基于NIR和PLS-DA法的東北大米產地快速溯源方法研究
2019-08-19 07:48:06吳靜珠劉翠玲于重重
中國糧油學報 2019年7期
高 彤 吳靜珠 林 瓏 劉 志 劉翠玲 于重重
(北京工商大學食品安全大數據技術北京市重點實驗室1,北京 100048)(浙江省農業科學院農業部農產品信息溯源重點實驗室2,杭州 310021)
大米在中國的經濟市場中起著非常重要的作用。大米的價格和質量與其產地息息相關,東北大米憑借其地理優勢不但保證了大米特有的高品質,而且其價格遠高于市場中同類普通產品。但是由于我國農產品市場準入制度和溯源體系的不完善,目前市場上出現東北大米“摻偽”“假冒”等現象,因此大力發展產地溯源技術對于保護地區名牌和特色產品以及質量管理部門的有效監管都具有十分重要的意義。
目前國內主流的產地溯源技術主要有礦物元素指紋分析技術、同位素指紋溯源技術、DNA指紋圖譜技術[1]、紅外光譜技術[2]等。其中近紅外光譜技術因其具有適應范圍廣、采集信息量大、分析速度快、無損無污染[3]等優點,成為了快速溯源技術的研究熱點。農作物中有機組分的組成及含量與其產地環境的特征關系密切,不同地域來源的農作物中化學成分含量及組成均存在差異,因此農產品的近紅外光譜能夠反映產地的地域特征信息,可用于產品的產地鑒別。目前已有學者將近紅外光譜用于大米產地溯源探索研究。錢麗麗等[4]將近紅外光譜與PLS-DA法結合用于黑龍江省內5個水稻主產區的大米粉末樣品的產地判別, 5個地域的預測正確率分別為87.5%、87.5%、100%、100%、100%。宋雪健等[5]利用傅里葉變換漫反射近紅外光譜法結合PLS-DA法、因子化法對來自2014年、2015年的地理標志產品查哈陽大米和五常大米進行產地溯源檢測,正確率均在90%以上。
近紅外光譜技術應用于大米產地快速溯源已取得了初步的成效,然而現有研究主要集中在某幾個知名的東北大米產區間的產地鑒別,大米品種較為單一,且大米產地溯源模型的適用性較窄。東北大米產地涵蓋了黑龍江省、吉林省和遼寧省,品種也較為繁多,主流的有長粒香、圓粒香、稻花香和小町米等。東北大米產區自然環境不盡相同且大米品種豐富多樣,這都會引起大米近紅外光譜顯著的差異,進而影響到大米近紅外產地溯源模型的準確性和適用性。因此本研究采用NIR和PLS-DA建立判別東北大米產地的溯源模型,通過光譜信號預處理和光譜分段建模方法優化東北大米產地鑒別模型,以期為東北大米產地溯源提供一種快速、無損的分析方法。
1 材料與方法
1.1 實驗材料
本實驗大米樣本由浙江省農業科學院提供,共收集產地為東北的大米樣本52份,非東北產地大米樣本23份,共計75份樣本產地信息如表1所示。
按照4∶1的比例隨機劃分訓練集和測試集,其中訓練集樣本60份(東北大米樣本43份,非東北大米樣本17份);測試集樣本15份(東北大米樣本10份,非東北大米樣本5份)。

表1 樣本統計信息
1.2 儀器與設備
采用德國BRUKER公司的VERTEX 70傅里葉變換紅外光譜儀[6]。
1.3 光譜采集及預處理
實驗采用大樣品杯旋轉采樣方式,裝樣前仔細篩查,剔除夾雜物以避免干擾,盡量保證每份樣本裝在樣品杯中的高度一致。儀器參數設定如下:波數范圍為4 00012 500 cm-1,分辨率為8 cm-1,掃描次數為64次,采樣點數為2 074。大米樣本的原始近紅外光譜圖如圖1所示(黑色光譜為東北大米,紅色為非東北大米)。

圖1 大米近紅外原始光譜圖
由于原始數據存在明顯的基線漂移和噪聲,因此采用一階導(9點)、二階導(9點)、SG平滑(9點)和矢量歸一化等方法進行光譜預處理。如圖2所示,經矢量歸一化處理后的譜圖光譜質量得到了明顯改善。

圖2 矢量歸一化后近紅外光譜圖
1.4 PLS-DA判別法
PLS-DA 判別分析法是一種基于偏最小二乘法(partial least squares,PLS)的有監督的模式識別方法,將光譜數據與分類變量進行線性回歸。對不同處理樣本(如觀測樣本、對照樣本)的特性分別進行訓練,產生訓練集,并檢驗訓練集的可信度。本研究應用PLS-DA 方法同時對光譜陣和類別陣進行分解,加強了類別信息在光譜分解時的作用,以提取出與樣本類別最相關的光譜信息,即最大化提取不同類別光譜之間的差異[7-9]。
2 結果與討論
2.1 基于不同預處理方法的東北大米產地溯源模型比較
實驗采用常規的一階導(9點)、二階導(9點)、SG平滑(9點)和矢量歸一化方法分別進行數據預處理。將賦值的地域作為分類變量Y,近紅外光譜數據作為分類變量X[12],建立分類變量Y(地域)與X(預處理后的近紅外光譜)的PLS-DA判別模型。R2是擬合的度量,即模型與數據的擬合程度。R2越大,說明近紅外光譜經過預處理后模型準確度越高。根據已建的PLS-DA模型計算R2值,如表2所示。根據表2可得,矢量歸一化后的R2(x)、R2(y)綜合值最大,因此首先應用矢量歸一化進行數據預處理。

表2 不同預處理方法的R2值
對光譜進行歸一化預處理后需要確定用于建立模型的最佳主成分數,理論上應選擇訓練集效果好的為最佳主成分數,但是主成分數過大,圖譜會出現過擬合現象;主成分數過少,圖譜則出現欠擬合現象[11]。根據表3所示,主成分位數為1的時候,測試集正確率較好,但是訓練集正確率不理想,呈現欠擬合現象。隨著主成分位數的增加,訓練集正確率呈現上升趨勢,在主成分位數為5的時候雖然訓練集正確率達到98.33%,但是測試集正確率下降,可是能過擬合的原因,見表3所示。因此,本實驗中PLS-DA模型可確定選取主成分數為4。
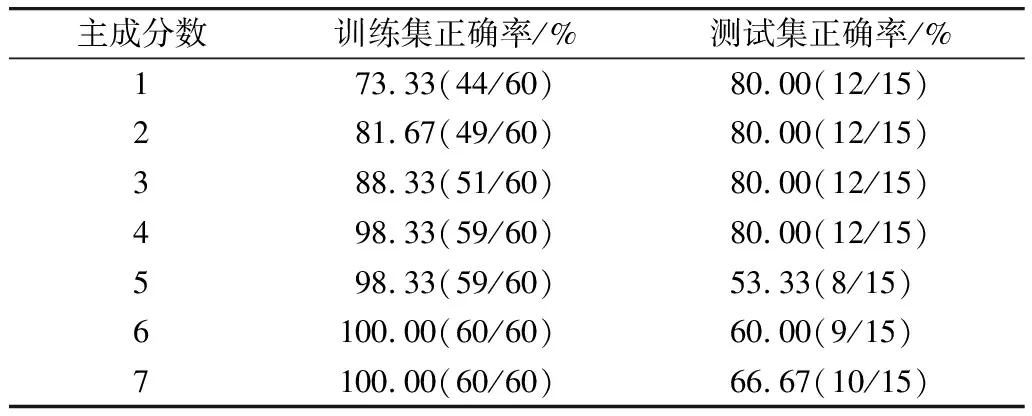
表3 不同主成分數訓練結果
2.2 基于分段譜區的大米產地溯源模型比較
在4 000~12 000cm-1范圍內,大米近紅外光譜總體呈現上升趨勢,在5 173、6 846、8 318 cm-1處有明顯的波峰。其中4 000~5 500 cm-1處是C-H第1組合頻譜區,表征蛋白質及淀粉物質中N-H、C-H、O-H及C=O鍵振動的要區間,其中5 173 cm-1處的吸收峰與其有關;5 500~7 500 cm-1處是C-H第2組合頻區,在6 846 cm-1附近的吸收峰是因-CH2二級振動引起的,因與樣品中氨基酸種類及含量有關,所以較7 500-9 000 cm-1信息稍微強些;波段7 500~9 000 cm-1處是C-H第3組合頻區,其中8 318 cm-1附近的吸收峰是由脂肪烴中甲基(-CH)基團引起的[14]。由于不同波段所含信息不同,故訓練效果不同,按照4個譜區分段(如圖3所示)后,建模結果如表4所示。

圖3 波段劃分圖
表4 分段建模訓練結果

波段(cm-1)訓練集識別率/%測試集識別率/%4 000~5 50093.33(56/60)86.67(13/15)5 500~7 50093.33(56/60)80.00(12/15)7 500~9 00095.00(5760)66.67(10/15)9 000~12 00098.33(59/60)80.00(12/15)全波段98.33(59/60)80.00(12/15)
基于特征波段的訓練,最終選取結果較好的4 000~5 500cm-1作為最終模型。訓練集正確率達93.33%,測試集總數為15個,正確判別13個,正確率為86.67%。
3 結論
采用PLS-DA方法結合近紅外光譜建立東北大米產地快速溯源模型,通過比較不同光譜預處理方法、不同特征譜區分段建模方法優化模型的準確性和適用性。實驗最終選取矢量歸一化預處理方法、4 000~5 500cm-1特征光譜譜區和PLS-DA方法建立判別東北大米產地的二分類定性分析模型,訓練集識別率達到93.33%,測試集識別率達到86.67%。初步的實驗結果表明了采用近紅外技術和化學計量學方法快速溯源東北大米產地的可行性,但是鑒于實驗訓練樣本還不夠充分,后續有待補充實驗樣本,進一步提升模型質量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
