全維知識圖譜概述及知識表示框架研究
2019-07-16 03:17:27黃細鳳
電腦知識與技術 2019年14期
黃細鳳
摘要:針對不同的信息品類在信息轉換、處理、展示時出現的失真、損傷或偏差的問題,提出了全維知識圖譜的概念,對全維知識圖譜的原理、關注內容、用法和好處進行了概述;然后針對全維知識表示,提出了統一的知識表示框架,采用分級的信息特征和特征屬性進行信息內容的描述,并以文本類信息為例對表示框架進行實例化,形成了信息特征表示模型。
關鍵詞: 知識圖譜;全維知識圖譜;全維知識表示;知識表示框架;信息特征
中圖分類號:TP18 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2019)14-0145-02
Abstract: Aiming at the problems of distortion, damage or deviation in information conversion, processing and display of different information categories, the concept of full-dimensional knowledge graph was proposed, and the principle, content, usage and advantages of full-dimensional knowledge graph were summarized. A unified knowledge representation framework was proposed for full-dimensional knowledge representation, which is based on hierarchical information features and feature attributes of descripting information content. Taking text information as an example, the representation framework was instantiated and an information feature representation model was formed.
Key words: knowledge graph; full-dimensional knowledge graph; full-dimensional knowledge representation; knowledge representation framework; information feature
世界多姿多彩,信息豐富,描述方式與信息品類多種多樣,有文字、聲音、圖片、視頻等等。而不同信息品類在信息轉換、處理、展示時會失真或損傷,甚至出現偏差與錯誤。例如,將聲音轉成文字時,僅僅記錄了聲音的語義,卻忽略了說話人的語種、語氣、語調、情感、修辭、傾向、風格等等信息,從而丟失了很多維度的信息,對于理解聲音就可能產生歧義、不到位、甚至錯誤的理解。
用全維知識圖譜的方法來進行信息解析與知識表達,不失真、不降維地對知識進行采集、存儲等。一方面,可以完整地高保真地對信息進行記錄,在轉移時使受眾不產生歧義;另一方面,統一一種處理方法,可以將文字、聲音、圖像、視頻等進行大融合,為跨專業、跨領域的知識交互與融合提供基礎。因此,本文提出采用全維知識圖譜來構建一種知識表達的框架和標準,規范不同品類信息的描述方法,以便在信息采集、存儲、解析、轉換、處理、融合等等過程中不失真、不降維。
1 全維知識圖譜概述
本文將從三個方面來對全維知識圖譜進行闡述,包括其關注內容、怎么用和有什么出好處。
1.1 關注內容是什么?
全維知識圖譜需要關注的內容有:
(1)全維知識圖譜基礎理論研究;
(2)跨學科知識表達標準體系,知識分類體系;
(3)知識表達統一框架構建,全維知識圖譜基本架構和頂層模型梳理;
(4)垂直領域全維知識圖譜構建;
(5)全維知識圖譜的效能統一表征方法與效能評估;
(6)基于全維知識圖譜的跨品類、跨專業、跨學科知識融合。
1.2 怎么用?
現階段以Knowledge Graph為主的一系列知識圖譜為精細化的查詢奠定了基礎,隨著智能信息服務應用的不斷發展,知識圖譜已被廣泛應用于智能搜索、智能問答、個性化推薦、可視化決策支持等領域。而當前知識表達方法,不管是基于怎樣的學習原則,都不可避免地產生語義損失。符號化的知識一旦向量化后,大量的語義信息被丟棄,只能表達十分模糊的語義相似關系。全維知識圖譜以知識圖譜的概念為基礎,構建知識表達統一框架,多視角、多維度地對信息或對象進行描述,應用于軍事領域,可為作戰指揮人員提供更為“真實”的情報,提高作戰效率。應用方向有:
(1)用于規范素材、信息的采集,提升海量半結構化、非結構化數據的有效獲取能力;
(2)促進領域知識體系的構建;
(3)基于全維知識圖譜,構建領域知識庫,在接入、處理、分析、服務等各個環節提供統一的數據空間,將不同品類、不同對象的數據統一存儲、處理、使用;
(4)特別地,應用于目標識別領域,可以給目標識別提供更加豐富的視角和特征;
(5)同樣地,支持基于知識圖譜的應用,如智能搜索、智能問答、個性化推薦、可視化決策支持等。
1.3 有什么好處?
作用和好處包括:
(1)全維知識圖譜可以指導信息的采集、存儲、處理、轉移、解析、理解;
(2)可以根據用戶的實際情況實現合理的剪裁,得到精準服務的效果,是人工智能的主要研究方向;
(3)可以完整地高保真地對信息進行記錄,在轉移時使受眾不產生歧義;
(4)信息利用更充分,可以將文字、聲音、圖像、視頻等進行大融合;
(5)全面地、多視角地、多維度地描述信息、目標等對象;為目標識別提供更多維度、更多視角、更多特征;
(6)可以提供深度的知識關聯及語義層的知識推理,更深層地理解信息;
(7)為跨領域、跨專業的交互、協作與統一融合提供了基礎。
2 全維知識表示框架
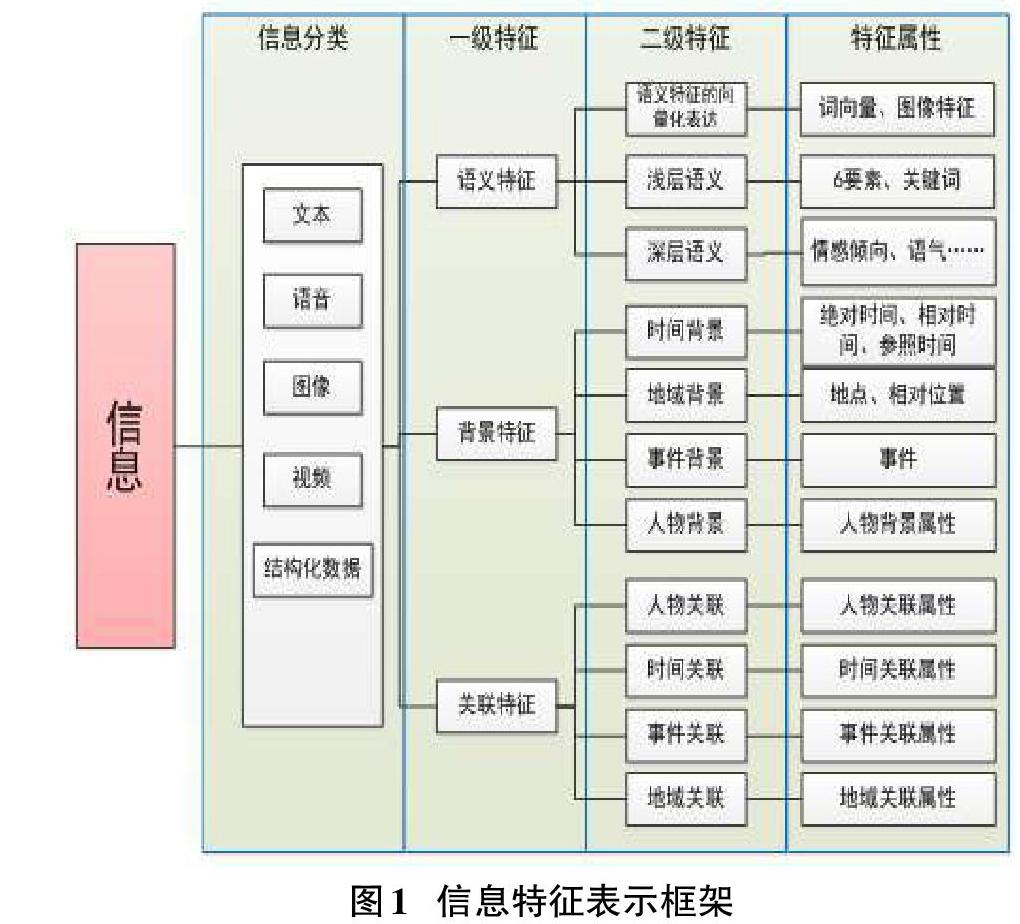
“全維”是指采用盡量多的維度和側面來描述信息,以使采集的信息盡量完整和準確。本文針對文本、語音、圖像、視頻、結構化數據等多種類型的信息,采用分級的信息特征和特征屬性進行信息內容的描述,形成基本的知識表示框架,如圖1所示。
信息特征由其語義特征、背景特征和關聯特征組成。其中語義特征由包括語義特征的向量化表達、淺層語義及深層語義;背景特征包括時間背景、地域背景、事件背景、人物背景等;關聯特征包括人物關聯、時間關聯、事件關聯、地域關聯等特征。
特征屬性中所有的屬性內容都有其模型,例如人物模型、時間模型、語氣模型、情感模型,也就是說每增加一項屬性內容就對該屬性內容進行描述,即知識對象模型。而當這些模型進行實例化時,知識數據就來自各種信息素材,從而與知識圖譜進行關聯,這樣就構建出了知識世界的框架。
3 信息特征表示模型
在信息特征表示框架中,按文本、語音、圖像、視頻等類型,對各自的特征屬性進行實例化,就構建成了文本、語音、圖像、視頻的信息特征表示模型了。下面以文本信息為重點進行詳細闡述。
3.1 文本信息特征表示模型
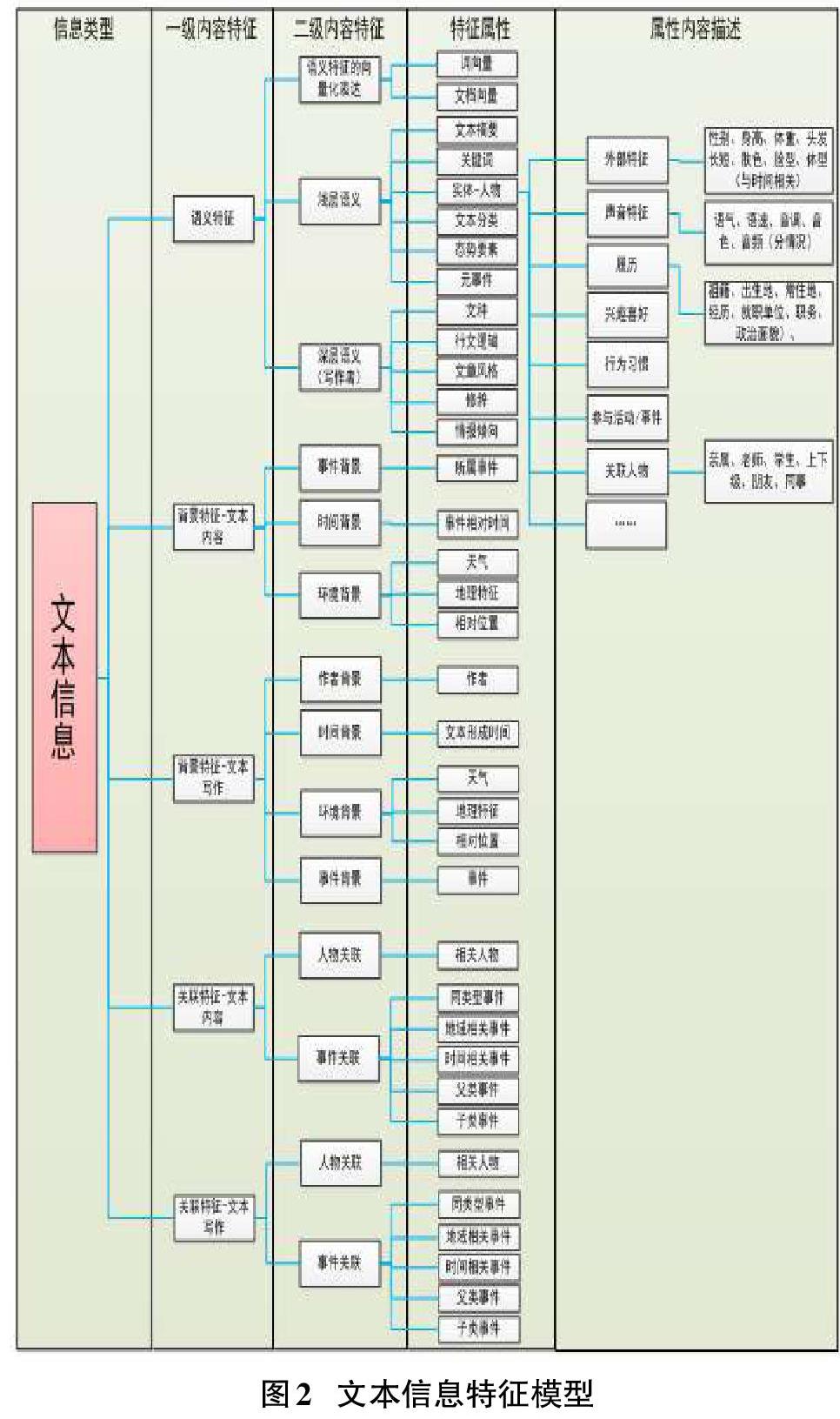
文本信息特征表示模型如圖2所示。
文本信息特征由語義特征、文本內容和文本寫作的背景特征和關聯特征等一級內容特征組成。其中,語義特征由語義特征的向量化表達、淺層語義、深層語義等二級內容特征組成;背景特征由事件背景、時間背景、環境背景、作者背景、時間背景、環境背景、事件背景等二級內容特征組成;關聯特征由人物關聯、事件關聯等二級內容特征組成。二級特征又由一系列的特征屬性組成,如淺層語義特征由文本摘要、關鍵詞、實體、文本分類、態勢要素、元事件等組成。每個特征屬性又具有相應的描述信息,如淺層語義中的人物實體對應的描述信息包括人物的外部特征、聲音特征、履歷、興趣愛好、行為習慣、參與事件活動、關聯人物等,其中每個描述信息又包括系列具體的屬性,如人物的外部特征包括性別、身高、體重、頭發長短、膚色、臉型、體型等外部特征描述和語義、語速、音調、音色等聲音特征組成。
3.2 其他信息特征表示模型
語音特征表示模型:基于信息特征表示框架,構建語音特征表示模型,其中背景特征和關聯特征與文本信息類似,重點對語義特征進行建模。其中,淺層語義主要指語音轉成的文字以及語音中的關鍵詞,深層語義主要指語音本身所攜帶的聲紋特征、語氣、語調、音色、音頻等特征。
圖像特征表示模型:圖像的語義特征,從向量化表達的角度,一般使用圖像特征來表達,如統計特征、紋理、結構等;圖像的淺層語義主要指從圖像中獲取的文本化內容,如圖像所描述的物體、人物、姿態以及位置關系等;圖像的深層含義主要指從圖像中描述的內容所表達的意圖信息、心理活動等。
視頻特征表示模型:視頻可以看成是連續的圖像加上聲音,其語義特征可以參照圖像特征及語音特征進行構建。
4 結論
在本文中,我們提出了全維知識圖譜的概念,采用盡量多的維度、統一的知識表示框架來規范不同品類信息的描述方法,能夠使采集的信息盡量完整和準確。本文對全維知識圖譜的概念內涵進行了闡述,并給出了一種知識表示的框架,說明在領域應用中是可行的,而通過分析可知,全維知識圖譜能夠在多個環節發揮實際的好處,因此,很有必要進行繼續深入的研究。
參考文獻:
[1] 徐增林, 盛泳潘, 賀麗榮. 知識圖譜技術綜述[J].電子科技大學學報,2016,45(4): 589-606.
[2] 馬創新.論知識表示[J]. 現代情報,2014,34(3):21-24.
[3] 劉嶠, 李楊, 段宏. 知識圖譜構建技術綜述[J].計算機研究與發展,2016,53(3):582-600.
[4] 虞盛康. 面向互聯網數據的知識表送與推理[D].浙江:浙江大學,2016.
[5] 陳宏. 基于本體的知識表示研究[D].長沙:長沙理工大學,2006.
[6] 黨洪莉. 知識科學視角下我國知識融合研究現狀解析[J].情報雜志,2015,34(8):158-162.
[7] 周芳, 王鵬波, 韓立巖. 多源知識融合處理算法[J].北京航空航天大學學報,2013,39(1):109-114.
[8] 王錦, 王會珍, 張俐. 基于維基百科類別的文本特征表示[J].中文信息學報,2011,25(2):27-31.
[9] 許鵬飛. 圖像結構化特征表達方法研究[D].哈爾濱: 哈爾濱工業大學,2013.
【通聯編輯:唐一東】
