大數據背景下的學生孤獨預警模型
2019-09-10 07:22:44余琳許婷李超廖莉莉許可解攀科
現代信息科技 2019年23期
關鍵詞:大數據
余琳 許婷 李超 廖莉莉 許可 解攀科
摘? 要:大數據時代背景下,關注大學生心理健康,要借用技術手段科學、客觀推進大學生心理健康教育工作。目前研究學生心理健康大多采用問卷調查的形式,所得結果取決于被調查者的填寫情況,不一定真實反映其內心的想法,并且調查個案有限,不能很好地反映總體情況。本文以華中師范大學為例,通過一卡通消費明細、圖書門禁明細得出學生間的共現頻率,從而得出學生的朋友關系表,得到疑似孤獨者名單,結合學生的就業情況,得出朋友關系較少的學生未就業率高于朋友關系多的結論;再運用DecisionTreeClassifier模型,挖掘出各個指標對就業成功的影響力,并基于訓練好的模型預測哪些學生有就業失敗的可能,可作為重點關注對象。分析結果與日常生活反饋較一致,對于應用大數據在高校學生管理工作有一定的借鑒作用。
關鍵詞:大數據;朋友關系;消費關系;圖書館關系;決策樹算法;各指標影響力
中圖分類號:TP183? ? ? ?文獻標識碼:A 文章編號:2096-4706(2019)23-0001-04
Early Warning Model of Students’Loneliness under the Background of Big Data
——Taking Central China Normal University for Example
YU Lin,XU Ting,LI Chao,LIAO Lili,XU Ke,XIE Panke
(Information Office of Central China Normal University,Wuhan? 430079,China)
Abstract:Under the background of the era of big data,paying attention to the mental health of college students,it is necessary to use scientific means to scientifically and objectively promote the mental health education of college students. At present,the research of students’mental health mostly adopts the form of questionnaire survey,which depends on the filling of the respondents,not necessarily reflect their inner thoughts,and the investigation cases are limited,which can not reflect the general situation well. This paper takes Huazhong Normal University as an example,through the details of the consumption of smartcard and the access details of the library to get the list of students friendship,and get the list of suspected lonely students. Combined with the employment situation of students,it is concluded that the unemployed rate with fewer friends is higher than that of friends;using the DecisionTreeClassifier decision tree model to discover the influence of various indicators of employment success,and predicting which students fail in employment based on the trained model can be the focus of attention. The analysis results are consistent with the daily life feedback,and it has certain reference for the application of big data in the management of college students.
Keywords:big data;friend relationship;consumption relationship;library relationship;decision tree algorithm;influence of various indicators
0? 引? 言
在大數據時代背景下,應用數據說話,應有效利用數據挖掘和學習分析產生迄今看不見、不被注意的數據與結論,為高校管理工作提供新思路。盡可能地收集全面的數據,再進行分析、挖掘,客觀找出疑似孤獨者名單,幫助就業處、院系輔導員查找可能存在問題的學生、提前做好心理健康指導、就業幫扶,物質幫扶等工作,幫助這些學生學會與人溝通交流,紓解心理抑郁,引導學生高質量就業、高幸福感生活,提高學生心理健康危機預警實效性。
1? 現狀分析
2011年2月23日,教育部印發了《普通高等學校學生心理健康教育工作基本建設標準(試行)》的通知,推進大學生心理健康教育工作科學化建設,強調要加強大學生心理危機預防與干預體系建設[1]。目前我國各高校相繼開展了心理健康普查工作,有關調查結果表明:大學生的心理健康狀況較差,經常存在心理問題的大學生約占總數的1/5,而有時有心理問題者則高達2/3左右。常有孤獨感的大學生約占28.6%,少有孤獨感的約占31.7%,從未感到孤獨的學生幾乎沒有[2-4]。孤獨、消極的情緒如抑郁、自卑,會危害學生身心健康,影響學習、生活和就業發展。目前研究學生心理健康的論文大多采用調查問卷的形式,得到的結果取決于被調查者的填寫情況,不一定真實反映了其內心的想法;并且問卷調查的個案較少,較難保證每個學生都填寫問卷,不能很好反映總體。
2? 研究內容
各高校主要是通過新生入學時的心理疾病篩查、日常學生間的反饋和心理輔導站老師的心理訪談發現與解決學生心理健康問題,出于保護隱私的考慮,大多高校的學生心理診斷結果及問題名單并未公布,缺乏基礎數據源,心理健康的特征難以量化。
本文以華中師范大學為例,采集了2011~2015級共22448名本科生的學生基本信息(性別、民族、生源地、政治面貌、婚姻狀況、是否獨生子女等)、學籍信息(所在年級、院系、入學年月)、家庭經濟情況(是否低保、家庭類別、家庭人口、家庭收入來源等)、畢業生求職信息(是否就業、就業年度)、學習成績信息(課程成績、學分)、獎學金信息(獎學金次數及金額)、榮譽獎勵信息(次數)、圖書借閱信息(借閱數量)、一卡通消費信息、圖書館門禁信息十大數據,其中2011~2014級的本科生17828人,1127人未就業。本文尋找孤獨的人,孤獨特征難以定義,直接尋找難度較大,研究思路采用排除法,先找出不孤獨的人,再用全體減去不孤獨的人,即是孤獨的人,再去驗證。
不孤獨即朋友關系多,有朋友一起吃飯、一起去圖書館,用數據特征表示即是同一食堂刷卡時間接近且次數較多、進入圖書館刷卡時間接近且次數較多。如果刷卡時間接近的定義過大則會導致朋友關系網過大、計算量太大;如果刷卡時間接近的定義過小則會導致朋友關系網較小,過濾了原本是朋友的人;考慮日常的實際食堂消費情況,一起去同一食堂可能不同窗口刷卡,刷卡時間相差不會太大,故本文將刷卡時間接近定義為5分鐘內。
2.1? 數據處理
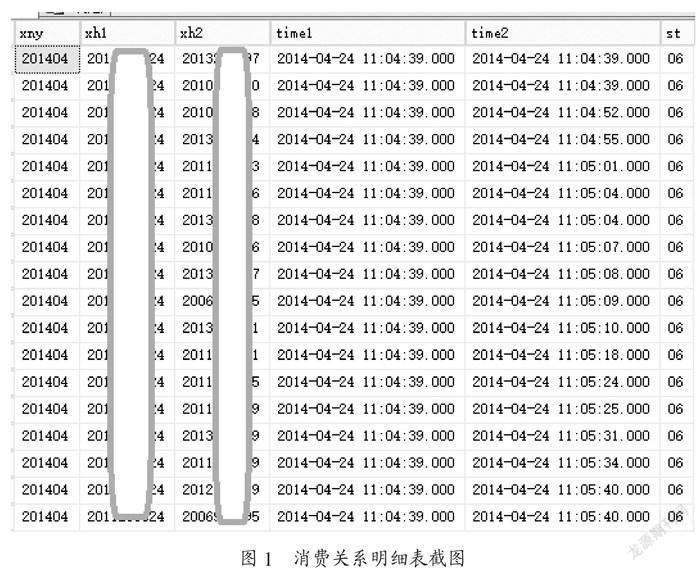
一卡通消費信息每月約200萬條明細數據,計算同一食堂任意兩個刷卡時間在5分鐘內的學生人數的記錄數較多,因數據量較大,選取每個年級在大三4、5、6三個月的消費記錄作為樣本數據,尋找消費朋友關系網。2011級學生對應的是2014年4、5、6三個月消費關系明細,2012級學生對應的是2015年4、5、6三個月消費關系明細,2013級學生對應的是2016年4、5、6三個月消費關系明細,2014級學生對應的是2017年4、5、6三個月消費關系明細,2015級學生對應的是2018年4、5、6三個月消費關系明細。消費關系明細表結構如圖1所示,xny代表每月,xh1代表2011級的某個學生,time1代表xh1學生的消費刷卡時間,xh2代表與xh1消費時間5分鐘內的所有學生,time2代表另一學生的消費刷卡時間且與time1相隔5分鐘之內,st代表食堂編號。
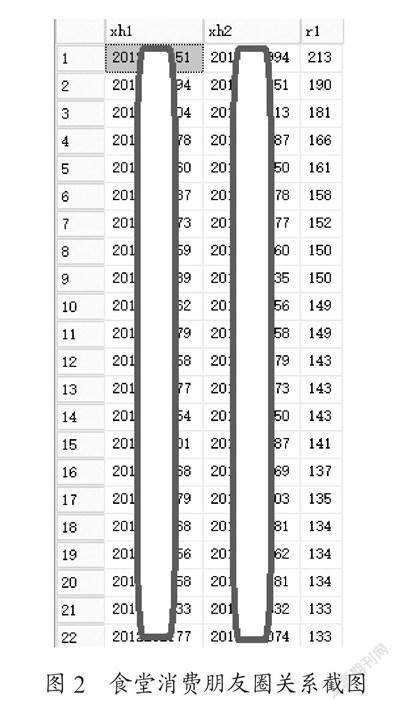
基于此消費關系明細表統計每個食堂的相遇關系,即統計兩兩相遇的次數及在該食堂消費的總次數。再將各食堂的相遇關系明細取相遇次數大于10的,unionall得到總消費次數表,再按xh1、xh2分組求和,形成食堂消費的朋友圈關系,如圖2所示。
基于此方法同樣可以得到圖書館的朋友圈關系。
2.2? 數據分析
根據得到的食堂消費的朋友關系表和圖書館的朋友關系表,隨意挑選幾組學生數據,通過其基本信息聯系其輔導員及同年級學生,分析并驗證是否是真的朋友關系。
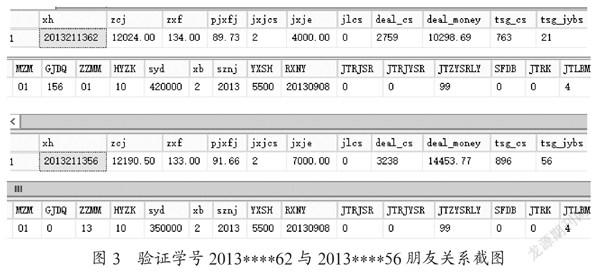
學生2013****62與學生2013****56,圖書館相遇273次,同一食堂相遇次數149次。通過學生基本表找出兩個人的特征如圖3所示,這兩個女同學都來自經濟與工商管理學院,平均學分績都很高,都得了兩次獎學金,一個7000元,一個4000元。一個是群眾,一個是共產黨員,都是漢族,都來自于城鎮。一個是福建人,一個是湖北人。都順利就業。
學生2012****51與學生2012****94,同一食堂相遇次數213次,圖書館相遇22次。通過學生基本表找出兩個人的特征,發現這兩個學生都來自社會學院,都得了兩次獎學金,都是2000元。一個是群眾,一個是共產黨員,都是漢族,來自于非貧困縣和城鎮(都不是來自農村或大城市的)。一個是河北人,一個是山東人。都順利就業。
學號2014****58與2014****81,同一食堂相遇次數134次,圖書館相遇20次。發現這兩個學生都來自計算機學院,都是漢族,一男一女,平均學分績都不高,一個78.15,一個75.72,兩個人都沒有順利就業。經輔導員驗證,確實為男女朋友。
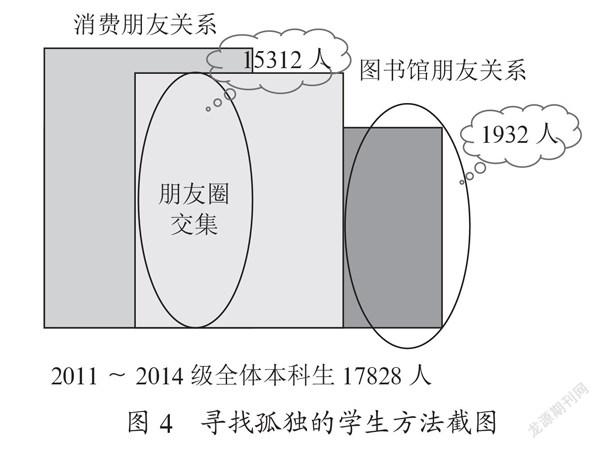
經驗證,以上隨機挑選的三組朋友關系,均確實屬于真正的朋友關系。再回到本項目中,采用排除法,尋找孤獨的人。以2011~2014級全體本科生作為樣本數據,共17828人,有食堂消費朋友關系表的有20585人,有圖書館的朋友圈關系表的有43840人(此處兩個數字均大于樣本數據17828,是因為按照前文提到的數據處理原則,2011~2014級的全體本科生作為xh1,xh2可為符合刷卡時間范圍內的全校師生,并不局限于同年級的學生),食堂消費朋友關系與圖書館的朋友圈關系取交集得到朋友較多的有15312人,既不在食堂消費朋友關系表中,也不在圖書館的朋友圈關系表中的有1932人。具體如圖4所示。
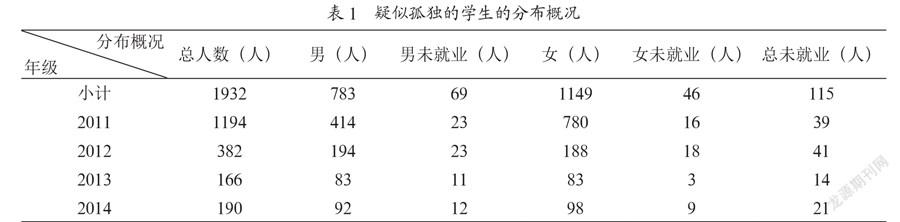
關聯學生的就業信息數據,將疑似孤獨的學生1932人按年級性別查看學生分布概況,如表1所示,115人未就業,未就業率5.95%。其中2011級疑似孤獨的學生就有1194人,占一半以上,但華中師范大學圖書館是2015年4月才安裝門禁的,也就是說門禁數據是2015年4月以后才有的,而按照前面的規則,2011級大三時應對應2014年的門禁數據,故2011級學生的圖書館朋友圈關系可能不準確。將2011級的孤獨人數1194人減掉還剩738人,其中76人未順利就業,未就業率10.30%。而朋友關系較多的15312人中只有608人未順利就業,未就業率3.97%。可得到結論:朋友關系較少的學生未就業率高于朋友關系多的學生。
2.3? 數據驗證
通過食堂消費朋友關系與圖書館的朋友關系可以得出朋友關系少的學生名單,關聯學生就業數據可以得出朋友關系少的就業失敗可能性高于朋友關系多的結論,但如果能通過算法正面驗證就業失敗有哪些影響因素,則可能更有利于證明結論的可信性。
通過前面的收集的樣本數據,2011~2014級四年的本科學生名單17828人,1127人未就業。將就業是否成功作為目標變量,將25個指標(性別、民族、生源地、國籍地區、政治面貌、婚姻狀況、所在年級、院系、入學年月、是否低保、家庭類別、家庭人口、家庭人均收入、人均月收入、家庭主要收入來源、畢業年度、總成績、總學分、獎學金次數及金額、榮譽獎勵次數、圖書借閱數量、一卡通消費次數及金額信息、圖書館門禁次數)作為自變量,使用決策樹模型,找出哪些指標是影響就業成功的因素。
決策樹是機器學習中常見的一種用于分類和回歸的非參數監督學習方法,目標是創建一個模型,通過從數據特性中推導出簡單的決策規則來預測目標變量的值。決策樹便于說明和理解,樹可以可視化表達;需要的數據準備不太難。故本項目使用python的機器學習算法庫scikit-learn中的DecisionTreeClassifier算法。
調用算法之前,我們把數據隨機分為訓練集和測試集,采用train_test_split隨機劃分函數,訓練集的數據主要用于構造決策樹,測試集主要用于計算錯誤率,看分析訓練后的決策樹模型能不能使用。
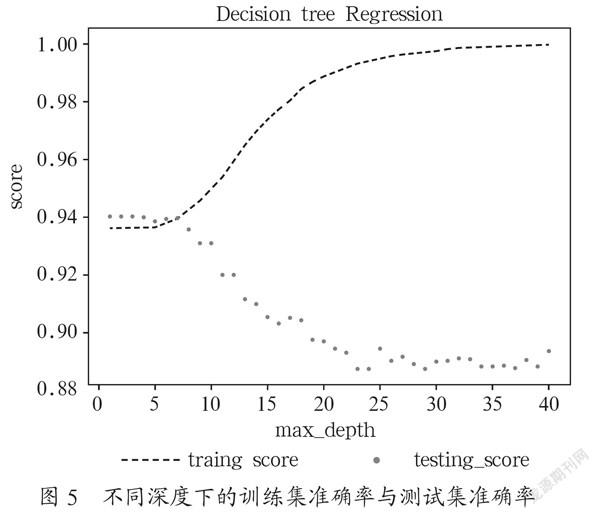
決策樹數據模型中樹的最大深度是一個關鍵參數,深度設置較小,會導致欠擬合,訓練集的錯誤率較高;深度設置較大,會導致過擬合,訓練集的正確率很高,但測試集的錯誤率較高。想要較好地調研決策樹分類算法,首先需要找到一個合適的max_depth值。
將最大深度設為1~40,計算每個值的預測情況并畫圖,所得結果如圖5所示。
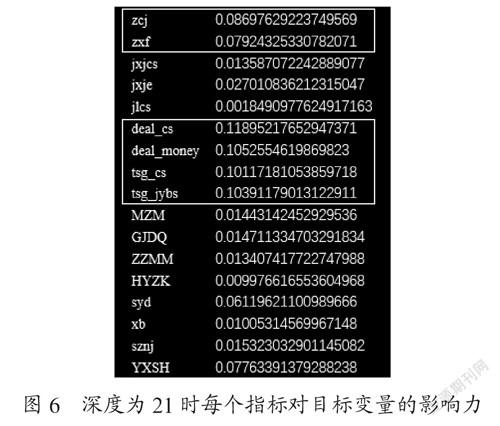
根據圖5,選取max_depth=21,再進行模型訓練,計算每個指標對目標變量的影響力。得到訓練集準確率0.9859,測試集準確率0.8937,以及每一個指標對目標變量的影響力。如圖6所示,發現deal_cs、deal_money、tsg_cs、tsg_ jybs(消費次數、消費金額、進入圖書館次數、圖書借閱本數)四個指標對就業是否成功的影響力相對較大,其次是zcj、zxf(總成績、總學分)。再次驗證了之前的結論,就業失敗可能性與消費關系及圖書館關系有相關性。
3? 應用與驗證研究
預測2015級本科生情況(總4620人),首先找出不在消費朋友關系表和圖書館朋友關系表中的名單,有500人,可得到疑似孤獨者名單。再用這500人名單用之前訓練的決策樹模型去預測就業失敗的人數,發現基于此模型,有153人會就業失敗,可被認為是重點關注孤獨對象。為了實際驗證模型的準確性,將153人按院系進行分布,其中計算機學院有11人,經輔導員與同學反饋,其中1人是2014級降級下來的,另10人中有2人確實存在某些問題,其余8人不明顯。
本項目研究主要采用的是校內數據,如果吃飯作息規律與一般人不同的,比如點外賣,外賣網絡數據暫時獲取不到,可能也會被該模型列為孤獨者名單。本項目的研究目的是通過大數據客觀找出孤獨者名單,幫助校方盡可能大范圍地為學生提供心理及就業幫扶,供學院領導決策并做出積極干預。
4? 結? 論
大數據給高校的學生管理工作帶來了機遇和挑戰,完成對學生管理數據的采集和分析體系的建設,才能科學地劃分學生群體。[5]本文通過數據獲取、數據處理、數據分析到數據驗證等一系列環節,充分利用一卡通消費時間數據與門禁刷卡時間數據,充分挖掘數據中的時間關系,找出朋友關系,再結合決策樹算法,得出了就業失敗的預測模型,為大數據時代的高校管理工作者提供了一個預警的解決思路。
參考文獻:
[1] 中華人民共和國教育部.教育部辦公廳關于印發《普通高等學校學生心理健康教育工作基本建設標準(試行)》的通知 [A/OL].(2011-02-23).http://www.moe.gov.cn/srcsite/A12/moe_1407/s3020/201102/t20110223_115721.html.
[2] 郭晉武,佘雙好.大學生身心健康狀況調查的初步報告 [J].青年研究,1992(6):19-24.
[3] 鄭延芳,周慶云.大學生身心健康狀況及其影響因素研究 [J].現代預防醫學,2008,35(24):4825-4827.
[4] 溫展明,張珂.大數據分析理念在高校學生工作中的應用 [J].開封教育學院學報,2018,38(2):138-139.
[5] 單耀軍.大數據背景下高校學生管理信息化研究 [J].教育與職業,2014(23):27-29.
作者簡介:余琳(1988-),女,漢族,湖北武漢人,中級工程師,工學碩士,研究方向:大數據分析、數據治理、情報分析。
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
