基于本體推理的終端用戶數據查詢構造方法?
2019-06-11 07:40:12王亞沙趙俊峰王江濤
軟件學報 2019年5期
唐 爽,王亞沙,趙俊峰,4,王江濤,4,夏 丁
1(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
2(北京大學 信息科學技術學院,北京 100871)
3(軟件工程國家工程中心(北京大學),北京 100871)
4(北京大學(天津濱海)新一代信息技術研究院,天津 300450)
企業信息系統中積累了大量與業務相關的數據,有效利用這些數據并從中分析獲取業務決策的知識,對于企業競爭力的提升十分重要[1].企業數據分析的一般流程大致包括3個步驟:(1) 根據決策需求確定數據分析所需回答的問題(如:在不同地區分別有哪些產品最受歡迎,什么樣的顧客有可能再次購買公司的產品等);(2) 根據問題,從企業內部信息系統及外部數據源中獲得相關數據;(3) 對數據進行分析,獲得與決策相關的知識,從而回答前面提出的問題[2].這個過程中,步驟 1與業務密切相關,且一般由對業務熟悉、具有分析經驗的人員人工完成,本文統稱此類人員為業務分析者.步驟 3雖然存在一些需要應用復雜機器學習算法的場景,但是企業日常分析中基于統計的描述性分析(descriptive analysis)仍占絕大多數[3-5].目前,研究者和產業界提出了大量的通用數據統計和可視化的工具,為描述性分析提供了較好的支持[6].而步驟 2是得到有價值分析結論的基礎,至關重要.然而,這個環節也是企業數據分析過程中主要瓶頸[7,8].
導致上述瓶頸的主要原因在于業務分析者與 IT人員在知識和技能上的鴻溝[7,8].通常,企業數據分析最主要的數據來源是企業內部的信息系統.這些信息系統大都采用關系數據庫系統存儲、管理數據,需要通過編寫并執行SQL語言程序查詢與獲取數據.業務分析者熟悉業務,了解問題與哪些方面的數據相關,但因為他們大都只是計算機終端用戶,而非計算機專業人員,也無法編程直接從數據庫中查詢并獲取數據;另一方面,運維企業信息系統的 IT人員雖然熟悉數據庫,但是卻無法根據問題確定數據查詢的需求.實踐中,一般業務分析者需在IT人員輔助下完成數據查詢任務.但是由于雙方知識結構差異較大,溝通效率較低.而且數據分析是一個需多次交互迭代的過程,需要雙發頻繁交互,由此因溝通不暢,對數據分析過程的效率造成較大負面影響.
針對上述問題,眾多學者對可視化查詢系統(visual query system,簡稱VQS)開展了研究[5-11].VQS系統將領域概念或查詢語句表達為可視化元素,讓非計算機專業的終端用戶(如業務分析者)通過交互界面操縱可視化元素,從而無需IT人員輔助即可完成查詢語句的構造.傳統的VQS系統直接基于數據模式向用戶提供可視化查詢界面,圖形化元素與關系數據庫中的表和字段一一對應[8,9].這類工作無法使用戶從數據模式的底層細節(例如數據庫中表和字段的含義、表連接條件等)中解脫出來,對于不了解數據庫結構細節的用戶幫助十分有限.
近年來,隨著語義網絡(sematic Web)和基于本體的數據訪問技術(ontology-based data access,簡稱OBDA)的發展[12-19],研究者們開始考慮利用本體(ontology)作為終端用戶和數據庫系統之間的媒介,讓用戶使用基于本體的VQS系統來構造本體查詢語句SPARQL.相對于傳統VQS系統(如圖1所示),基于本體的VQS系統(如圖2所示)的優勢在于:(1) 本體模型的圖結構和語義表達能力使其對于終端用戶的可用性更強;(2) 本體模型的規范性使其適合于作為多個系統中異構數據模式的統一視圖,從而屏蔽異構性.例如,某餐飲集團有多個門店,而不同門店使用了不同的前臺信息管理系統.雖然這些系統的數據庫的數據模式不同,但是因為同屬餐飲前臺管理領域,數據在語義層所表達的概念、關系、規則等領域知識卻十分相似,可以通過一套統一的本體模型進行表示.終端用戶利用VQS構造與具體信息系統數據模式無關的SPARQL本體查詢語句,而VQS系統則基于本體模型與各信息系統中關系模型的映射,將SPARQL語句轉換為SQL語句,進而實現對數據的查詢與獲取.較之傳統的VQS,基于本體的VQS系統需要額外增加本體模型構造、關系模型與本體模型映射以及從SPARQL查詢到SQL查詢的轉換等技術內容.目前,在OBDA領域中,基于關系數據模式的本體模型自動生成及關系模型與本體模型映射關系建立等技術已經十分成熟,并被制定成為了W3C標準[20,21].而SPARQL到SQL的轉換已經提出了高效的轉換算法并研發了實用的轉換工具[22-27].因此,本文方法將直接應用已有技術,而將關注點聚焦于如何從業務邏輯,而非數據庫設計的視角,幫助終端用戶高效構造基于SPARQL的本體查詢語句.
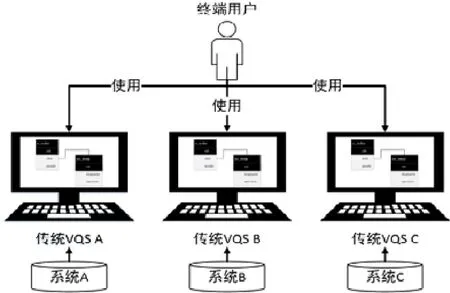
Fig.1 Traditional VQS diagram圖1 傳統VQS系統示意
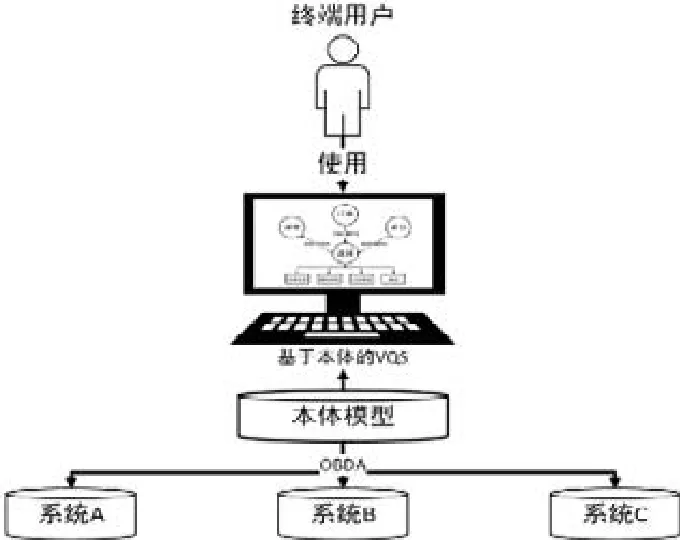
Fig.2 Ontology-based VQS diagram圖2 基于本體的VQS系統示意
現有的基于本體VQS系統的相關工作在幫助用戶構造SPARQL查詢語句的過程中,存在的主要問題是采用的本體模型不能很好地屏蔽數據庫存儲的底層細節,其主要原因是數據庫模式到本體的映射規則不完整、不準確.相關工作中,系統自動生成的本體模型基本和數據庫同構,沒有對存儲細節進行屏蔽.屏蔽數據庫細節的映射規則需要用戶手動編寫,且不能在多個數據庫之間通用.
針對基于本體的VQS現有工作的問題,本文提出了一種“基于推理的終端用戶本體查詢構造方法”,并實現了原型系統.該方法通過本體推理的方式輔助用戶對數據庫存儲的細節進行屏蔽,免去了繁瑣的規則編寫操作.此方法首先基于對終端用戶理解與數據庫存儲之間差異的分析,設計了與特定領域無關的抽象層本體模型——查詢元模型;然后,基于該元模型設計了用于屏蔽數據庫數據模式、支持和簡化屬性分組聚合操作的面向查詢的本體推理規則;最后,在元模型和推理規則的基礎上設計了可視化查詢系統以及本體查詢構造算法.同時,為了實現屬性分組聚合操作,系統對新版SPARQL語言中引入的GROUPBY關鍵字專門進行了支持.
本文第1節介紹傳統VQS及基于本體的VQS相關研究工作.第2節介紹本文方法的總體框架.第3節則針對查詢元模型、面向查詢的本體推理規則、VQS用戶可視交互設計、本體查詢 SPARQL語句構造算法等方法的核心環節進行介紹.第 4節基于國內一款主流的餐飲前臺信息管理系統的數據庫模式以及一個真實的數據獲取需求,對本文方法和原型系統進行了案例展示.
1 相關研究工作
1.1 基于數據源的VQS系統
基于數據源的 VQS系統幫助用戶構造數據源查詢語句,如 SQL,其相關工作有如下典型代表:QBE[11]面向關系型數據庫,提出一種高級數據庫管理語言,并基于此語言向用戶提供了數據查詢、更新等操作的統一接口;Xing[12]面向半結構化的XML數據,基于XML文檔模式提出一種可視化語言和界面,幫助用戶查詢和轉換XML數據;Tableau[15]是目前市面上流行的可視化數據分析軟件代表,其支持多種數據源的接入,提供可視化的交互界面供用戶完成數據連接、篩選和調整等底層操作,并提供完善的數據可視化支持.
基于數據源的VQS系統不能屏蔽底層數據模式的細節.以Tableau軟件為例,使用者在操作關系型數據庫構建數據查詢時,需要理解每張數據庫表和每個數據字段的含義以及表連接的連接字段和不同連接類型的具體語義,故 Tableau軟件的表達能力和可視化能力雖然強大,但要求使用者具備一定的專業知識,對于沒有計算機基礎知識的終端用戶不具有可用性.除此之外,直接基于數據源的 VQS系統通常只能面向單個數據源,在存在多個異構數據源系統的應用場景中難以運作.
1.2 基于本體的VQS系統
基于本體的VQS系統幫助用戶構造本體查詢語句SPARQL,本體模型的圖結構、語義表達能力和規范性使得基于本體的VQS系統相對于傳統的基于數據源的VQS系統更適合終端用戶使用,其典型代表工作如下.
· SEWASIE[16]使用集成的本體作為多個異構數據源的全局視圖并提供統一的數據訪問功能,其查詢界面通過本體中更豐富的詞匯庫幫助用戶理解數據源,并以迭代式的查詢構造和查詢確認過程幫助用戶更好地完成概念和屬性的組裝.
· DEMO[17]是面向 OWL和 SPARQL的圖形化查詢界面,其使用流程是:首先,用戶選擇查詢中所涉及的概念;然后,系統搜尋并列舉概念之間的備選關系,由用戶從中選擇;最后,用戶設置屬性的篩選條件.
· OptiqueVQS[7]是最新的基于本體的VQS系統,該系統面向終端用戶,建立在OBDA系統 Optique[6]上,結合了分面搜索和導航查詢2項網頁界面特性,分3個窗口分別展示概念列表、屬性列表和查詢構造圖示.OptiqueVQS的使用流程是:首先,用戶選擇核心概念;然后,從核心概念出發,順概念之間的關系擴展其他所需概念,對于每個概念,可在屬性列表中對屬性進行輸出選擇或條件設置.如圖3是OptiqueVQS的查詢構造界面.

Fig.3 Query construction interface of OptiqueVQS圖3 OptiqueVQS查詢構造界面
現有的基于本體的VQS系統的共性問題在于,數據庫到本體映射不能很好地屏蔽數據庫的底層細節.現有工作數據庫模式到本體模型的映射主要分為兩種方法.
1.根據數據庫模式進行直接映射(direct mapping).
將數據庫中表、字段、外鍵關系等元素映射為本體中的概念、屬性和關系,該過程稱為本體模型的bootstrapping過程.這種方式因本體模型與數據庫模式基本同構,向終端用戶暴露了過多數據庫設計的技術細節,增加了用戶理解的難度,降低了系統的可用性.如圖4所示,以“餐飲前臺信息管理”領域為例,按終端用戶的習慣,從業務知識的角度來理解,“店鋪品牌”“營業額”和“客容量”都是描述概念“店鋪”的屬性,但在實際的數據庫系統中,“品牌名稱”存儲于概念“品牌”“營業額”來源于對概念“訂單”的屬性“實收金額”的統計,“客容量”來源于對概念“桌臺”的屬性“座位數”的統計,三者均不直接從屬于概念“店鋪”中.這是由于數據庫設計需要考慮數據存儲和操作的性能,例如,為了避免冗余存儲和操作異常而需要使數據庫模式滿足一些規范約束(如 3NF),而一旦施加了這些約束,往往導致概念上緊密相關的字段分屬不同表,一方面,表的數量增加加大了理解的難度;另一方面,也使終端用戶很難從業務知識的角度出發找到自己關心的字段,進而造成查詢構造難度增加.
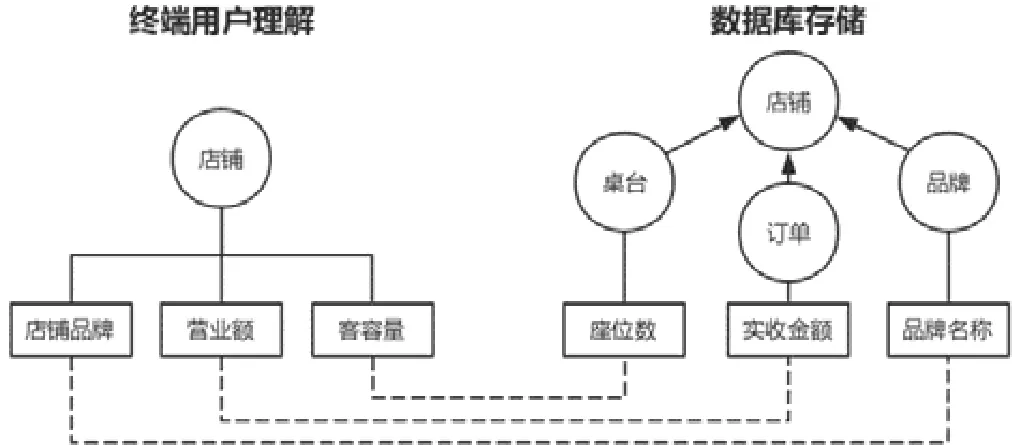
Fig.4 Example of the difference between the data conceptual model of the business perspective and the actual data schema of the database圖4 業務視角的數據概念模型與數據庫實際數據模式的差異示例
2.基于R2RML[21]語言進行映射.
該方法利用R2RML語言對數據庫模式到本體的映射方式進行描述,能夠實現自定義映射.R2RML是W3C提出的關系型數據庫到本體模型的映射語言,它除了支持簡單的字段元素映射外,還支持將SQL查詢的結果映射到本體模型.該方法往往作為 bootstrapping過程的補充,系統利用直接映射方法生成基本的映射,然后利用R2RML語言進行人工優化.利用該語言對映射進行定義,雖然能夠對數據庫設計細節進行屏蔽,但實際上是將問題拋給用戶處理,系統本身沒有解決映射的問題.一方面,該方法的映射規則需要預先編寫,特別是復雜的SQL查詢映射,必須由專業的IT人員編寫;另一方面,R2RML語言編寫的映射規則只針對特定關系數據庫有效,不能在不同的數據庫之間通用.采用 R2RML語言并不能自動地解決數據庫到本體模式映射,并屏蔽數據庫存儲細節的問題,它仍然需要大量人工參與.
因此,在構造本體模型映射的過程中,自動地屏蔽數據庫設計的技術細節、還原終端用戶自然理解的模型視圖是十分必要的,解決該問題需要深入分析用戶理解與數據存儲之間的差異本質.
2 本文方法框架
2.1 方法思路
熟悉業務的終端用戶通常從業務邏輯的視角理解數據.圖4給出了一個業務邏輯視角看待數據的概念模型與與數據庫實際存儲的數據模式之間存在差異的例子.其本質在于,概念模型中,從屬于某個概念的另一個概念(或屬性)在數據庫的實際存儲中并不一定被直接存儲,相關信息分散存儲在多個表或字段中.而這些被分散在多個表中屬于同一概念的信息,可以通過表之間直接或間接的外鍵關系來連接.如圖5所示,表A和表B的主鍵分別為屬性a,d,表A中屬性c是表B的外鍵,此處以直接的外鍵關系為例,間接的外鍵關系可同理推導.在此關系中,存在逆外鍵方向和順外鍵方向的邏輯從屬關系,本文中分別稱為屬性的“向內共享”和“向外共享”關系.
(1) 向內共享:若將數據庫范式要求由第三范式降為第二范式,則表B中屬性可以置于表A,這意味著表B中的屬性e可以在邏輯上對表A所對應的概念進行描述.“向內共享”所描述的就是屬性e逆外鍵方向邏輯從屬于表A的這種關系,如圖4中“品牌名稱”與“店鋪”.
(2) 向外共享:表A與表B因為外鍵關系形成多對一關聯,前者可按后者(即外鍵c)進行分組,若表A的屬性b的數據類型為數值型,則表A按外鍵c分組并對屬性b施加聚合函數(總計、平均值、最大值、最小值等)后屬性b可以在邏輯上對表B所對應的概念進行描述.“向外共享”所描述的就是聚合后的屬性b順外鍵方向邏輯從屬于表B的這種關系,這也是分組統計需求的基本結構,如圖4中“實收金額”與“店鋪”.
為了更好地幫助用戶構造查詢,我們應該盡量屏蔽屬性與概念之間的物理從屬關系,還原符合用戶自然理解的邏輯從屬關系,同時對屬性的聚合和分組提供支持.利用本體的推理能力,我們可以完成此項任務:設置相應的本體推理規則,根據實際存在的物理從屬關系和概念之間的外鍵關系推導出屬性與概念之間的“向外共享”和“向內共享”關系.而這樣的推理規則必須脫離具體實例,建立在與特定領域無關的抽象本體模型之上,從而具備通用性,故本文方法充分利用了本體的層次抽象能力,首先設計了與特定領域無關的抽象層本體模型——查詢元模型;然后,基于該元模型設置用于表達“向外共享”和“向內共享”關系的面向查詢的本體推理規則.本文首先對數據庫直接映射生成的本體模型進行分析,通過繼承關系將本體模型抽象到查詢元模型層次,抽象方式是,讓本體模型中的類繼承查詢元模型中的“查詢對象”、本體模型中的屬性繼承查詢元模型中的“查詢屬性”,通過這樣的過程,當用戶在本體模型上進行查詢操作的時候,用戶查詢的本體模型中的屬性將會被算法看作為“查詢屬性”,用戶查詢的本體模型中的類會被看作為“查詢對象”,從而將用戶查詢也抽象到查詢元模型層次.抽象到查詢元模型后,定義在查詢元模型上的推理規則就能應用到本體模型中.本文系統基于查詢元模型和推理規則實現可視化查詢算法,在提升可用性和表達能力的同時,還有以下幾點主要優勢.
(1) 避免數據轉換帶來的信息損失.在查詢元模型層次只是進行本體推理和查詢語句構造,不會進行數據轉換,最終的查詢還是在本體模型對應的底層數據庫中進行.
(2) 本體模型直接接入,提高靈活性.系統通過將本體模型抽象到查詢元模型來進一步屏蔽數據庫細節,該過程不需要對映射算法進行修改.因此,系統的數據通過本體模型直接接入,數據庫到本體模型的映射可以使用任意算法工具實現,可以支持多個數據庫到同一本體模型的映射.
(3) 本體模型只需一次接入,查詢操作無額外成本.本體模型接入到系統后,系統會將其抽象到查詢元模型,并利用推理規則進行查詢指標推理,接入完成后,用戶的查詢操作不會再次進行抽象和推理,不會帶來額外操作成本和計算成本.

Fig.5 Foreign key relationship example圖5 外鍵關聯示例
2.2 方法框架
本文方法的框架如圖6所示,基于本體的VQS系統以及查詢構造算法建立在查詢元模型和面向查詢的推理規則之上,其中,VQS利用推理規則所推導的導出關聯關系可幫助用戶屏蔽數據存儲細節、方便用戶完成查詢構造,并生成用戶輸入,然后由查詢構造算法根據用戶輸入還原原始的查詢結構并生成相應的 SPARQL查詢語句.對于任意的領域相關的本體模型,只要以繼承查詢元模型的方式接入系統,即可支持面向查詢的本體推理規則的運行、VQS系統的操作和本體查詢構造算法的執行.
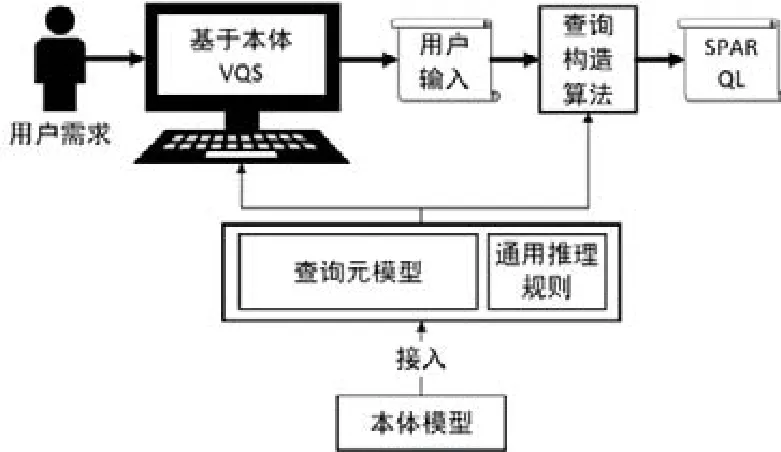
Fig.6 Method framework of this paper圖6 本文方法框架
3 詳細實現
3.1 查詢元模型
為了脫離特定領域和具體實例來設置通用的推理規則,并對屬性的聚合提供模型上的支持,本文方法首先設計了僅與查詢行為相關、與特定領域無關的查詢元模型,該元模型仍用OWL進行表達,如圖7所示.其中,“查詢屬性”概念用于描述用戶所關心的數據庫表項,如“品牌名稱”;“查詢屬性”所屬的數據庫表則抽象為“查詢對象”概念,如“品牌”.“查詢屬性”與“查詢對象”之間除了物理的“從屬”關聯,也有通過推理規則表達的邏輯上的“向內共享”關聯;對于可聚合的一類“查詢屬性”,模型中使用“查詢指標”概念對其統計值進行表達,如“營業額”(“實收金額”的統計值).“查詢指標”與“查詢對象”之間也有通過推理規則表達的邏輯上的“向外共享”關聯.

Fig.7 Query meta model diagram圖7 查詢元模型示意圖
關于查詢元模型中,“向內共享”“向外共享”關系在數據庫中的表達,主要通過兩個途徑獲取:第 1種途徑是通過面向查詢的本體推理規則計算所有可能的“向內共享”“向外共享”關系,由用戶選擇所需的關系進行標注和命名,這種方式優點是無需額外信息,只需要提供原始數據庫模式就能通過人工輔助的方式建立映射,缺點是用戶需要對數據庫模式和查詢需求有一定的了解;第 2種途徑是在已經擁有一些已知的映射關系后,對于同一領域的新數據庫,使用模式匹配方法自動生成映射關系,這種方式的優點是高效、無需用戶操作、對用戶無要求,缺點是自動生成的映射關系可能會有誤,需要手動校正.
3.2 面向查詢的本體推理規則
基于查詢元模型的本體推理規則以查詢元模型中的抽象概念、抽象關系和抽象屬性作為基本元素來進行構建,運行在查詢元模型之上,主要用于表達“向外共享”和“向內共享”所描述的并不直接存在于原始本體模型中的導出關系.這些本體推理規則可以幫助VQS系統向終端用戶適當屏蔽數據庫實際存儲模式,還原終端用戶自然理解的模型視圖,并優化終端用戶的查詢構造流程.
以“向外共享”關系的運用為例,其對應的面向查詢的本體推理規則的內容見表1,通過該推理規則可以在“查詢指標”和“查詢對象”之間建立“向外共享”關聯.

Table 1 Example of query-oriented ontology reasoning rules:Out share表1 面向查詢的本體推理規則示例:向外共享
如圖8所示,對于用戶需求“查詢各品牌的總營業額”,按照現有工作的構造方案,用戶首先必須了解營業額的計算來源于對概念“訂單”的屬性“實收金額”的聚合;其次,必須依照數據庫存儲模式構造出用戶需求中所涉及的概念(“訂單”“店鋪”“品牌”)、概念間的連接關系、聚合屬性(“實收金額”)以及分組屬性(“品牌名稱”).這套操作要求使用者熟悉數據庫實際的存儲模式,且具備一定的關系代數理論知識,對于沒有計算機基礎的終端用戶來說難度較大,系統可用性差.而按照本文方法,系統首先發現查詢指標“營業額”來自查詢屬性“實收金額”,查詢中,另一個本體中的類“品牌”是一個查詢對象;接著,系統通過查詢元模型對“向外共享”關系的表達,在查詢指標“營業額”和查詢對象“品牌”之間建立了導出關系,用戶可以直接從查詢對象“品牌”出發選擇查詢指標“營業額”完成查詢構造,而實際完整的本體查詢結構將由系統依據對應的面向查詢的推理規則反向推導而構造得到.本文方案構造流程清晰、構造內容簡潔且符合終端用戶的自然理解,系統可用性強.
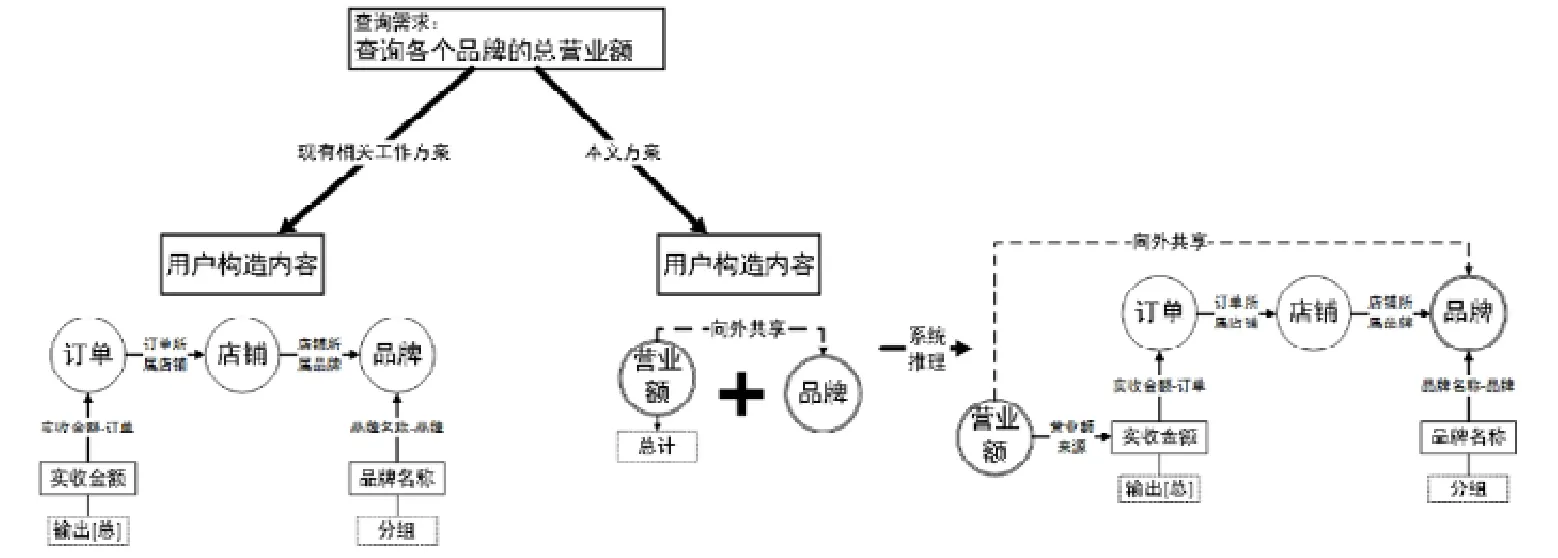
Fig.8 Example of the application of query-oriented ontology reasoning rules圖8 面向查詢的本體推理規則的運用示例
3.3 用戶可視化交互設計
本文方法中,終端用戶與系統的交互界面如圖9所示,界面中主要包含查詢指標樹(左 1欄)、查詢對象圖(左 2欄)、查詢屬性表(右2欄)、查詢元素表(右 1欄)4個子窗口.其中,查詢指標樹窗口負責展示“查詢指標”;查詢對象圖窗口負責以圖形式展示“查詢對象”;查詢屬性表窗口負責展示與用戶所點選的“查詢對象”相關的“查詢屬性”;查詢元素表窗口負責記錄用戶所選擇的元素,對于用戶所選的“查詢指標”可點擊選擇指標的聚合方式.
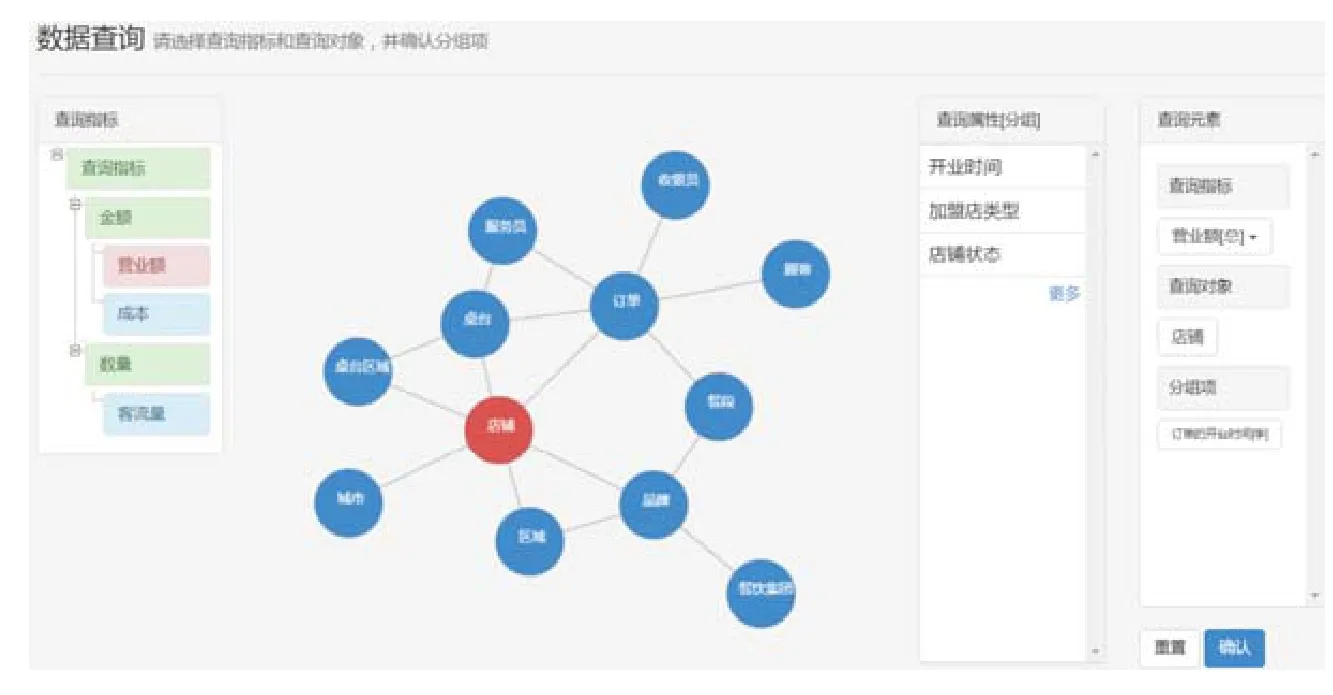
Fig.9 Interactive interface of data query system圖9 數據查詢系統的交互界面
在該界面中,用戶可以通過選擇查詢指標和查詢對象進行配合實現屬性的聚合,選擇查詢屬性實現屬性的輸出、篩選和分組,并最終完成用戶輸入.系統利用面向查詢的本體推理規則所推導的導出關系幫助用戶屏蔽實際的數據存儲模式并優化查詢構造流程,使得終端用戶可以操作少量元素來表達包括分組統計查詢在內的較為復雜的查詢結構,系統可用性和表達能力較強.最終的用戶輸入user_input整合為五元組(mname,ind,gprop,oprop,fcond)保存于系統,其中,mname為所查詢模型名稱,ind為用戶所選指標集合,gprop為用戶所選分組屬性集合,oprop為用戶所選輸出屬性集合,fcond為用戶所選篩選條件集合.隨后,系統運行本體查詢構造算法完成本體查詢語句SPARQL的構造.
3.4 本體查詢SPARQL語句構造算法
本體查詢構造算法負責將用戶輸入轉換為 SPARQL語句,SPARQL語句中最核心的組成成分為圖模式WHERE部分,為了構造圖模式,我們需要確定查詢所涉及的所有“查詢對象”以及它們之間的“外鍵關聯”關系,本體路徑搜索子算法將用于處理此任務.
本體路徑搜索子算法以用戶輸入user_input和本體模型對象ont_mgr為輸入,輸出為查詢所涉及的所有“查詢對象”之間的“外鍵關聯”關系的列表,即連接這些“查詢對象”的路徑.算法的思路是:從“查詢對象”有向圖中提取所有入度為 0的“查詢對象”組成起始對象集合,接下來遍歷起始對象集合,對每個“查詢對象”都以之為起點開始以廣度優先搜索順序遍歷“查詢對象”有向圖,對于遍歷過程中所訪問到的任意“查詢對象”,檢查其是否與用戶輸入中任意“查詢屬性”具有“從屬”關系,若有,則將該次遍歷的“外鍵關聯”關系加入結果列表.本體路徑搜索子算法的偽代碼如下:
算法1.本體路徑搜索子算法(searchOntPath).
輸入:用戶輸入user_input,本體模型對象ont_mgr.
輸出:“外鍵關聯”關系列表path_list.

SPARQL語句中最核心的組成成分為圖模式WHERE部分,該部分描述了查詢所涉及的概念、概念之間的關系、概念的屬性及對屬性的篩選,需要最先進行處理,圖模式構造子算法將用于完成圖模式部分的構造任務.
圖模式構造子算法以用戶輸入user_input、本體模型對象ont_mgr和“外鍵關聯”關系列表path_list為輸入,輸出為本體查詢的圖模式部分where,并將圖模式中使用的變量id寫回用戶輸入user_input的輸出屬性和分組屬性中,用于構造SPARQL語句中的其他部分.算法的思路是:首先遍歷“外鍵關聯”關系列表path_list,為遍歷到的每個“外鍵關聯”關系和“查詢對象”類都生成相應圖模式三元組,并記錄所有遍歷到的“查詢對象”組成列表;然后再遍歷該“查詢對象”列表,檢查用戶輸入中從屬于各“查詢對象”的“查詢屬性”,針對這些“查詢屬性”生成相應圖模式三元組,并判斷是否需要添加篩選條件;最后返回本體查詢中的圖模式部分字符串.每個“查詢對象”和“查詢屬性”都將生成唯一變量id.圖模式構造子算法的偽代碼如下:
算法2.圖模式構造子算法(genSparqlWhere).
輸入:用戶輸入user_input,本體模型對象ont_mgr,“外鍵關聯”關系列表path_list.
輸出:圖模式where.

完整的本體查詢構造過程由本體查詢構造算法負責.本體查詢構造算法以用戶輸入user_input和本體模型對象ont_mgr為輸入,輸出為SPARQL查詢語句字符串.
算法的思路是:首先,調用本體路徑搜索子算法searchOntPath獲得構造查詢所需的“外鍵關聯”關系列表path_list;然后調用圖模式構造子算法genSparqlWhere生成本體查詢語句中最核心的圖模式部分;接下來遍歷用戶輸入中的“查詢指標”、“輸出屬性”和“分組屬性”來生成SPARQL語句中的其余部分;最后,將SPARQL各部分組裝為整體字符串返回.本體查詢構造算法的偽代碼如下:
算法3.本體查詢構造算法(genSparql).
輸入:用戶輸入user_input,本體模型管理器ont_mgr.
輸出:SPARQL查詢語句sparql.


4 案例展示
本節以“北京宴品牌2016年各店鋪各季度的總營業額”查詢需求為例,展示本文VQS系統的使用操作.
終端用戶(查詢用戶)首先需要選擇所查詢領域的本體模型,如在本例中,用戶選擇“餐飲前臺信息管理”模型,選擇了對應的領域模型后,用戶就能開始構造查詢模式.
終端用戶點擊進入“餐飲前臺信息管理”領域的查詢構造界面,如圖10所示,用戶按照需求點選指標“營業額”、點選對象“店鋪”,并設置按屬性“訂單開臺時間(季度)”分組.分組構造結束后是查詢構造階段,用戶按照需求對屬性“訂單開臺時間(年份)”設置篩選條件“等于:2016”,對屬性“品牌名稱”設置篩選條件按“是:北京宴”.至此完成查詢構造,然后點擊“確認”提交查詢.
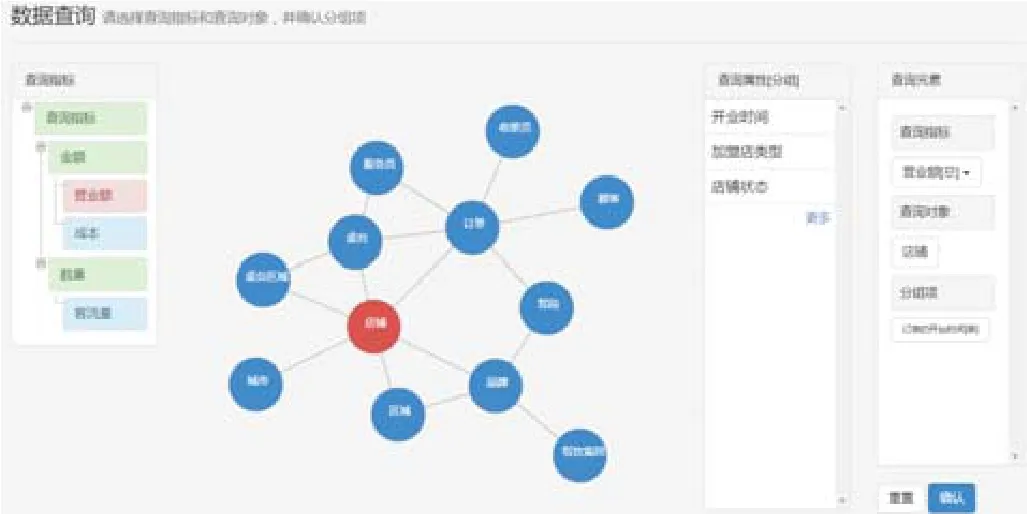
Fig.10 Data access:Design group圖10 數據訪問:分組構造
用戶完成操作后,系統將會運行完整的數據訪問流程獲得查詢結果,并進入數據展示界面,包含查詢結果、SPARQL查詢、SQL查詢和數據可視化這4部分,具體如圖11、圖12所示.

Fig.11 Example of the contructed SPARQL and SQL queries圖11 SPARQL與SQL查詢語句構造示例

Fig.12 Data display:Sector and histogram圖12 數據展示:扇形圖和柱狀圖
5 實驗驗證
5.1 實驗設定
本節對本文方法進行評估的方法為實驗測試,主要評估指標為方法的可用性和表達能力.由于用戶對數據庫和計算機系統的了解程度非常難以量化,評估系統易用性將結合可用性和表達能力進行.在表達能力相同的情況下,可用性越高(操作越簡單),則易用性越強.實驗對比對象為目前最優秀的基于本體的可視化查詢系統OptiqueVQS[7].實驗所使用的實驗材料來自于“餐飲前臺信息管理”領域中,一款主流餐飲前臺管理系統——“餐行健”系統的后臺數據報表管理平臺,本節從其中隨機選取了 40項數據查詢實例,分別按照本文方法及OptiqueVQS方法完成本體查詢構造任務.為了保證用戶對數據庫以及計算機專業知識了解程度相同,實驗中,兩種VQS系統由同一用戶操作.在實驗開始之前,讓用戶充分熟悉系統的界面和操作,避免UI設計影響用戶操作,用戶在進行查詢時,允許用戶多次進行同一查詢實例的查詢,我們記錄其操作最簡單的一次操作.
5.2 實驗指標
實驗的主要評估指標是可用性和表達能力.
· 方法的可用性是指通過系統完成查詢的操作復雜程度.
VQS系統的操作主要有點擊選擇(點選)、翻頁查找(翻頁)以及輸入信息(輸入).通常情況下,認為輸入操作最為復雜,翻頁操作次之,點選操作比較簡單.同時,對于 VQS系統來說,可視化操作意味著鼠標操作是主要操作方式,因此點選操作占絕大部分,翻頁操作較少,而輸入操作一般出現在特殊查詢條件的輸入.不同系統操作次數一般相同,以“北京宴品牌2016年各店鋪各季度的總營業額”為例,本文方法完成查詢需要15次點選操作和2次輸入操作,沒有翻頁操作.因此在考慮評估操作復雜程度時,我們主要是比較點選操作的數量.但為了區分不同操作的復雜性不同,在設置操作積分時,我們為點選設置積分為1分;翻頁操作為2分,因為翻多頁需要多次點擊,但為了排除列表順序對積分的影響,我們按實驗過程中統計的平均翻頁次數 2次計算翻頁操作的積分;而輸入操作為 3分,這是因為輸入操作比其他操作復雜,但數量較少且不同系統差異較小,不應該在總積分中占較大比重.對于同樣的查詢需求,可用性高的VQS系統用戶操作較為簡單,反之較為復雜.
· 方法的表達能力是指通過系統可視化操作構造的查詢語句的能力.
可視化查詢方法相對于語句查詢方法在簡化用戶查詢操作難度的同時,往往會帶來表達能力的損失,即部分查詢語句無法通過可視化操作的方式構造.不同的 VQS系統一般具有不同的表達能力,表達能力高的 VQS系統能構造出更多復雜查詢語句,能更好地滿足用戶的查詢需求.
兩種指標的量化計算步驟如下.
1.數據查詢實例數量N=40.
2.對于第i條查詢實例,在查詢構造所需的操作中點選次數記為Ci、翻頁次數記為Pi、輸入次數記為Ii.給點選、翻頁和輸入操作分別設置Mc=1,Mp=2,MI=3的操作積分,積分高的操作更為復雜.再根據所選系統能否正確構造出查詢語句來設置正確性標志Ai:

3.若VQS系統不能正確構造查詢語句,則假設用戶最后可以通過輸入正確查詢語句的方式更正查詢,實驗中首先構造出最接近查詢目標的查詢,然后增加一次更正操作(輸入操作).
4.對于第i條查詢實例,方案的操作積分Qi的計算公式為
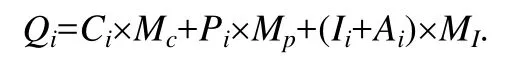
其含義為:根據操作次數計算出每種操作的總積分,再將點擊、翻頁、輸入這 3種操作的積分求和作為最終操作積分.
5.對于第i條查詢實例,方案的表達積分Ei的計算公式為

其含義為:除更正操作外,其他操作總分占操作積分的比例.因此,如果可以正確構造查詢語句,表達積分為1;不能正確構造查詢語句,則積分小于 1.由于Qi與要構造的查詢的復雜程度基本正相關,這保證了在無法正確構造的情況下,要構造的查詢越簡單,積分越接近于0,即懲罰無法正確構造的簡答查詢.
6.記兩種VQS系統所有查詢實例中操作積分最高為Qmax.
7.方案可用性的計算公式為

8.方案表達能力的計算公式為

5.3 實驗結果
實驗結果中,兩種評估指標如圖13所示.
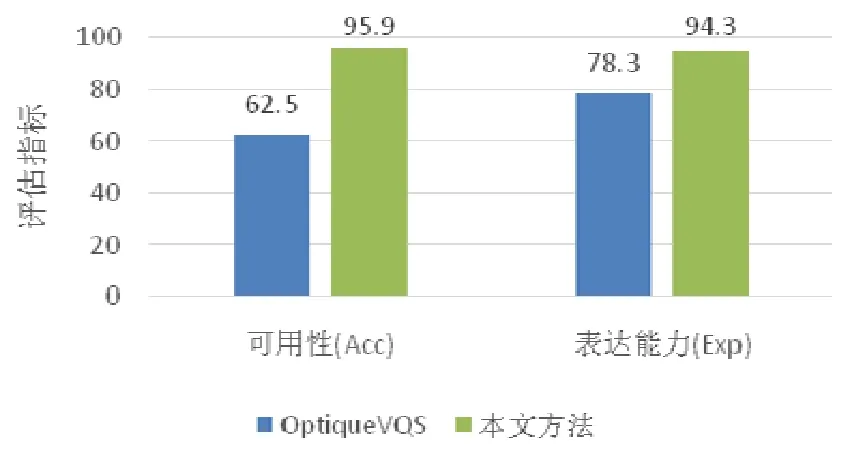
Fig.13 Method evaluation results of this paper圖13 本文方法評估結果
對于實驗結果的分析如下.
(1) 本文方法的可用性量化值高于OptiqueVQS方法,說明終端用戶利用本文方法進行查詢構造所需要的操作復雜度更低.形成這樣的實驗結果的原因在于:本文方法充分利用了本體模型的推理能力來優化查詢構造流程,用戶可以依賴由面向查詢的本體推理規則所推導出的導出關系來完成查詢構造,減少了構造查詢所需要確認的模型元素,而實際的完整查詢結構則由系統根據對應的推理規則反向推導得到,用戶不需要了解數據庫系統的實際存儲模式.該結果驗證了本文方法具有更強的可用性.
(2) 本文方法的表達能力量化值高于OptiqueVQS方法,該差異主要來源于本文方法對終端用戶的分組統計需求進行了支持,而OptiqueVQS方法未能對之進行相應支持.實驗共40個查詢實例,其中4個查詢實例本文方法無法正確構造,其原因在于這些查詢需要對多條查詢語句的結果進行組合得到;12個查詢實例OptiqueVQS方法無法正確構造,除前面提到的4個查詢實例外,還有8個查詢實例中涉及到了分組統計,而OptiqueVQS無法可視化構造分組查詢.該結果驗證了本文方法具有更強的表達能力.
6 結 論
本文以幫助終端用戶構造本體查詢語句 SPARQL為基本目標,首先調研了相關的研究工作,分析并總結了相關工作的主要內容與不足之處,不足之處主要在于直接暴露數據庫實際存儲模式且不能支持分組統計需求;然后,針對終端用戶的真實數據訪問需求以及現有相關工作的不足,提出并實現了一種基于推理的終端用戶本體查詢構造方法;最后,通過“餐飲前臺信息管理”領域的實際案例對本文方法進行了驗證.
本文方法面向沒有計算機基礎的終端用戶,充分利用本體模型的語義表達能力和推理能力來優化終端用戶的查詢構造流程,幫助用戶脫離數據庫的實際存儲模式細節;同時,對終端用戶的分組統計需求提供了支持,填補了現有相關工作的不足,具備更強的可用性和表達能力.
本文工作未來的一個研究方向是實現對復雜統計指標的支持.在實際應用場景中,終端用戶所關心的一些復雜統計指標無法直接單次構造得到,需要對多條查詢進行組合,例如店鋪的“客均營業額”指標需要由店鋪的“營業額”和“客流量”這兩項指標聯合計算得到,而本文方法尚不支持對多條查詢進行組合.故本文未來需要研究“多條查詢的組合和運算”,首先,在模型上增加元素對其進行表達;然后,在系統中添加相應功能,實現對單條查詢之間類似四則運算的組合機制.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
