深度學習
2019-07-20 08:21:08袁冰清王巖松
數字通信世界 2019年6期
關鍵詞:深度
袁冰清,張 杰,王巖松
(國家無線電監測中心上海監測站,上海 201419)
深度學習(Deep learning),也稱為深度結構學習(Deep Structured Learning)或者是深度機器學習(Deep Machine Learning),是一類算法的集合,是機器學習的一個分支。如今,深度學習在算法領域可謂是大紅大紫,不只是互聯網、人工智能,生活中的各大領域都能反映出深度學習引領的巨大變革,如目前最先進的語音識別、視覺對象識別等領域。本文先從深度學習中涉及到的一些概念去理解深度學習,最后主要介紹目前在圖片識別和語言處理中應用最廣泛的兩大類深度學習網絡:卷積神經網絡和循環神經網絡。
1 表示學習
人工智能(AI)系統需要具備自己獲取知識的能力,即從原始數據中提取模式的能力,這種能力就稱為機器學習(Machine Learning)。傳統的機器學習技術在以原始形式處理自然數據能力方面是有限的。表示學習[1](Representation Learning)是允許機器自適應原始數據并且自動發現這些可以檢測或者分類的表現形式的一系列方法。深度學習就是具有多級表示的表示學習方法,獲得更高層次、更抽象的表示層次[2]。事實證明,深度學習非常善于發現高維度數據中的復雜結構,除了在圖片識別與語音識別方面取得重要成就之外,深度學習在自然語言多任務理解方面也有顯著的成果,尤其是在主題分類、情感分析及語言翻譯等方面。
2 監督學習
機器學習的主要形式就是監督學習(Supervised learning),不管是深度還是非深度。從訓練集中學到或建立一個模式,并依此模式推測新的實例,訓練集就是由相對應的輸入和預期輸出組成。實際輸出與所期望的輸出之間的誤差,我們定義為目標函數,機器可以修改內部的權重去減少誤差。在一些典型的深度學習系統中,可能有數百萬計的可調權重,以及數百萬計的標簽樣本去訓練機器。為了正確調整權重向量,學習算法計算一個梯度矢量,對于每個權重而言,每次增加一個微小的量時,誤差就會相應地增加或者減少一定的量,然后權重向量就向梯度矢量相反的方向調整來適應梯度向量。實際中,大家最常用的一種稱為隨機梯度下降(Stochastic Gradient Descent,SGD)的算法[3]。對于很多樣本,計算輸出誤差,計算樣本的平均梯度,相應地去調整權重。這個過程重復多次,直到目標函數的平均值減小。在訓練之后,系統的性能就用一系列不同的被稱為測試集的樣本來測量,這也是測試機器的泛化能力-檢驗對于在訓練期間沒見過的輸入產生合理答案的能力。
深度學習架構都是簡單模型的多層堆疊[1],所有的或者大部分模塊都是需要學習,其中許多都是非線性的輸入-輸出映射。在堆疊中的每個模塊轉變輸入以增大特征的選擇性和不變性。對于一個非線性多層網絡來說,比如深度是5-20層的深度,系統就可以進行非常復雜的功能,對于細節的輸入就非常敏感了,比如可以區分長得很像的薩摩耶和白狼,但也可以對不相關的變量如:背景、姿勢、燈光和周圍的物體就不敏感了。
深度學習當前應用最廣泛,效果最佳的就在計算機視覺和語音識別領域。而在計算機視覺方面,卷積神經網絡就是典型范例。卷積神經網絡是一種特殊類型的深度前饋網絡,更易于訓練,并且比全接連的神經網絡的泛化性能更好[4]。
3 卷積神經網絡與圖像識別
卷積神經網絡(Convolution Neural Networks,CNN)被設計用來處理多維數組數據的,比如一個包含三個顏色通道的彩色圖片。很多數據形態都是多維數組形式:1D用來表示信號和序列如語音,2D用來表示圖像,3D用來表示視頻或者由聲音的圖像。下面我們用彩色圖像中某一個顏色通道來說明理解卷積神經網絡的過程。如下圖所示:實際上卷積神經網絡是一個多層的神經網絡,其中基本運算包含:卷積運算、池化運算、全連接運算和識別運算[5]。

圖1 卷積神經網絡原理過程
圖片的原始數據就是像素矩陣,每個像素點里都存儲著圖像的信息。我們再定義一個卷積核(相當于權重),用來從圖像中提取一定的特征。卷積核與數字矩陣對應位置相乘再相加,得到卷積層輸出結果。卷積核的取值在沒有以往學習的經驗下,可由函數隨機生成,再逐步調整。當所有的像素點都至少被覆蓋一次后,就可以產生一個卷積層的輸出。機器一開始并不知道要識別的部分有什么特征,但是用過與不同的卷積核作用后得到的輸出值,相互比較來判斷哪個卷積核最能表現該圖片的特征。卷積層的輸出值越高,就說明匹配程度就越高,越能表現該圖片的特征。即卷積層就是通過不斷地改變卷積核,來確定能初步表征圖片特征的有用的卷積核是哪些,再得到與相應的卷積核相乘后的輸出矩陣。池化層的輸入就是卷積層輸出的原始數據與相應的卷積核相乘后的輸出矩陣。那池化層的目的:為了減少訓練參數的數量,降低卷積層輸出的特征向量的維度,減小過擬合現象,只保留最有用的圖片信息,減少噪聲的傳遞。最常見的兩種池化層的形式:最大池化-選取指定區域內最大的一個數來代表正片區域;均值池化-選取指定區域內數值的平均值來代表整片區域。卷積和池化層的工作就是提前特征,并減少原始圖像帶來的參數,然而為了生成最終的輸出,我們需要應用全連接層來生成一個等于我們需要的類的數量的分類器。全連接層的工作原理跟一般的神經網絡學習很類似,我們需要把池化成輸出的張量重新切割成向量,乘上權重矩陣,加上偏置值,然后對其使用RELU激活函數,用梯度下降法優化參數即可。卷積神經網絡在卷積運算和池化運算中就通過三個核心想法來改進學習效率及體現自然信號的屬性:稀疏交互、權值共享及等變表示。
自從21世紀初以來,卷積神經網絡就被成功地應用在檢測、分隔和物體識別及圖像的各個領域方面。這些應用都是使用了大量的有標簽的數據,比如交通信號識別,生物信息分割,面部特征探測,自然圖像中的文字,行人和人的身體部分探測。卷積神經網絡當前最成功的應用就是人臉識別。
4 循環神經網絡和語言處理
當處理序列信息的任務,如理解一句話的意思時,孤立地理解這句話的每個詞是不夠的[6],我們需要處理這些詞連接起來的整個序列,即前面的輸入跟后面的輸入是有關系的,這時候我們就需要用到深度學習領域中一類非常重要的神經網絡-循環神經網絡(Recurrent Neural Network,RNN)。
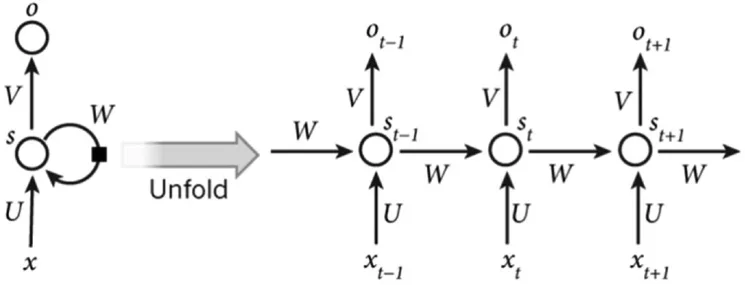
圖2 循環神經網絡展開結構圖
循環神經網絡的結構如上圖[1]所示,跟普通的全連接神經網絡相比,多了一層循環層,按時間序列展開來看,就是當前隱藏層的輸出值不僅與當前的輸入值有關,還取決于上一次隱藏層的值。循環神經網絡的訓練算法是BP算法的變體,BPTT(Back Propagation Trough Time)。但是在實踐中,RNN在訓練中很容易發生梯度爆炸和梯度消失,導致梯度不能在較長序列中一直傳遞下去,因此RNNs不能很好地處理較長序列的問題。比如在語言文字識別中,在長語句“I grew up in France…I speak fluent French”中去預測最后的French,那么模型會推薦一種語言的名稱,但是具體到哪一種語言時就需要用到很遠之前的文字France,這時候RNN可能不能夠學到前面的知識。為了解決長距離的依賴問題,通常使用一種改進之后的循環神經網絡:長短時記憶網絡(Long Short Term Memory Network,LSTM)及其變體:GRU(Gated Recurrent Unit)。
LSTM的思路非常簡單,原始的RNN的隱藏層只有一個狀態,即h,它對短期的輸入非常敏感,我們在增加一個狀態C,讓她來保持長期的狀態,新增加的狀態c,成為單元狀態(cell state),按時間序列展開如圖3所示[7]:
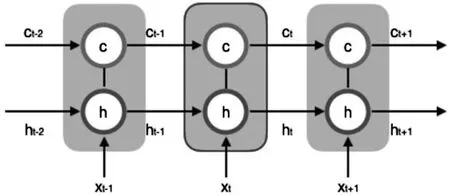
圖3 LSTM的單元狀態展開圖
在當前t時刻,LSTM的輸出有兩個,當前時刻LSTM輸出值ht、和當前時刻單元狀態ct,輸出值ht不僅跟當前的輸入Xt有關,還跟上一層的輸出ht-1、ct-1有關。因此LSTM的關鍵就是怎樣控制長期狀態C,而長期控制狀態是通過三個門(實際上是一層全連接層)來控制的,分別是遺忘門、輸入門和輸出門。GRU作為LSTM的一種變體,將遺忘門跟輸入門合并為一個單一的更新門,同樣混合了單元狀態和隱藏狀態,最終的模型比標準的模型要簡單,是也是非常流行的變體。
但是往往在語言識別中,同樣的一句話有不同的意義,比如兩個外語學院的學生,一種意思是兩個外語學院的/學生,另一種意思是兩個/外語學院的學生。這時候,把句子看成是詞的序列輸入是不夠的,必須按照樹結構去處理信息,而不是序列,這就是遞歸神經網絡(Recursive Neural Network,RNN),跟循環神經網絡的縮寫一樣,看以看成是循環神經網絡更一般的形式,它可以處理樹、圖這樣的遞歸結構。遞歸神經網絡可以把樹/圖結構信息編碼為一個向量,也就是把信息映射到一個語義空間中,通過編碼后向量的距離來代表句子意義的相近問題如圖4所示[8]。所以說遞歸神經網絡是一種表示學習,可以將詞、句、段、篇按照他們的語義映射到同一向量空間中,把組合的信息表示為一個個有意義的向量。但是因為遞歸神經網絡的輸入必須把每個句子標注為語法解析樹的形式,需要花費很大的精力,因此在實際應用中反而不太流行。

圖4 遞歸神經網絡中語義解析
5 深度學習的展望
人類視覺是一個智能的,基于特定方式的利用小或大分辨率的視網膜中央窩與周圍環繞區域對光線采集成像的活躍的過程。我們期望未來的機器視覺進展是來自于端到端的訓練系統,并將卷積神經網絡和遞歸神經網絡結合起來,采用增強學習來決定走向。結合深度學習和增強學習的系統還處于起步階段,但是他們已經超越來在分類任務中超過了被動視覺系統,并在學習操作視頻游戲中產生了令人印象深刻的效果。
自然語言理解是深度學習的另一個領域,有望在未來幾年內產生巨大的影響。我們希望使用RNN 的系統能夠理解句子或者整個文檔,當他們學習有選擇性地學習了某時刻部分加入的策略。
總之,人工智能將取得重大的進展,通過將表現學習與復雜推理學習結合起來。盡管深度學習和段時間了,我們仍需要通過操作大量向量的新范式來取代基于規則的字符表達式操作。
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
