基于主題層次的文本篇章結構分析方法
2019-07-08 02:23:41黃細鳳
電腦知識與技術 2019年13期
黃細鳳

摘要:針對文本篇章結構分析與語義內容理解,提出了基于主題層次的文本篇章結構分析方法,包括文本篇章結構表示體系、文本篇章結構分析框架及關鍵技術描述。首先根據文本篇章的外在形態和內在邏輯構建了包含主題維度和結構維度的文本篇章結構表示體系,然后,基于表示體系構建了基于主題分割的文本篇章結構分析框架,并重點對其中的主題分割和篇章關系分析算法進行了闡述。
關鍵詞: 篇章結構分析; 篇章關系識別; 主題層次; 主題分割; 句際關系
中圖分類號:TP306 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2019)13-0012-05
Abstract: For text structure analysis and semantic content understanding, a text structure analysis method based on topic level was proposed, which includes text structure representation system, text structure analysis framework and key technologies description. Firstly, according to the external form and internal logic of text, a text structure representation system including topic dimension and structure dimension was constructed. Then, a text structure analysis framework based on topic segmentation was constructed based on the representation system, and the algorithms of topic segmentation and text relationship analysis were emphatically expounded.
Key words: text structure analysis; text relation recognition; topic level; subject segmentation; inter-sentence relations
1 引言
文本的篇章結構分析與語義內容的自動理解是自然語言處理(Natural Language Processing,簡稱NLP)的一項重要的基礎研究內容,是基于文檔庫的問答系統、文本閱讀理解、文本的摘要生成等技術和應用系統所必需的研究基礎。
自然語言的單位由小到大可以分為字、詞、短語、句子、段落和篇章;其中,篇章的語義最為完整,能夠從多個側面、按多層級關系,描述具有關聯關系的一個或多個主題、事件、問題或情境,它由一系列連續的子句、句子或語段構成。因此,篇章既包含了組成篇章的各級語義單元,還包含了他們之間的鏈接及邏輯關系。目前,針對篇章結構的分析一般也是基于修辭結構理論(Rhetorical Structure Theory, RST)從這兩個維度進行的,具體包括對篇章單位、連接詞、篇章結構、篇章關系、篇章主次等方面的分析。
英語篇章結構分析的理論研究比較多,相關理論主要包括Hobbs模型[1-2]、修辭結構理論(Rhetorical Structure Theory, RST)[3-4]和賓州篇章樹庫體系(Penn Discourse Tree Bank,PDTB) [5-6]。漢語篇章結構分析的理論研究較少,當前階段,仍然基于西方現代篇章語言學理論(比較有影響的是RST和PDTB體系)所進行,因此需要建立適合漢語特點的篇章結構表示體系。為了進行全面、系統的篇章級文本分析,本文提出了一種基于主題層次的篇章結構表示體系,在此基礎上建立了文本篇章結構分析的框架。
2 基于主題層次的文本篇章結構表示體系
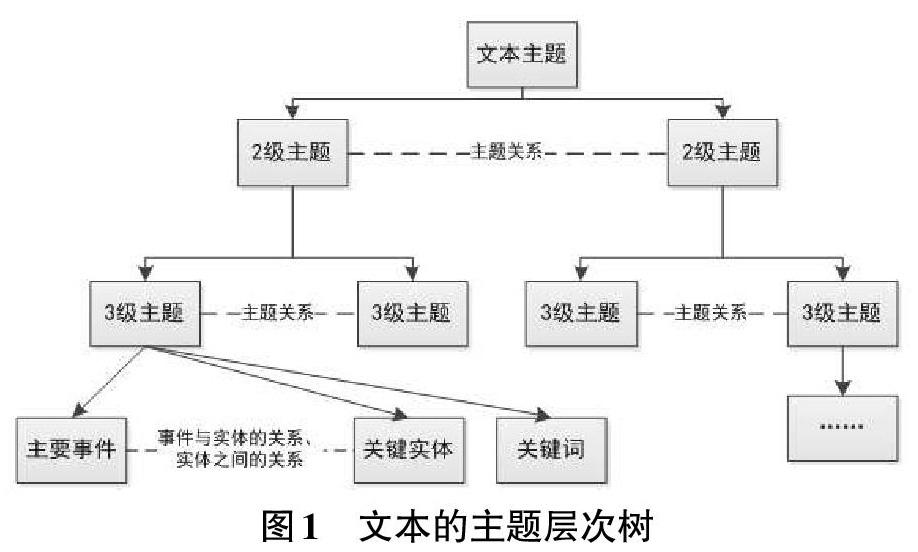
一篇文檔(尤其是長文檔)往往描述了一個主題,而各個不同語義片段又描述了該主題的不同側面,不同側面下還可進行再細分,因此整篇文檔的各層語義片段的主題共同形成了一棵主題層次樹。主題層次樹中的不同節點之間存在著不同的關聯關系;在不同層級的主題中,又包含了不同的語義單元和連接關系,如圖1所示。
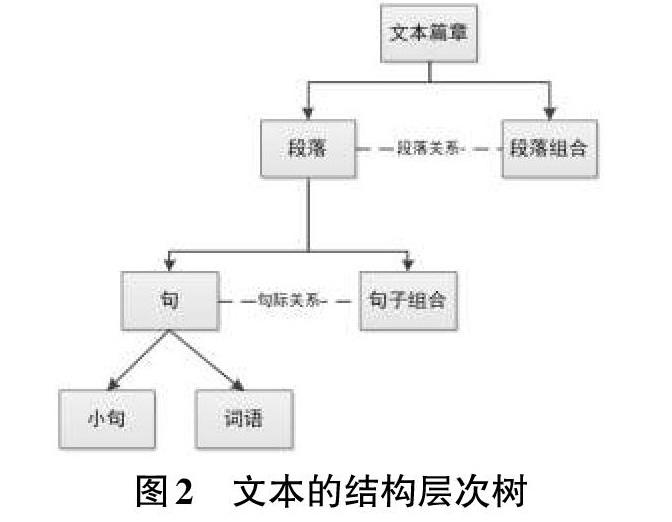
從文本的組織上,文本篇章是通過各級語義單位按照一定關系進行組織的,由詞語和小句(小句即一個句子中包含的小的分句)構成句子,由句子的組合構成段落,由段落的組合構成篇章;其中,篇章關系表示同一篇章內相鄰或跨度在一定范圍內的文本片段之間的語義連接關系,可以包括句際關系(即句子或小句之間的關系)和段落之間的關系(也稱為宏觀篇章關系)。其層次組織關系如圖2所示。
根據文本的篇章組織結構以及所表達的主題層次,將一篇文本分解成如圖3所示。
從而形成基于主題層次的篇章結構表示體系,如圖4所示。文本的外在形態是篇章結構層次及關系、內在邏輯是主題層次及關系;篇章結構層次之間的關系反映的就是主題層次的關系。
基于主題層次的篇章結構表示體系包括表示維度和描述方法。表示維度從主題維度來說,包括主題、子主題、元事件、實體等,其中,主題和子主題通過主題描述、關鍵詞、主題與子主題的關系、子主題間的關系等;元事件通過元事件類型、元事件描述、各要素等來描述。結構維度包括篇章、段落、句等,并通過篇章結構層次、篇章關系來描述。
3 基于主題分割的文本篇章結構分析框架
根據文本篇章結構表示體系可知,從篇章內容本身來說,一篇文本可以包含篇章段落結構、按篇章結構組織的文本內容、按篇章結構組織的多級主題和其他重點描述內容;為了獲得這些內容,本文建立的文本篇章結構分析框架如下圖所示,包括篇章結構解析和主題中相關重要內容的抽取。對于篇章段落的層次結構和關系識別是對文章宏觀層面的分析,是自頂向下對文章的分解,當前篇章關系識別多從篇章基本單元入手,分析句子之間文本片段的連接關系,是以自底向上的角度進行篇章關系的分析,但難以對篇幅規模較大的文本進行全面歸納,因此,本文提出了一種自頂向下的基于主題分割的文本篇章結構分析框架。如圖5所示。
基于主題分割的文本篇章結構分析框架中,通過多級主題分割,識別出篇章中包含的所有主題;同時結合篇章關系識別,將主題之間的關系和層次構建出來;并對各個主題進行描述。其中,篇章關系識別包括主題間的篇章關系和主題內的篇章關系,本文中,篇章關系的最小粒度即基本篇章單元(EDU)為小句。本文基于文獻[11],定義了漢語篇章關系類型,如表1所示。
表中“[ ]”內表示英文標記符。關系包含大、中、小三種關系類型,顯示了不同粒度下的類型區分。大類上(CLASS)區分了“附屬”“聯合”“主從”三個類型。中類上劃分為 6 個類別,最細致的小類上劃分為 17 個類別。在上述大、中、小三層語義關系下,進行篇章關系分析時可以根據實際應用需求選擇不同的粒度。
例如,在識別主題間的篇章關系時,關注的是相對宏觀的篇章關系,就可以選擇第2層中的并列、對比、推理、條件、總分、分總來表述。而在識別句間的主題內篇章關系時,就可以選擇第2層到第3層的語義關系。
內容抽取主要包括元事件及實體抽取,完成句子級或篇章級的元事件抽取、實體相關內容抽取(包括實體抽取、實體相關描述、屬性及關系的抽取等)。其中,元事件是表示一個動作的狀態或變化的細粒度事件,是各級主題內容的重要組成。根據ACE測評中對元事件描述的相關術語有:事件類型、事件描述、事件觸發詞、事件實體、事件實體描述、事件論元角色等。
4 關鍵技術實現方法概述
基于主題層次的文本篇章結構分析中,主要涉及的關鍵技術有主題分割、篇章關系識別、元事件抽取、實體抽取、實體關系抽取等。總體處理思路是:人工標注一定規模的訓練語料,包括通用領域和特定領域,而后采用機器學習方法訓練模型進行自動分析和抽取。本文重點對主題分割、篇章關系識別方法進行概述。
4.1 主題分割
文本分割算法中需要解決的兩個根本問題是主題相關性度量以及邊界劃分策略。目前,文本分割方法主要有如下三種:(1)根據語言學特征,認為特定的語言現象,比如提示短語、新詞出現、命名實體、韻律特征、停頓標記、重復特征、指代使用、句法以及詞匯的形態同化等與片段首尾隱含著某種必然聯系;(2)假定相同、相似或語義相關的詞匯傾向于描述同一個主題,即傾向于出現在同一主題片段內。需要從語料庫中統計分析詞搭配、互信息和詞匯共現頻率等語言知識,作為分割的依據;(3)認為合適的概率統計模型能夠為片段邊界的估計提供可靠依據。近幾年,主題模型幵始應用在文本分割領域,取得了很好的分割效果,特別是LDA模型的應用。提下面介紹基于LDA模型的文本分割算法。
主題分割方面,可以采用基于LDA模型的文本分割。
一個文本通常需要討論若干個主題,而文本中的特定詞匯表征了所討論的主題。在文本主題建模中,將主題視為詞匯的概率分布,文本為這些主題的隨機混合。假設有T個主題,則所給文本中第i 個詞匯可以表示為:
利用局部最小值的邊界估計策略,通過句間相似值識別段落邊界。按相關度結果繪圖,高相關處出現波峰,低相關處出現波谷,選擇波谷處作為分界線,將自然段組合成語義段。進一步,選擇該語義段中概率最高的前L個詞作為主題詞。
4.2 篇章關系分析
如前所述,篇章關系分析根據關系粒度可以分為宏觀篇章關系識別和句際關系識別。篇章關系分析根據是否存在連接詞,分為顯式篇章關系識別和隱式篇章關系識別兩大類。顯式關系的顯著特征是篇章的基本單元之間存在顯式連接詞,因此,顯式篇章關系識別主要包含了漢語連接詞識別和篇章關系分類兩個步驟。隱式關系識別由于連接詞缺失,判斷兩個基本篇章單元之間存在何種邏輯關系較困難,通常只能根據一些語言學特征進行關系識別。
目前國內的篇章關系研究仍處于初級階段,文獻[15]提出構建中文篇章樹庫的任務,文獻[16]根據中文特點基于PDTB語料的標注特征提出具體的中文篇章關系標注準則,文獻[17]參照PDTB中定義的篇章關系類型,初步構建面向中文的篇章關系分析數據。
下面介紹一種基于監督學習和規則相結合的方法。
自下而上進行篇章關系識別時,可以分為三個步驟:第一步,將句子切分為基本篇章單元(EDU);第二步,分析句子之間的修辭關系,構建層級結構樹,以表征各個EDU的層級結構;第三步,識別結構樹中節點之間的內部關系,以表征各個EDU的關系標簽。
第一步中,直接利用標點符號“,”將句子切分為互不重疊、交叉、連續的“小句”,即基本篇章單元(EDU)。
第二步,層級結構分析,可以采用排序SVM和基于規則的方法。
排序SVM方法中,將連續三個篇章單元作為一個樣例,通過比較此相鄰兩對篇章單元的結合緊密程度定義正例和負,來訓練分類器。
基于規則的方法中,一個IF-THEN規則是一個如下的表達式:IF條件THEN結論。規則的結論包含一個類預測,這里指的是是否合并節點。
規則和 SVM 分類器融合的方法為:
1)使用冒號和分號將整個句子切分成多個子句序列;
2)對于分號切分開的并列語句,分別使用 SVM 方法建樹;
3)對于使用冒號切分開的語句,如果左半部分包含不止一個小句,那么先將最后一個小句與右半部分合并建樹,再和左半部分其余節點一塊兒使用 SVM 方法建樹。
第三步,句際關系識別,基于SVM的方法:在人工標記語料上訓練多分類SVM模型,然后利用訓練好的模型對句子層級結構樹中每一個內部節點進行關系識別。規則方法:主要是借助連接詞和副詞信息進行規則判定。
每個訓練樣例(待識別的層級結構關系樹內部節點)都由兩個篇章單元(當前關系樹的左右子樹)組成,分別記為左單元(UL)和右單元(UR)。方便起見,將左單元最后一個EDU記為EUL,右單元第一個EDU記為EUR。實驗中SVM模型采用的特征如表2 所示:
5 ?實驗
本文基于文本篇章結構表示體系,采用基于文本分割的篇章結構分析方法,參考文獻[11]的篇章級句際關系標注體系,開發了標注工具,進行了一定數據的篇章關系語料標注;在文本結構層次分析中采用基于LDA的文本分割方法,對于一篇有42個自然段的長文本,實驗結果如圖6所示。
然后采用文中基于監督學習和規則相結合的方法,對主題內的句際篇章關系進行分析,其中一段的分析結果如圖7所示。
基于人工標注數據進行測試,層級結構分析的正確率為 66.5%,關系類型識別的F值為71%。實驗表明,本文提出的自頂向下的篇章結構分析思路具備良好的有效性。
6 ?結論
在本文中,我們提出了一種基于主題層次的文本篇章結構分析方法,這是一種自頂向下的篇章結構表示體系,能夠從宏觀和微觀角度建立文本篇章的畫像,擴展了篇章結構的表示維度;基于該表示體系,本文提出了基于文本分割的篇章結構分析框架,能有效實現對篇章結構的分析。
參考文獻:
[1] Hobbs J. R. Coherence and coreference[J]. Cognitive Science, 1979,3(1):67-90.
[2] Hobbs J. R. Information, Intention, and Structure in Discourse: A first draft[C]. In Burning Issues in Discourse, NATO Advanced Research Workshop, 1993:41-66.
[3] Mann W. C. and Thompson S. A. Relational propositions in discourse[J]. Discourse processes, 1986, 9(1):57-90.
[4] Mann W. C. and Thompson S. A. Rhetorical structure theory: A theory of text organization[M]. University of Southern California, Information Sciences Institute, 1987.
[5] Mann W. C., Matthiessen C., and Thompson S. A. Rhetorical structure theory and text analysis[J]. Discourse description: Diverse linguistic analyses of a fund-raising text, 1992:39-78.
[6] Prasad R., Dinesh N., et al. The Penn Discourse Treebank 2.0[C]. In Proceedings of LREC, 2008:2961-2968.
[7] PDTB Research Group. The Penn discourse treebank 2.0 annotation manual[R]. IRCS Technical Reports Series, 2007, 99p.
[8] 丁彬, 孔芳, 李生. 漢語顯式篇章關系分析[J]. 北京大學學報(自然科學版),2014, 28(6):101-106.
[9] 孫靜, 李艷翠, 周國棟. 漢語隱式篇章關系識別[J]. 中文信息學報, 2014,50(1): 111-117.
[10] 呂國英, 蘇娜, 李茹. 基于框架的漢語篇章結構生成和篇章關系識別[J]. 中文信息學報,2015,11.29(6): 98-109.
[11] 吳云芳, 徐藝峰, 王愷然. 漢語篇章級小句關系的標注體系[J]. 中文信息學報,2015,5. 29(3): 71-81.
[12] 嚴為絨, 徐揚, 朱珊珊. 篇章關系分析研究綜述[J]. 中文信息學報.,2016,7. 30(4): 1-11.
[13] 李國臣, 張雅星, 李 茹. 基于漢語框架語義網的篇章關系識別[J]. 中文信息學報, 2017,11. 31(6): 172-189.
[14] 李效晉. 基于統計模型的文本分割方法及其改進[J]. 山東: 山東大學, 2014.
[15] N Xue. Annotating discourse connectives in the Chinese Treebank[C]. Proceedings of the Workshop on Frontiers in Corpus Annotations II: Pie in the Sky, 2005: 84-91.
[16] Y Zhou, N Xue. Pdtb-style discourse annotation of Chinese text[C]. Proceedings of the 50th Annual Meeting of the ACL, 2012: 69-77.
[17] H H Huang, H H Chen. Chinese Discourse Relation Recognition[C]. Proceedings of the 5th International Joint Conference on Natural Language Processing (IJCNLP), 2011: 1142-1146.
【通聯編輯:唐一東】
