基于邊介數模型的差分隱私保護方案
2019-06-11 03:05:24黃海平王凱湯雄張東軍
通信學報 2019年5期
黃海平,王凱,湯雄,張東軍
(1. 南京郵電大學計算機學院,江蘇 南京 210023;2. 江蘇省無線傳感網高技術研究重點實驗室,江蘇 南京 210023)
1 引言
快速發展的社交網絡應用促使大量社交數據被廣泛使用,對用戶隱私構成了威脅[1]。因此,社交網絡的研究者通過在節點參數和圖結構中添加噪聲來實現數據隱私保護。然而,即使是引入噪聲的圖數據仍然可以實現去匿名化,尤其是在攻擊者具備相應網絡背景知識的前提下。隨著社交網絡在全球范圍內的普及,攻擊者將更容易獲得各種類型的背景知識,隱私泄露的風險也隨之增加。
為了加強隱私保護的效果,差分隱私技術[2]被應用于社交網絡中。最早的差分隱私只是對社交網絡數據進行一些簡單的統計分析,大多只涉及屬性信息而忽略了結構信息,許多重要的圖屬性都可以通過子圖計數查詢得到。其后,關系差分隱私框架出現,它保證了社交網絡中任何一條邊的改變都不會對查詢結果造成太大的影響。然而,盡管關系差分隱私框架將需要引入的噪聲量從網絡中節點數量的多項式級別減少到了多項式對數級別,但相對于查詢函數中節點的數目,關系差分隱私需要引入的噪聲量依然是超指數級別的,查詢結果的數據可用性依然很難保證。為了在不泄露隱私的情況下安全地發布真實的社交網絡圖數據,可應用一個更加強健的匿名技術框架[3],其以精妙的方式修改圖結構以提高隱私保護程度,而保留大部分的原始圖結構。然而,這類方法通常僅能針對一種特定類型的攻擊方式,而對一些新型的去匿名化攻擊技術效果不佳。
鑒于此,本文將尋求一種提供圖數據隱私保護且能保留圖結構的方案,該方案將“重要性”相同的邊劃分成為單獨的組進行加噪處理,在提供了較高強度的隱私保護性的同時,保證了社交網絡圖的數據可用性。本文的主要貢獻如下。
1) 結合dK-匿名結構將排序后的2K序列根據條件進行聚類操作,劃分成一組組子序列,使 2K序列敏感度上限顯著減少,從而大大降低了所需引入的總噪聲量。
2) 提出基于邊介數模型的差分隱私保護方案BCPA(betweenness centrality protection algorithm),根據介數排序的dK序列將原始圖中“重要性”相同或相近的邊聚類在同一子序列中,分組加噪時能保證不改變各條邊的“重要性”,在保留了更多結構特征的同時也具有更好的數據可用性。
3) 提出一種基于鄰接度的隱私保護性衡量算法,可以有效地衡量擾動對原始圖數據的影響程度。
2 相關工作
近年來,針對社交網絡圖結構的差分隱私,研究者們取得了很多成果。Hay等[4]提出k-邊差分隱私,即2個鄰圖最多相差k條邊,以求擾動程度與隱私保護強度之間的平衡,與常用的節點差分隱私相比,其減小了校準噪聲的添加,使圖結構分析在k-邊差分隱私時較為準確。Mir等[5]試圖用隨機Kronecker圖[6]生成與原始圖具有相似敏感度的差分隱私拓撲圖,提供較為準確的真實圖像,同時保護其中參與個體的隱私。Day等[7]引入基于邊加法的圖投影方法,提出2種基于聚合和累加直方圖的方法來發布滿足差分隱私的擾動圖,通過降低敏感度來生成逼近真實度分布的拓撲圖。
在處理差分隱私發布圖時,研究者廣泛運用了dK圖隱私模型。Sala等[8]提出一種dK圖隱私模型,設計了dK-PA(dK-perturbation algorithm)處理差分隱私的圖發布,使用dK圖查詢并獲取圖結構的dK序列,對查詢結果dK注入差分隱私噪聲獲得擾動的dK序列。其后,Sala等[8]又設計出DRC(divide randomize and conquer)算法,通過對加噪之前的dK序列進行聚類分組,以降低算法復雜度,但是由于全局敏感度較大,所提出的 2K圖隱私模型實用性比較低。Wang等[9]結合dK圖模型與隨機矩陣圖模型,設計了針對圖的1K、2K、3K模型處理算法注入擾動參數,獲取網絡圖的邊差分隱私。蘭麗輝等[10]針對權重社交網絡,結合dK圖模型設計LWSPA(protection algorithm based on Laplace noise for weighted social network)對查詢結果集中的三元組序列進行分割,再對每個子序列構建滿足差分隱私的算法,將查詢結果集映射為一個實數向量,通過在向量中注入 Laplace噪聲實現隱私保護。然而,這些方法在數據可用性方面仍顯不足,除非隱私參數ε被設置成不合理的大值。
通過對上述相關工作的研究與分析,本文提出了基于邊介數模型的差分隱私處理方案。在該方案中,選用dK圖模型來實現圖的差分隱私。根據給定的原始網絡圖,生成對應的 2K序列;根據邊中介中心性系數對2K序列進行重新排序;將排序后的序列聚類為一個個子序列,并分組進行擾動[11]以滿足差分隱私;將擾動后的各子序列整合成完整的新2K序列,并還原成圖進行發布。最后,本文將該隱私保護方案與已有經典方案進行比較,實驗結果表明,在較高隱私需求的情況下,其隱私保護性和大部分數據可用性都具有一定優勢。
3 模型與算法描述
3.1 差分隱私定義
差分隱私是由Dwork[2]提出的一種隱私保護模型。該模型可以保證即使攻擊者獲得了所能掌握的最大背景知識,仍無法識別某一條數據記錄是否存在于該數據集中。同時,該模型還提出了一種量化分析方法來表示隱私保護強度。
定義1若給定 2個數據集D1和D2,有且只有一條記錄不同,表示為,則稱D1和D2為兄弟數據表。對于隨機算法A,Range(A)用來表示該算法的輸出結果集合,即對于D1與D2的算法輸出結果S∈Range(A),若滿足式(1),則稱算法A滿足ε-差分隱私。

其中,概率Pr表示隱私被披露的風險;ε為調節算法A隱私保護強度的參數,即隱私預算參數,ε越小,數據的安全性越高[12]。
定理1非交互輸出擾動[13]。設有函數集F,其敏感度為S(F),K為向F中每一個函數f的輸出添加獨立噪聲的算法。若該噪聲為參數值取的Laplace分布,則算法K滿足ε-差分隱私。其中,對以兄弟數據表為輸入的查詢函數,敏感度S(F)為其查詢結果的最大曼哈頓距離。
證明見文獻[13]。
定理2組合性質[14]。假設有n個隨機算法,其中Ai滿足εi-差分隱私,且任意2個算法的操作數據集沒有交集,則{Ai}(1≤i≤n)組合后的算法滿足max(εi)-差分隱私。
證明見文獻[14]。
由定理1可知,敏感度S(F)和差分隱私參數ε決定了實現差分隱私需要添加的Laplace噪聲量。
3.2 dK序列及2K敏感度分析
dK序列是一組描述圖屬性的數據集合,它可以將不同細節級別的圖結構表示為統計信息。隨著d值的增加,描述的圖屬性也更加具體。
對于給定的圖G,0K分布只是圖的平均節點度;1K分布則是圖的度數分布;2K分布是圖的聯合度分布,即具有不同節點度組合的2節點子圖的數目;3K分布表示具有不同節點度組合的3節點子圖的數目,即聚類系數分布。在極限情況下,nK分布(其中n是圖中的節點數)可以捕獲完整的圖結構。圖1給出一個詳細的示例,其中列出了所給圖的2K序列和3K序列。

圖1 dK序列示例
dK模型是一個圖構造模型,它利用dK序列捕獲的結構性統計數據集合,生成與原始圖結構類似的圖。對于給定的圖G,dK圖模型可以對其進行分析以產生相應的dK序列,然后使用相應的生成器來構造使用dK序列作為輸入的合成圖。
本文方案主要運用2K圖模型,因此2K序列敏感度在其中起到至關重要的作用。設圖G=(V,E),其中V是節點的集合,E是連接V中節點對的邊的集合。2K序列形式上是元組{dx,dy;k}的集合,其中,每個元組表示具有度dx和dy且連接分量為 2的節點對的數量為k。設m為元組的總數目,dmax是圖G中的最大節點度數,有,且在圖G為完全圖時取得最大值,因此
函數的敏感度被定義為當函數域中的一個元素被修改時,函數輸出的最大曼哈頓距離。2K序列的域是圖G,G的鄰圖是所有與G相差至多一條邊的圖G′。改變G中的一條邊將導致在相應的2K序列中改變一個或多個條目。因此,2K序列的敏感度等于所有G的鄰圖G′中的2K序列的最大變化數。
定理 32K序列敏感度上限[8]。2K序列的敏感度S2K的上限為4dmax+1。
證明見文獻[8]。
由定理1可知,對于給定的差分隱私參數ε,敏感度的上限決定實現差分隱私所必要的噪聲添加量,因此在這里只討論2K序列敏感度的上限。如果使用更高階的dK序列,將造成更高的敏感度值,這必然會降低生成的合成圖的精確度。
3.3 基于邊介數模型的差分隱私處理方案
3.3.1 方案算法流程
若直接對圖G的2K序列進行隨機擾動以滿足差分隱私,需引入大量的噪聲。根據定理 3,任意圖G上2K序列的敏感度S2K的上限為4dmax+1。為了顯著減少實現給定級別差分隱私所必須添加的噪聲量,本文方案根據各元組中邊中介中心性系數的平均值大小對2K序列進行重新排序,將數據分割成一組組子序列,然后獨立地對每個子序列進行擾動以實現ε-差分隱私。下面本文將證明如果在每個劃分出的子序列上實現ε-差分隱私,在整個2K序列也將實現ε-差分隱私。具體算法流程如算法1所示。
算法1基于邊中介中心性系數的分組差分隱私
輸入由給定圖G生成的2K序列,用{dx,dy;k}表示,子序列數量n
輸出滿足差分隱私的新2K序列,用{d′x,d′y;k′}表示
1) 求出2K序列的元組數量q;
2) fori= 1 toq
4) end for
6) 將排序后的2K序列聚類為一組組子序列;
7) fori= 1 ton
8) 利用dK擾動算法向子序列注入噪聲;
9) end for
10) 將擾動的子序列合成為新的序列{d′x,d′y;k′};
具體的實現過程將在3.3.2節~3.3.4節介紹。
3.3.2 邊介數排序算法
邊中介中心性系數(edge betweenness centrality)定義為網絡中所有最短路徑中經過該條邊的路徑的數目占最短路徑總數的比例[15],即網絡中包含成員i的所有最短路徑數占所有最短路徑數的百分比。它表示邊i的控制能力,其值越大就代表有越多的節點需要通過它才能與其他節點發生聯系[16]。對于給定圖G,N為其節點數目,i是圖G中任意一條邊,則邊i的中介中心性系數的計算式為

其中,nst表示節點s與節點t之間最短路徑的數目,而nst(i)表示節點s與節點t之間通過邊i的最短路徑的數目。
由3.2節可知,2K序列是元組{dx,dy;k}的集合,其中每個元組表示具有度dx和dy且連接分量為 2的節點對的數量為k,即度為dx的節點和度為dy的節點之間連接邊的數量為k。對于每個元組,求出其中包含的邊的中介中心性系數平均值,并根據中介中心性系數平均值由小到大對2K序列重新排序。具體算法流程如算法2所示。
算法2邊中介中心性系數平均值計算
輸入由給定圖G生成的2K序列,用{dx,dy;k}表示
輸出2K序列的邊中介中心性系數平均值
1) 求出2K序列的元組數量q;
2) fori= 1 toq
3) 篩選出符合{dx,dy}度分布的k條邊;
6) end for
7) 根據邊中介中心性系數平均值由小到大對2K序列重新排序;
邊中介中心性系數可以量化表示某一條邊在圖中的“重要性”,通過引入邊中介中心性系數,對2K序列重新排序,將“重要性”相同或相近的邊進行聚類分組,在擾動時能夠有效地保留原始圖的屬性與結構特征,使加噪后的圖數據具有較好的研究意義。
3.3.3 分組差分隱私噪音添加
將排序后的2K序列R根據數據集大小劃分為n個子序列,第i個命名為Ri,i∈[1,n]。n的大小由數據集大小決定,若數據集較大,則選擇相對較大的n;若數據集較小,則選擇相對較小的n。依照下面2條規則對R序列進行聚類。
1) 每個子序列只能獲取R序列中的連續元組。
2) 每個元組必須出現且僅可以出現在一個子序列中。
根據上述2條規則,可以獲得連續且相互不相交的子序列Ri。由定理3可知,這2條規則對于子序列敏感度性質是非常重要的。
定理4子序列獨立性。對于排序后的2K序列R,當i≠j時,R序列的任何子序列Ri與Rj的敏感度相互獨立。
證明該定理是基于以下假設利用反證法進行證明的。假設Ri的敏感度受到發生在Rj中的變化的影響,i≠j。在不失一般性的前提下,假設i<j,并且T(i′)是Ri中的元組,T(j′)是Rj中的元組。假設在節點v1和節點v2之間形成一條新邊,其中節點v1的相應元組<T(i),T(i+1),…>∈Ri且節點v2的相應元組<T(j),T(j+1),…>∈Rj。由于此事件可能發生的最大變化次數受v1和v2的度值的限制。令d1為v1的新度值,Ri中變化的元組的最大數目為d1-1個被刪除的元組和d1個添加的元組,即小于2d1。對稱地,令d2為v2的新度數,因此Rj中變化的元組的最大數目小于2d2。即使d1和d2等于它們的子序列中的最大度值dmax,如在定理3中規定的,每個子序列中涉及的變化的數目是2dmax<4dmax+1,這意味著Ri和Rj的敏感度不會相互影響,與該假設相矛盾。
證畢。
利用dK擾動算法,計算要注入2K序列的噪聲以滿足ε-差分隱私。dK擾動算法是基于 Laplace分布 Lap(λ)中的隨機變量改變 2K序列的每個元組的噪音添加算法。
定義2設DK是對圖G生成的2K序列執行差分隱私機制,使。對于至多相差一條邊的任何圖G和G′,如果滿足式(3),則DK滿足ε-差分隱私。
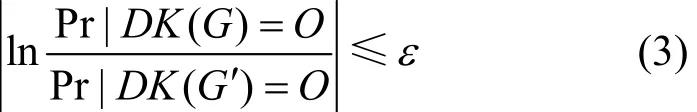
其中,S2K為2K序列的Laplace機制敏感度,O為DK(G)可能的輸出,μ為2K序列的元組個數。
根據定理3,若直接對2K序列R添加噪聲,該噪聲為參數取值的Laplace分布,且μ值為整個2K序列R的元組個數。若如算法2所述,先對 2K序列進行聚類分組,獲得連續且相互不相交的子序列Ri,則每個子序列的敏感度為再運用定義 2對每個子序列Ri注入參數為的Laplace噪聲,這將大幅減小擾動噪聲的添加量,理由如下。
設di為相應子序列Ri中節點的最大度數,μi為相應子序列Ri的元組個數,則該噪聲為參數且μi值為子序列Ri的元組個數。由于di≤dmax且μi≤μ,因此對噪聲添加量的縮減是指數級別的,這意味著在獲得相同隱私保護強度的情況下,聚類操作將很大程度上減小對原始圖結構的擾動。
隨后利用dK擾動算法向每個子序列注入噪聲使每個子序列都滿足ε-差分隱私,再將加噪后的子序列整合為一個新的2K序列。下面將證明如果在每個劃分出的子序列上實現ε-差分隱私,在整合之后的2K序列上也將實現ε-差分隱私。
定理5子序列組合性質。給定n個滿足ε-差分隱私的不同的Ri子序列,i∈[i,n],它們合成的2K序列R也滿足ε-差分隱私。
證明對于n個滿足ε-差分隱私的子序列Ri。根據定理4,當i≠j時,任何子序列Ri與Rj的敏感度相互獨立,即每個Ri引入噪聲量相互獨立。根據定理2,合成的2K序列R滿足ε-差分隱私。
證畢。
3.3.4 2K隨機圖生成算法
給定無向圖G=(V,E),其節點數n=|V|,邊數m=|E|。設deg(v)為節點v的度數,Vk為度數為k的節點集合。
聯合度矩陣JDM定義為

此矩陣描述連接度為k的節點和度為l的節點之間的邊的數量,2K序列可以容易地由聯合度矩陣推導得出。根據同一個聯合度矩陣,2K序列可以構造出不止一個在結構和屬性上有略微差異的圖。
2K隨機圖生成算法如算法3所示。
算法32K隨機圖生成
輸入聯合度矩陣JDM′
輸出滿足JDM = JDM′的隨機圖
1) 創建|V|個節點,每個節點擁有deg(v)個可用端口;
2) 對于所有(k,l)∈JDM′,令JDM (k,l) = 0;
3) for (k,l)∈JDM′(k,l)
4) while JDM (k,l)<JDM′(k,l)
5) 任選不相連的 2個節點v∈Vk及w∈Vl;
6) ifv沒有可用端口
7) 調用算法4 NeighborSwitch(v);
8) end if
9) ifw沒有可用端口
10) 調用算法4 NeighborSwitch(w);
11) end if
12) JDM (k,l)++;JDM (l,k)++;
13) end while
14) end for
初始化過程中,創建|V|=n個節點,分別以它們的度數作為標號。對每個節點v∈V,根據它們各自的度數分配 deg(v)個可用端口。初始狀態下全部節點都尚未連接,所以將JDM (k,l)中所有度數對(k,l)的值初始化為 0。隨后算法開始進行迭代,在每次迭代中,選擇2個不相連的節點v和w,度數分別為k和l。當JDM (k,l)沒有構造完全時,將v的一個可用端口與w的一個可用端口連接起來以創建邊(v,w),并且將相應的2個項JDM (k,l)和JDM (l,k)的值增加1。直到當前JDM的所有條目已經達到其在JDM′(l,k)中的目標值,2K圖構造完成。
2K隨機圖生成算法的核心在于:當JDM (deg(v),deg(w))尚未達到其目標值時,即使不相連的2個節點v和w中的任一個或兩者都沒有可用端口時,也總是可以在它們之間添加一條邊。在添加邊(v,w)之前,對于沒有可用端口的每個節點,對邊執行重新布線。這一操作被稱為“鄰節點轉換”。
將沒有可用端口的節點定義為飽和節點,將至少有一個可用端口的節點定義為不飽和節點。鄰節點轉換算法如下。
算法4鄰節點轉換算法(NeighborSwith)
輸入飽和節點i
輸出生成邊(i′,j)
1) 選擇不飽和節點i′;
2) if deg(i′) == deg(i)
3) 選擇與i相連且與i′不相連的節點j;
4) 刪除邊(i,j);
5) 添加邊(i′,j);
6) end if
對一個給定節點i進行鄰節點轉換,可以在不改變當前JDM的情況下為節點i釋放一個可用端口。由于deg(i′) == deg(i),鄰接點轉換保證了JDM(deg(v),deg(w))的值不會改變。
4 實驗仿真與性能分析
本節主要通過仿真實驗來分析本文方案 BCPA的隱私保護性和數據可用性,并將其與同樣使用差分隱私機制的dK-PA方案和DRC方案進行比較。其中,dK-PA模型是直接對2K序列進行加噪處理,而另外2種模型都是基于2K序列排序聚類加噪算法。不同的是,DRC模型是基于節點度大小對 2K序列進行排序,而BCPA是基于邊中介中心性系數進行重新排序。
為了驗證本文方案是否適用于社交網絡圖結構,如表1所示,選取wiki-Vote和ego-Twitter這2個真實社交網絡數據集作為測試數據集,它們分別是維基百科who-votes-on-whom網絡數據和Twitter社交網絡數據。這2個數據集都具有以下2個顯著特征:1) 節點度的統計個數符合冪律分布;2) “小世界”的特征,更接近真實世界。
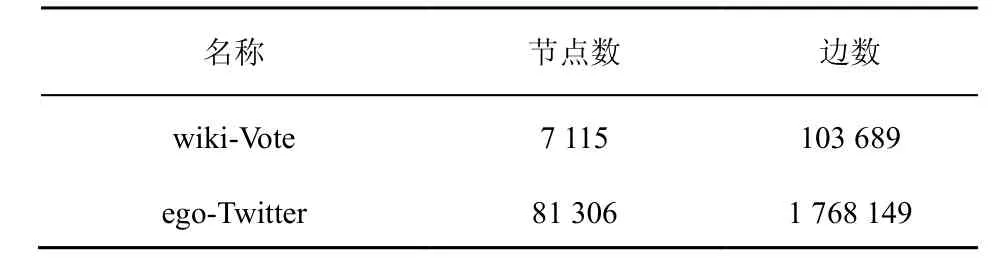
表1 測試數據集
4.1 隱私保護性評估
為了量化差分隱私保護算法對原始數據圖的具體擾動,針對社交網絡圖結構的特點,本文基于dK模型設計了一種基于鄰接度的隱私保護性衡量算法,具體如算法5所示。
算法5隱私保護性衡量算法
輸入原始圖G(V,E),擾動圖G′(V′,E′)
輸出隱私保護性P
1) 計算原始圖中的邊個數m,計算擾動圖中的邊個數m′,Ddiff= 2mmax;
2) 對于節點u,u∈G,找出與u所連接的其他節點的度,降序排列并存儲在link(u)=(d1,d2, ... ,dn),其中n表示節點u的度;
3) 反復執行步驟2)和步驟3),直至遍歷所有節點;
4) 對于節點u′,u′∈G′,找出與u′所連接的其他節點的度,降序排列并存儲在 link(u′)=(d1′,d2′, ... ,dn′′),其中n′表示節點u′的度;
5) if id(u)==id(u′)
6) 找出 link(u)和 link(u′)相同的度關系,每找出一個,則Ddiff=Ddiff-1;
7) end if
8) 反復執行步驟5)~步驟8),直至遍歷所有節點;
9) 計算隱私保護性P;
分別生成原始圖相鄰節點度序列和擾動圖相鄰節點度序列,比較2個序列,得到2個序列之間不相同的值的個數Ddiff,取原始圖的邊數量m和擾動圖的邊數量m′。
2組數據中邊數量的最大值為
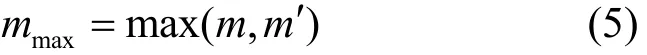
隱私保護性為

隱私保護性P的取值范圍為0~1,值越大,隱私保護程度越高。當隱私保護性P較小時,表示鄰接節點的度改變較小,此時攻擊者仍然有很大概率實施結構攻擊和度攻擊。
根據算法5,實驗分別對BCPA、DRC和dK-PA這3種方案進行了仿真,以達到比較3種算法的隱私保護效果,如圖2所示。

圖2 隱私保護性變化趨勢
由圖2可以看出,在不同ε值和不同大小的數據集中,相比于直接對2K序列進行擾動的dK-PA方案,聚類加噪的BCPA方案和DRC方案都表現出較優異的隱私保護效果。這印證了本文中的理論分析,即聚類后加噪可以更有效地利用隱私預算以達到提高隱私保護強度的作用。BCPA方案和DRC方案在不同的ε值范圍下,隱私保護效果各有優劣。無論是在體量較小的wiki-Vote網絡中,還是在體量較大的 ego-Twitter網絡中,在ε值較小的情況下(ε≤40),即隱私保護強度較高時,BCPA方案表現更好;而當ε值較大時(ε≥50),隱私保護強度較弱,此時 DRC方案的效果更勝一籌。這種結果差異性是排序算法不同造成的,2種排序算法基于不同的圖屬性重組2K序列,導致在根據加噪后的2K序列生成新圖時,新圖結構的差異在隱私保護性衡量算法中反映出來。值得注意的是,當ε值增加到一定值后(ε>90),3種方案的隱私保護效果差別較小,可見引入噪聲量較小時,3種方案的隱私保護性能差異不大。綜上,在隱私預算較小時,BCPA方案具有更高的隱私保護強度。
4.2 數據可用性評估
對于社交網絡圖數據而言,數據可用性分析主要是對社交網絡的結構特征參數進行分析。本實驗通過將原始圖與擾動圖的特征參數進行比較分析,驗證在不同的隱私預算下BCPA方案在數據可用性方面的優勢。本實驗選擇平均聚集系數、平均最短路徑和平均度分布這3個重要參數,用于衡量圖結構特征。
由于2K序列非常敏感,其需要添加高水平的噪聲以提供高級別的隱私保護。然而,非常小的ε值需要引入非常大的噪聲值,雖然隱私強度很高,但會導致產生與原始圖結構極不相似的合成圖。當ε<1時,對于較大的圖,所需的噪聲水平過高,以至dK圖生成器很難生成與所得到的dK分布匹配的合成圖。因此,為了取得較好的實驗效果,本文分別生成ε=5、ε=10和ε=100的滿足ε-差分隱私的擾動圖。
4.2.1 平均聚類系數

在社交網絡圖中,平均聚類系數的定義為其中,n為圖中節點總數,i為圖中某一節點,Ci為該節點的聚類系數。網絡的平均聚類系數可以很好地表示網絡中節點與其相鄰節點之間彼此連接的程度,即由3條邊連接三點形成的子圖三角形在當前完整網絡中的密集程度。
由圖3可知,在ε值相同的情況下,BCPA方案生成圖的平均聚類系數與原始圖更相近,而加噪的差分隱私生成圖都呈現出同樣的趨勢:即當ε值不斷減小時,生成圖的平均聚類系數逐漸增大。這是由于隱私保護需求的增大,引起更多的噪聲邊和噪聲節點的加入,三角形子圖密度增大,導致平均聚類系數值變大。

圖3 平均聚類系數柱狀圖
但即使是在ε=5的情況下,2個體量各異的真實社交網絡圖與BCPA方案生成圖之間的差異也沒有超過20%,因此,在保證較高隱私保護強度的情況下,BCPA較好地保留了原始圖屬性。
4.2.2 平均路徑長度
由于真實社交網絡圖數據滿足“小世界”特征,即圖平均路徑長度值為6左右。通過仿真實驗比較wiki-Vote網絡和 ego-Twitter網絡的平均路徑長度值與其滿足ε-差分隱私的擾動生成圖的平均路徑長度值,其結果如圖4所示。
圖4表明,2個真實社交網絡圖數據的平均路徑長度均符合“小世界”特征,而其差分隱私生成圖隨著ε值的減小,平均路徑長度也隨之變短。即,隨著ε值的減小,隱私保護需求不斷增大,所需引入的噪聲也隨之增多,添加了較大數量的擾動邊,導致節點之間的連通路徑有了更多選擇。因此,平均路徑長度隨著噪聲量的增大而不斷減小。

圖4 平均路徑長度柱狀圖
由圖4可知,對于數據量不同的2個社交網絡圖數據,BCPA加噪生成圖的平均路徑長度均更加接近于原始圖。因此,在給定隱私預算的情況下,BCPA能夠更好地保留原始圖的屬性,使擾動數據具有更好的數據可用性。
4.2.3 節點度分布
節點度分布是對一個圖中節點度數的總體描述,對于本文方案所采用的2K隨機圖而言,節點度分布就是圖中頂點度數的概率分布。節點分布對比如圖5所示。
圖 5(c)和圖 5(f)表明,當ε=100時,由于所引入的噪聲量較小,原始圖與BCPA和DRC的加噪生成圖的節點分布相差不大。而當ε=5和ε=10時,wiki-Vote網絡和ego-twitter網絡的加噪生成圖都與原始圖結構有較大差距。出現這種差異的原因是少數高度數節點連接大多數其他節點。因此,當高度數節點引入了噪聲時,它會產生向圖的其余部分傳遞波動的結構變化。可見當數據集所含節點數較多時,為實現較好的隱私保護效果,引入的大量噪聲顯著改變了圖結構。

圖5 節點度分布對比
此外,由圖5可知,在節點度分布屬性上,BCPA和DRC的效果明顯優于dK-PA,且DRC方案稍好于BCPA方案,但差距不明顯。這是由于DRC是根據節點度大小對2K序列進行聚類分組,使加噪生成圖的節點度分布更接近原始圖。而BCPA是根據中介中心性系數對2K序列進行聚類分組,在原始圖中“重要性”相同或相近的節點被聚類在同一子序列中,分組加噪時依然能保證不改變各節點的“重要性”。因此BCPA生成的差分隱私圖在平均路徑長度和平均聚類系數這2項重要屬性上保留了更多的原始圖結構特征。
5 結束語
本文針對基于差分隱私的社交網絡圖數據發布問題,提出一種基于邊介數模型的差分隱私處理方案 BCPA,該方案結合dK模型對邊序列進行聚類劃分,同時考慮到各邊在圖中的影響力程度,引入邊中介中心性系數來顯著減少2K序列敏感度。將BCPA方案與DRC和dK-PA方案進行了實驗仿真,通過對平均聚類系數、平均路徑長度以及節點度分布等指標的對比和分析,在較高隱私需求情況下,BCPA方案的隱私保護性和大部分數據可用性都優于DRC方案和dK-PA方案。下一步可進行以下2個方面的工作:1) 在本文所提算法的基礎上,進一步改進 2K序列構造算法而提升運行效率;2) 在隱私需求較高的情況下,在引入噪聲量增大的同時,保證數據可用性維持在較高水準。
