基于多融合模型的圖像語(yǔ)義描述研究
2019-09-10 07:22:44王媛華
河南科技 2019年14期
王媛華


摘 要:圖像語(yǔ)義描述可以自動(dòng)生成圖像的自然語(yǔ)言描述,對(duì)場(chǎng)景理解具有重要意義。本文主要針對(duì)圖像語(yǔ)義描述的特征學(xué)習(xí)和語(yǔ)義學(xué)習(xí)等進(jìn)行改進(jìn),提出一種新的多融合模型。實(shí)驗(yàn)結(jié)果表明,本文提出的模型有較好的描述效果,但模型在訓(xùn)練時(shí)時(shí)間過(guò)長(zhǎng),有待改進(jìn)。
關(guān)鍵詞:圖像描述;語(yǔ)義網(wǎng)絡(luò);卷積神經(jīng)網(wǎng)絡(luò);LSTM
中圖分類號(hào):TP391.41 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1003-5168(2019)14-0034-03
Image Caption Based on Multi-fusion Model
WANG Yuanhua
(College of Mathematics and Computer Science, Yan'an University,Yan an Shaanxi 716000)
Abstract: Image semantic description can automatically generate natural language description of images, which is of great significance to scene understanding. In this paper, we proposed a new multi-fusion model for feature learning and semantic learning of image semantic description. The experimental results show that the model proposed in this paper has good descriptive effect, but the training time of the model is too long and needs to be improved.
Keywords: image caption;semantic compositional network;Convolutional Neural Network;LSTM
計(jì)算機(jī)視覺(jué)(Computer Vision,CV)作為人工智能的重要分支之一,隨著深度學(xué)習(xí)模型的建立開(kāi)始蓬勃發(fā)展。現(xiàn)代科技生活帶來(lái)了各種各樣的圖像,這些圖像大多數(shù)都沒(méi)有具體的語(yǔ)言描述,對(duì)人類而言,其可以輕而易舉地理解它們,但對(duì)機(jī)器來(lái)說(shuō),要將圖像描述得很全面是比較困難的。圖像語(yǔ)義描述綜合了計(jì)算機(jī)視覺(jué)與自然語(yǔ)言處理(Natural Language Processing,NLP)的任務(wù),越來(lái)越引起人們的重視[1-4]。圖像語(yǔ)義描述的目的是解決機(jī)器表達(dá)圖像這個(gè)問(wèn)題,可以分為圖像理解和圖像的語(yǔ)言描述。圖像理解需要檢測(cè)和識(shí)別物體,需要了解場(chǎng)景類型或位置、對(duì)象屬性及其之間的關(guān)系,最后生成格式良好的句子,同時(shí)需要對(duì)語(yǔ)言進(jìn)行語(yǔ)法和語(yǔ)義理解。圖像所包含的信息量非常巨大,而且在語(yǔ)義概念上也存在模糊和多義的特點(diǎn)。目前,借助深度學(xué)習(xí)的方法,圖像語(yǔ)義描述取得了一定成效,但仍存在樣式單一、語(yǔ)義信息缺失、抗噪聲能力較弱的問(wèn)題。因此,本文提出多融合模型。
1 圖像語(yǔ)義描述研究現(xiàn)狀
目前,圖像語(yǔ)義描述方法較多,早期主要使用自下而上的范式來(lái)進(jìn)行圖像語(yǔ)義描述。這種范式首先通過(guò)對(duì)象識(shí)別和屬性預(yù)測(cè)生成圖像的描述詞,然后再結(jié)合語(yǔ)言模型生成最終的語(yǔ)義表達(dá)。最近,由于神經(jīng)網(wǎng)絡(luò)在機(jī)器翻譯中的成功應(yīng)用,編碼解碼器框架已經(jīng)被引入圖像語(yǔ)義描述中。遵循這一框架的方法,通常通過(guò)卷積神經(jīng)網(wǎng)絡(luò)將圖像編碼為單個(gè)特征矢量,然后將這些矢量輸入循環(huán)神經(jīng)網(wǎng)絡(luò)以生成描述,此外還制定了各種建模策略。Karpathy和Fei-Fei等人提出了通過(guò)檢測(cè)圖像中的對(duì)象來(lái)增強(qiáng)模型的方法。Ranzato等人提出了一個(gè)序列級(jí)的訓(xùn)練算法。在推理過(guò)程中,大多最先進(jìn)的方法都使用一種常用的解碼器機(jī)制,即貪婪搜索或光束搜索。
2 多融合模型
本文提出的多融合模型包括兩部分:在編碼過(guò)程中以語(yǔ)義組合網(wǎng)絡(luò)(Semantic Compositional Network,SCN)作為提取圖像特征的網(wǎng)絡(luò);解碼過(guò)程提出一種可以推理下一個(gè)單詞的LSTM變體模型[5-11]。
2.1 編碼器
在編碼器中,本文以SCN作為圖像的輸入網(wǎng)絡(luò)。在實(shí)驗(yàn)中,SCN基于對(duì)被測(cè)圖像中的語(yǔ)義概念(即標(biāo)簽)的檢測(cè)。為了從圖像中檢測(cè)這樣的語(yǔ)義圖像,本文首先從訓(xùn)練集中的標(biāo)題文本中選擇一組標(biāo)記。筆者使用訓(xùn)練標(biāo)題中最常用的K個(gè)詞來(lái)確定標(biāo)簽的詞匯,其中包括最常用的名詞、動(dòng)詞或形容詞。
2.2 解碼器
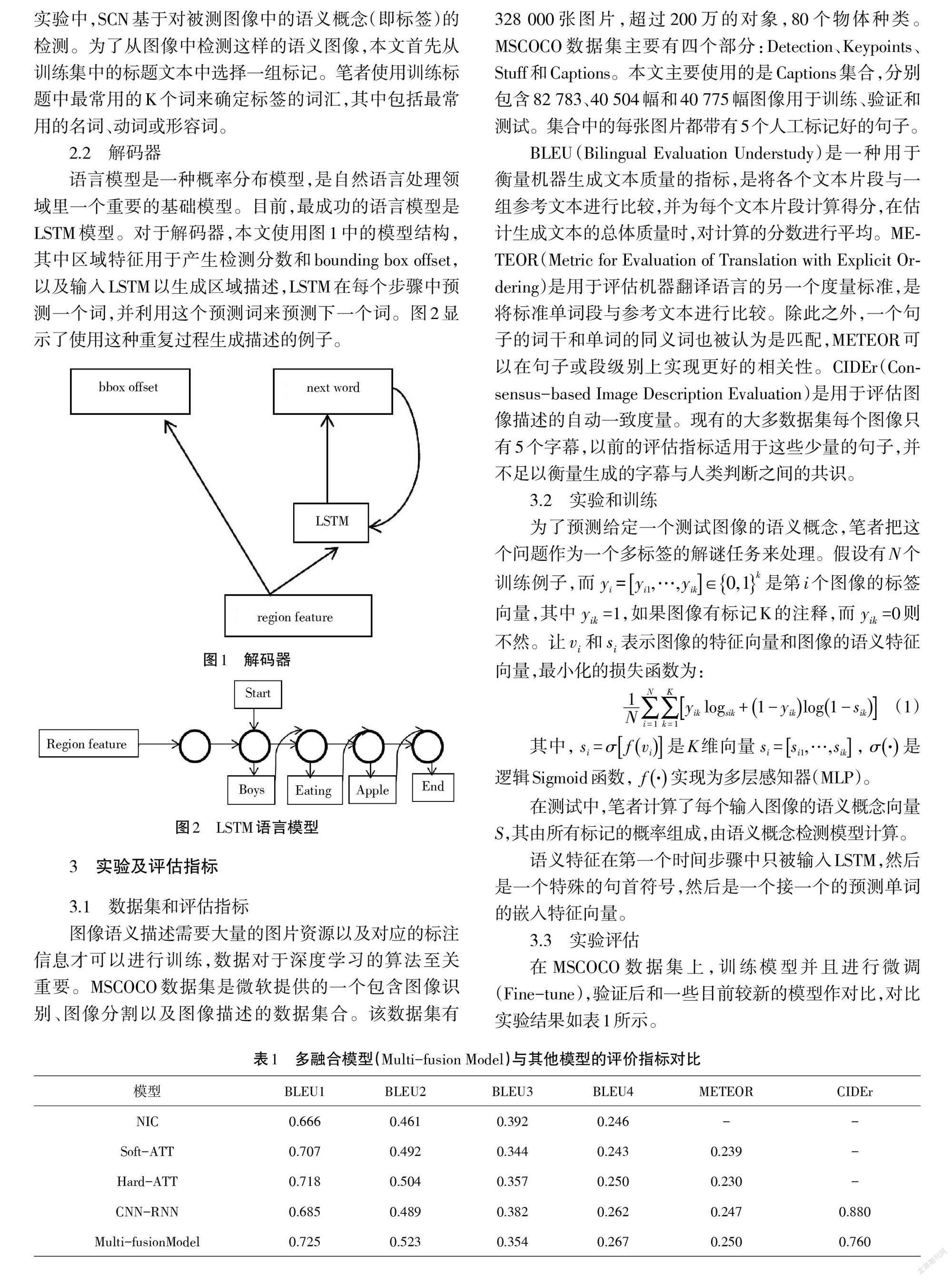
語(yǔ)言模型是一種概率分布模型,是自然語(yǔ)言處理領(lǐng)域里一個(gè)重要的基礎(chǔ)模型。目前,最成功的語(yǔ)言模型是LSTM模型。對(duì)于解碼器,本文使用圖1中的模型結(jié)構(gòu),其中區(qū)域特征用于產(chǎn)生檢測(cè)分?jǐn)?shù)和bounding box offset,以及輸入LSTM以生成區(qū)域描述,LSTM在每個(gè)步驟中預(yù)測(cè)一個(gè)詞,并利用這個(gè)預(yù)測(cè)詞來(lái)預(yù)測(cè)下一個(gè)詞。圖2顯示了使用這種重復(fù)過(guò)程生成描述的例子。
3 實(shí)驗(yàn)及評(píng)估指標(biāo)
3.1 數(shù)據(jù)集和評(píng)估指標(biāo)
圖像語(yǔ)義描述需要大量的圖片資源以及對(duì)應(yīng)的標(biāo)注信息才可以進(jìn)行訓(xùn)練,數(shù)據(jù)對(duì)于深度學(xué)習(xí)的算法至關(guān)重要。MSCOCO數(shù)據(jù)集是微軟提供的一個(gè)包含圖像識(shí)別、圖像分割以及圖像描述的數(shù)據(jù)集合。該數(shù)據(jù)集有328 000張圖片,超過(guò)200萬(wàn)的對(duì)象,80個(gè)物體種類。MSCOCO數(shù)據(jù)集主要有四個(gè)部分:Detection、Keypoints、Stuff和Captions。本文主要使用的是Captions集合,分別包含82 783、40 504幅和40 775幅圖像用于訓(xùn)練、驗(yàn)證和測(cè)試。集合中的每張圖片都帶有5個(gè)人工標(biāo)記好的句子。
BLEU(Bilingual Evaluation Understudy)是一種用于衡量機(jī)器生成文本質(zhì)量的指標(biāo),是將各個(gè)文本片段與一組參考文本進(jìn)行比較,并為每個(gè)文本片段計(jì)算得分,在估計(jì)生成文本的總體質(zhì)量時(shí),對(duì)計(jì)算的分?jǐn)?shù)進(jìn)行平均。METEOR(Metric for Evaluation of Translation with Explicit Ordering)是用于評(píng)估機(jī)器翻譯語(yǔ)言的另一個(gè)度量標(biāo)準(zhǔn),是將標(biāo)準(zhǔn)單詞段與參考文本進(jìn)行比較。除此之外,一個(gè)句子的詞干和單詞的同義詞也被認(rèn)為是匹配,METEOR可以在句子或段級(jí)別上實(shí)現(xiàn)更好的相關(guān)性。CIDEr(Consensus-based Image Description Evaluation)是用于評(píng)估圖像描述的自動(dòng)一致度量。現(xiàn)有的大多數(shù)據(jù)集每個(gè)圖像只有5個(gè)字幕,以前的評(píng)估指標(biāo)適用于這些少量的句子,并不足以衡量生成的字幕與人類判斷之間的共識(shí)。
3.2 實(shí)驗(yàn)和訓(xùn)練
為了預(yù)測(cè)給定一個(gè)測(cè)試圖像的語(yǔ)義概念,筆者把這個(gè)問(wèn)題作為一個(gè)多標(biāo)簽的解謎任務(wù)來(lái)處理。假設(shè)有N個(gè)訓(xùn)練例子,而[yi=yi1,…,yik∈0,1k]是第i個(gè)圖像的標(biāo)簽向量,其中[yik]=1,如果圖像有標(biāo)記K的注釋,而[yik]=0則不然。讓[vi]和[si]表示圖像的特征向量和圖像的語(yǔ)義特征向量,最小化的損失函數(shù)為:
[1Ni=1Nk=1Kyiklogsik+1-yiklog1-sik] ? (1)
其中,[si=σfvi]是K維向量[si=si1,…,sik],[σ·]是邏輯Sigmoid函數(shù),[f·]實(shí)現(xiàn)為多層感知器(MLP)。
在測(cè)試中,筆者計(jì)算了每個(gè)輸入圖像的語(yǔ)義概念向量S,其由所有標(biāo)記的概率組成,由語(yǔ)義概念檢測(cè)模型計(jì)算。
語(yǔ)義特征在第一個(gè)時(shí)間步驟中只被輸入LSTM,然后是一個(gè)特殊的句首符號(hào),然后是一個(gè)接一個(gè)的預(yù)測(cè)單詞的嵌入特征向量。
3.3 實(shí)驗(yàn)評(píng)估
在MSCOCO數(shù)據(jù)集上,訓(xùn)練模型并且進(jìn)行微調(diào)(Fine-tune),驗(yàn)證后和一些目前較新的模型作對(duì)比,對(duì)比實(shí)驗(yàn)結(jié)果如表1所示。
實(shí)驗(yàn)結(jié)果顯示,多融合模型通過(guò)微調(diào)后,可以得到模型的最優(yōu)性能。實(shí)驗(yàn)顯示,評(píng)價(jià)指標(biāo)相比其他模型有良好的表現(xiàn)能力。
4 結(jié)語(yǔ)
本文通過(guò)研究SCN網(wǎng)絡(luò)和LSTM,將兩種模型結(jié)合在一起,提出一種新的多融合模型。通過(guò)改進(jìn)編碼器和解碼器,使圖像內(nèi)容表述簡(jiǎn)潔通暢。實(shí)驗(yàn)結(jié)果表明,本文提出的模型有較好的描述效果,但模型在訓(xùn)練時(shí)時(shí)間過(guò)長(zhǎng),有待改進(jìn)。
參考文獻(xiàn):
[1]Bengio Y,Louradour J, Collobert R, et al. Curriculum learning[J]. Proc.int.conf.on Machine Learning,2009(60):6.
[2]Chen X , Fang H , Lin T Y , et al. Microsoft COCO Captions:Data Collection and Evaluation Server[J]. Computer Science,2015(5):1-7.
[3]Chen X , Zitnick C L . Mind's eye:A recurrent visual representation for image caption generation [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).2015.
[4]Cho K, Van Merrienboer B, Gulcehre C, et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. Computer Science,2014(6):1724-1734.
[5]Chung J , Gulcehre C , Cho K H , et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J]. Eprint Arxiv, 2014(2):1-9.
[6]Deng J, Dong W, Socher R, et al. ImageNet: a Large-Scale Hierarchical Image Database[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2009.
[7]Donahue J, Hendricks L A, Guadarrama S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]// Computer Vision & Pattern Recognition. 2015.
[8]Elliott D, Keller F. Image description using visual dependency representations[EB/OL].(2016-04-01)[2019-04-22]. http://www.doc88.com/p-5416901465276.html.
[9]Hao F, Platt J C, Zitnick C L, et al. From captions to visual concepts and back[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2015.
[10]Farhadi A, Hejrati M, Sadeghi M A, et al. Every picture tells a story: generating sentences from images[J]. Lecture Notes in Computer Science,2010(10):15-29.
[11]Frome A , Corrado G S , Shlens J , et al. Devise:A deep visual-semantic embedding model[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2013.
