用戶畫像構建研究
2019-09-10 07:22:44馬朋輝王雪寧李勇邵帥
現代信息科技 2019年6期
馬朋輝 王雪寧 李勇 邵帥

關鍵詞:用戶畫像;Word2vec;詞向量;Stacking
中圖分類號:TP391.1;TP391.4 ? ? 文獻標識碼:A 文章編號:2096-4706(2019)06-0017-03
Abstract:This paper mainly studies user portrait construction based on user browsing data of Sogou engine. We describe user characteristics concretely,labeled and targeted,and use this as the basis of market analysis,business decision-making and precise marketing. User portrait technology can help search engines more targeted service users. The main work of this paper is as follows:Firstly,the data set of user search is preprocessed. In word segmentation,we choose Jieba word segmentation tool;secondly,we use TF-IDF-based vector space model to select feature words;thirdly,we use Word2vec to transform feature words into word vectors;finally,we use different classifiers to construct user portraits,we use Stacking model here.
Keywords:user portrait;Word2vec;word vector;Stacking
0 ?引 ?言
大數據時代的到來,有力的緩解了信息爆炸的問題,搜索推薦系統也一直在致力于從“拉”模式到“推”模式的改變[1],與此同時,隨著互聯網計算機技術的快速發展,云計算技術的出現為大數據的及時性分析、處理提供了技術上的支持[2],用戶畫像是根據用戶的社會屬性、生活習慣和消費行為等信息而抽象出的一個標簽化的用戶模型。構建用戶畫像的核心工作即是給用戶貼“標簽”。通過構建搜索引擎的用戶畫像可以大大減少平臺的運營成本。
1 ?相關技術介紹
Word2vec:Word2vec模型其實就是簡單化的神經網絡,一般分為CBOW(Continuous Bag-of-Words)與Skip-Gram兩種模型。CBOW模型的訓練輸入是與某一個特征詞的上下文相關的詞相對應的詞向量,而輸出的就是這特定的一個詞的詞向量。Skip-Gram模型和CBOW的思路是反著來的,即輸入是特定的一個詞的詞向量,而輸出是特定詞對應的上下文詞向量。CBOW對小型數據庫比較合適,而Skip-Gram在大型語料中表現更好。
Stacking模型:Stacking是一種分層模型集成框架。以兩層為例,第一層由多個基學習器組成,其輸入為原始訓練集,第二層的模型則是以第一層基學習器的輸出作為訓練集進行再訓練,從而得到完整的Stacking模型。
2 ?用戶畫像模型構建
2.1 ?數據集
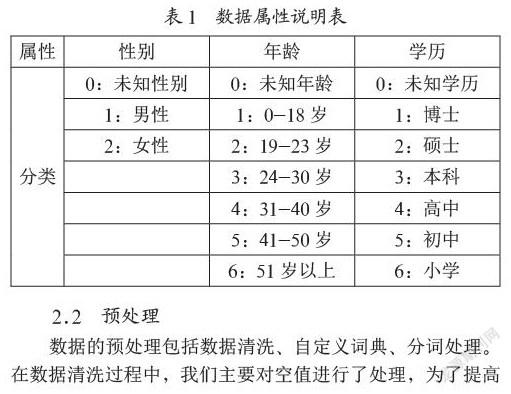
本文中所采用的數據來源于CCF競賽平臺,搜狗公司提供的用戶搜索數據,其中用戶的ID經過加密算法加密。其中每條數據包含用戶的ID、Age(年齡)、Gender(性別)、Education(教育程度)、Query List(用戶搜索詞列表)。數據說明如表1。
數據的預處理包括數據清洗、自定義詞典、分詞處理。在數據清洗過程中,我們主要對空值進行了處理,為了提高最后所做預測的準確程度,我們對于有空值的用戶信息選擇舍去,因為我們認為被丟棄的數據占比太小,對預測的準確程度影響不大;在自定義詞典過程中,我們花費了大量的時間和精力進行了一些詞語的替換來換取準確率的提高,比如將百度網盤網址替換為“網盤”;在分詞處理工作中,我們主要使用了結巴分詞,在分詞后又使用了正則表達式和去停用詞來實現精確分詞。
用戶搜索詞列表分詞前:
中財網首頁財經 ?http://pan.baidu.com/s/1plpjtn9 ?周公解夢大全查詢2345 ?曹云金再諷郭德綱 ?總裁大人行行好
用戶搜索詞列表分詞后:
中財網 財經 網盤 周公解夢 曹云金 郭德綱 小說
2.3 ?特征詞的抽取
特征詞的選擇即從上述總分詞庫中篩選出最能代表用戶搜索內容的詞,簡單來說就是如果某個詞匯出現的次數多,那么這個詞語就能被篩選出作為特征詞。在這里我們使用TF-IDF算法篩選出特征詞,TF-IDF算法是經典的文本特征加權方法,它衡量了某一個單詞在文檔中的重要性;TF-IDF與一個詞在文檔中的出現次數成正比,與該詞在整個語言中的出現次數成反相關。式(1)是TF-IDF算法的公式:
特征詞處理完畢之后,就該著手把特征詞轉換為計算機能讀懂的語言,那么問題來了,根據詞向量,該如何表達特征詞呢?假設某用戶含有N個特征詞,每個特征詞使用K維的詞向量表示。有人可能會說,把詞向量拼起來,將一個用戶形式化為N*K的向量,但這種做法并不合適,因為無法解決不同用戶的特征詞數量所導致的維度不一致問題,下面為我們的方法:首先,使用傳統的One-Hot方式,具體是先構建一個詞典,它包含所有我們選取的特征詞;然后,對于用戶的每一個搜索詞,如果它在詞典中出現了,對應位置就標記為1,否則標記為0;最終,每一個用戶的特征表示就是01序列,長度為詞典長度。再然后使用Word2vec把特征詞向量加和求平均值,根據特征詞的語義獲得其分布式表達,且詞語之間的相似性可以由向量的余弦夾角來表示,豐富了詞語特征的表達。測試集第一個用戶特征向量表示如下(一共是300維向量,這里只展示24維向量):[-0.13521618 ?-0.12654323 ?-0.29329249 -0.09194205 ?0.08417522 ?0.27917215 ?0.13377914 ?0.05475752 ?-0.09656907 ?0.14759752 ?-0.39463448 -0.0143092 ?-0.60612251 ?-0.39274153 ?-0.16835085 -0.21356585 ?-0.29147161 ?0.40192119 ?0.37719944 ?0.25010119 ?-0.29925515 ?0.31874303 ?-0.1342936 ? 0.43075851]
2.5 ?用戶畫像模型
Stacking模型:集成學習就是通過構建并結合多個學習器來完成學習任務,多個學習器的結合常可以獲得比單一學習器顯著優越的泛化性能。其中Stacking是一種著名的集成學習方法。
Stacking先從初始數據集訓練出初級學習器,然后“生成”一個新的數據集用于訓練次級學習器,在這個新數據集中,初級學習器的輸出被當作樣例輸入特征,而初始樣本的標記仍被當作樣例標記[3]。
Stacking集成最大的特點是靈活,我們可以設置多層級的Stack,每層可以設置合適的分類器簇,并且可以將新特征很方便的融合在層之間的中間結果里。經典的Stacking框架分為2層,第一層含有T個分類器,產生T組與原數據集規模相同且維度為1的結果,將這T組結果拼在一起可組成新的數據集,用以構成第二層的輸入。在一層中,對于T個分類器中的每一個分類器,我們把訓練數據分割為N份,利用其中的N-1份做訓練,剩下的那一份做預測,這樣對訓練集重復N次,就可以得到在一個分類器下對原始訓練數據的一個完整預測結果,于是一個分類器可以得到N*1的新表達,那么T個分類器就可以得到N*T的新表達,而這就是用于下一層的輸入。
2.6 ?模型預測結果
Stacking模型預測準確率如表2所示。
3.1 ?總結
我們在實驗中遇到了很多難題,比如龐大的數據量,繁多臃腫的特征向量,為保證精準性,并沒有做大批量刪除處理,在保證結果的精度的前提下我們只保留了頻率大于50的詞,對小部分數據進行刪減,使數據更加精簡整潔,在解決數據冗雜的問題后,我們利用模型得到的結果與實際相比較準確率較低,因此,我們對預處理部分做了進一步優化,篩選出沒有使用到的詞,在此基礎之上,變換不同的Word2vec維度,以得到準確率更高的結果。
在如今互聯網高速發展的背景下,勾勒用戶畫像作為一種手段,有非常廣泛的用途,例如:精準營銷,用戶分析,數據分析,數據應用等。用戶畫像根據用戶搜索記錄,搜索頻數,瀏覽時間等建立用戶個性化配置文件,再使用各種數據挖掘工具從用戶歷史記錄中學習用戶個人愛好與偏向,即這可以作為是從搜索即瀏覽記錄中刻畫用戶畫像,從而應用在個性化訂制推薦中[4]。曾鴻等(2016)通過采集分析新浪微博等用戶社交數據,定量分析定性描述社交網絡用戶的群體行為特征,構建基于社交數據的用戶畫像模型,支撐精準營銷[5]。
本文基于十萬搜狗用戶的搜索詞條,在經過數據預處理、特征選擇、建立特征向量等處理后,我們采用Stacking分類模型對性別、年齡、學歷三項進行預測,并與正確結果做比較,所得結果如下:性別標簽的精確度為0.783;年齡標簽的精確度為0.584;學歷標簽的精確度為0.601。
3.2 ?展望
本文是通過用戶搜索詞對用戶貼標簽,由于存在同一賬號不同用戶使用的情況,可能會導致一些誤差,所以可以分時間段對詞進行處理,以提高準確性。
參考文獻:
[1] 趙鑫,丁效.淺析推薦系統中的用戶畫像構建與應用 [J].中國計算機學會通訊2017,13(11):45-51.
[2] 李雅坤.基于搜索引擎的用戶畫像構建方法研究 [D].山西:山西財經大學,2018:1-3.
[3] 周志華.機器學習 [M].北京:清華大學出版社,2016:183-185.
[4] Adomavicius G,Tuzhilin A. User profiling in personalization applications through rule discovery and validation [A]. Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining [C],DBLP,1999:377-381.
[5] 曾鴻,吳蘇倪.基于微博的大數據用戶畫像與精準營銷 [J].現代經濟信息,2016(16):306-308.
作者簡介:馬朋輝(1999.08-),男,漢族,河南周口人,軟件工程專業,本科,研究方向:機器學習、數據挖掘;王雪寧(1997.08-),女,蒙古族,遼寧朝陽人,計算機科學與技術專業,本科,研究方向:網絡與信息安全;李勇(1998.07-),男,回族,寧夏吳忠人,本科,研究方向:數學統計;邵帥(1998.06-),女,漢族,黑龍江哈爾濱人,網絡與信息安全專業,本科在讀,研究方向:網絡與信息安全。
