基于情感分析算法在笑聲音頻檢測與應用的探索
2019-09-10 07:22:44鄒宇驍
高考·中 2019年2期
摘 要:探索笑聲的情感分析算法是有意義的研究。本文介紹了笑聲心理特征,笑聲識別的基本原理,特征提取、計算模型和數據集情況,提出若干問題及可能的解決方案,并在此基礎上探討了研究應用和發展前景。
關鍵詞:笑聲音頻檢測;情感分析算法;笑情感測量計
引言:笑聲情感自動識別是指:根據笑聲的音頻數據和其他相關信息構建計算模型,實現笑聲情感自動判別的過程。笑聲情感識別技術涉及多個領域,包括認知科學、心理學、生理學、聲學、音頻信號處理、自然語言處理和機器學習等,是一個多學科交叉的研究領域。音頻信號大致可以分為三類:語音、音樂和環境聲音。語音、音樂和環境聲音具有顯著不同的特性,因而通常分為三種不同的情形進行處理,不同音頻類型需要不同的檢索和語義分析技術,本文以笑聲(語音)的音頻特征,探索適應該特征的處理、檢索和情感分析技術。
1.笑聲分析
1.1笑聲的心理分析
笑是人的本能反應,是情緒或者情感變化的一種重要表現形式,笑通常是一種積極快樂的情緒反映,但你遇到高興的事情時,你會以笑來表現內心的歡快,或者以笑來表達自己快樂和滿意的心情。笑通常分為兩種:一種是無聲的微笑,一種是有聲的笑。有聲笑根據情緒的高低、快樂的程度分為三種:小笑“XiXiXi(嘻嘻嘻),中笑”kekeke(呵呵呵),大笑“hahaha”(哈哈哈)。三種有聲的笑反映人情感的三個維度或者開心的指數,這種情感的維度或者開心指數是可以通過笑音頻分析計算出來的。
1.2笑聲音頻分析
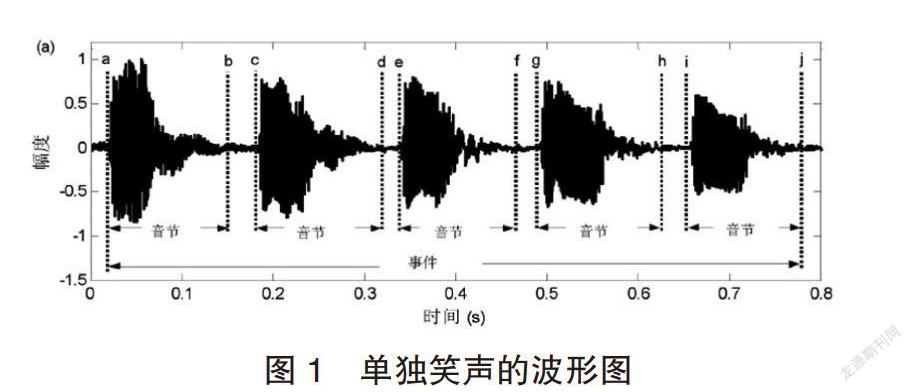
一次完整的笑聲過程被稱為一個“笑聲事件”,構成一次完整笑聲的各個相鄰信號段被稱為一個““音節幀袋”(bag of frames)或“音節”,這兩個術語是分析笑聲的特性,笑聲音節跟語音音節一樣,也是由濁音成分和清音成分組成的信號段。笑聲事件即一次完整的笑聲過程,由相鄰的笑聲音節構成。例如,一次完整的笑聲過程通常標注為“ha haha”、“kekeke”或者“XiXiXi”。笑聲事件就是指與標注“hahaha”“kekeke”或者“XiXiXi”對應的波形信號段;笑聲音節則是指與某個標注“ha、ke或者xi”對應的波形信號段。單獨笑聲由相鄰的獨立笑聲音節組成,一般是由一個人發出的,圖1給出了一個單獨笑聲的波形圖。
1.3笑聲情感識別系統框圖
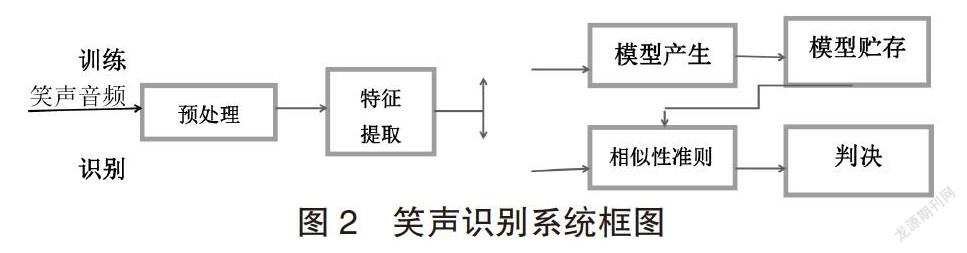
圖2為笑聲識別系統框圖。和語音識別系統一樣,建立和應用這一系統可分為兩個階段:訓練階段和識別階段。在訓練階段,系統的每個使用者說出若干笑聲,系統據此建立每個使用者的模板或模型參量參考集;而在識別階段,待識別笑者中導出的參量要與訓練中的參考參量或模板加以比較,并且根據一定的相似性準則形成判斷。
2.笑聲情感識別
2.1特征提取
笑聲情感識別常用的音頻特征是以“音節幀袋”方式提取的,但是這種特征提取方法忽略了笑聲的時間結構。然而,笑聲隨時間呈現的變化,對笑聲情感識別來說可能很重要。為了驗證時間信息對預測音樂表達的情感的重要性,可以將笑聲變成一個特征向量時間序列。用生成式模型(向量空間模型、馬爾可夫和隱馬爾可夫模型)來表示該時間序列(這些模型都基于特征向量量化結果),通過使用概率乘積核,將生成式模型用于情感區分任務,這樣時間信息利用后,情感預測性能得到提高。
2.2笑聲情感模式的選擇
笑聲情感表示是情感心理學研究的一個新課題.相關研究不多,但已經有多種方案音樂情感識別和人語言情感識別的方法可供研究人員來選擇。從情感識別的角度看,情感空間可以用離散類別模型或連續維度模型來表示,這樣情感識別問題就分別對應到機器學習的分類問題或回歸問題。
對比其他情感識別方法,笑聲情感模型使用的是通用連續維度情感模型,因為通用連續維度模型將人類情感狀態表示為二維或三維連續空間中的點。這種維度模型的優點在于,它可以描述和刻畫情感狀態的細微差別,描述笑聲情感時更準確、更細致,與人的笑情感體驗更一致。
被廣泛采用的通用連續維度模型是環形(circomlex)模型(也稱為VA模型)和PAD模型。環形情感模型認為情感狀態是分布在一個包含效價度(快樂基調程度)(valence)和激活度(arouala)的二維環形空間上的點(參見圖1).其中縱軸表示激活度,橫軸表示效價度。
針對笑聲識別以及檢測問題,近些年來已有一些人員在不同的方面進行了相關研究。Gouzhen An等考慮到笑聲波形結構,提出類基于音節的笑聲檢測方法。該實驗首先以幀為單位,提取上述常用特征并使用SVM分類算法得到最初的每幀的分類結果。然后再基于韻律特征對數據進行音節劃分對再對上述基線系統的分類結果進行重新打分以得到優化的結果。該方法充分考慮了笑聲的結構特征,即每個笑聲事件均由數個相鄰的音節組成,使得笑聲識別系統的性能有了明顯的提升。
2.3笑聲情感高斯模型
每個人笑聲對情感標注經常是有所不同的,他們為概率分布,聲音情感高斯(Acoustic Emotion Gaussians,AEG)模型較好的解決了這一問題,AEG模型的一個好處就是便于針對具體用戶構建個性化情感識別模型,采用AEG模型來為VA笑聲情感識別建模,并且提出一個基于線性回歸的調整方法來對一般模型進行個性化調整。
3.基于笑聲音頻算法的實驗設計
3.1算法選擇
搜索了文獻發現,目前尚無針對單個笑事件的笑聲音頻算法,多數笑情感算法是在連續語音中的笑聲檢測,或者在環境聲音笑聲檢測,但這些算法給我們提供了有意義的參考。
本研究以單個笑事件的笑聲音頻“音節幀袋”的連續性情感模型和笑聲情感高斯模型為特征,應用極限學習機(ELM)算法實現笑事件的笑聲檢測。
3.2ELM算法特點
ELM是一種新型神經網絡算法,它的特點是簡單易用、有效的單隱層前饋神經網絡SLFNs學習算法,相比傳統神經網絡,需要人為設置大量的網絡訓練參數,并且很容易產生局部最優解的缺點。ELM的訓練速度非常快,需要人工干擾較少,對于異質的數據集其泛化能力很強。對于單隱層神經網絡,ELM可以隨機初始化輸入的權重以及偏置從而得到相應的輸出權重,在算法執行過程中不需要調整網絡的輸入權值以及隱元的偏置,并且產生唯一的最優解,因此具有學習速度快且泛化性能好的優點。
4.應用
笑情感識別研究的最終目的創造一種人“笑情感測量計”,因為笑可以給人類帶來智慧和力量,有助人的身體健康和控制情緒的作用,有一個“笑情感測量計”就像一個溫度計一樣時時刻刻可以客觀評價人的情感維度和開心指數。開心的情緒和情緒的控制對于我們每個人的健康生活,預防和治療疾病,幸福感;對于我們和諧家庭的夫妻關系、親子關系;對于我們工作的人際關系等等方面都將起到意想不到的作用。特別是它可以將每時每刻,每分每秒,每日每月,每年的“笑情感”記錄、分析和總結,這樣大大地提高人機互動的效果。
研究工作展望:人類的笑情緒表現主要有三種:笑聲表情、面部笑表情和身體笑姿態表情。身體笑姿態表情(如手勢、運動姿勢)變化的規律性難以獲取,因而笑情感識別的研究目前主要側重于笑聲情緒和面部笑表情的識別。對笑聲情緒的識別,通常被稱為“笑聲情感識別”;對面部表情的識別,通常被稱為“人臉笑表情識別”。盡管從笑聲情感獲取的音頻信息和面部笑表情獲取的視覺信息在進行情感識別時所起的作用都很大,但這二者各有自己的優缺點,也有著某種程度的互補作用。為了在言語情感和面部表情之間取長補短,因而未來有必要將笑聲情感識別技術和人臉笑表情識別技術融合在一起,以便對人類笑情感的類別進行更有效地判定。這就是所謂的“多模態笑情感識別”,即同時融合多種表情(如言語表情和面部表情)的情感識別,形成一種全方位的人笑情感測量計。
參考文獻
[1]孔維民.情感心理學新論[M].長春:吉林人民出版社,2002.
[2]詹姆斯.薩利.笑得研究-笑得笑聲、起源、發展和價值[M].北京:中國社會科學出版社,2011.
[3]徐利強,謝湘,黃石磊,李通.連續語音中的笑聲檢測研究與實現[J].聲學技術,2016,35(s6):581-584
[4]孫守遷,王鑫,劉濤,等.音樂情感的語言值計算模型研究[J].北京郵電大學學報,2006,29(s2):34-41
[5]陳曉鷗,楊德順音樂情感識別研究進展[J].復旦學報(自然科學版) 2017,56(s2):138—142
[6]鄒宇驍(2001--),男,湖南郴州市人,郴州市第一中學
