基于大數據技術的數據倉庫體系結構設計
2019-06-15 01:01:22姚鵬飛
數字技術與應用 2019年3期
關鍵詞:大數據
姚鵬飛
摘要:大數據時代,數據結構的復雜性和數據體量的劇增使得傳統數據倉庫體系結構已經不能滿足數據處理的需要。本文在對傳統數據倉庫體系結構相關理論研究的基礎上,重點分析了傳統數據倉庫體系結構存在的不足以及大數據的特征和對數據處理的新需求,構建了基于大數據技術的數據倉庫體系結構,采用目前流行的Hadoop/Spark大數據處理技術架構,實現半結構化數據和非結構化數據的收集、處理、存儲和分析挖掘,彌補了傳統數據倉庫在海量數據處理、存儲方面的不足,有效解決數據利用率低、價值發揮不明顯的問題。
關鍵詞:大數據;數據倉庫;體系結構
中圖分類號:TP311.13 文獻標識碼:A 文章編號:1007-9416(2019)03-0141-03
0 引言
隨著數據量的急劇增長,傳統的數據倉庫應用已經難以滿足聯機分析處理對數據倉庫提出的新需求[1],數據處理的實時性要求和數據結構的多元化、非結構化使得傳統數據倉庫的性能瓶頸逐漸顯現。大數據、云計算等新技術以其強大和高效的存儲和計算能力正在成為海量數據管理的經濟有效方式[11]。在數據應用領域,隨著各類系統復雜性的不斷增強,數據總量正逐年以指數形式上漲,且數據類型超越了傳統數據庫所能處理的范疇。如何將這些數據進行收集、整理并加以分析、應用成為研究熱點。傳統的數據倉庫由于處理數據格式有限、計算能力擴展困難,已經不能滿足數據處理需要,尋求新的數據倉庫解決方案成為當務之急。大數據技術能夠極大拓展數據的收集能力,提升數據的綜合分析處理能力。本文基于大數據技術構建數據倉庫體系結構,將大數據和數據倉庫技術進行結合,采用目前流行的大數據架構Hadoop/Spark,充分借鑒其低成本、高性能、高可靠性和可擴展的特點,以期實現對數據的采集、處理、存儲和深度挖掘分析,有效發揮數據價值。
1 傳統數據倉庫技術架構面臨的挑戰
1.1 傳統數據倉庫技術架構
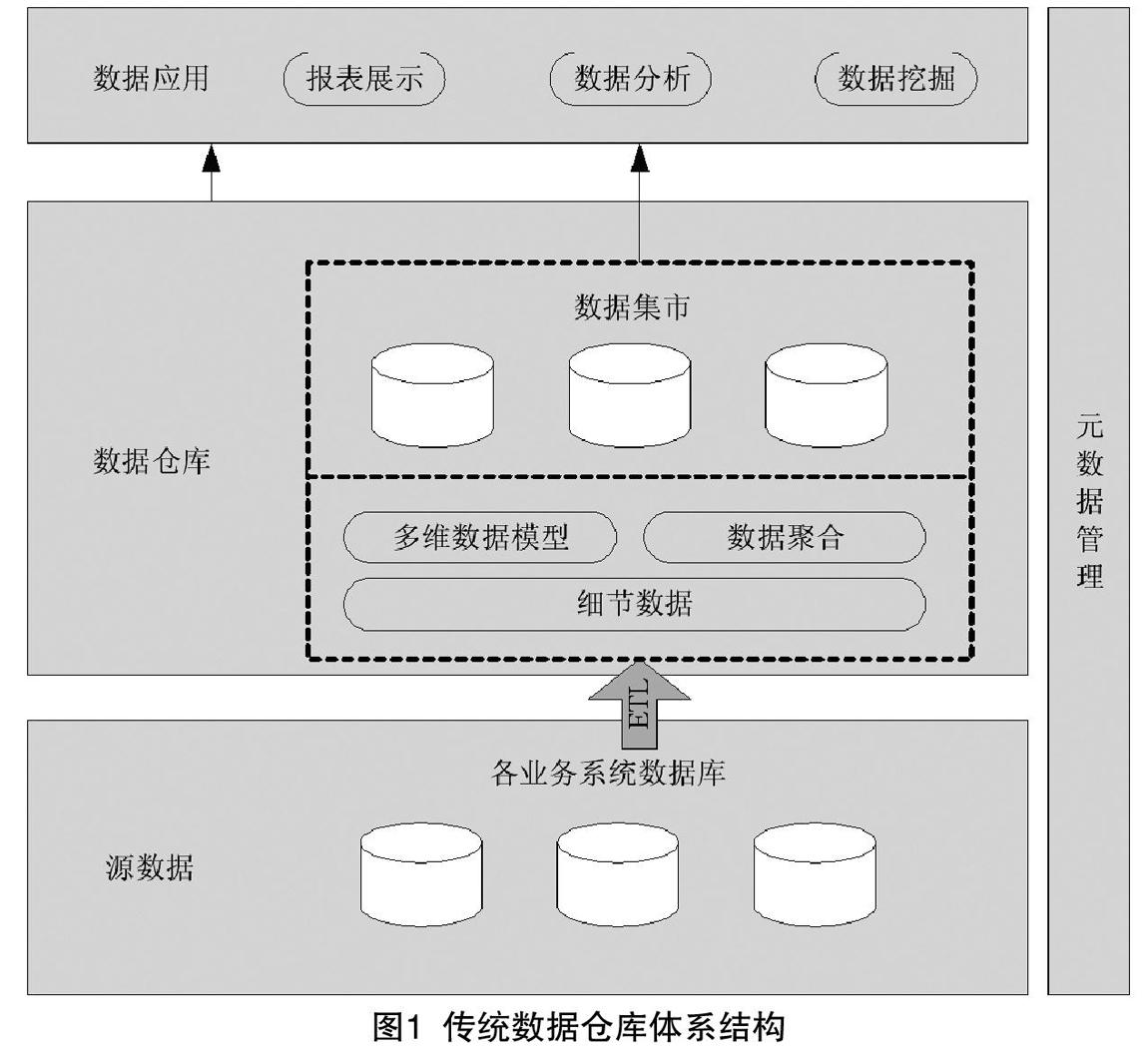
數據倉庫是以數據庫技術為核心,涉及元數據、數據挖掘、數據展現等多技術領域的綜合應用[10]。傳統數據倉庫按層次劃分,主要包含源數據層、數據倉庫層、數據應用層三部分。傳統數據倉庫體系結構如圖1所示。
(1)源數據層。傳統數據倉庫的數據來源主要是從各個業務系統抽取的數據。按照數據倉庫數據結構和編碼格式對源數據進行抽取、清洗、轉換和加載。
(2)數據倉庫層。傳統數據倉庫主要存儲的是經過ETL(Extract /Transformation /Load)處理后的結構化數據,且是按照數據的主題進行分類存儲。主要的存儲方式包括:多維數據庫、關系型數據庫及兩者相結合的方式[2]。傳統數據倉庫基于維護細節數據基礎,使其能夠真正應用于分析。聚合數據指的是基于特定需求的簡單聚合,多維數據模型提供了多角度多層次的分析應用,可以實現在各時間維度和地域維度的交叉查詢[3]。除此之外,數據倉庫中還存儲元數據,描述數據倉庫的數據信息及輔助用戶使用和了解數據倉庫的數據信息。
(3)數據應用層。數據應用層的核心是聯機分析處理OLAP(On-Line Analysis Processing),主要包含報表展示、數據分析和數據挖掘,為決策者提供多維度數據[9]。聯機分析處理從多維度、多角度對數據進行分析,系統深入挖掘數據背后的關聯,從而輔助用戶決策。
(4)元數據管理。元數據能支持系統對數據的管理和維護,是進行數據集成的基礎,主要存儲了原始數據和數據倉庫中數據的對應關系以及校驗、轉換、過濾的規則等信息[4]。元數據是建設數據倉庫必需的最主要、最根本和最基礎的描述元素[12]。通過對元數據的統一維護,可以實現各業務信息系統之間信息交互,避免出現“數據孤島”現象。另外,元數據提供了數據訪問的接口,幫助進行數據檢索和數據挖掘。
1.2 存在的主要問題
(1)傳統數據倉庫架構基本以三層架構為主,采用單點服務器結構,一方面,對分布式并行計算模式的支持力度不夠,難以實現處理能力水平拓展,往往需要通過對服務器等硬件的升級改造來實現處理性能提升,升級改造成本相對較高,且服務器等硬件性能升級周期較長[5]。另一方面,采用單點服務器結構經常會遇到單點故障和I/O處理性能瓶頸等問題,計算能力和存儲能力相對較弱。
(2)由于地域、型號等因素影響,數據應用系統種類繁多、形式多樣,在單個數據倉庫系統處理性能有限的狀況下,普遍存在獨自建設,導致“煙囪”式建設現象嚴重,缺乏統一的頂層設計和籌劃規劃,各個數據倉庫系統間界限劃分不合理,口徑不一致,存在數據的重復加工問題。
(3)傳統數據倉庫主要面向數據分析型應用設計,在數據的實時處理方面不足,無法適應高并發、低延遲等應用場景需要,難以滿足實時分析處理需求。
(4)傳統數據倉庫主要處理的是結構化數據,通過從各類關系型數據庫系統抽取數據實現數據集成。在大數據背景下,非結構化數據、半結構化數據大量出現,占到數據總量的90%以上,傳統數據倉庫架構不支持HBase、NoSQL等數據庫,在處理各類非結構化數據和半結構化數據方面能力不足,不能實現對各類數據的完全覆蓋。
2 數據特征及新處理需求
隨著數據采集方式的多樣化,數據積累體量將呈指數級增長,傳統的存儲手段、計算能力已經不能滿足海量數據的存儲和分析。此外,云計算、大數據等相關技術快速發展,數據的存儲和分析能力得到了前所未有的提升,通過海量數據處理、多樣本分析、超實時計算和復雜模型解算實現數據價值深度挖掘、開發各類數據產品已經成為對數據處理的新需求。
大數據時代,數據處理的模式主要包括:“離線批處理式數據處理”,“查詢式數據處理”以及“實時式數據處理”三種模式[7]。按照以上數據處理模式,基于大數據的數據倉庫采用Hadoop/Spark架構,可以有效彌補傳統數據倉庫在海量數據處理、數據存儲等方面的不足,有效解決傳統數據倉庫平臺處理能力不足的問題。基于大數據技術構建的數據倉庫可以實現彈性擴容和資源隔離,縮短統計分析響應時間,通過統一資源調度管理平臺,減少數據復制導致的時間開銷和多個應用數據庫獨立部署帶來冗余的數據存儲成本。另外,可以實現對數據的有效管控和數據標準的實施,實現數據質量管理。Hadoop是一個開源的、可運行于大規模集群之上的分布式計算平臺,通過實現MapReduce計算模型和分布式文件系統HDFS(Hadoop Distributed File System),并且可以通過橫向擴展實現計算能力和存儲能力的大幅提升,可以實現對離線的、處理實時性要求不高的海量數據的存儲與處理分析工作[8]。Spark是基于內存計算的大數據并行計算框架,可以有效減少迭代計算時的I/O開銷,實現對數據的實時分析和處理。
3 基于大數據的數據倉庫體系架構設計
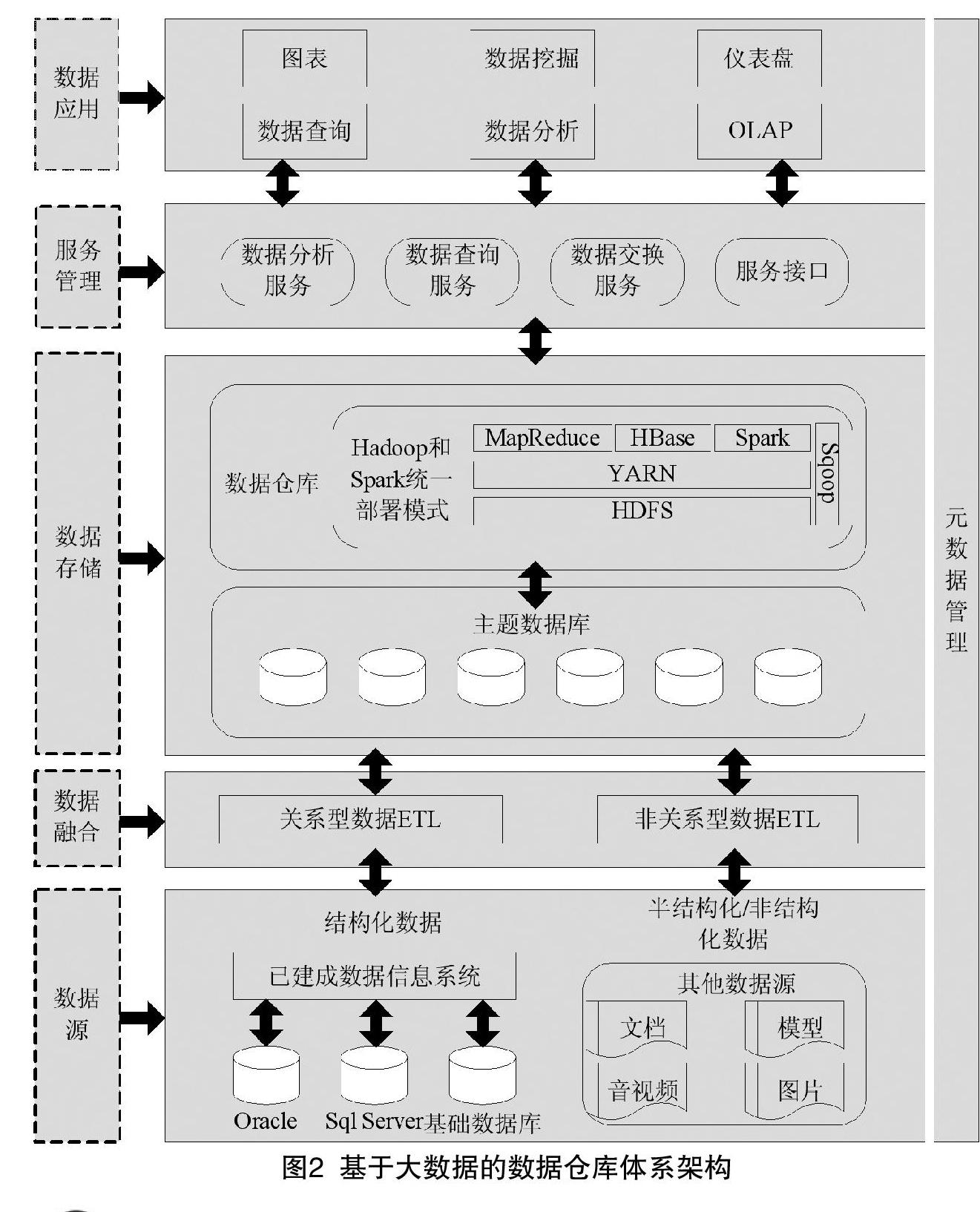
基于大數據的數據倉庫體系架構采用柔性架構設計理念和分層設計思想,綜合運用Hadoop/Spark為代表的大規模數據處理技術和傳統數據倉庫的特點,采用組件化、模塊化、服務化的方式進行設計,體系結構的主要內容以及相互之間的邏輯關系如圖2所示。
(1)數據源部分。目前,試驗數據應用領域,已建成的信息系統主要采用Oracle、SqlServer、基礎數據庫,除此之外,與相關的文檔、模型數據、音視頻數據、圖片數據等,大多數以非結構化或半結構化數據形式存在。相比傳統數據倉庫體系結構而言,基于大數據的數據倉庫不僅能實現對結構化數據的處理,還能實現對半結構化及非結構化數據的處理。
(2)數據融合部分。分為兩部分,對于關系型數據,按照主題數據庫的分類進行抽取、轉換,加載到主題數據庫中。對于非關系型數據,按照指定的元數據、數據結構、數據編碼、數據定義、鍵結構和數據物理特征等進行數據抽取和轉換,加載到主題數據庫,為后續的統計、分析、挖掘業務提供標準化、規范化的數據資源。
(3)數據存儲部分。主題數據庫中按照不同的主題對數據進行分類存放,主題數據庫為數據倉庫提供數據來源。數據倉庫采用Hadoop和Spark統一部署模式架構,具有高模塊化、松耦合特點,利用其先進的并行計算框架和資源調度框架,彌補傳統數據庫的局限,支持SQL標準數據庫語言及Oracle、DB2、MySQL、SQLServer等多種傳統應用數據庫。MapReduce、Spark在資源管理框架YARN之上部署和運行,可以有效實現計算資源按需伸縮、共享底層存儲,避免數據跨集群遷移。根據不同應用場景,實現資源調度和數據處理工作。對于據數據處理速度及分析響應要求高的數據處理場景,采用Spark處理架構實現實時處理,對于數據處理速度及分析響應要求不高的數據處理場景,采用MapReduce架構實現批處理。Sqoop組件主要用來實現Hadoop和主題數據庫之間的數據交換,完成關系型數據庫到Hadoop平臺的數據遷移工作。
(4)服務管理部分。實現對各種服務的管理,主要包括數據分析服務、數據查詢服務、數據交換服務和數據服務接口,以組件化、模塊化的方式,為實現數據挖掘分析及綜合展現提供服務支持。
(5)數據應用部分。主要包含數據查詢、數據分析、數據挖掘、OLAP等數據應用,并將查詢及挖掘結果以圖表、儀表盤等可視化方式進行展現。
(6)元數據管理部分。元數據(Meta Date),即數據的數據。主要描述數據倉庫中各種模型的定義、各層級間的映射關系、數據倉庫的數據狀態信息,通過元數據庫實現統一存儲和管理。
4 結語
長期以來,由于在數據融合、數據挖掘等方面缺乏必要的技術手段支持,數據的效益沒有得到有效發揮。本文通過分析傳統數據倉庫在處理大數據方面的不足,結合大數據時代數據處理的新需求,研究構建基于大數據技術的數據倉庫體系結構,以期實現數據的高效管理和快速處理分析。
參考文獻
[1] 吳黎兵,邱 鑫,葉璐瑤,等.基于Hadoop的SQL查詢引擎性能研究[J].華中師范大學學報(自然科學版),2016,50(2):174-182.
[2] 瞿志凱,張婷.基于大數據的反恐情報數據倉庫體系結構設計[J].情報雜志,2016,35(2):30-36.
[3] 費仕憶.Hadoop大數據平臺與傳統數據倉庫的協作研究[D].上海:東華大學,2014.
[4] 張鶴.元數據在圖書館信息管理中的應用研究[J].北京印刷學院學報,2017,25(4):60-62.
[5] 趙毅.基于大數據平臺構建數據倉庫的研究與實踐[J].中國金融電腦,2017(05):37-42.
[6] 龔昕,周大慶,鞠亮,等.武器數據工程理論與實踐[M].北京:國防工業出版社,2017:20-30.
[7] 李貞強,陳康,武永衛,等.大數據處理模式—系統結構,方法以及發展趨勢[J].小型微型計算機系統,2015,4(4):641-646.
[8] 林子雨.大數據技術原理與應用[M].北京:人民郵電出版社,2017:184-187.
[9] 寧兆龍,孔祥杰.大數據導論[M].北京:科學出版社,2017:34-40.
[10] 于鵑.數據倉庫與大數據融合的探討[J].電信科學,2015,66(1):66-71.
[11] 王緩緩,郭敬義,張警燦,等.基于Hadoop的數據倉庫構建模式研究[J].重慶理工大學學報(自然科學版),2015,29(7):69-73.
[12] 黨懷義.典型大數據倉庫-飛行試驗數據倉庫設計[J].計算機測量與控制,2015,23(4):1407-1413.
Research on Data Warehouse Architecture Based on Big Data Technology
YAO Peng-fei
(Army of 92493,Huludao Liaoning? 125000)
Abstract:In the age of big data,the complexity of data structure and the sharp increase of data volume make the traditional data warehouse architecture connot meet the needs of data processing.This paper is based on the theoretical research of traditional data warehouse architecture, shortcomings of traditional data warehouse architecture and characteristics of data and new requirements for data process are emphatically analyzed,the system architecture of data warehouse based on big data technology is constructed,adopt the currently popular hadoop/spark big data process technology architecture,realizes the collection,processing,storage ,analysis and mining of semi-structured and unstructured data , makes up for the deficiency of traditional data warehouse in mass data processing and storage,this way can solve the problem of low utilization of data and unobvious value.
Key words:big data;data warehouse;architecture
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
