個人貸款違約預測模型研究
2019-07-03 09:42:32馮寧
現代商貿工業 2019年17期
馮寧

摘?要:隨著全球經濟的快速發展以及資本市場的壟斷,無論是企業的發展還是人們超前消費觀念的提前到來,貸款已成為企業和個人解決經濟問題的一種重要手段。對于銀行業或者小貸機構而言,信用卡以及信貸服務是高風險和高收益的業務,如何通過用戶的海量數據挖掘出用戶潛在的信息即信用評分,并參與審批業務的決策從而提高了風險防控措施,該過程不僅提高了業務的審批效率而且給予了關鍵的決策,同時風險防控如果沒有監測到位,對于銀行業來說會造成不可估量的損失,因此這部分的工作是至關重要的。通過某銀行脫敏的信用卡客戶數據,通過建立現階段比較熱門的機器學習Logistic模型來研究客戶信用的關鍵指標對模型的作用,從而對信用卡用戶的違約情況進行提前預測分析。個人貸款違約預測模型的建立以及后期的關鍵指標的探索,在銀行業或者小貸機構的貸前審批以及貸中的管理決策中都有很好的指導作用,并且具有很強的實踐性和意義。
關鍵詞:python;Logistic模型;違約
中圖分類號:D9?????文獻標識碼:A??????doi:10.19311/j.cnki.1672-3198.2019.17.080
1?引言
本文建立個人貸款違約預測模型的目的是利用銀行脫敏的數據進行描述性統計分析,來提前預測客戶在貸款期間的違約概率,從而幫助銀行的業務人員明確客戶的更多有意義的指標變量,及早發現貸款的潛在損失。本章主要對項目的背景與選題來源,國內外發展狀況,以及研究意義和目的,相關研究成果進行大致說明,并討論了創新點。
1.1?項目背景與選題來源
目前,在經濟快速發展的時代,貸款的風險審批是商業銀行面臨的首要問題。貸款中風險的產生,不僅在貸款審查階段出現,而且貫穿整個貸款流程中:在實際貸款審批流程中,大多數的審貸過程并非十分嚴謹和周全,因此不良貸款的概率會日漸飆升,在這樣的背景下,建立一個科學有效、有解釋力度的模型對貸款客戶的信用進行評估與判定,從而將違約的風險降到最低并將利潤最大化是刻不容緩的事情。對信用風險的識別與防控是商業銀行風險管理研究的重要內容,是金融機構不可回避的核心問題,也是各國政府與金融機構風險管理的焦點。因此,為了更好解決風險管理中的問題,本文涉及的數據包含銀行客戶的交易數據,而且涉及大部分貸款信息與眾多信用卡的數據,通過分析這些數據可以獲取與銀行服務相關的業務知識,例如,提供增值服務的銀行客戶經理,希望明確客戶有更多的業務需求,而風險管理的業務人員可以及早發現貸款的潛在損失。
1.2?國內外發展現狀
21世紀大數據信息和互聯網金融得到了前所未有的巨大發展,個人消費經濟市場空間也得到了拓展,與此同時,人們提前消費經濟觀念的轉變導致全球個人信貸規模急劇擴大,我國的一些大城市居民債務比率已經達到甚至超過美國等發達國家的平均水平,為有效應對這一趨勢的發展,我國已經采取措施對商業銀行加強信用風險管理,并改進管理技術。截至2006年底我國已經全面實現了金融業對外開放,面對全球的激烈競爭,我國若想要保住全球的經濟地位并使之發揚壯大,需要自身依靠內部評級體系的建設和發展。然而近幾年,我國涌現出了很多研究數據科學的高端人才,對于模型的建立和探索已經在國內外取得了不小的成就,在未來的數據科學以及商業應用中,預測模型也會應用到我們生活中的方方面面,并且會得到空前的發展和巨大的進步。
1.3?本論文的創新點
相較于傳統模型而言,本文采用了機器學習中的邏輯回歸模型(logistic regression),該模型是基于現階段國內外發展狀況和項目背景以及相關業務場景的探索研究,該模型屬于概率型非線性回歸模型,它是研究二分類觀察結果(被解釋變量)與一些影響因素(解釋變量)之間關系的一種多變量分析方法。如果用線性回歸分析,由于應變量Y是一個二值變量(通常取值1或0),不滿足應用條件,尤其當各因素都處于低水平或高水平時,預測值Y值可能超出0~1范圍,出現不合理都現象。用logistic回歸分析則可以較好的解決上述問題。
2?相關技術介紹
數據科學是一個發現和解釋數據中的模式,并用于解決問題的過程。
2.1?數據科學過程
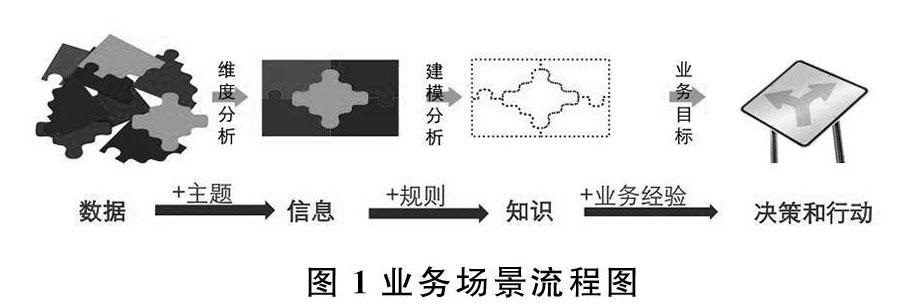
數據科學中的過程,主要分為以下幾個步驟:相關數據和主題結合生成信息,信息通過規則的加工生成知識,知識通過業務經驗的豐富生成相關管理人員的決策和行動,這些步驟在業務場景中的流程如圖1所示。
2.2?模型的實際應用過程
分析建模人員通過分析數據建立模型,在該過程中主要是找出隱藏在數據背后的模式,這些模式能把數據轉化為知識,而這些已發現的知識就是我們所謂的模型,業務人員把模型用在實際數據上,從而預測未來的行為,在這個過程中主要是部署,即應用已發現的知識達成實用的目的。
2.3?數據科學實施路線圖
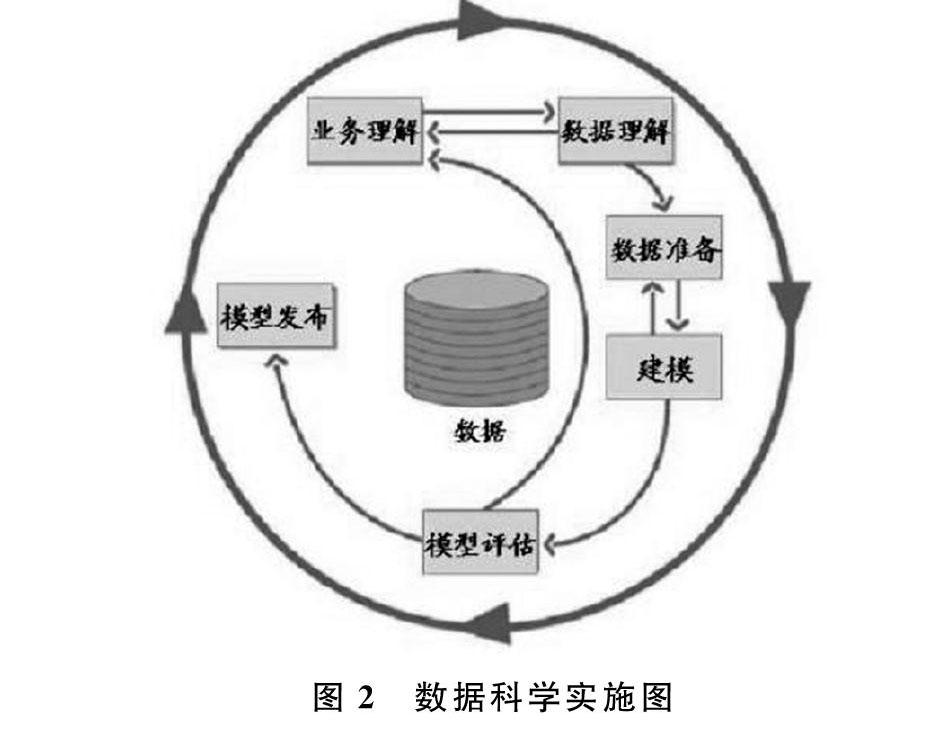
在數據科學中,數據挖掘的實施路線圖貫穿整個數據建過程中,如圖2所示為數據科學實施路線圖。
3?個人貸款違約預測模型的創新點介紹
個人貸款違約預測模型的建立包括:業務理解、數據獲取、數據清洗與處理、數據建模等過程,每個過程的創新點在后面會展開討論。
3.1?業務理解
業務理解是數據建模中關鍵的環節,若業務理解不到位則直接關系到業務目標的偏離,從而導致最后的模型預測不準確,不僅浪費較長的時間人力成本,而且會對公司的經營狀況造成巨大的損失,因此好的業務理解對數據建模起到關鍵性的作用。
本文涉及的數據業務是在銀行場景下進行個人客戶業務分析和數據挖掘進行的,筆者希望明確哪些客戶有更多的業務需求,而風險管理的業務人員可以及早發現貸款的潛在損失,那么根據客戶的貸款屬性、交易信息、狀態信息怎樣預測客戶的貸款違約行為呢?這是本文需要重點探索的問題。
而拆分這些數據的指標,我們可以分為三大類:屬性、狀態、行為信息,而這三大類指標對建模的特征變量的篩選有重要的指導意義。整理這些變量通常會與兩個指標變量息息相關-還款意愿和還款能力指標,而在貸款審批前業務人員會重點關注其還款意愿情況,若客戶得到的收益高于成本,則客戶的還款意愿不足,從而導致違約;在貸款后業務人員會關注客戶還款能力情況,若客戶的經濟條件惡化,從而導致違約,而還款能力不足包括欲望大于能力,生活狀態不穩定等情況。而描述這些還款指標的變量基本都是衍生變量,而這些衍生變量分為:
一級衍生變量,比如資產余額;二級衍生變量,比如資產余額的波動率、平均資產余額;三級衍生變量,比如資產余額的變異系數等。因此在接下來的章節中將詳細闡述這些變量提取的過程。
3.2?數據獲取
本案例的數據來自一家銀行的真實客戶與交易數據,設計客戶主記錄、賬號、交易、業務和信用卡、地區等數據,下面分別介紹這幾張數據庫表的重要字段。
貸款表(Loans):該表記錄每個賬戶上的一條貸款信息,包括以下字段:權限號(disp_id)、貸款號(loan_id)、賬戶號(accout_id)、發放貸款日期(date)、貸款金額(amount)、貸款期限(duration)、每月歸還額(payments)、還款狀態(status)。其中還款狀態A代表合同終止,沒問題;B代表合同終止,貸款沒有支付;C代表合同處于執行期,至今正常;D代表合同處于執行期,欠債狀態。
賬戶表(Account):該表記錄賬戶相關信息,包括以下字段:賬戶號(account_id)、開戶分行地區號(district_id)、開戶日期(date)、結算頻度(frequency)。
客戶信息表(Clients):該表記錄客戶的基礎屬性相關信息,包括以下字段:客戶號(client_id)、性別(sex)、出身日期(birth_date)、地區號(district_id)。
權限分配表(Disp):該表每條記錄描述了客戶和賬戶之間的關系,以及客戶操作賬戶的權限,包括以下字段:權限設置號(disp_id)、客戶號(client_id)、賬戶號(account_id)、權限類型(type)。其中權限類型字段中只有“所有者”身份可以進行增殖業務操作和貸款。
支付命令表(Orders):該表每條記錄描述了一個支付命令,包括以下字段:訂單號(order_id)、發起訂單的賬單號(account_id)、收款銀行(bank_to)、收款客戶號(account_to)、欠款金額(amount)等。
交易表(Trans):該表每條記錄代表每個賬戶上的一條記錄,包括以下字段:交易序號(trans_id)、發起交易的賬戶號(account_id)、交易日期(date)、借貸類型(type)、交易類型(operation)、欠款金額(amount)、賬戶余額(balance)等。
信用卡表(Cards):該表每條記錄描述了一個賬戶上的信用卡信息,包括以下字段:信用卡ID(card_id)、賬戶權限號(disp_id)、卡類型(type)、issued(發卡信息)。
人口地區統計表(District):該表記錄描述了一個地區的人口統計學信息,包括以下字段:地區號(A1)、GDP總量(GDP)等。
其中各表與表之間的聯系即E-R圖如圖3所示。
3.3?數據清洗與處理
數據清洗與處理是數據建模中重要環節,如果源數據不經過處理以及處理不夠精確,則會直接影響模型的預測準確度。本小節主要介紹該案例背后的數據處理的相關過程以及代碼實現的小細節。
(1)首先需要對貸款違約預測模型的被解釋變量Y值定義違約和非違約的狀態,通過數據獲取章節中的貸款表可知,狀態為B和D為違約狀態,C為未知狀態,D為正常狀態,因此對貸款表新增解釋變量Y值字段bad_good,實現的相關代碼如下:
Loans[‘bad_good]?= loans.status.map({"B":1,"D":1,"C":0,"A":2})
(2)由于貸款信息需要知道詳細貸款人的基礎屬性信息,因此需要將loans表和用戶clients表進行連接,但是中間需要權限表disp表建立中間橋梁進行連接,并且只有權限為“所有者”的用戶才能操作所有相關的表:
df = pd.merge(loans,disp,on="account_id",how="left")
df = pd.merge(df,clients,on="client_id",how="left")
df = df[df.type==”所有者”]
(3)由于對取數的時間有要求,因此需要對現有的時間格式進行轉換,方便后續計算:
df2["date"]?= pd.to_datetime(df2["date"])
df2["date_trans"]?= pd.to_datetime(df2["date_trans"])
(4)對于動態數據,其觀察期的取數窗口的規則是交易日期在貸款日期之前,并且交易日期在貸款日期前一年的時間內:
import datetime
df3=df2[df2.date-datetime.timedelta(days=365) [df2.date_trans (5)由于賬戶余額和貸款金額為無法正確計算的字符串,需要對字符串進行清洗處理得到數值形式,對于每個賬戶的交易類型,有兩種情況,‘借代表支出,‘貸代表收入,需要將收入和支出標準化,方便后續計算: df2["amount1"]=df2["amount"].map(lambdax:int("".join(x[1:].split(",")))) df2["balance1"]=df2["balance"].map(lambdax:int("".join(x[1:].split(",")))) 3.4?數據建模 數據建模是模型建立的最后一個環節,該過程包括數據特征變量的篩選和模型的選取。 3.4.1?特征變量的選取 (1)賬戶余額的變異系數:賬戶的平均余額/賬戶的標準差。 df4=df3.groupby("account_id")["balance1"].agg(["mean","std"]) .reset_index() df4["cv_balance"]?= df4.apply(lambda x:x[2]/x[1],axis=1) (2)賬戶的平均收入和平均支出: df5=df3.groupby(["account_id","type1"]).balance1.sum().unstack() .reset_index().fillna(0) df5["r_out_in"]?= df5.apply(lambda x:x[2]/x[1],axis=1) (3)貸存比和貸收比:貸存比=貸款總額/平均余額、貸收比=貸款總額/總收入 df6 = pd.merge(df1,df4,on="account_id",how="left") df7 = pd.merge(df6,df5,on="account_id",how="left") df7["r_lb"]?= df7[["amount","avg_balance"]].apply(lambdax: x[0]/x[1],axis=1) df7["r_lincome"]?= df7[["amount","income"]].apply(lambdax: x[0]/x[1],axis=1) 3.4.2?模型的選取 由于被解釋變量是二分類變量,因此模型選取該業務場景下常用的模型-邏輯回歸模型(Logit Regression)。而用于預測模型的訓練集和測試集都是從貸款表中的狀態類型進行篩選的,其中訓練集和測試集從狀態為C的情況下選取的,訓練集隨機選取幾何的07,測試集為0.3。使用了邏輯回歸的向前逐步法模型直接調用邏輯回歸的函數,代碼如下所示: fpr,tpr,th = metrics.roc_curve(test.bad_good,lg_m1.predict(test)) plt.figure(figsize=[6,6]) plt.plot(fpr,tpr,'b--') plt.title('ROC curve') plt.show() print('AUC = %.4f' %metrics.auc(fpr,tpr)) for_predict['prob']=lg_m1.predict(for_predict) for_predict[['account_id','prob']].head() 最后生成的是ROC曲線,求得的AUC為0.8780。曲線如圖4所示。 4?總結 本論文通過對案例的數據進行一系列的分析和挖掘得到比較精準的模型,并且已在實際的業務場景中進行了測試和監控,最后的反饋結果都得到了非常不錯的效果,在未來的日子里,筆者也會繼續探索相關的機器學習模型,例如決策樹、組合算法等模型,通過這些模型的比較看能否得到更符合業務場景并且相對精準的模型。 參考文獻 [1]舒揚,楊秋怡.基于大樣本數據模型的汽車貸款違約預測研究[J].管理評論,2017,29(09):59-71. [2]王粟旸.商業銀行小微企業違約風險管控及違約概率估計模型研究[D].南京:南京大學,2014. [3]章寧,陳欽.基于TF-IDF算法的P2P貸款違約預測模型[J].計算機應用,2018,38(10):3042-3047. [4]朱偉義,喬琳霏.基于多維特征邏輯回歸識別模型的排隊監測方法[J].電氣自動化,2018,40(06):94-97. [5]李佳,黃之豪.銀行信用風險預測——基于SVM和BP神經網絡的比較研究[J].上海立信會計金融學院學報,2018,(06):40-48. [6]姚蘭蘭.淺析商業銀行信用風險管理存在的問題與對策[J].現代商業,2018,(31):84-85. [7]金美子.我國商業銀行信用風險管理存在的問題及監管對策[J].現代商業,2018,(28):73-74.
