基于Boost算法的鋼水配料方案優化
2019-09-10 08:21:57李婷婷
青年生活 2019年23期
李婷婷
摘要:本文主要介紹了關于鋼水配料方案模型的建立,對于不同類型不同情況,采用決策樹模型進行分類,針對每一類別,提供不同參數的線性回歸方程。在優化過程中,結合Boost算法的原理,將錯誤數據權值調大,進行迭代,從而得到擬合優度較高的模型。
關鍵詞:Boost算法;皮爾遜相關系數;決策樹
一、簡介
在煉鋼過程中,金屬的氧化反應是非常關鍵一步。這個過程將各個金屬融合在一起,從而煉出合金。對于鋼廠而言,如何提高各個金屬的利用率是非常重要的,可以減少成本、提高產量。
二、研究背景
對于不同金屬的配料,不僅與合金中相應金屬的需求息息相關,還需要考慮各個金屬之間互相的影響。因為添加配料中的某一種金屬不可能被全部吸收,所以對于金屬的加入量,應綜合考慮其吸收程度等因素。
根據不同金屬,先求解其吸收程度,然后對多種因素進行線性回歸。對于出現的誤差數據,可以將其權值調大,進而統計,經過多次迭代,最終得到擬合程度較好的模型。
三、模型建立與分析
根據數據計算出C、Mn被合金吸收的質量以及C、Mn加入的質量,進而求得C、Mn的歷史收得率。
(一)決策樹分析
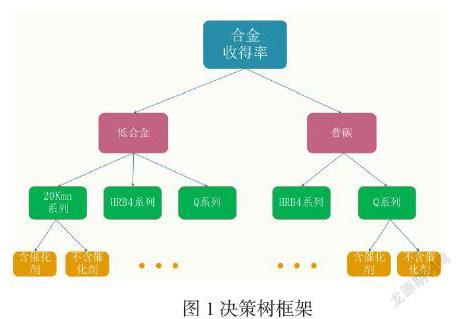
基于求得的歷史收得率,發現C、Mn的歷史收得率在某個鋼種,某個鋼號,以及是否加脫氧劑的情況下,C、Mn的歷史收得率有很大差異,因此針對這三個分類方式,采用決策樹的方法,最終得出一種最優的分類順序,即先對鋼種進行分類,再對鋼號進行分類,最后再對是否加脫氧劑進行分類。沿著決策樹的某一分支,對影響C、Mn的收得率因素進行分析。影響收得率的因素可能有許多,將這些因素分別與C、Mn的歷史收得率計算Pearson相關系數,挑取相關系數較大的因素,最終得到影響收得率的主要因素,決策樹框架如圖1
(二)主成分線性回歸
建立主成分線性回歸模型,使用AdaBoost對數據表進行處理,使用主成分線性回歸方法進行預測,對比發現,預測的結果較未使用AdaBoost改進的準確很多。首先對影響收得率的因素進行因子分析,找出原始因素之間的關聯,提取相對數量的因子,從而減少變量。多元線性回歸進行預測,為減小預測的誤差,使用AdaBoost對數據表進行處理,將歷史數據可靠性不強的樣本數據賦予較小的權重,從而提高數據表的準確性,進而加強了主成分線性回歸的預測結果的準確性。
將C元素鋼號HRB400D作為訓練數據,數據分布如圖2所示。對于Boost過程,進行訓練樣本數據的初始化,接著開始迭代,在得到新的權值分布的情況下,選取誤差率最小的分類器進行二次迭代。不斷反復此步驟,一共迭代6次,整合得強分類器,使正確率提升。
(三)規劃方案
脫氧合金化不僅要保證C、Mn、Si、P、S含量達到標準,而且要使合金成本達到最小。因此本文提出以C成本最小化為目標,C、Mn、Si、P、S含量達到標準為約束,以合金加入量為決策變量優化,線性規劃,得到最優化的合金配料比,結果如表1。
四、結語
模型穩定性強,誤差較小;充分考慮數據的有效性與準確性。模型針對不同類別鋼種不同環境,可以較為準確地預測出收得率;改變脫氧劑的加入情況,決策樹會分支成不同路徑,能較好的適應不同環境;主成分分析是選取代表性指標,對于原始影響因素進行降維,靈敏性較好;對于不同類別鋼種,對應不同的表達式,可移植性較好,可以適應各種情況。
參考文獻
[1]王熙辰.淺談轉爐煉鋼技術的應用和革新途徑[J].科技風,2019(15):148.
[2]連克強.基于Boosting的集成樹算法研究與分析[D].中國地質大學(北京),2018.
