圖像語義分割方法綜述
2019-09-23 01:21:06
測控技術 2019年7期
(空軍工程大學 信息與導航學院,陜西 西安 710077)
圖像語義分割(Semantic Segmentation)是一種將圖像劃分成一系列具有特定語義信息的圖像區域的方法,已成為圖像理解分析領域的一個研究熱點,并展現出廣闊的應用前景。例如,在智能汽車領域,通過對無人車前景物體圖像進行語義分割可以有效地幫助計算機判斷路況[1-2];在醫療領域,通過對醫學圖像進行語義分割可幫助醫生迅速分析和判斷患者病情[3-4]。
鑒于圖像語義分割方法的巨大應用價值,國內外大量研究機構和學者開展了相關研究,并取得大量研究成果。其中國外典型的機構包括:加州大學伯克利分校的機器視覺實驗室、普林斯頓大學的計算機視覺實驗室、斯坦福大學的人工智能和視覺實驗室以及卡內基梅隆大學的視覺與自主系統實驗室等[5-7]。在國內,近年來不少機構也對圖像語義分割進行了較為深入的研究工作,如香港中文大學、清華大學、國防科技大學、中國科學院自動化研究所、西安電子科技大學、上海交通大學和中山大學等[8-12]。
從方法研究的角度看,圖像語義分割的研究最早可追溯到計算機視覺的研究,早期的代表性成果是美國麻省理工學院Robertsr[13]提出的三維物體感知。之后麻省理工大學人工智能實驗室的D.Marr[14-15]將圖像處理與生物神經學等多學科結合,提出了著名的馬爾視覺計算理論,極大地促進了計算機視覺的研究進展。Bajcsy[16]和Aloimonos[17]等人針對馬爾視覺計算理論缺乏高層知識反饋等問題相繼提出了目的視覺和主動視覺等理論。從20世紀80年代以來,馬爾科夫隨機場(Markov Random Field,MRF)和條件隨機場(Conditional Random Field,CRF)理論在圖像語義分割中掀起一陣熱潮。Grenande[18]與Geman[19]的工作給出了計算機視覺問題通過MRF建模的完備數學描述,成功將MRF模型引入到圖像分析領域。Kumar[20]將CRF模型擴展到2-維格型結構,開始將其引入到圖像分析領域,引起了學術界的高度關注。隨著深度學習熱潮的出現,很多學者將其應用到圖像語義分割,極大地提高了分割效果[21-23]。
1 圖像語義分割方法
圖像語義分割可以視為一種在傳統圖像分割的基礎上,給各圖像區域賦予某種語義屬性的特殊的圖像分割方法。為便于理解,圖1給出了一幅圖像的語義分割示意圖,其中圖1(a)為原始圖像,圖1(b)為其語義分割結果,其將圖像分割為畫像、椅子、桌子、地板等語義區域,每個區域采用不同顏色進行標注區分[24]。

圖1 圖像語義分割示意圖
為了實現圖像語義分割,國內外眾多學者提出了大量方法。從驅動類型來看,圖像語義分割方法可分為基于模型驅動的方法和基于數據驅動的方法。
1.1 基于模型驅動的圖像語義分割方法
基于模型驅動的方法通過圖像語義分割進行數學建模,首先建立圖像語義分割的明確的數學模型,然后通過訓練數據確定相應數學模型的參數,最終利用確定模型實現圖像語義分割。
根據建模方法的不同,基于模型驅動的方法進一步可分為生成式(Generative)和判別式 (Discriminative)兩大類,如表1所示。對于輸入x,類別標簽y,用生成式模型估計它們的聯合概率分布P(x,y),而判別式模型用于估計條件概率分布P(y|x)。
(1) 生成式模型。
基于生成式模型的圖像語義分割方法先學習圖像特征和標簽的聯合概率,通過貝葉斯公式計算給定圖像特征時各個標簽的后驗概率,并依據后驗概率進行圖像標注[25]。這類方法具有可擴展的訓練過程,對訓練圖像集人工標注的質量要求較低。目前生成式模型主要有3類:概率潛在語義分析(Probabilistic Latent Semantic Analysis,PLSA)、隱狄利克雷分配(Latent Dirichlet Allocation,LDA)和MRF模型。
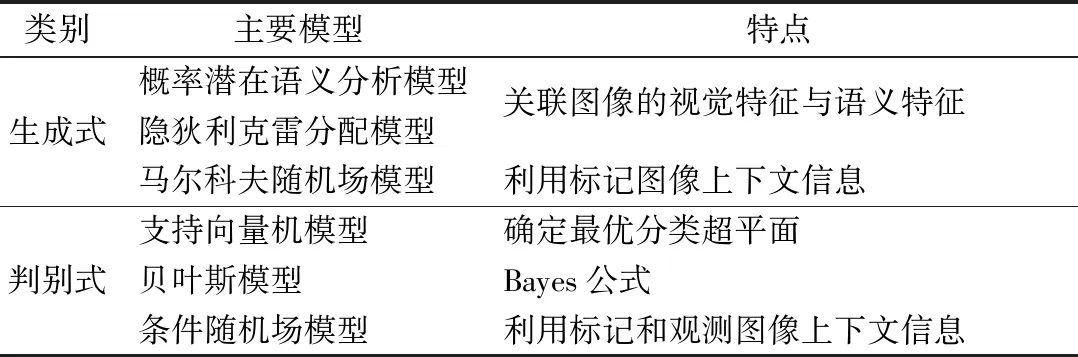
表1 模型驅動的方法
PLSA和LDA通過隱主題將圖像的視覺特征與語義特征相關聯,對圖像進行語義標記。Hofmann[26]等人在2001年提出的PLSA模型最開始應用于文本與自然語言的研究中,通過計算詞語和文本對應的概率分布確定詞語在文本中的相似性。在訓練數據太少或者存在噪音的情況下, PLSA 有時會出現過擬合的現象,針對這個問題,PLSA 通常采用期望最大化方法(Expectation Maximization,EM)對隱變量模型進行最大似然估計[27]。Blei[28]等人提出的LDA模型將超參層引入PLSA 模型,建立了隱變量的概率分布,在圖像語義分割中得到廣泛應用。
MRF模型是目前應用更為廣泛的一種生成式模型。MRF模型能夠很好地利用標記圖像的上下文信息,將標記圖像中的上下文信息和輸入的圖像特征包含在一個統一的理論框架中。現有的許多圖像標記方法,如對數回歸分類器[29]、支持向量機(Support Vector Machine,SVM)[30]等,只能用于獨立分布的標記數據,本身很難對表征數據相關性的上下文信息建模。圖像上下文信息只是簡單地用于后處理過程,而沒有應用在分類器的分類過程中,可能會降低圖像標記精度。MRF模型在分類過程可以利用部分先驗上下文信息和一些通過訓練得到的上下文信息,提高初步分類的結果。
二是切實強化防洪薄弱環節治理,著力提升防洪保安能力。加快推進大中型病險水庫、病險水閘除險加固工程,開工建設泗河、洙趙新河、大汶河、馬頰河等重要支流治理,力爭完成德惠新河續建任務;加快進一步治淮前期工作并及早組織實施,加快千里海堤工程建設。
(2) 判別式模型。
基于判別式模型的圖像語義分割方法假設圖像特征到標簽之間的映射是某種參數化的函數,直接在訓練數據上學習此函數的參數。這類方法將各個語義概念視為獨立的類別,一般來說能取得較高的標注精度。判別式的圖像語義分割模型主要包括貝葉斯(Bayes)模型、高斯混合模型(Gaussian Mixture Model,GMM)、SVM模型和CRF模型。
Bayes模型通過Bayes公式求解后驗概率,實現對圖像的語義分割。Shi等人[27]對每個語義概念進行建模,將先驗層次知識與圖像的多級概念結構表示方法相結合,再利用Bayes框架實現圖像語義分割。在基于模型驅動的語義分割方法中,建立的模型往往需要大量的圖像數據來進行參數學習,這種情況下,很多研究者使用GMM模型進行圖像語義分割。Barnard[31]利用GMM模型對圖像中的每個語義類的分布進行建模,最后用EM方法對模型參數進行學習。
SVM定義為特征空間上的間隔最大的線性分類器,即確定一個最優分類超平面,使兩類訓練樣本中距離超平面最近的樣本與超平面距離最大。SVM因其可處理非線性、高維小樣本并且具有良好的泛化能力,在圖像語義分割中得到廣泛的應用。文獻[32]詳細介紹了SVM,文獻[5]將SVM用于圖像語義分割,在PASACAL 2009和PASACAL 2010數據集上進行測試。Felzenszwalb等人[33]組合梯度下降直方圖和SVM在PASACAL圖像分割挑戰賽上獲得第七名的成績。
CRF是Lafferty等人[34]提出的一種概率圖模型,最初用于處理序列數據。由于可以融合多特征和上下文信息,隨后CRF模型在圖像標記中得到了成功的應用[35]。相比于MRF模型,CRF模型不僅可以利用標記圖像上下文信息,還可以利用觀察圖像中從局部到全局各種形式的上下文信息[9]。
1.2 基于數據驅動的圖像語義分割方法
與基于模型驅動的方法不同,基于數據驅動的方法從圖像數據本身出發,可利用大量訓練數據自動學習特征,然后聯合優化特征表示和分類器,充分挖掘其中蘊含的類別信息來實現圖像語義分割。最近幾年,深度學習技術在處理多種計算機視覺任務上取得了巨大進展,尤其是一些處理圖像分類和目標檢測問題的方法,如卷積神經網絡(Convolutional Neural Network,CNN)等[36-38],越來越多的研究者開始利用CNN來解決圖像標記問題。相對于傳統方法, CNN通過訓練數據自動學習特征,可以控制整體模型的擬合能力,是一種典型的數據驅動的語義分割方法。很多基于深度學習的方法[39-41]既需要大量的訓練數據來確定網絡參數,也需要建立相應的模型,本小節根據這類方法需要通過大量訓練數據自動學習特征的特點將其統一歸為基于數據驅動的圖像語義分割方法介紹。
CNN是一種高性能的深層神經網絡模型。一方面,CNN神經元間的連接是非全連接的,另一方面,同一層中某些神經元之間的連接的權重是共享的。它的非全連接和權值共享的網絡結構使之更類似于生物神經網絡,降低了網絡模型的復雜度,減少了權值的數量。如基于ImageNet訓練的AlexNet[37]模型輸出一個1000維的向量表示輸入圖像屬于每一類的概率。AlexNet[42]只能用于對圖像分類,無法完成語義分割任務。Long等人的FCN(Fully Convolutional Network)[23]提出了使用全卷積網絡進行語義分割,推廣了原有的基于全連接層的網絡結構,在不帶有全連接層的情況下能進行密集預測。FCN可以接受任意尺寸的輸入圖像,對最后一個卷積層的feature map進行上采樣,使它恢復到與輸入圖像相同的尺寸,從而可以對每個像素都產生了一個預測,同時保留了原始輸入圖像中的空間信息,最后在上采樣的特征圖上進行逐像素分類。
盡管FCN具有強大的靈活性,但仍然存在其所提取特征的類內緊湊度不夠以及類間可分性不高的問題,針對這些問題,目前針對FCN的改善主要集中在引入全局上下文信息以及改善分割邊緣兩個方面。在引入全局上下文信息方面, DeepLab模型[39]將全連接CRF引入到FCN中,對FCN預測結果進行后處理。它將每個像素點表示為CRF模型中的節點,無論兩個像素距離多遠,每個像素對都可以用一個成對項表示。Zheng[40]等人提出了另外一種引入全局上下文信息的方法CRFasRNN,將CRF的求解推理迭代過程看成了RNN的相關運算,嵌入CNN模型中,最終實現FCN與CRF的端到端結合訓練。文獻[41]提出的深度解析網絡(Deep Parsing Network,DPN)將MRF與傳統CNN結合,將MRF的單位置函數和雙位置函數的推斷和學習統一到CNN中,取得了比CRFasRNN更好的分割性能。在改善分割邊緣方面,文獻[43]針對FCN池化會造成分辨率下降的問題提出使用空洞卷積層(Dilated Convolution Layer),可使感受野呈指數級增長,而空間維度不至于下降。2016年劍橋大學提出的SegNet[44],使用不到1000張圖訓練出城市道路分割網絡,對很多場景都有很好的泛化性,通過逐步的編碼解碼使其能較好保留細節信息。文獻[45]利用金字塔池化實現整體輪廓信息與細節紋理結合,在一定程度上解決了分割任務中的多尺度問題。
基于模型驅動的語義分割方法對特征和分類器分開優化,研究者往往采用手工設計特征提取方法,再采用合適的分類器對特征進行分類,這類方法可顯式地分析特征的表示方式,但描述能力有限。而典型的基于數據驅動的語義分割方法,如CNN,可通過訓練數據自動學習特征,然后聯合優化特征表示和分類器,最大程度地發揮了二者聯合協作的性能,但是這類方法難以有清晰的數學表達。
2 語義分割方法評價標準
為評估圖像語義分割方法的性能,除了時間、內存開銷外,主要是從語義分割的準確性進行衡量。目前,圖像語義分割的準確性度量的指標主要包括像素精度(Pixel Accuracy,PA)、平均像素精度(Mean Pixel Accuracy,MPA)和均交并比(Mean Intersection over Union,MIoU),其定義如下。
假設測試數據集中總共有n個類(從L1~Ln),pij表示第i類數據中被標記為第j類的數量,pji表示第j類數據中被標記為第i類的數量,則
① PA 定義為正確分類像素數與總像素數的比值。
(1)
② MPA 相較于PA,在每個類別的基礎上計算正確分類像素的比例再求平均。
(2)
③ MIoU是一種最為常用的準確性評估標準,只需求每一類真實標記和預測標記交集與它們并集的比值再取平均,這種評估標準可以較好地評估語義分割方法的性能。
(3)
上述的3種評價標準中,PA和MPA僅簡單地計算正確分類像素的比例,而MIoU通過計算每一類真實標記和預測標記交集與它們并集的比值的平均值作為評估標準,相對于其他兩種方法計算更為精確。目前研究者主要采用MIoU評估其方法性能。
3 結束語
圖像語義分割是圖像理解分析的重要組成內容,其研究具有重要理論意義和廣闊應用前景。介紹了主流的圖像語義分割方法。目前,圖像語義分割方法的研究已取得巨大進展,隨著深度學習等理論的發展以及海量圖像數據的涌現,認為圖像語義分割方法面臨的問題及其發展趨勢包括如下幾方面。
① 深度學習模型中的參數設置問題。深度學習模型中的參數確定在很大程度上會直接影響最終的性能,當前的深度學習模型的參數包括網絡層數、迭代次數和學習率等基本都是依據經驗得到的,雖然也取得了較為不錯的結果,但沒有從中總結出規律。因此,找到合適的參數設置方法是提高深度學習模型性能和推動深度學習技術向前邁進的重要方向。
② 深度學習方法的實時性問題。深度學習模型往往包含的層數較多,其中有海量的參數需要訓練,耗時非常長,嚴重降低了方法的實時性。因此,如何在保證精度的基礎上提高方法的實時性是后續研究工作的一個重點研究方向。
③ 基于模型驅動的方法的特征提取問題。當前基于模型驅動的方法需要依據先驗知識人工設計特征,很多時候特征設計不合理會導致特征表征性不強,因此,如何提取更具表征性的特征是后續研究的一個重要方向。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
