基于激活漏洞能力條件的軟件漏洞自動分類框架
2019-06-14 05:47:54王飛雪
重慶理工大學學報(自然科學) 2019年5期
王飛雪,李 芳
(1.重慶人文科技學院 計算機工程學院, 重慶 401524; 2.重慶大學 計算機學院, 重慶 400044)
隨著軟件系統的發展,軟件漏洞識別變得越來越重要[1-3]。能導致未經授權的用戶破壞系統安全策略的特定類型的缺陷稱為漏洞或安全漏洞。漏洞是信息系統安全領域的重大威脅[4]。例如,2012年,FLAME病毒攻擊了中東地區使用微軟操作系統的計算機,該病毒利用操作系統的數字簽名欺騙漏洞進行自我隱藏[5]。計算機應急響應小組稱,軟件開發中的大量漏洞是在其他系統中重復檢測到的漏洞。
目前,關于安全漏洞和缺陷分類策略分析方面的文獻較少。對影響失效再現性條件的缺陷分類的研究中,在軟件bug類型方面引入了兩個定義[6-8]:① 玻爾bug(bohr bug,BB),在測試階段容易再現的bug; ② 曼德博bug(mandel bug,MB),在測試階段難以重現的bug。BB是可預知的,其激活和錯誤傳播并不復雜。如果讓軟件在相同條件下運行, bug可以再次顯現。MB是另一種類型的軟件缺陷,具有復雜的故障激活或錯誤傳播條件,在復雜條件下觸發,且沒有規律,不容易重現。采用BB和MB分類法來解決安全性缺陷,從重現性角度分析漏洞。在本文中,具有BB和MB特征的安全漏洞分別稱為BV(bohr vulnerability)和MV(mandel vulnerability)。
對于缺陷分類,文獻[9]通過文本挖掘bug數據庫提出了一種隱藏影響bug識別方法,利用錯誤報告的文本描述來提取文本信息,文本挖掘過程中提取錯誤報告的語法信息并壓縮信息以便于操作,然后利用壓縮信息生成呈現給分類器的特征向量。文獻[10] 提出了手動分類的自動替代方法,能根據漏洞描述自動對漏洞進行分類,并使用神經網絡和樸素貝葉斯方法評估了該方法。文獻[11]中提出了一種新的軟件漏洞分類方法,該方法基于漏洞特征,包括錯誤或資源消耗的累積、嚴格的時序要求以及環境與軟件之間復雜的交互。
對于軟件缺陷分類的研究,文獻[12]中提出一種軟件缺陷檢測和分類方法,并集成數據挖掘技術對大型軟件庫中的缺陷進行識別和分類。文獻[13]提出了一種名為USES的基于文本挖掘的解決方案,用于根據故障觸發器的概念對錯誤進行分類,該方法適用于文本錯誤報告、BB和MB分類以及USES分類。由于文本中可能存在噪聲,這兩種技術無法提供準確的結果,基于錯誤報告的分類方法性能高度依賴術語選擇和噪聲消除的有效性。
針對軟件漏洞分類中存在的問題,本文提出一種軟件漏洞分類框架,它能夠有效區分BV和MV,從文本報告和漏洞代碼修復中提取特征,然后采用不同的機器學習技術(隨機森林、C4.5決策樹、Logistic回歸和樸素貝葉斯)來構建靜態模型,選擇具有最高F值(精確度和召回的加權平均值)的模型來識別未見漏洞的類別。該方法評估了從Bugzilla收集的Mozilla Firefox發布的580個發布后漏洞(發布后發生的漏洞)。結果表明:該方法可以通過C4.5決策樹獲得69%MV的F值。所提框架能夠識別風險文件,指導開發人員增加對故障部件的測試工作。
1 軟件漏洞分類框架
本文軟件漏洞分類框架包括兩個階段:訓練階段和部署階段。訓練階段將一組漏洞與漏洞報告、漏洞代碼修復和已知漏洞類別相關聯。由于所有特征可能不適合區分MV和BV,因此找到了最相關的特征。不同機器學習算法(隨機森林、C4.5決策樹、Logistic回歸和樸素貝葉斯)被用來建立適當的分類。選擇具有最高F值的分類器,并將其傳遞到部署階段。
部署階段有2個輸入:訓練階段的模型和未知類別的漏洞,用于提取對漏洞進行分類的最具辨別力特征的值。最終,確定漏洞是否屬于BV或MV類別。軟件漏洞分類框架具體過程見圖1。

圖1 軟件漏洞自動分類框架
1.1 文本特征提取
在大多數軟件問題研究中,未明確提及激活漏洞的條件,而本文研究中分析了可能與激活條件具有直接或間接關系的特征。某些特征已成功用于缺陷分類,如修復時間和嚴重性應用在分析大型OSS(開源軟件)項目的bug報告中,安全漏洞位置可以作為漏洞分類的分析維度。本文選擇4個主要維度:修復時間(time to fix,TTFX)、開發人員、安全漏洞位置和嚴重性,挖掘漏洞報告的不同部分,包括標題、描述和摘要,以方便使用Python腳本和C代碼提取特征。具有相應提取機制的特征將在以下內容中描述。
1) 修復時間(TTFX):TTFX是開發人員用于解決安全問題的時間段,可以顯示漏洞對安全缺陷管理的影響。由于MV在再現安全性故障方面比BV更復雜,因此MV可能需要比BV更長的TTFX。
提取機制:在漏洞存儲庫中,當檢測到安全性故障時,將時間記錄為報告日期(reported date,RD)。當它被修復時,時間被報告為修改日期(modified date,MD)。在MD和RD之間的時間內,漏洞已打開,該時間段包括4個任務:① 由開發人員重現安全故障;② 認識其根本原因;③ 實施和測試所提出的修復方法;④通過測試驗證修復方法。雖然MV的預期TTFX由于其性質而高于BV,但不應預先判斷比較。假設有時漏洞的TTFX可能受到其他因素的影響,例如:涉及的開發人員可能同時忙于處理大量漏洞,因此,下一個特征考慮了開發人員的角色。
2) 開發人員:此特征演示了開發人員與漏洞類型之間的關聯。具有兩個子集:開發人員數量(number of developers,NOD)和開發人員體驗(developer experience,DE)
開發人員數量:NOD衡量修復漏洞所需的安全專家人數。本文假設具有復雜激活條件的漏洞會吸引更多開發人員。
開發人員體驗:本文假設對于難以重現的安全問題,安全測試人員或專家的知識可以有效地處理類似問題,經歷過大量MV的開發人員可能比其他人能更專業地解決復雜的漏洞。
提取機制:為了識別NOD,計算編寫注釋并嘗試解決安全問題的唯一開發人員的數量。有時開發人員可能會寫1個以上的評論,本文只計算1次。提取分配了漏洞的專家開發人員(expert developer,ED)的名稱,當確定所有漏洞的ED時,檢查數據集以確定每個ED解決了多少漏洞。
3) 位置:位置維度表示漏洞出現的位置,位置可以是組件、版本、模塊或文件。提取機制:在大多數漏洞存儲庫中,明確記錄了發生安全漏洞的組件和版本。本研究中,根據文件識別系統的易受攻擊部分。版本或模塊對于統計分析來說很大,細節提取機制在1.2節中描述。
4) 嚴重性:嚴重性發現漏洞是否被利用,其后果是從用戶的角度來看嚴重程度,可以具有不同的級別,例如崩潰、數據丟失和內存泄漏。否定此特征背后的動機是實現最終用戶是否因BV和MV引起的安全故障而感知到不同的行為。提取機制:開發人員從各自的角度報告每起安全性故障的嚴重性,可以直接從漏洞數據庫的字段中提取此特征值。
1.2 代碼特征提取
以確定源代碼和漏洞類型之間的更改和修復之間的相關性定義代碼特征提取部分。代碼修復的復雜性是MV復雜性的一個主要原因,為了測量漏洞代碼修復的定量復雜度,提取了3個特征:改變文件的數量(number of changed files,NOC-F)、改變代碼行的數量(number of changed (added/deleted) line of code,NOC-LOC)和漏洞修復熵(vulnerability fix entropy,VFE)。
1) 更改文件數:在軟件系統中,大多數故障屬于少量模塊。復雜的代碼X過程需要大量的變化,識別潛在易受攻擊系統的某些部分對測試人員和質量管理人員有較大的幫助,這可以指導軟件開發團隊增加對易出現漏洞的系統部分的測試工作,從而提高下一版本中軟件的安全性,還可滿足時間和預算限制。
2) 更改代碼行的數量(添加/刪除):假設更多更改的代碼行來解決安全問題與更多的代碼復雜度相關。
3) 漏洞修復熵:要解決安全問題,可能需要更改多個文件(例如,添加和刪除)。開發人員通過許多修改來遵循修復過程并不容易。假設MV復雜性的一個原因可能與修復過程的復雜性有關,與簡單漏洞BV相比,修復復雜漏洞MV可能涉及許多文件,因此預計MV具有高熵。
提取機制:漏洞數據庫不存儲有關代碼修復的信息,本文使用Mercurial分布式源代碼管理工具(一個分布式修訂控制系統)來提取有關源代碼的信息。在本地系統復制Mozilla Firefox源代碼后下載其提交日志,然后應用文本挖掘算法將安全問題映射到已更改的文件。
尋找到數據集中的漏洞后,存儲其相關字段(如父項,日期,文件和摘要)以提取代碼特征。這種集成方法取決于開發人員的評論,在修訂控制系統中,進行了許多更改以增強系統的一部分而不解決任何安全問題。本文專注于C/C++及其頭文件,其他文件類型(如腳本和配置)將被排除在外,從而為每個有風險的文件提取代碼特征。在為數據集中的漏洞提取風險文件后,使用版本控制工具的diff命令來獲取NOC-LOC。
基于已更改文件列表及其對應的NOC-LOC,通過應用Shannon熵計算漏洞修正熵,定義為:
(1)
其中:v是1個漏洞;n是變化文件的數量;pi是特定文件i的發生概率,其被改變以修復漏洞v。當所有文件具有相同的概率值時,熵是最大的(Hn(v)=1),pi=1/n?i∈(1,2,…,n),這意味著大量的文件被改變。另一方面,當只有漏洞集中在一個文件中時,熵將是最小的(Hn(v)=0)。為了計算每個漏洞的熵,使用具有相應NOC-LOC的改變文件,然后將Shannon的熵應用于漏洞熵。漏洞熵的計算過程如下:
通過更改fileA和fileB來解決問題。在fileA中分別添加2行和刪除5行代碼,共7個變化。在fileB中添加4行和刪除1行代碼,共5個變化。為了計算每個文件的概率,將其改變的LOC除以所有更改的行(在這種情況下為12),則有p(fileA)=7/12,p(fileA)=5/12。為了標準化香農熵,將等式除以ln(n)。對于該過程,歸一化的Shannons熵是0.980 864。如果所有變化分散在12個更改行而不是2個更改行上,則漏洞x的熵變為1。
1.3 判別特征選擇與模型生成
所有維度可能沒有足夠的能力來區分BV和MV類別,這是因為不相關或冗余的特征會降低分類器的效率和性能。為了解決這個問題,使用Fisher得分(或Fisher內核)識別最相關的特征。該技術基于標準偏差和特征平均值計算分數,通過等式(2)分別計算每個特征的Fisher得分來判別維度。
(2)

在表示具有最具辨別力的漏洞特征之后,需要知道它們與漏洞類型(BV或MV)的關系,其他系統的關系可能會發生變化。模型構建器部分的目標是構建一個可以根據特征向量學習每個類的特征的分類器。
將1組具有對應類別(BV或MV)的輸入給予系統以訓練模型;然后,模型根據數據集中實例的特征來學習BV和MV特征。提供各種機器學習算法用于構建模型,每種算法對輸入數據做不同的假設,這些假設會影響分類的性能,不同的技術有不同的性能。
選擇幾種經典機器學習算法,包括隨機森林(random forest,RF)、C4.5決策樹、Logistic回歸(logistic regression,LR)和樸素貝葉斯(naive bayes,NB),在Weka工具包(懷卡托環境知識分析)中使用默認參數值實現。
類別預測器部分使用分類器來標識未見漏洞的類別。對于分類器的選擇,采用上述幾種經典學習算法中性能最優的算法來實現類別預測。通過對分類指標的分析,計算漏洞屬于BV或MV的可能性,最后選擇具有最高概率的類別。
2 實驗結果與分析
使用MFSA(mozilla foundation security advisory)解決安全問題。考慮到用戶數量(大約2.7億)和代碼行(每個版本有超過200萬LOC)數量,本研究選擇數量較大的Mozilla Firefox項目,從不同版本收集安全缺陷,以確保特定版本不會影響分類器。
軟件漏洞分析中大多數漏洞屬于以下類別:① 內存錯誤:內存故障會導致內存損壞、內存安全錯誤和內存泄漏;② 空指針:可能導致分割故障;③ 驗證初始化檢查:在沒有任何適當初始化的情況下使用資源可能導致信息泄漏或分段錯誤;④ 競爭條件:允許鎖定或鏈接系統資源;⑤ 訪問控制:操作允許獲得適當的權限以獲得對整個資源的控制。
2005年1月21日——2015年1月13日收集了MFSA中與上述類別相關的軟件漏洞。盡管假設在測試階段可以檢測到BV并將其消除,但Mozilla Firefox有非漏洞與BV相關的釋放后漏洞數量可忽略不計。一個可能的原因是大型系統的實際測試困難,或者沒有足夠的測試技術。此外,擴展或修改項目可能給系統帶來新的漏洞。在本文研究中,BV和MV的分布幾乎相似,53%和47%的漏洞分別屬于BV和MV。此外,檢測到漏洞的主要比例(725中的702個)屬于內存。BV和MV分布取決于所分析系統的性質、系統與硬件設備或與其開發的語言交互的頻率。對于使用C/C++開發的系統,由于內存由開發人員管理,所以更容易出現與內存相關的漏洞。
在提取特征值之后,判別特征選擇器部分為其計算Fisher分數,然后選擇具有大分數的排名靠前的相關特征,如表1所示。

表1 TOP判別特征
盡管MV顯示出比BV更復雜的行為,但由MV引起的感知安全性失敗與由于開發者的BV導致的安全性失敗沒有顯著差異。本文使用10折交叉驗證來進行實驗,其中數據集被分為10份,模型學習9份,評估1份,所有正確分類實例的平均值表示模型的準確性。評估指標包括準確率、精確率、召回率和F值。
準確率(Accuracy)表示正確的分類率,在本研究中表示所有漏洞中正確分類的BV和MV的數量。
(3)
精確率Precision表示正確分類到所有分類漏洞的比例作為目標類別,精度是衡量分類器有效性的重要指標。
(4)
召回率Recall也稱為檢測概率,表示正確分類的漏洞與屬于目標類別的所有實際漏洞的比例。具有高召回率的模型具有發現更多漏洞的能力。
(5)
式(3)~(5)中,TP表示被歸類為MV的漏洞數量,它們都是真正的MV;FP表示被歸類為MV的漏洞數量,它們是真正的BV;TN表示被歸類為BV的漏洞數量,它們是真正的BV;FN表示被歸類為BV的漏洞數量,它們是真正的MV。
F值表示精確度與召回率的加權調和平均值,召回率和精確度的值不可能同時較高,因此本文采用F值進行最終判斷。
(6)
不同分類算法的性能比較結果如表2所示。由于基于安全性失敗重現性的漏洞分類沒有相關工作,將結果與缺陷分類研究結果進行比較,將其分為BB和MB。
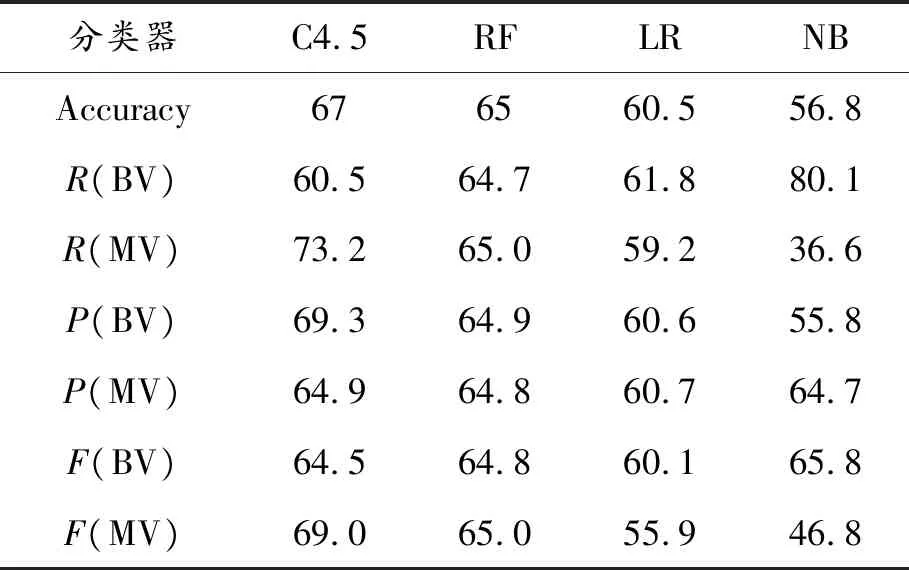
表2 不同分類算法的性能比較 %
所有分類算法的準確度均超過56.8%,表示基于文本報告和代碼修復定義度量的效率。具有67%準確度的C4.5決策樹,可以識別69%的MV。在漏洞分類中,將BV錯誤地視為MV相比不檢測MV更好,因為它們可以保留在系統中并導致嚴重的安全故障。
因此得出結論,決策樹方法在準確性和F值方面比其他方法獲得了更好的結果。主要原因在于其簡單性和對數據集中噪聲的魯棒性。具有67%準確度的C4.5決策樹可以識別69%的MV。由此認為,在漏洞分類中,將BV錯誤地視為MV相比檢測不到MV更好,因為BV在系統中將導致嚴重的安全故障。
為了體現本文方法的有效性,將本文算法與文獻[13]基于自然語言描述分析缺陷方法進行比較。分類器使用C4.5,實驗數據庫為Redhat Bugzilla數據集,結果見表3。

表3 不同軟件漏洞算法的性能比較 %
從表中數據可得:無論機器學習方法的類型如何,根據文本錯誤報告,文獻[13]計算的F值范圍為29.8%~61.5%,而本文方法獲得MV的F值在48.3%~70.7%范圍內,說明了本文方法的有效性。
3 結束語
本文提出一種自動軟件漏洞分類框架以區分BV和MV。該方法基于文本報告和代碼修復定義一組特征,使用不同的機器學習技術來構建分類器,選擇具有最高F值的分類器實現分類判別。解決方案對Mozilla Firefox項目收集的580個漏洞進行了評估。結果顯示,具有十折交叉實驗結果的C4.5決策樹實現了最高的F值(69%)識別不可見漏洞類別。此外,該框架能夠檢測包含BV和MV的文件。與其他方法相比,本文方法在準確性和MV識別性能方面優于現有方法,證明了本文方法的有效性。在下一步工作中,將根據軟件復雜性指標研究BV和MV特征。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
