一種能“讀心”的助聽器, 精準放大嘈雜環境中你想聽的聲音
2019-06-25 02:58:57
海外星云 2019年11期
關鍵詞:研究
在嘈雜的環境中,比如擁擠的咖啡店或繁忙的城市街道,我們的大腦有著非凡的本領,能夠分辨出某一個人的聲音。即使是最先進的助聽器,也難以做到這一點。但是現在,哥倫比亞大學的工程師開發了一項新的AI技術,能夠精準放大群體內發出的某種聲音,這項突破性的技術進展也有望促進新型助聽器的開發。
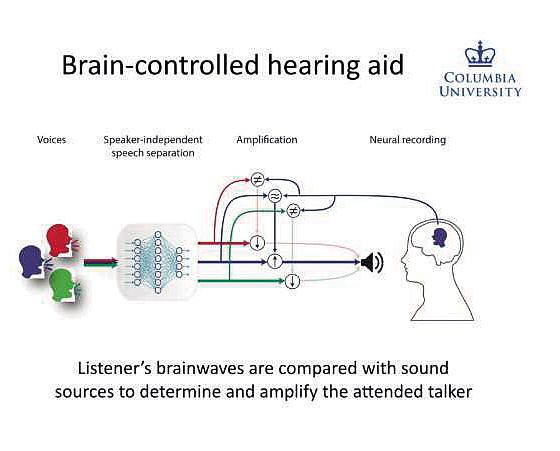
研究人員開發的這項實驗技術,能夠模擬大腦探測和放大多個聲音中任意一個聲音的天生能力,并且研究人員開發出一種由大腦控制的,可以“讀心”的助聽器,就像一個聲音自動過濾器,監測佩戴者的腦電波,并放大他們想要聽到的聲音。
雖然這項技術仍處于早期發展階段,但其意義仍極為重要,不僅有助于人們開發更好的助聽器,而且能夠幫助佩戴者跟周圍的人進行無縫、高效的交談。相關成果發表在近日的Science Advances(《科學進展》)中。
“負責處理聲音的大腦區域極其敏感和強大,它似乎可以毫不費力地放大一個聲音,而當前的助聽器與之相比則相形見絀。”哥倫比亞大學莫蒂默·祖克曼大腦行為研究所學術帶頭人、哥倫比亞大學工程學院副教授Nima Mesgarani是該論文的通訊作者,他表示,“通過創造一種能夠模擬大腦本身能力的設備,我們希望我們的工作將促進技術的進步,使全世界數億聽力受損的人能夠像他們的朋友和家人一樣輕松地與人交流。”
現代助聽器在放大語音的同時,在抑制某些類型的背景噪音(如交通噪音)方面非常出色,但它們難以提高多個聲音中其中一個聲音的音量。這個問題跟喧鬧的派對中混在一起的嘈雜聲音類似,所以科學家們稱之為雞尾酒會問題,而在擁擠嘈雜的地方,傳統的助聽器也會同時放大所有聲音,嚴重阻礙佩戴者的有效交談能力。而這次研究人員開發的腦控助聽器,不僅僅依靠像麥克風這樣的外部聲音放大器,還能夠監測傾聽者自身的腦電波,此前研究人員已經發現當兩個人互相交談時,說話者的腦電波開始類似于傾聽者的腦電波。
利用這些知識,研究小組將強大的語音分離算法與模仿大腦自然計算能力的神經網絡相結合,創造了一個系統。這個系統首先從一個群體中分離出單個說話者的聲音,然后將每個說話者的聲音與傾聽者的腦電波進行比較。如果說話者的聲音模式最接近傾聽者的腦電波,那么這個聲音就被放大。研究人員在2017年發表了這個系統的早期版本,在當時雖然這一實驗很有希望,但有一個關鍵的限制:它必須通過預先訓練來識別特定的說話者,現在的版本很大程度上解決了這個問題。
在哥倫比亞科技投資公司的資助下,團隊改進了他們的原始算法,Mesgarani博士、第一作者Cong Han以及James O'Sullivan博士再次利用深度神經網絡的力量,建立了一個更復雜的模型,可以推廣到聽者遇到的任何潛在的說話者。研究人員最終開發出一個語音分離算法,與以前的版本相比,運行方式類似但有重要的改進,可以立刻識別并解碼任何聲音。
為了測試最新算法的有效性,研究人員與論文的合著者、醫學博士Ashesh Dinesh Mehta合作,Mehta也是醫療集團Northwell Health的神經外科醫生,他對癲癇病人進行治療,這些病人中的一些人必須接受常規手術。研究人員在病人的大腦內植入了電極,在這些病人傾聽不同的說話者說話時,可以通過這些電極監測他們的腦電波,然后使用新開發的算法計算這些數據。當病人聽以前沒有聽過的演講者說話時,研究小組的算法會跟蹤病人的注意力。當病人把注意力集中在一個說話者身上時,系統會自動放大那個聲音。當他們的注意力轉移到另一個說話者身上時,音量水平就會發生變化,以反映這一轉變。

Mesgrani 博士
受到研究結果的鼓舞,研究人員正在嘗試將這個原型轉變成一個可以放置在頭皮或耳朵周圍的非侵入性設備。他們還希望進一步改進和完善算法,使其能夠在更廣泛的環境中運用。到目前為止,研究人員還只在室內環境中進行了測試,但研究人員希望它能在繁忙的城市街道或嘈雜的餐廳里同樣有效,這樣無論佩戴者走到哪里,他們都能充分體驗周圍的世界和人們。
(摘自美《深科技》)(編輯/華生)
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
遼金歷史與考古(2019年0期)2020-01-06 07:45:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年11期)2018-08-04 03:26:04
汽車工程學報(2017年2期)2017-07-05 08:13:02
國際商務財會(2017年8期)2017-06-21 06:14:14
電子制作(2017年23期)2017-02-02 07:17:19
海外星云 2019年11期