基于數據壓縮與改進的概率神經網絡的貴州方言辨識
2019-09-10 07:22:44艾虎李菲
現代信息科技 2019年6期
艾虎 李菲

關鍵詞:漢語方言辨識;梅爾頻率倒譜系數;主成分分析;概率神經網絡
中圖分類號:TP391.4 ? ? ? 文獻標識碼:A 文章編號:2096-4706(2019)06-0005-05
Abstract:In order to judge the location of the suspect’s dialect,it provides important clues for the detection of the case. In this study,600 phonetic samples of different ages and sexes were collected from 6 different regions of Guizhou and the Mel frequency cepstrum coefficient MFCC was extracted from the samples. The Principal Component Analysis (PCA) and the data compression method proposed in this study are used to reduce the dimensionality of the MFCC to get the data set used in the training of probabilistic neural network. Then the probabilistic neural network is improved,and then it is used to construct the identification model of Guizhou dialect. The simulation results show that the correlation coefficient R between the dialect model identification result and the actual result is 90%. This model can effectively identify the dialects in Guizhou.
Keywords:Chinese dialect identification;mel frequency cepstrum coefficients;principal component analysis;probabilistic neural network
0 ?引 ?言
現代通訊工具在案件偵破中扮演著重要角色,對其中的語音信息進行方言辨識,可以判斷犯罪嫌疑人的方言歸屬地,從而為案件偵破提供重要線索。由于方言的發音差異主要體現在頻譜結構的時間變化上[1],所以需要提取梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficients,MFCC)。因為方言辨識模型的訓練需要大量的語音樣本,導致提取的MFCC的數據量巨大,所以有必要先對所提取的MFCC進行降維和壓縮處理,然后構建分類模型進行方言辨識。
近年來,國內在漢語方言辨識方面采用的算法有流形學習與特征融合、聯合多樣性密度和深層與深度神經網絡[2-5]等。本研究提出一種基于數據壓縮和改進的概率神經網絡的方言辨識模型,該模型采用了主成分分析與本研究所提出的數據壓縮方法對MFCC進行降維處理,得到用于概率神經網絡訓練和仿真的數據集,并對概率神經網絡進行了改進,該模型能有效地對貴州地區方言進行辨識。
1 ?MFCC的相關知識
MFCC是基于人耳聽覺特性提出來的,先將頻譜轉化為基于Mel頻標的非線性頻譜,然后通過轉換得到倒譜域,由于MFCC在沒有任何前提假設的條件下,充分考慮了人的聽覺特性,因此MFCC具有良好的辨識性能和抗噪性,廣泛地應用在語音辨識領域[6]。
本研究收集和整理了貴陽市、安順市、遵義市、凱里市、都勻市和六盤水市6個地區不同性別和不同年齡(年齡區間為8~60歲)的600份方言語音樣本,收集到的語音樣本時長5~20秒不等,把收集到的語音樣本平分為兩份,一份用來訓練概率神經網絡,另一份用來驗證概率神經網絡。
語音采樣率為8000Hz;采樣點數256;幀長設為32ms;幀移10ms;所提取的MFCC為24維,其全部組成為:12維MFCC系數和12維一階差分參數。所以一個語音文件提取得到的MFCC是一個N×24的矩陣。
3 ?MFCC的降維處理
3.1 ?主成分分析
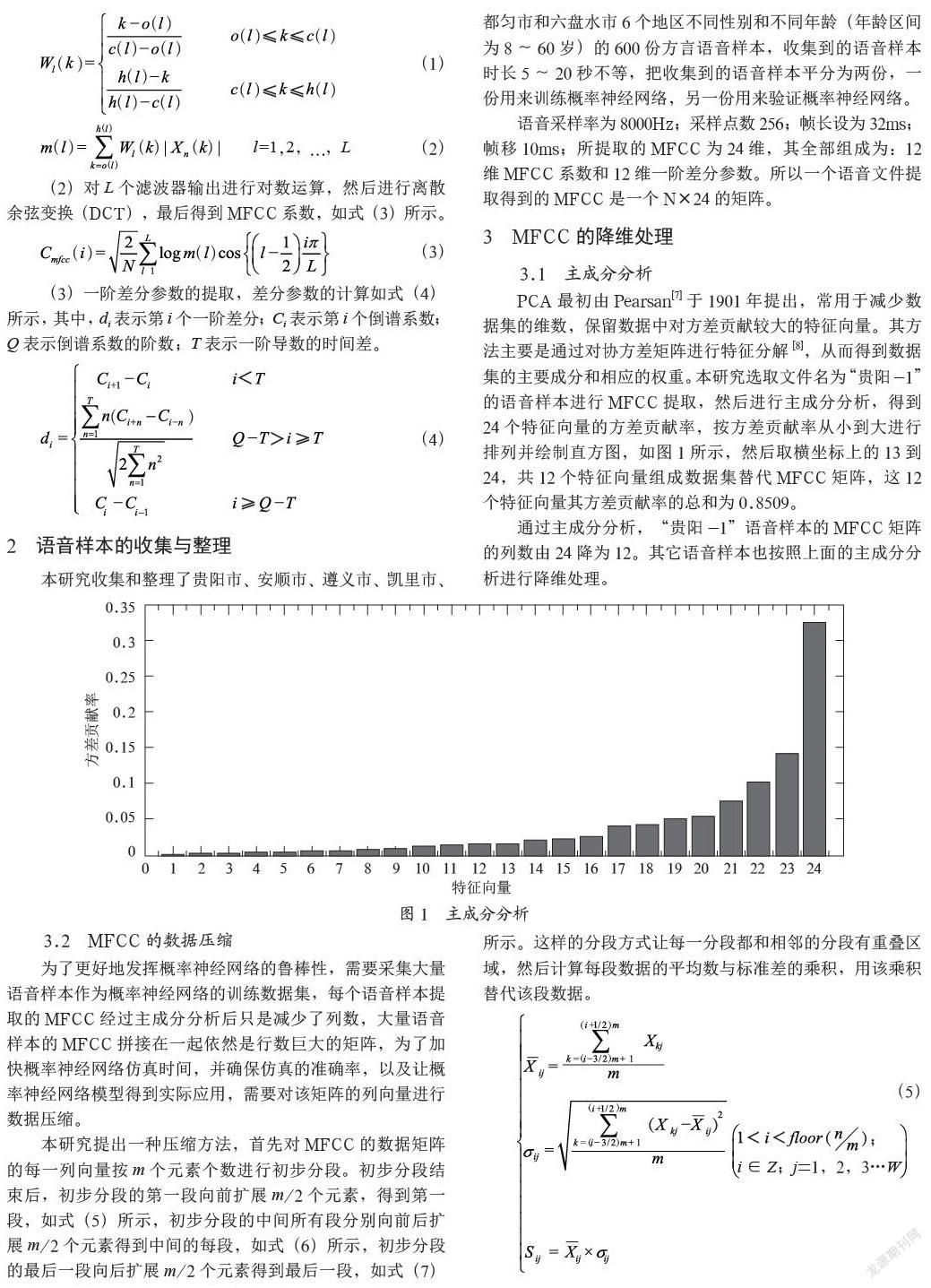
PCA最初由Pearsan[7]于1901年提出,常用于減少數據集的維數,保留數據中對方差貢獻較大的特征向量。其方法主要是通過對協方差矩陣進行特征分解[8],從而得到數據集的主要成分和相應的權重。本研究選取文件名為“貴陽-1”的語音樣本進行MFCC提取,然后進行主成分分析,得到24個特征向量的方差貢獻率,按方差貢獻率從小到大進行排列并繪制直方圖,如圖1所示,然后取橫坐標上的13到24,共12個特征向量組成數據集替代MFCC矩陣,這12個特征向量其方差貢獻率的總和為0.8509。
通過主成分分析,“貴陽-1”語音樣本的MFCC矩陣的列數由24降為12。其它語音樣本也按照上面的主成分分析進行降維處理。
3.2 ?MFCC的數據壓縮
為了更好地發揮概率神經網絡的魯棒性,需要采集大量語音樣本作為概率神經網絡的訓練數據集,每個語音樣本提取的MFCC經過主成分分析后只是減少了列數,大量語音樣本的MFCC拼接在一起依然是行數巨大的矩陣,為了加快概率神經網絡仿真時間,并確保仿真的準確率,以及讓概率神經網絡模型得到實際應用,需要對該矩陣的列向量進行數據壓縮。
本研究提出一種壓縮方法,首先對MFCC的數據矩陣的每一列向量按m個元素個數進行初步分段。初步分段結束后,初步分段的第一段向前擴展m/2個元素,得到第一段,如式(5)所示,初步分段的中間所有段分別向前后擴展m/2個元素得到中間的每段,如式(6)所示,初步分段的最后一段向后擴展m/2個元素得到最后一段,如式(7)所示。這樣的分段方式讓每一分段都和相鄰的分段有重疊區域,然后計算每段數據的平均數與標準差的乘積,用該乘積替代該段數據。
4 ?改進的概率神經網絡方言辨識模型
概率神經網絡(Probabilistic Neural Network,PNN)適合用于模式分類,屬于徑向基神經網絡的一種,是基于貝葉斯最小風險準則發展而來的一種并行算法,由美國加州Specht博士[9,10]在1988年提出。
4.1 ?概率神經網絡PNN的改進
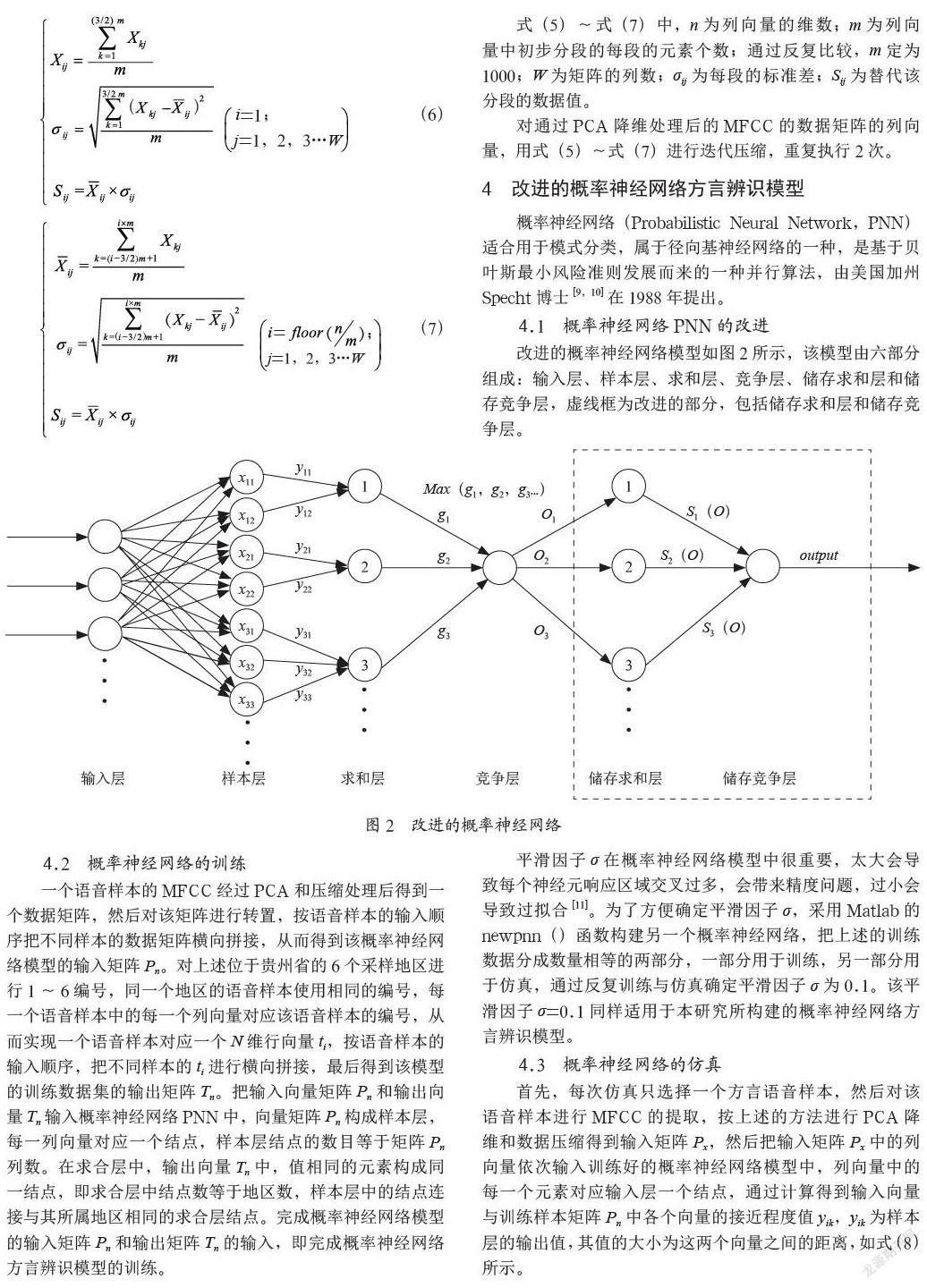
改進的概率神經網絡模型如圖2所示,該模型由六部分組成:輸入層、樣本層、求和層、競爭層、儲存求和層和儲存競爭層,虛線框為改進的部分,包括儲存求和層和儲存競爭層。
4.2 ?概率神經網絡的訓練
一個語音樣本的MFCC經過PCA和壓縮處理后得到一個數據矩陣,然后對該矩陣進行轉置,按語音樣本的輸入順序把不同樣本的數據矩陣橫向拼接,從而得到該概率神經網絡模型的輸入矩陣Pn。對上述位于貴州省的6個采樣地區進行1~6編號,同一個地區的語音樣本使用相同的編號,每一個語音樣本中的每一個列向量對應該語音樣本的編號,從而實現一個語音樣本對應一個N維行向量ti,按語音樣本的輸入順序,把不同樣本的ti進行橫向拼接,最后得到該模型的訓練數據集的輸出矩陣Tn。把輸入向量矩陣Pn和輸出向量Tn輸入概率神經網絡PNN中,向量矩陣Pn構成樣本層,每一列向量對應一個結點,樣本層結點的數目等于矩陣Pn列數。在求合層中,輸出向量Tn中,值相同的元素構成同一結點,即求合層中結點數等于地區數,樣本層中的結點連接與其所屬地區相同的求合層結點。完成概率神經網絡模型的輸入矩陣Pn和輸出矩陣Tn的輸入,即完成概率神經網絡方言辨識模型的訓練。
平滑因子σ在概率神經網絡模型中很重要,太大會導致每個神經元響應區域交叉過多,會帶來精度問題,過小會導致過擬合[11]。為了方便確定平滑因子σ,采用Matlab的newpnn()函數構建另一個概率神經網絡,把上述的訓練數據分成數量相等的兩部分,一部分用于訓練,另一部分用于仿真,通過反復訓練與仿真確定平滑因子σ為0.1。該平滑因子σ=0.1同樣適用于本研究所構建的概率神經網絡方言辨識模型。
4.3 ?概率神經網絡的仿真
首先,每次仿真只選擇一個方言語音樣本,然后對該語音樣本進行MFCC的提取,按上述的方法進行PCA降維和數據壓縮得到輸入矩陣Px,然后把輸入矩陣Px中的列向量依次輸入訓練好的概率神經網絡模型中,列向量中的每一個元素對應輸入層一個結點,通過計算得到輸入向量與訓練樣本矩陣Pn中各個向量的接近程度值yik,yik為樣本層的輸出值,其值的大小為這兩個向量之間的距離,如式(8)所示。
測試使用電腦的配置:戴爾OptiPlex 9020 Mini To-wer;英特爾酷睿i7-4790 @ 3.60GHz 四核;顯卡AMD Radeon R5 240(1GB/戴爾);內存8GB(三星DDR3 1600MHz)。
把收集到的600份語音樣本平分為兩份,一份用來訓練概率神經網絡,別一份用來仿真驗證概率神經網絡。在進行數據壓縮時,為了選擇合適的分段大小,本研究對不同的分段大小進行測試和比較,測試和比較的結果如表1所示,相關系數R為方言模型辨識結果與實際結果的相關系數。通過測試結果的比較得出分段大小取30最合適,分段大小取30時,仿真結果與實際結果的散點圖如圖3所示,相關系數R為90.903%。
本研究采用概率神經網絡對貴州方言進行辨識,由于概率神經網絡的魯棒性建立在大量訓練樣本的基礎之上,所以需要采集大量的方言語音樣本,由于每一個語音樣本所提取MFCC是一個矩陣,從而導致訓練樣本巨大,龐大的訓練數據集會讓概率神經網絡仿真時間變長,失去實用價值。為了讓概率神經網絡貴州方言辨識模型可用于處理實際事務,本研究首先采用PCA對MFCC進行降維處理,然后再對其列向量進行分段和壓縮,并通過優化與比較確定分段大小取30最合適。經過降維與壓縮處理后的訓練數據集能有效縮短概率神經網絡的仿真時間,并且模型仿真結果與實際結果的相關系數R達到0.90903,如表1所示。
由于每一個語音樣本所提取MFCC經過PCA降維和數據壓縮后仍然是一個矩陣,輸入概率神經網絡后矩陣的每一列向量分別有一個輸出,所以需要在原有的基礎上對概率神經網絡進行改進,把每一列向量的輸出進行儲存,然后對同一個語音樣本的所有輸出進行求和比較,最后得出該語音樣本的辨識結果。
7 ?結 ?論
本文采用PCA和本研究所提出的數據壓縮方法對貴州方言樣本的MFCC進行降維處理,得到用于概率神經網絡訓練的數據集,然后對概率神經網絡進行改進,并構建貴州方言辨識模型,訓練完成的模型能有效對貴州方言進行辨識。
參考文獻:
[1] BAKER W,EDDINGTON D,NAY L. Dialect identi-fication:The effects of region of origin and amount of experience [J]. American Speech,2009,84(1):48-71.
[2] 賈晶晶,顧明亮,朱恂,等.基于流形學習與特征融合的漢語方言辨識 [J].計算機工程與應用,2015,51(7):233-237.
[3] 顧明亮,張世形,張浩,等.基于聯合多樣性密度的漢語方言辨識 [J].計算機工程與應用,2016,52(10):161-166.
[4] 景亞鵬,鄭駿,胡文心.基于深層神經網絡(DNN)的漢語方言種屬語音識別 [J].華東師范大學學報(自然科學版),2014(1):60-67.
[5] 崔瑞蓮,宋彥,蔣兵,等.基于深度神經網絡的語種識別 [J].模式識別與人工智能,2015,28(12):1093-1099.
[6] 張毅,黎小松,羅元,等.基于人耳聽覺特性的語音識別預處理研究 [J].計算機仿真,2015,32(12):322-326.
[7] Pearson K. On lines and planes of closest fit to systems of points in space [J]. The London,Edinburgh,and Dublin Philosophical Magazine and Journal of Science,1901,2(6):559-572.
[8] Abdi H,Williams LJ. Principal component analysis [J]. Wiley Interdisciplinary Reviews Computational Statistics,2010,2(4):433-459.
[9] SPECHT DF. Probabilistic neural networks for classification,mapping,or associative memory [C]// Neural Networks,1988.,IEEE International Conference on. S.l.:s.n.,1988:525-532.
[10] Specht DF. Probabilistic neural networks [J]. Neural Networks,1990,3(3):109-118.
[11] 董長虹.Matlab神經網絡與應用(第2版) [M].北京:國防工業出版社,2007.
通訊作者:艾虎(1974-),男,漢族,江西弋陽人,博士,副教授,研究方向:聲音與圖像。
