基于擁擠度的改進蟻群算法
2019-09-20 05:48:22
測控技術 2019年3期
關鍵詞:信息
(上海大學 機電工程與自動化學院,上海 201900)
蟻群算法是意大利學者Dorigo于1992年提出的一種群智能仿生算法[1]。該算法模擬蟻群覓食行為,蟻群會在覓食所經過的路徑上留下一種名為信息素的化學物質[2]。螞蟻之間靠感知信息素強度尋找最優覓食路徑。蟻群算法具有高魯棒性、分布式計算、正反饋、易與其他算法融合的優點[3]。而這些優點可用于解決一系列NPC(Non-Deterministic Polynomial Complete)問題。目前,蟻群算法已被廣泛用于解決旅行商問題、指派問題、調度問題以及圖著色等問題[4]。但蟻群算法也存在著一些問題,如搜索時間較長、易陷入局部最優、收斂速度過慢、易產生停滯現象[5]。針對這些不足,很多專家學者都提出了自己的改進方法。例如安葳鵬[11]通過引入最大代價與最小代價來優化蟻群算法的信息素更新機制;方春城[12]將網格地圖模型與蟻群算法相結合來優化機器人行走路徑。
蟻群算法的核心技術在于其信息素更新方式和狀態轉移概率選擇[6]。其中信息素矩陣的構造尤為關鍵,信息素引導著螞蟻做各種路徑選擇,蟻群的狀態轉移也基于蟻群的信息素矩陣。因此對信息素矩陣的重新構造便可提供一種改進的蟻群算法,比如ACS(Ant Colony System)算法[7]、MMAS(Max-Min Ant System)算法[8]、自適應蟻群算法[9]、混合行為蟻群算法[10]。
為改善蟻群算法易陷入局部最優的情況,本文引入擁擠度算子來增強蟻群之間的信息交流,改善信息素矩陣的分布,避免蟻群因局部信息素過大而過早陷入停滯狀態。同時通過全局信息素更新和局部信息素更新對信息素矩陣進行自適應調整,提前預防早熟現象。在路徑調整過程中結合一項高效的變異操作,在增強全局搜索能力的同時又提高算法的收斂速度。
對于擁擠度概念,前人也有相關研究,王劍[13]將魚群算法的擁擠度因子引入蟻群算法,但其僅考慮了整體的擁擠情況,未考慮局部路徑情況,而本文將兩種情況都納入考慮范圍。而對于鄰域搜索概念,段海濱[14]將連續空間上的相鄰下一節點定義為鄰域。而本文中是將離散空間中以某一點為圓心的附近若干點劃分為鄰域,著重縮小搜索范圍,提高搜素效率。
1 傳統蟻群算法模型
本文以平面TSP(Traveling Salesman Problem,旅行商問題)為例求解基本蟻群算法模型。該模型采用全局信息素更新和局部信息素更新相結合的方法,信息素的揮發和釋放動作只對至今全局最優螞蟻所走的路徑更新。螞蟻每選擇一條路徑,都通過局部信息素更新規則削弱該路徑上的一定量信息素,增加蟻群探索其他路徑的可能性。
1.1 狀態轉移規則
在蟻群系統中,m只螞蟻在n個城市中并行構建TSP路徑。初始時刻,螞蟻被分別置于隨機選出的城市中,各城市之間每條路徑的信息素皆相等。在構建路徑的過程中,蟻群采用一種偽隨機比例規則來確定螞蟻k下一步將要訪問的城市j。其過程為
(1)
(2)
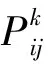
采用這種偽隨機比例規則產生的城市,既可以保證螞蟻利用路徑的先驗知識選擇當前最有可能的最優解,又以一定的概率探索新的路徑。通過調整參數q0,可以調節算法對新路徑的探索概率,達到蟻群算法在探索新路徑和保持較優路徑之間的平衡。
1.2 局部信息素更新
在每只螞蟻經過一條路徑時,都將會對該路徑上的信息素進行局部更新,即
τij=(1-ζ)·τij+ζ·τ0,τ0∈(0,1)
(3)
式中,ζ為一固定參數;τ0為初始信息素的值,一般取值為1/n·Lnn。其中,Lnn為由最近鄰域啟發式方法得到的路徑長度。通過局部信息素的更新,達到削弱該條路徑信息素的效果。使該條路徑信息素不會過大增長,從而保證了搜索其他路徑的可能,避免陷入局部最優解。
1.3 全局信息素更新
在所有螞蟻都遍歷城市之后,開始進行全局信息素更新。全局信息素更新只對當前最優螞蟻所走的路徑作用。全局信息素更新公式為
τij=(1-ρ)·τij+ρ·Δτij
(4)
式中,ρ為信息素揮發因子;Δτij是信息素增量,由螞蟻遍歷一周釋放的信息素與最優路徑相除得到。
2 蟻群算法的改進
針對蟻群算法易陷入停滯的缺陷,本文提出一種基于擁擠度的動態信息素蟻群算法(Dynamic Pheromone Ant Colony System,DPACSC),在蟻群釋放信息素的過程中實時監測當前路徑信息素含量和蟻群路徑的情況,為螞蟻提前做好分流準備,增加螞蟻探索其他路徑的可能,提前做好主動防御工作。
2.1 擁擠度
在路徑選擇過程中,螞蟻會傾向于尋找信息素大的路徑,同時由于蟻群算法的正反饋機制,信息素大的路徑在搜尋過程中信息素的累積會越來越大,進而導致蟻群算法陷入局部最優,直至停滯。為了增加蟻群算法路徑選擇的多樣性,提高蟻群算法全局搜索的能力,本文提出靜態擁擠與動態擁擠的概念。
定義1 靜態擁擠。設Pij是蟻群在某一輪循環后從i城市到j城市的路徑轉移概率。δ為接近于1的一個常數。當Pij>δ時,則定義路徑i→j發生全局擁擠。
定義2 動態擁擠。設螞蟻的總數為m,螞蟻在時刻t時位于城市u,且在t+1時刻選擇到達城市v的螞蟻總數為k,則在時刻t,路徑u→v的動態擁擠度定義為
(5)
2.2 狀態轉移規則更新
為防止蟻群算法過早集中于某些路徑,增大蟻群全局搜索能力,結合擁擠度的概念,改進的狀態轉移規則算法為
(6)
(7)
在啟發式信息相對重要性系數β的基礎上增加擁擠度參數,由擁擠度參數來動態控制啟發式信息在路徑選擇中的重要性,當該條路徑在某一時刻變得擁擠時,則相對降低它在候選路徑中的比例。
2.3 信息素更新方案
蟻群算法在構建解的過程中,會產生很多無用解,具體表現為:① 產生許多重復解,一直在進行無用迭代;② 構建許多明顯不是最優解的路徑,例如將兩個相距很遠的城市作為螞蟻路徑上的相鄰解。針對問題①,引入擁擠度的概念,擴大螞蟻選擇路徑的可能性來降低蟻群的重復解。同時加入下文的變異操作尋找更優異的解。針對問題②,提出“搜索域”概念,優先將最靠近當前城市的nk個城市置于“搜索域”中。但由于環境復雜性以及某些情況下最優解不在當前nk個城市中產生,造成漏解。因此設定如下“搜索域”方法。
假定在城市i處尋找下一城市j,首先尋找距離城市i最近的一處城市x,i→x的距離為dix,在此基礎上疊加一項Δd的參數,以(dix+Δd)為半徑,在此半徑范圍內的城市則為允許搜索的城市,其余歸入禁忌表之中。
(8)
式中,allow為可搜索的城市集合;tabu為蟻群的禁忌表集合。在可選取的城市中采用偽隨機概率選擇公式和擁擠度結合的方法進行下一個城市選擇。
2.4 變異操作
蟻群算法搜索路徑的大部分操作都是對重復路徑的查找。為避免這種重復操作,當路徑重復次數達到S次時,則表明當前查找路徑陷入局部最優解,開始進行兩元素優化(2-opt)的變異操作[15]。在當前最優路徑的城市訪問順序中選取兩個城市進行互換。當互換的城市并非相鄰順序的城市時,則將兩個城市之間的順序完全顛倒。例如,TSP城市集C={c1,c2,c3,…,cn},假設其中有兩個城市節點i,j。交換節點i在j的前面,即順序T=v1→v2…vi-1→vi→vi+1…vj-1→vj→vj+1…vn→v1,當進行交換順序時,將vi到vj之間的順序完全交換,即新的順序為T=v1→v2…vi-1→vj→vj-1…vi+1→vi→vj+1…vn→v1。這時檢驗交換后的路徑長度,若優于原路徑長度,則替換原搜索順序。在搜索時從前往后依次進行檢驗。本文在此基礎上再次進行改良,針對2-opt算法的盲目實驗替換,結合本文“搜索域”方案,使交換的兩元素限定在一定區域內,減少了實驗的操作步驟。經過試驗,本方法可一定程度上加快實驗收斂速度,基本可保證在100次迭代左右便搜索到較好的路徑。
3 算法框架
基于擁擠度的動態信息素蟻群算法的步驟表述如下。
① 初始化參數α,β,q0,ζ,ρ,δ,螞蟻變量t=1,城市變量m=1,循環次數NC。
② 查看是否達到最大的循環次數NC,若是,則直接退出算法,若不是,則更新各條路徑信息素的值,保留各次最優路徑。
③ 查看搜索相同路徑次數是否超過S,若是,則進行局部2-opt的路徑優化,如發現更優路徑,則用該路徑來替換搜索路徑。
④ 隨機分配螞蟻至各個城市,并將該城市計入禁忌表之中。
⑤ 判斷是否所有的螞蟻均已完成搜索,若是,則返回步驟②,否則從第t+1只螞蟻開始搜索路徑。
⑥ 判斷是否螞蟻已完成所有城市的訪問,若是,則返回步驟⑤,否則從第m+1個城市開始搜素路徑,并檢查搜索路徑概率是否大于δ。
⑦ 按“搜索域”大小搜索可訪問城市,并計算各條路徑上的擁擠度大小。
⑧ 按上述的狀態轉移規則選擇下一個城市的選取點,并將該點置入禁忌表中,返回步驟⑥。
⑨ 展示各條最優路徑。
4 仿真實驗
為使算法更具說服力,選用國際上經典的TSPLIB庫中的12個案例(Eil51、Berlin52、St70、KroA100等)作為標準實驗數據進行試驗。對參數的初始化固定如表1所示。其中,螞蟻數量設為城市數量的2/3, “搜索域”間距Δd設為初始間距dix的1/3。
利用Eclipse編寫程序驗證算法。表2為各TSP的官方數據。各問題求解結果如表3所示。圖1~圖8為所得路徑結果。
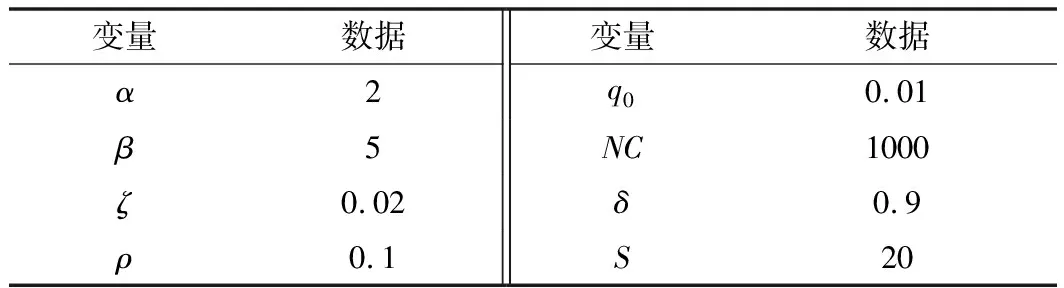
表1 各參數設置
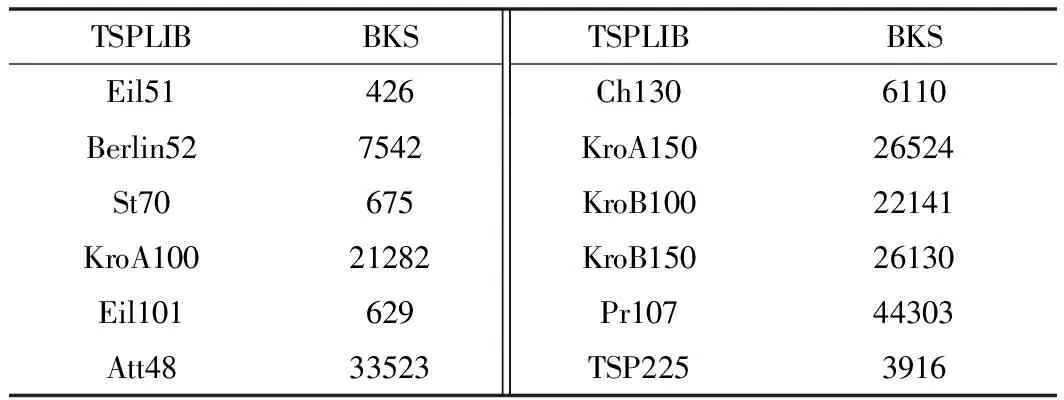
表2 各TSP官方最好記錄
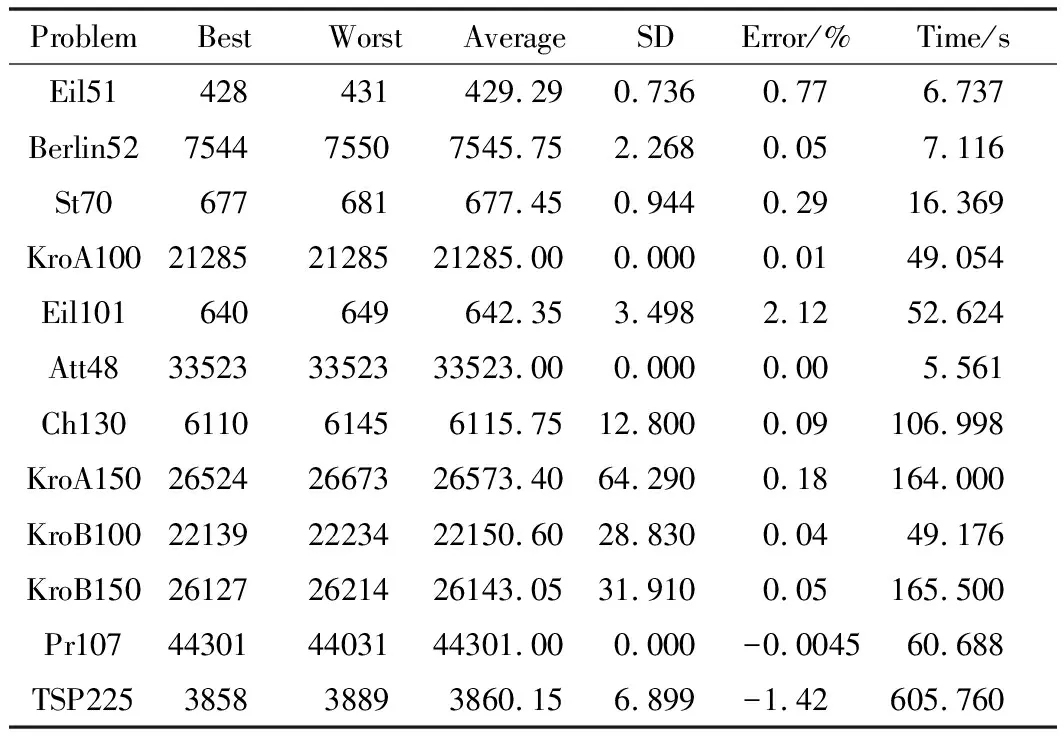
表3 典型TSP問題求解對比實例
SD:standard deviation

圖1 KroA100

圖2 St70

圖3 Berlin52

圖4 ch130

圖5 Eil101

圖6 KroA150

圖7 KroB150

圖8 TSP225
從表3可以看出,經過改進的蟻群算法在驗證各個TSPLIB問題時,都可得到接近最優解的路徑。從各算法性能比較(表5)中可以看出,有些結果要優于文獻中的研究結果。標準偏差也在理想范圍之內,說明在各個循環過程中,改進的蟻群算法可以得到較優解。對比文獻中的結果,所提出的方法產生了較為理想的結果。其中,對比WFA with 2-opt可以看出,在城市數目較小的情況下,WFA with 2-opt可以得到較好的路徑解,但隨著城市數目增大,解質量開始下降。反觀本算法,雖然在城市數目較小的情況下并未取得最優解,但與最優解的偏差都在可接受范圍內。即使城市數目開始增多,但解質量并未隨之變差,依舊在最優解附近。如KroA200問題中,WFA with 2-opt和PSO-ACO-3opt問題的標準偏差都已經很大,說明解已經開始不穩定。其中在和PSO-ACO-3opt算法的對比中,增加了兩者算法的運行時間比較,如表4所示。
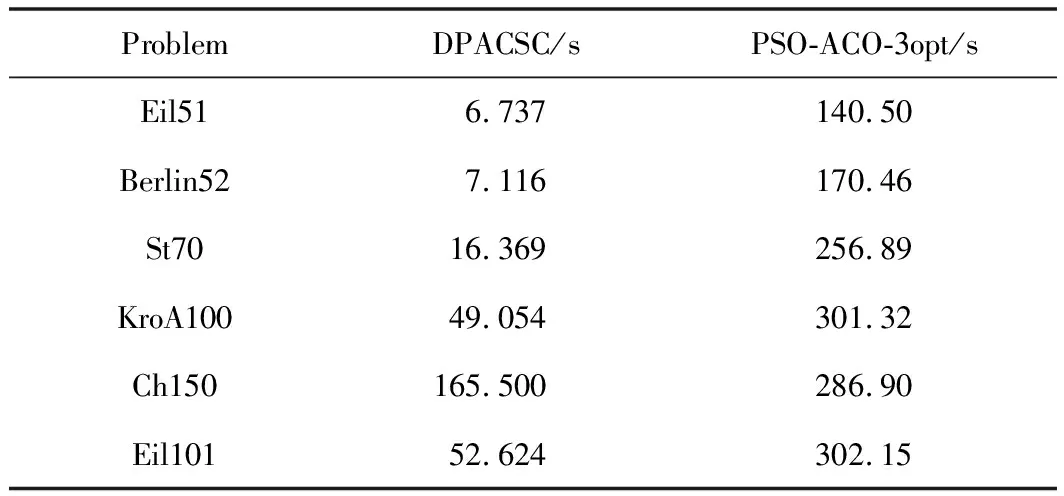
表4 算法的運行時間對比
通過表4可以看出,對于同一個TSPLIB問題,在相同的搜索次數內,PSO-ACO-3otp在求解時,將會花費較多時間,即使是最基本的Eil51問題,PSO-ACO-3opt將花費140.50 s的時間,而本算法只需6.737 s便可完成任務,在效率方面本算法更加優異。
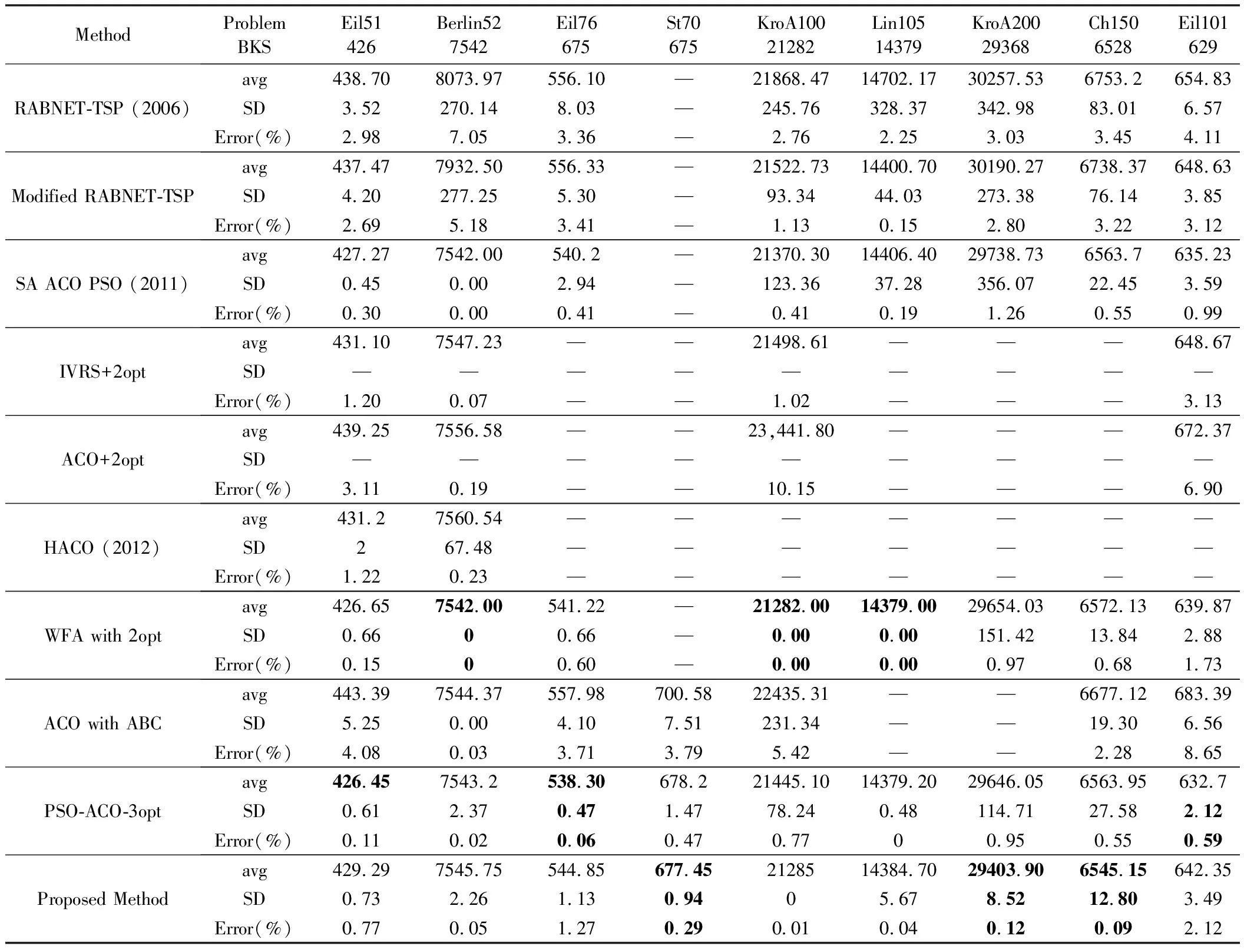
表5 各算法性能比較
5 結束語
針對蟻群算法易陷入局部最優解的問題,提出了一種基于擁擠度的蟻群優化算法。通過引入靜態擁擠度算子和動態擁擠度算子,蟻群算法參數可跟隨信息素濃度變化而動態更新,增強了蟻群之間的信息交流,達到了改善信息素矩陣的目的。改進的蟻群算法能夠提前主動預防早熟和停滯現象,提高了蟻群算法的全局搜索能力。同時加入的“搜索域”規則在求解過程中首先淘汰大部分劣質解,使算法在很少的步驟內就得到一組全局次優解,而引入的變異算子能對次優解進一步優化,增強蟻群算法的局部搜索能力。
蟻群算法作為一種新興的仿生優化算法,還有許多值得研究的地方,很多理論問題也有待進一步探討。但是隨著研究的深入,蟻群算法也將和其他模擬進化算法一樣,能夠獲得越來越多的應用。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
