融合詞性的維吾爾語文本分類研究
2019-07-25 08:03:24李高鵬艾山吾買爾
現代計算機 2019年17期
李高鵬,艾山·吾買爾
(新疆大學信息科學與工程學院,烏魯木齊830046)
0 引言
文本分類技術是指利用計算機編寫程序,實現把某一文本按照一定的標準規范,劃分到給定的類別中的技術。文本分類技術被廣泛應用于信息檢索、數字化圖書館、有害信息過濾、搜索引擎等領域[1]。研究維吾爾語(以下簡稱維語)文本分類有助于管理和篩選互聯網上海量的信息。目前維語文本分類的研究主要采用基于機器學習的方法[2-5],基于深度學習的維吾爾文文本分類研究較少,文本分類實驗的結果仍有待提高。目前的維語文本分類在特征提取時采用的是信息增益(IG)、期望交叉熵(ECE)等方法,向量表示方法采用的是向量空間模型(VSM)主要存在三個問題:①特征空間存在高緯度的問題;②向量表示存在高稀疏性的問題;③在以往的研究中很少考慮詞性特征對維語文本分類實驗的影響。
基于以上問題,為了降低特征空間的維度,和向量表示稀疏性的問題,本文根據將訓練語料花費為以下三組,第一組訓練文本為僅僅對待訓練文本進行去停用詞等處理,用來作為基線與其他組實驗進行對比;第二組訓練語料是根據詞性特征從第一組訓練語料中篩選出名詞、動詞、形容詞,過濾掉其他詞匯(如:副詞、連詞、代詞等);第三組訓練語料是根據詞性特征從第一組訓練語料中只挑選出文本中詞性為名詞的詞匯作為文本特征。本文通過對這三組訓練語料,采用機器學習的方法,以及深度學習的方法進行實驗,研究了解維語詞性特征對分類結果的影響,通過將這訓練三組語料,在傳統機器學習方法SVM、KNN、DTree 以及深度學習方法CNN、RNN、CNN-BLSTM 上進行實驗,對比實驗結果發現在機器學習方法上,通過改變特征選擇的方法,提高了文本分類的準確率,并且大大降低了訓練時間;在基于神經網絡的算法上,第三組訓練語料較第一組訓練語料及第二組訓練語料,準確率有所提高,訓練時間也有所降低。
1 相關工作介紹
1.1 維語文本分類研究現狀
2007 年胡燕等人[6]提出將類別特性強的名詞、動詞作為文本的一級詞性提取出來,提高了特征提取的效率,降低了特征向量的維度,不失為一種簡單高效特征提取方法。2015 年路永和等人[7]引入詞性特征改進了特征權重的計算方法,提高了分類的準確率。賈會強等人[24]提取藏文中的名詞動詞作為一級詞性再通過計算這些詞的文本頻數(TF)和文檔頻數(DF)來計算其權重;根據權重進行排序,篩選出前K 個詞作為特征空間。2017 年黃賢英等人[8]在利用基于語義的短文本相似度進行文本分類時通過對提取到的關鍵詞的詞性不同賦予不同的權重系數,以此區別各種貢獻度詞項在短文本相似度計算中的重要程度,有效的提高了短文本分類的準確率。在這些方法中考慮了詞性特征,不同的詞性包含的信息不同,對于具有較強分類特性的詞賦予較高的權重或者是直接將具有很強分類特性的詞作為一級特征詞進行特征選擇,缺乏了更進一步的研究和對比,本文在考慮影響分類類別的重要因素時,通過人工觀察及對比發現包含類別信息最多的詞是名詞,動詞、形容詞、代詞、量詞等包含較少的類別區分特征。
2012 年阿力木江·艾沙等人[3]提出了基于統計方法的維語短語抽取算法,采用支持向量機(SVM)算法進行了分類實驗。買買提依明·哈斯木[4]提出了一種基于N 元模型的維語文本分類技術。2016 年阿力甫·阿不都克里木等人[9]提出一種基于TextRank 算法和互信息相似度的維文關鍵詞提取方法,然后根據互信息相似度度量,計算輸入文本關鍵詞集和各類關鍵詞集的相似度,實現了文本分類。2017 年吐爾地·托合提等人[5]研究了一種n元遞增算法來抽取維吾爾文本中表達關鍵信息的語義串,提出了一種類似于Jaccard 相似度的文本和類主題相似度度量方法,實現了維語文分類算法。以上關于維語的文本分類研究大都還停留在傳統的機器學習的方法,基于深度學習的維語文本分類研究較少,維語文本分類的研究仍有很大的提升空間。本文在研究詞性對基于傳統機器學習的文本分類結果的同時也研究詞性對基于深度學習算法的文本分類結果的影響。
1.2 維語詞性
維語構詞和構形附加成分很豐富。關于維語詞性的劃分有不同的標準,表1 所示的是新疆大學多語種信息技術重點實驗室獨立創建了維語詞性劃分的標準[10]。

表1 維語一級詞性劃分標準

圖1 詞性分布表
圖1 是對實驗所用的語料進行統計得到的詞性分布,可以看出名詞詞性在所有詞中占據了54%的比例,動詞占據了20%的比例,形容詞占據了9%的比例。名詞、動詞、形容詞加起來占據了所有詞中83%的比例,其他詞性的詞匯合計占據17%。因此本文根據詞性的比重設計的第二組訓練語料為只保留文本中為名詞、動詞、形容詞詞性的特征與只去除停用詞的第一組訓練語料作對比,同時考慮到針對文本分類問題,動詞和形容詞似乎對分類的作用沒有名詞的影響大,于是在本文的第三組訓練語料中,只保留了維語文本中名詞詞性的詞匯。
1.3 支持向量機
支持向量機是建立在統計學習理論基礎上的一種有監督的機器學習方法,主要思想是在線性可分的情況下,在文本空間中直接尋找最優超平面,在線性不可分的情況下,通過與高斯“核”函數的結合,將數據從低維映射到高維,構建一個最優超平面,使得超平面兩邊的樣本點到超平面的距離最大。支持向量機的優點在于它將非線性問題轉化為線性問題,并將求解的問題轉化為一個凸優化問題,對應的局部最優解即為全局最優解,通過將分類間隔最大化,使得支持向量機具有較好的魯棒性。支持向量機的方法在文本分類中能達到較好的效果。假設訓練集為:T={(xi,yi),L,(xi,yi)}∈(X×Y)l,其中xi∈X=Rn為輸入樣本,yi∈Y={1,-1}代表分類類別,n 維空間中線性判別函數的一般形式為:

要使得f(xi)<-1 或f(xi)>1,并使得分類間隔最大,等式需滿足以下條件:

1.4 循環神經網絡
循環神經網絡主要用于解決時序依賴等問題,循環神經網絡可用于股票走勢預測、語音識別等領域。通常神經網絡模型在各個網絡層之間都是全部連接在一起的,各層之間的各個節點之間是沒有連接的,而循環神經網絡則不同,循環神經網絡同一層的輸出會傳遞到同一層的下一個狀態,參與運算,進行狀態更新,循環神經網絡基于上下文的內容是相關的這一假設的基礎上,通過共享不同時間的參數,實現對序列數據的處理,學習到不同時間的信息之間的依賴關系。循環神經網絡的網絡結構如圖2 所示。

圖2 RNN網絡結構
2 實驗介紹及實驗結果分析
實驗的語料來源于天山網和人民網,本文挑選了以下7 個類別,共計26733 篇文本作為實驗語料。為了得到可靠穩定的模型,采用交叉驗證法,按照8:1:1的比例劃分為訓練集、驗證集和測試集,劃分結果如表2 所示。

表2 訓練集、驗證集和測試集的劃分
為了進行對比和比較全面地評估文本分類的實驗結果,本文采用準確率(Precision,P)、召回率(Recall,R)和F1值三個指標來衡量實驗結果。本文首先對維語文本中的詞匯進行詞性標注,然后根據詞性選擇出特定詞性的維語詞匯特征,用作實驗的語料。其中維語詞性標注方法采用基于Bi-LSTM-CRF 的詞性標注方法實現的[10],準確率達到了98.41%。針對三組訓練語料,本文采用期望交叉熵方法進行特征選擇,特征空間的維度為5000 維,用VSM 向量空間模型將文本向量化,然后利用KNN、SVM、決策樹、邏輯回歸、隨機森林的方法,進行實驗對比,實驗結果如表3。

表3 基于機器學習分類算法的實驗結果
其中T 表示的是訓練耗時單位為時分秒格式,DTree 代表決策樹算法、LR 代表邏輯回歸算法、RFR代表隨機森林算法下同,從表3 可以看出,第三組訓練語料在KNN、SVM、邏輯回歸和隨機森林算法上,F1 的值比在其他兩組語料上結果要好,在決策樹算法上略低于第二組訓練語料,在訓練耗時的比較上第三組語料花費的時間也略低于其他兩組。實驗結果表明直接通過過濾詞性提取特征,對文本分類實驗結果影響不大,只篩選出名詞詞性的第三組語料實驗結果在多數情況下比篩選名詞、動詞、形容詞的第二組語料和只去除停用詞的第一組語料相比分類效果較好,耗時較短,為了繼續研究是哪些詞匯在影響分類的結果,本文對三組實驗的特征集(分別為5000 個詞匯)取交集得到3078 個詞匯作為特征空間,繼續進行實驗,實驗結果如表4 所示。

表4 縮小特征空間后的基于機器學習分類算法的實驗結果
從表4 可以看出利用三組實驗特征集合的交集作為特征空間的方法在訓練語料一上表現最好,將上面兩表中的最好實驗結果以及對應訓練耗時進行對比,如表5、表6 所示。
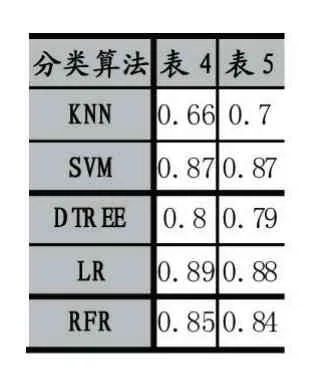
表5 兩組最好分類結果對比

表6 兩組實驗訓練耗時對比
由表5、表6 可以看出,通過取三組訓練語料特征集合的交集得到的特征集合與三組語料分別進行特征提取再訓練的實驗結果沒有太大的差別,但卻大大縮短了文本分類實驗的訓練時間。
為了更好地對比詞性因素對文本分類實驗的影響,本文還采用了深度學習中的CNN、RNN、CNNBLSTM 方法進行比較,在文本向量化時,我們選擇采用的是字符向量化的方法。

表7 基于深度學習分類算法的實驗結果
由表7 可以看出在基于神經網絡的文本分類中,第一組語料在CNN 上的實驗結果略高于其他兩組訓練語料,但第三組語料的訓練時間較短,并且第三組語料在RNN、CNN-BLSTM 上表現高于其他兩組訓練語料,訓練時間也較短。以上實驗表明根據詞性過濾后的神經網絡分類算法實驗,在準確率相差無幾的情況下,卻可以較大程度上縮短訓練時間。
3 結語
實驗結果表明名詞對維語文本分類的影響最大,動詞、形容詞等對文本分類的貢獻較小。通過期望交叉熵的方法,進行特征提取,可以有效的提取出對分類貢獻高的詞匯,但通過詞性篩選又可大大降低特征空間的維度,大幅縮短訓練時間,并且在一些方法上提高了文本分類實驗的效果。本文在研究過程中并未采用控制變量法逐一證明各個詞性對文本分類的影響,只是通過詞性為名詞、動詞、形容詞的詞匯包含更多的文本信息這一先驗知識的基礎上進行的實驗對比。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
