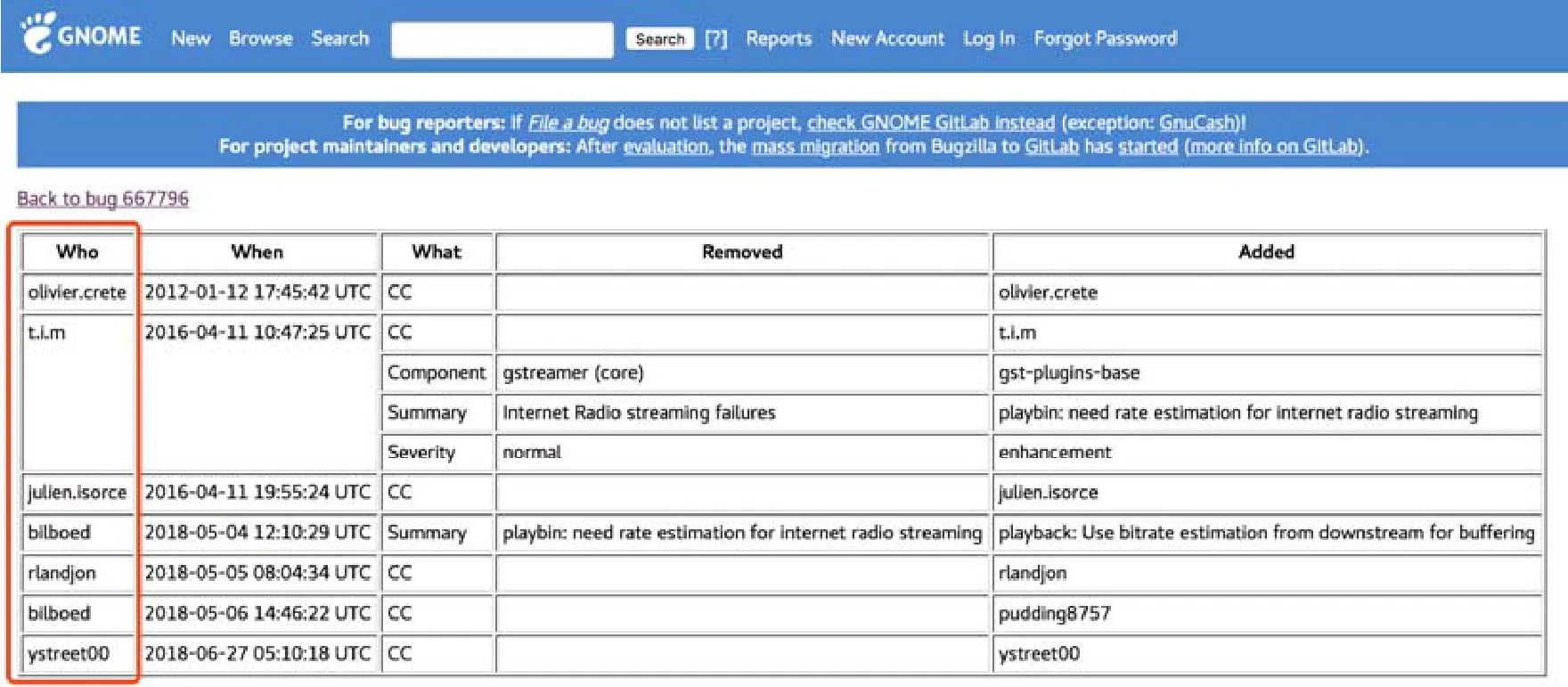
Fig.2 Activity history of issue report of #667796 in Gnome圖2 Gnome項目的667796號問題報告的歷史活動
1.2 版本控制數據
版本控制系統的核心要求是能夠方便團隊協同開發以及記錄歷史版本,目前最常見的版本控制系統有Git、Mercurial、SVN 和 CVS等.
版本控制系統在代碼提交日志里記錄了開發者的每次代碼提交信息.如圖3所示,開發者的一次代碼提交,一般包括如下信息:提交者、作者、代碼提交的時間、代碼修改的時間、對該次提交的注解、修改的文件以及對每個文件修改的內容.
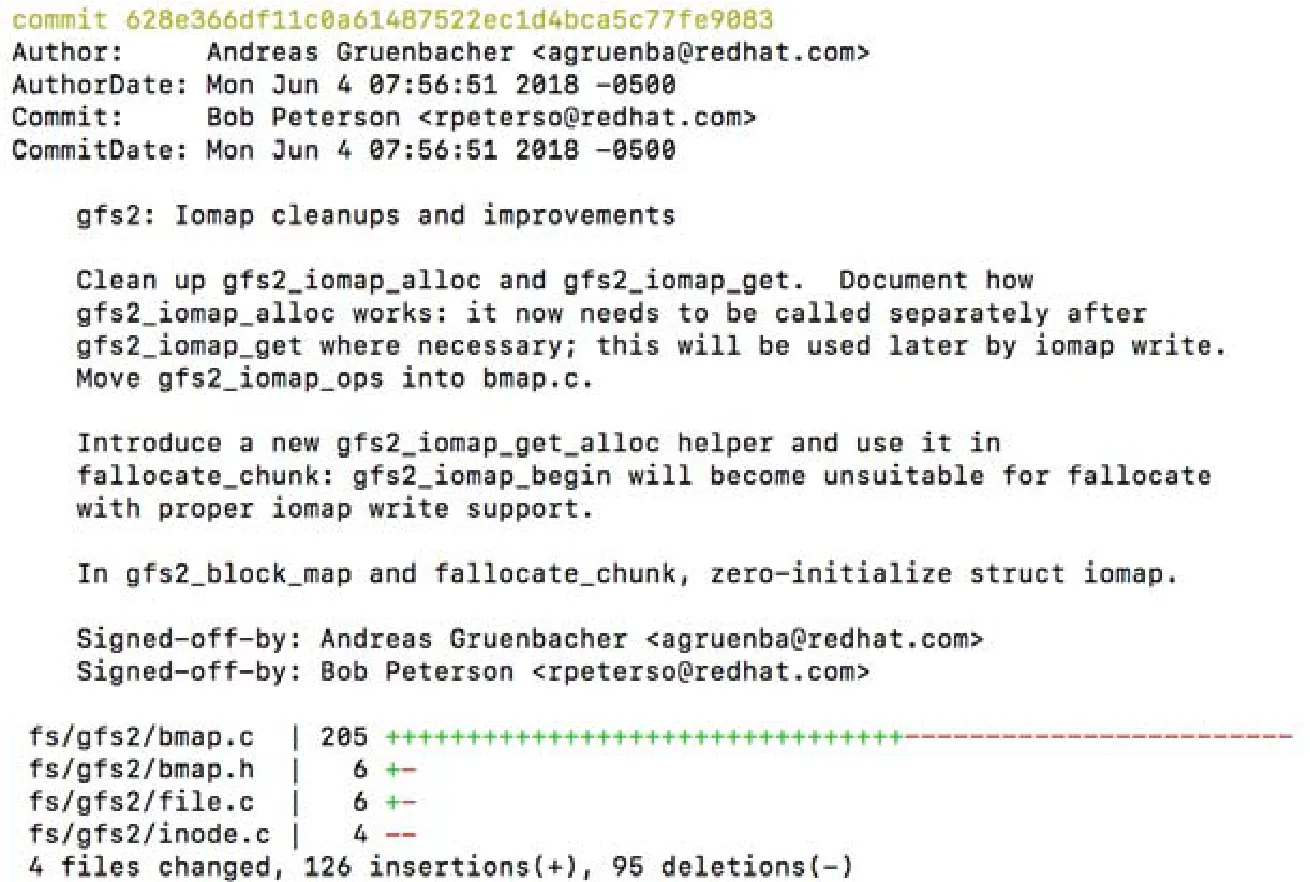
Fig.3 A code commit log in Linux kernel圖3 Linux kernel項目的一條代碼提交日志
2 研究方法
問題追蹤數據和版本控制數據記錄了軟件從需求到代碼實現的過程,是軟件開發中非常重要的數據.本文研究主要針對這兩類數據.
為了對數據質量問題進行全面的總結,我們首先在DBLP數據庫中進行檢索,時間范圍是2000年~2017年,檢索時采用的英文關鍵詞包括“bug report”“issue report”“code repository”“software repository”,共檢索到 501 篇文章;然后,對檢索出的論文,通過人工審查方式移除掉與研究問題無關的論文,并通過查閱相關論文的參考文獻和相關研究人員發表的論文列表來進一步識別出遺漏的論文.
進一步地,我們基于自身的研究和實踐經驗,對Gnome、Mozilla和Linux kernel數據進行分析,觀察可能的錯誤所在,并跟研究社區進行互動以理解數據問題存在的廣度與深度.
在調研的過程中,我們發現許多工作并不會清楚地說明論文中使用的數據集的來源,對數據進行的預處理也很少提及,例如,Tamrawi等人[10]在任務分配的工作中并沒有提及如何建立郵箱地址和獨立開發者之間的關聯關系.另外,在調研的過程中,我們去除了“問題報告錯誤分類”這一類已經非常有影響力的工作.我們更多關注的是在軟件開發活動數據的分析中,容易忽略的數據質量問題.
3 數據質量問題
本節回答第1個研究問題:軟件開發活動數據可能存在哪些質量問題?
數據質量問題可能產生于與數據有關的任何階段,其產生的原因也多種多樣.在使用軟件開發支持工具的過程中,工具記錄了與開發活動相關的數據,這個過程為數據的產生過程.數據使用者通過各種方式,將軟件開發支持工具記錄的數據收集到本地,這個過程為數據的收集過程.數據使用者基于自身對數據的理解,利用數據解決各種研究問題,這個過程為數據的使用過程.
如圖4所示,我們根據問題可能產生的時間點,即數據產生階段、數據收集階段和數據使用階段,將數據質量問題分為3類.數據產生階段的數據質量問題包括前文提到過的“任務完成時間”的陷阱、問題追蹤數據的創建時間錯誤和版本控制數據中的時間問題.數據收集階段的數據質量問題包括爬取數據不完整問題和隱私保護和安全保護等導致的數據不完整問題.數據使用階段的數據質量問題包括未來數據泄露問題、郵箱地址的問題、版本控制數據中關于作者與提交者的問題.
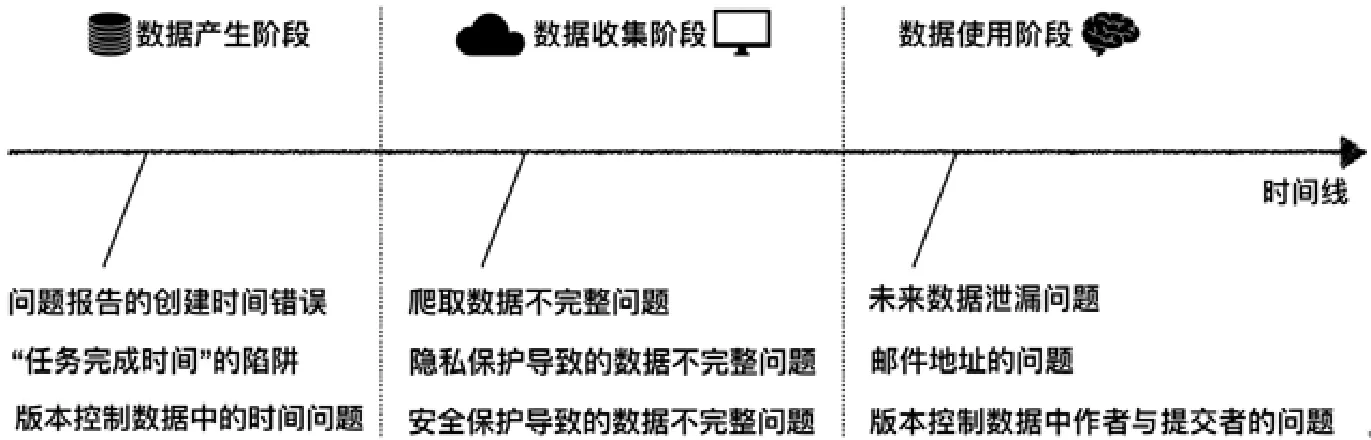
Fig.4 Three phases of data quality problems of software developemt activity data圖4 軟件開發活動數據的數據質量問題產生的3個階段
不同階段的數據問題具有不同的特性.數據產生階段的問題通常是因為軟件開發流程(支持工具或基礎設施)等所造成的數據使用者無法控制的問題.數據收集階段的問題多數可以通過優化數據收集方法而得到解決或者部分解決,屬于部分可控.數據使用階段的問題在本文中多指“數據誤用問題”,即數據使用者忽略了數據本身的某些特征,誤用數據導致問題.這類問題往往較為隱蔽不易發現,需要數據使用者對數據有深刻的理解.
這 9個數據質量問題有些源自數據經驗,有些是從文獻中歸納總結的.為了使本文更具實踐價值,對于每一個數據問題,我們列出其影響的項目.如果數據問題源于數據經驗,那么其影響的項目就是指Gnome、Mozilla、Linux kernal;如果數據問題源于文獻調研,那么除了Gnome、Mozilla、Linux kernal,其影響的項目還包括相應文獻中涉及的項目.表1列出了這9個數據質量問題的來源和影響的項目.
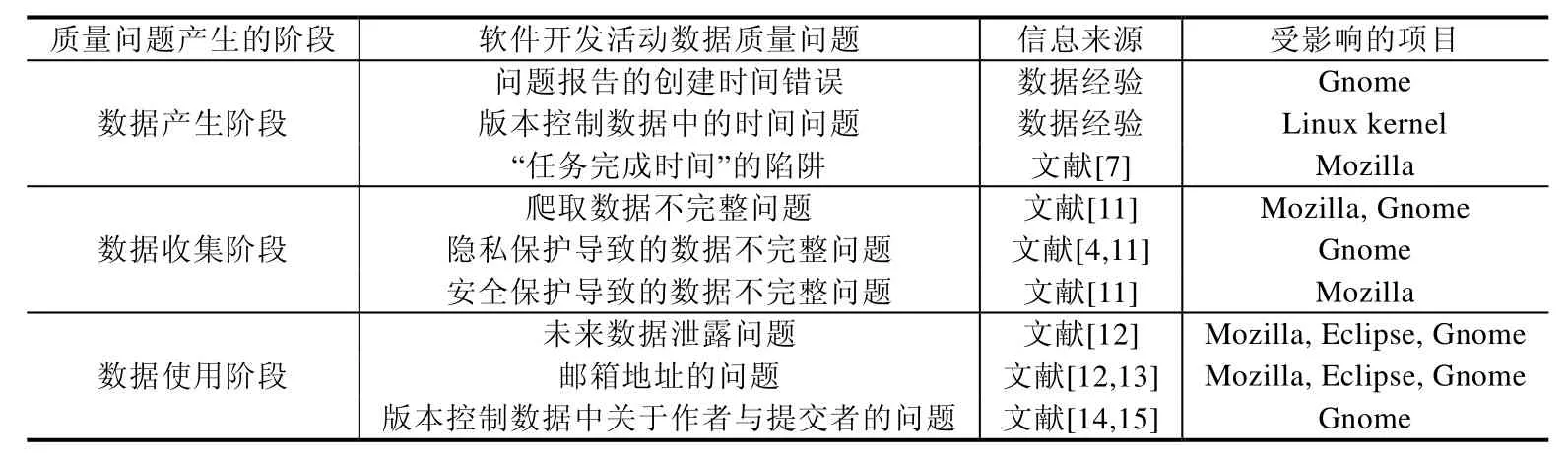
Table 1 Nine data quality problems of software developemt activity data表1 軟件開發活動數據的9個數據質量問題
3.1 數據產生階段的數據質量問題
數據產生階段的數據質量問題主要是指,記錄在軟件開發支持工具中的數據并不能真實地反映真實的開發活動.這些有問題的數據產生的原因多種多樣,可能是軟件在記錄過程中出現了問題,也可能是由于特殊的軟件開發實踐.
對于許多工作來說,時間是一個非常重要的研究因素[6,16,17].直觀上,相較于其他文本數據而言,數據中記錄的時間的準確性相對較高.因為時間的記錄形式簡單,通常為數字;含義明確,表示了某項活動發生時的系統時間.而且時間通常是由軟件自動記錄,不涉及人工輸入.但是我們所發現的數據產生階段的數據質量問題全部與時間相關.
3.1.1 問題報告的創建時間錯誤
當問題報告被創建時,問題追蹤系統自動記錄了該問題報告的創建時間.如圖2所示,在Gnome項目中,有一些問題報告的創建時間為1970年.這顯然是錯誤的時間數據,因為Gnome基金會最初建立于2000年(https://en.wikipedia.org/wiki/The_GNOME_Project),不可能在 1970年報告問題.這類問題的出現可能是源于軟件記錄的錯誤.軟件系統中記錄的時間通常與UNIX時間戳對應,而UNIX時間戳是從1970年1月1日開始計算.因此當軟件系統發生錯誤時,記錄的錯誤時間通常在1970年附近.
3.1.2 版本控制數據中的時間問題
前文已經介紹,版本控制系統中存在代碼作者和代碼提交者兩種不同的角色:代碼作者指實際寫代碼的人,代碼提交者指將寫好的代碼提交到版本控制系統中的人.根據活動發生的時間看,代碼提交的時間不會早于寫代碼的時間.如果代碼提交者同時也是代碼作者,那么代碼提交的時間可能與寫代碼的時間相同,或者代碼提交的時間晚于寫代碼的時間.如果代碼提交者和代碼作者不同,那么代碼提交的時間晚于寫代碼的時間.在 Linux kernel中,存在一些代碼提交數據,它們的代碼提交者和作者不同,但是代碼提交時間和寫代碼時間相同.根據前面的分析,這明顯是存在問題的數據.那么在根據時間戳追溯代碼變更的過程時,這個問題就會造成困擾.
3.1.3 “任務完成時間”的陷阱
“任務完成時間”的陷阱就是前文中舉例的問題.有許多工作利用問題報告的“任務完成時間”來預測一個新的問題需要的修復時間.計算方法是:一個問題報告的“任務完成時間”(即問題報告被標記為“已解決”的時間)與該問題報告的創建時間之間的時間差,即為修復該問題所需的時間.Kim等人的工作就是通過這種計算方法來預測任務完成的時間.但是,Zheng等人發現,如果將把問題報告標記為“已解決”的人視為解決該問題的人,那么按照每人每天來統計工作量,則會發現有的人一天內解決了超過200個問題.據估計,每人每天解決9個問題即為上限.一人一天內解決200個問題,這極大地超過了人的能力限制.因此,這明顯是有問題的數據.Zheng等人發現,開發者在完成任務后可能并不會及時將問題報告標記為“已解決”,而是在之后清理問題追蹤系統時,通過腳本進行批量處理.因此,“任務完成時間”并不能真正代表任務被解決的時刻.而基于問題時間數據的研究結果產生了偏差.
3.2 數據收集階段的數據質量問題
數據收集階段的數據質量問題主要是指,數據使用者收集到的數據與軟件開發支持工具產生的數據不完全一樣,在這一節中列舉的數據質量問題主要是指數據不完整.無論是通過爬蟲從網站上爬取數據,還是通過API或者某些工具同步數據,或者是直接從官方鏈接下載整理好的數據集,收集到的數據都可能會出現不完整的問題.
3.2.1 爬取數據不完整問題
在官方沒有提供數據集或者沒有可用 API下載數據的情況下,數據使用者們往往需要自己編寫爬蟲來爬取數據.這就很容易遇到爬取數據不完整的情況[11].主要是兩點原因:網絡問題以及反爬蟲機制.網絡問題主要是指網頁加載慢、網絡延遲或者丟包等問題;反爬蟲機制是指被爬取的網站采取的防御措施.因為這兩點原因,當使用爬蟲爬取數據時,數據往往不完整.
3.2.2 隱私保護導致的數據不完整問題
開源社區為了保護貢獻者的隱私,會采取一些列措施使得外部人員無法批量獲取貢獻者名單和郵箱地址.如圖2所示,在Gnome社區中,如果不登錄賬號,則無法看到貢獻者完整的郵箱地址[4].由于無法獲得完整的郵箱地址,只有開發者的昵稱,于是就喪失了郵件地址的域名這部分信息,而這部分信息往往包含了的背景信息,例如公司、學校等,因此可能會對開發者的背景分析造成困擾.
3.2.3 安全保護導致的數據不完整問題
Zhu等人的工作[11]提供了多個版本的Mozilla問題追蹤數據,其中,2011和2012兩個版本為通過爬蟲爬取的數據,2013的版本為Mozilla官方提供的數據.通過3個版本的數據比較,他們發現有些問題報告Mozilla社區并不會開放出來,因為這些問題可能涉及到 Mozilla的核心安全.當確認這些報告并不會產生安全隱患后,這些報告會重新開放出來.這種數據問題對于研究“安全”相關問題的人來說非常重要,因為這些曾經被隱藏起來的問題是真正涉及到安全的問題,是非常具有研究價值的對象.
3.3 數據使用階段的數據質量問題
數據使用階段的數據質量問題是指,數據使用者由于對數據產生的上下文不了解,而基于數據建立了錯誤的假設.
3.3.1 未來數據泄露問題
問題報告的屬性一直在隨著問題修復的進程而被不斷修改.但是許多問題追蹤數據的使用者并沒有清楚地認識到這一點,并且沒有仔細區別實驗中所使用的數據是否與研究問題的應用場景所匹配.因此,可能產生在研究實驗中,錯誤的使用了來自“未來”的信息[12].例如在Sun等人[18]的研究中,他們使用問題報告的標題進行重復報告檢測.然而,問題報告的標題會不斷修改.他們在實驗中使用的問題報告的標題已經是經過反復修改的.但是重復報告檢測的應用場景,主要是發生在問題報告創建之初.因此,應用問題報告創建時的原始標題來檢測該報告是否重復更為合適.這種數據使用問題主要是因為沒有理解“問題報告的屬性一直在隨著問題修復的進程而被不斷修改”這一事實,忽略了數據產生的上下文,對數據建立了錯誤的假設.這種錯誤使用未來數據的問題也普遍存在于數據挖掘領域,也稱為數據泄露問題,是數據挖掘的十大錯誤之一.
3.3.2 郵箱地址的問題
在軟件數據倉庫挖掘中,一個郵箱地址通常代表了一個開發者.但是一個郵箱地址并不是單純地對應一個開發者,而是存在“多對一”和“一對多”的關系.一個郵箱地址對應多個開發者,這種情況是指“一個郵箱地址”是公共郵箱(郵件列表地址)或者代表了特殊標識,例如 platform-help-inbox@eclipse.com 和 nobody@mozilla.org.前者可以被看作是問題報告分發過程中的 HUB,而后者則是代表了目前這個問題報告沒有指派,任何人都可以嘗試解決這個問題.在研究問題報告分配任務時,如果目的是將問題報告分配給具體的真實開發者,那么“多對一”將引入噪音.多個郵箱地址對應一個開發者,這是因為開發者擁有多個賬戶.這些賬戶的使用場景可能不同,例如,私人郵箱和公司郵箱;或者開發者所屬單位發生了變化,即開發者跳槽了,因此擁有多個賬戶.在研究開發者工作效率或者開發者網絡時,“一對多”將使結果產生偏差.
3.3.3 版本控制數據中關于作者與提交者的問題
在版本控制系統的提交日志中,代碼提交者(committer)和代碼作者(author)代表了兩種不同的身份.Git將代碼提交者和代碼作者分別用committer和author記錄.但是SVN和CVS并沒有區分這兩種不同的身份.在SVN和CVS中,只存在author這個域,但是author實際記錄的卻是代碼提交者.因此,如果按照Git的習慣去理解SVN和CVS的數據,以為author記錄的是代碼作者,那么就對數據有了誤解,產生了錯誤的假設.
4 數據質量問題的發現和修正
本節回答第2個研究問題:如何發現和解決軟件開發活動數據的質量問題?
4.1 問題的發現
在前面的分析中可以看出,有的數據質量問題很容易理解,比較容易發現,例如問題報告的創建時間錯誤,通過常識和統計分析及數據可視化可以發現;但有的數據質量問題比較隱蔽,例如未來數據泄露問題,需要對數據上下文有清楚的理解.
4.1.1 理解數據上下文
對于數據產生的上下文的理解,是應用數據的基礎.在第 3.3節中,我們反復強調了理解數據上下文的重要性.對數據理解不重復或者存在誤解,都會對研究結果產生影響.Mockus[19]認為,理解數據產生的上下文應至少包含以下幾點:1) 數據產生的方式,例如數據是由系統自動產生還是人工輸入、是否存在缺省值;2) 數據是否存在修改/刪除/過濾/缺損的情況,以及這些被修改/刪除/過濾/缺損的數據對結果是否有影響.
以“任務完成時間”的陷阱為例.在一般情況下,問題報告是在開發者解決了對應的問題后,手動將問題報告關閉并標記為“已解決”.但是 Zheng等人發現一天之內解決上百個問題報告,這已經不是正常情況下的處理流程.據他們發現,這種現象一般是由腳本批處理造成的.有 3個原因導致了這種特殊的問題報告處理流程:第一,問題報告由其他系統進行管理,兩邊系統進行數據同步,批量關閉了報告;第二,某個時間點集中清理問題追蹤系統中遺留的長期未解決的問題,將這些報告批量關閉;第三,當版本控制系統中的問題修復了,其關聯的問題報告可能會被批量關閉.這3種情況下,數據都是系統自動處理,而非人工手動輸入.這就是因為對數據產生的方式理解不充分而產生的數據質量問題.
4.1.2 統計分析及數據可視化
發現問題的一個有效手段是統計分析.最簡單地,統計數據的平均值、中位數、最大值、最小值、四分位數,就可以對數據的分布有一個大概的認識.在這個過程中,如果有分布非常不均衡的現象,一些突出的問題已經可以被識別出來,例如郵箱地址問題中的一對多問題.此外,還可以通過擬合一些概率分布模型來發現數據中的異常值.以“任務完成時間”的陷阱為例,Zheng等人通過泊松分布定位出了異常的“任務完成時間”.
數據可視化是數據分析中一個有效的技術手段[20].當數據以直觀的圖形形式展示在分析者面前時,分析者往往能夠一眼洞悉數據背后隱藏的信息并轉化知識以及智慧[21].通過數據可視化,可以對數據的整體走向有一個清楚的認識,對于其中的異常點也能夠輕而易舉的捕捉到.例如,在揭示“任務完成時間”陷阱的過程中,Zheng等人通過數據可視化展示出了該數據質量問題日益嚴重的發展趨勢.另外,在可視化問題追蹤數據的過程中找到了1970年這個異常點,因此發現了問題報告的創建時間錯誤.
4.2 問題的修正
在發現了軟件開發活動數據的質量問題后,可以嘗試通過兩種方法對問題數據進行修正來降低數據質量問題帶來的負面影響,即利用冗余數據進行修正和挖掘用戶行為模式進行修正.所幸,豐富的軟件開發活動數據資源使得這兩種數據修正方式成為可能.這兩種數據修正方法分別適用于不同的研究問題和背景:利用冗余數據進行修正的方法能夠很好地適用于時間存在問題的數據,例如“任務完成時間”陷阱;挖掘用戶行為模式進行修正適用于需要進行用戶身份識別的問題,例如郵箱地址的問題.數據問題的修正方法與研究問題和背景密切相關,仔細分辨研究問題的動機、背景,了解數據產生的上下文,不僅可以發現問題,也是修正數據必不可少的步驟.
4.2.1 利用冗余數據進行修正
冗余數據是指,軟件開發活動數據中與原數據用途、含義相近的數據.在軟件開發活動數據中,一項開發活動可能在多個不同的系統或者相近的活動中留下痕跡.這些就是互為冗余的數據.特別強調,這里的冗余并非貶義詞,而是指數據的意義相近(并非完全相同需要去除的冗余數據).
以“任務完成時間”的陷阱為例.冗余數據可能存在于同一個系統中,也可能存在于不同的系統中.“任務完成時間”的陷阱中,有問題的數據是問題報告被標記為“已解決”的時間.這個數據原本是想表示該問題被解決的時間.但是當它出現了問題,它就并不能起到應有的作用了.因此,從這個數據原本表示的含義出發,結合“已解決”時間產生的上下文,即與該數據相關的軟件開發活動,分別在同一個系統和不同的系統中尋找意思相近的數據.在同一個系統中,即問題追蹤系統中,每一個問題報告的最后一條評論時間基本可以等視為問題被解決的時間.因為當一個問題被解決后,就很少會有人再去關注它、討論它.那么就可以將原先錯誤的“任務完成時間”修改為更為準確的問題報告最后一條評論時間.在不同的系統當中,例如版本控制系統,與該問題報告對應的代碼的提交時間可以等視為問題為解決的時間.因為通常情況下的處理流程就是:在代碼庫中提交了代碼修改,然后將問題報告標記為“已解決”.這些都是從數據的含義出發,理解了開發實踐過程,找到的解決方法.
這種方法也可以應用到問題報告的創建時間的修正上,例如,可以用問題報告的第1條評論的時間或者第1次信息被修改的時候來預估問題報告的創建時間.利用冗余數據進行修正的方法在修正軟件開發活動的時間上具有一定的通用性,因為軟件開發活動是一系列連貫的活動,根據該項活動前后的活動數據,就可以對原來錯誤的數據進行修正.
4.2.2 挖掘用戶行為模式進行修正
軟件開發活動數據記錄了軟件開發過程中開發者的一系列活動.軟件開發是一項連續的活動,每一個行為或活動不可能單獨存在,也不會突然發生巨大的改變.我們假定一個用戶的行為模式是特定的,那么我們可以從歷史數據中挖掘出用戶的行為模式,進而對問題數據進行修正.
這里以郵箱地址的問題為例.在解決“多對一”的問題時,除了根據用戶名的命名規則和相似度進行識別,還可以通過挖掘用戶行為模式進行修正.例如在版本控制數據中,這些郵件地址的作者或者代碼提交者如果有著相近或者相同的行為習慣,那么這些郵件地址就很有可能指向同一個人.在這個問題中,行為習慣包括編寫或者提交過的文件、提交日志的書寫風格和工作時區.如果多個不同的賬戶修改同樣的代碼文件,那他們可能指向同一個人.不同的開發者有著不同的代碼風格,也有著不同的代碼日志風格,如果多個賬戶的代碼提交日志的書寫風格類似,那么他們可能指向同一個人.假定開發者的物理位置不會頻繁發生改變,那么如果多個,例如有相同書寫風格的賬戶的物理位置相近,他們就更可能指向同一個人,而在版本控制數據中,該信息可以從時區信息中提取出來.
同樣地,在識別“一對多”問題時,也同樣可以通過挖掘用戶行為模式定位出那些公共賬號,例如工作時區.在開源開發中,開發者遍布世界各地.當一個郵件地址對應的時區信息經常發生變化,具有較大不確定性,那么該賬號就很有可能是一個公共賬號.
5 總結與展望
高質量的數據是對軟件開發實踐進行分析、預測、推薦的基礎.隨著越來越多的工作圍繞軟件活動開發數據展開,也逐漸有一些工作認識到數據質量的重要性并發現了數據中潛在的數據質量問題.然而,人們對于軟件數據質量問題的關注度還遠不能匹配數據本身的重要性.因此,本文通過廣泛的文獻調研并深入分析數據,總結出了9類數據質量問題,并從發現問題和解決問題方面分別提出了建議.
我們相信,隨著智能化軟件開發的蓬勃發展,數據質量問題會得到越來越多的關注(鑒于智能軟件開發對于數據的依賴).同時希望有越來越多的努力構建出可靠的數據集,或者構建相應的方法來產生可靠的數據集.未來工作我們將重點關注用自動化的方法來檢測和修正問題數據.
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中老年保健(2021年2期)2021-08-22 07:31:10
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
海峽姐妹(2018年3期)2018-05-09 08:20:40
南方人物周刊(2017年32期)2017-10-28 22:48:36
南風窗(2016年26期)2016-12-24 21:48:09
汽車觀察(2016年3期)2016-02-28 13:16:26
