基于Python的微信公眾平臺數據爬蟲
2019-10-14 00:42:32
福建質量管理 2019年17期
(重慶交通大學 重慶 400074)
引言
信息技術的進步和人工智能的到來使人們的生活方式逐漸發生改變,社交網絡的高速發展和形式變遷就是一個非常突出的例子。在大數據時代,社交網絡產生的數據就像一個巨大的寶庫,這吸引了大量的研究人員參與到相關內容的研究。在國外,人們針對Twitter、Facebook等知名社交平臺展開了一系列的分析。但是針對國內社交網絡平臺的研究還比較欠缺。主要是缺乏相關的研究數據,使得一些研究難以開展。在國外Twitter等社交平臺會提供一些數據接口供研究人員獲取研究數據,但是在國內卻無法正常訪問這些接口。如此之大的一個社交平臺為社交網絡分析、網絡數據挖掘等研究提供了強有力的大數據支持。
目前微信公眾號注冊量巨大,然而微信公眾平臺并沒有提供相關的數據接口,沒有數據,一些研究分析工作也無法進行。目前網絡中也存在一些公開的微信公眾號數據供人們下載,但是這些數據集通常規模比較小,而些技術力量強勁、資源充足的研究團隊通常自己開發一些爬蟲來獲取研究數據。這對不熟悉爬蟲技術的且還缺乏實時性。有研究人員而言是個極大的挑戰。本文提出了一款基于Python語言的微信公眾號數據爬蟲,為數據獲取提供支持。
本文爬蟲通過模擬客戶端的操作如登錄、訪問關注量、查看歷史消息、查看消息內容等方式獲取相關數據,并且將這些數據持久化保存到本地硬盤上,方便后續進一步的數據挖掘與分析。使用本文爬蟲能夠節省分析人員的開發時間,使得他們可以將更多的精力放在數據分析上面,同時也可以對一些無用的數據起到過濾作用。
一、爬蟲相關原理
想要爬取某些網站的數據需要一些手段才能實現,因為并非所有人都希望自己的成果被別人輕易地復制據為己有,但是在不違反道德和法律的基礎上,僅用于個人能力提升和學術上的研究以及在不影響他人利益的情況下自己獲利進行網頁數據爬取是很有必要的。
首先找到目標數據網頁并發送請求,獲取響應內容,分析目標數據所對應的URL(統一資源定位符),找到目標數據在網頁源代碼中的位置,然后用正則表達式鎖定要選取的內容下載數據存到本地,清洗數據,最后保存數據。
(一)發送HTTP請求
進行網頁數據爬取的第一步是得到該網頁的URL,有了URL之后用Python向服務端發送HTTP請求。
一般的網頁信息的爬取請求方式是get,如果需要填寫表單才能進一步獲取資源請求方式是post。在專業領域中還有更多請求方式,一般有四種基本請求方式,即get,post,put,delete,本文主要涉及get請求和post請求。一般的網站專業人士認為get請求和post請求的本質的區別在于,get請求主要用于獲取、查詢資源信息,post請求主要用于更新(修改)資源信息。
(二)HTTP請求響應
當用戶向服務端發送了請求之后,服務端會根據HTTP協議中的定義解析出請求的東西然后發送給用戶。每一次響應都會有一個相對應響應狀態,響應成功對應的響應碼是200,其他的一般都是響應錯誤。
(三)正則表達式
正則表達式,又稱規則表達式。(英語:Regular Expression,在代碼中常簡寫為regex、regexp或RE),計算機科學的一個概念。正則表達式通常被用來檢索、替換那些符合某個模式(規則)的文本。
許多程序設計語言都支持利用正則表達式進行字符串操作。例如,在Perl中就內建了一個功能強大的正則表達式引擎。正則表達式這個概念最初是由Unix中的工具軟件(例如sed和grep)普及開的。正則表達式通常縮寫成“regex”,單數有regexp、regex,復數有regexps、regexes、regexen。
正則表達式能從一大堆信息中提取本文想要的信息。構造正則表達式是得到網頁源代碼之后非常重要的一步,構造正則表達式需要觀察網頁源代碼的特征,正則表達式中的字符表達基本上有下面這些:
二、爬蟲算法模塊
(一)主要模塊
1.re模塊
re模塊就是正則表達式對應的模塊,可以直接選取本文需要的資源,這里主要用了re模塊下的re.compile(A).findall(B)函數,參數A是本文按照自己需求構造的正則表達式用來提取有用的資源,參數B是所有資源
2.urllib模塊
urllib模塊有很多功能,其中本文主要涉及到的函數或功能有urllib.request下面的urlopen,build_opener,install_opener,ProxyHandler,retrieve等。
urllib模塊是整個基礎爬蟲中最重要的模塊之一,本文主要引用了urllib模塊進行爬蟲有關操作,當然也有其他模塊和框架(scrapy項目框架)可以進行爬蟲,在此暫時不做考慮。
(二)應對反爬蟲機制
在對某些網站進行爬取的時候會遇到一些反爬機制,所謂反爬機制就是指對方不希望別人用除瀏覽器以外的途徑去獲取該網站的信息或者不希望該網站的數據被某些人用于商業用途從而制作的一些拒絕爬取的手段。本文主要講的有兩種反爬機制分別是,網站拒絕除瀏覽器以外的訪問方式和網站拒絕反復多次提供數據給同一IP地址.針對第一種常見的解決方案是構建用戶代理或者用戶代理池,針對第二種情況則是構建IP代理或者IP代理池。
(三)用戶代理池
用戶代理(User Agent),簡稱 UA,它是一個特殊字符串頭,使得服務器能夠識別客戶使用的操作系統及版本、CPU 類型、瀏覽器及版本、瀏覽器渲染引擎、瀏覽器語言、瀏覽器插件等.一些網站常常通過判斷 UA 來給不同的操作系統、不同的瀏覽器發送不同的頁面,因此可能造成某些頁面無法在某個瀏覽器中正常顯示,但通過偽裝 UA 可以繞過檢測。
用戶代理池由多個用戶代理構成,從里面隨機選取一個用戶代理來應對相應的錯誤.
(四)IP代理池
高頻抓取某個網站的數據,很有可能就被網站管理員封掉IP,導致抓取數據失敗,解決這個問題最直接,簡單的方法就是使用代理IP。目前網上有不少提供付費代理IP的平臺,但是如需長期使用,該方案是筆不少的開銷。本項目通過抓取IP代理網站提供免費代理IP,并不間斷的驗證IP的有效性,根據代理IP驗證的歷史記錄對IP進行評估,輸出高質量代理IP。
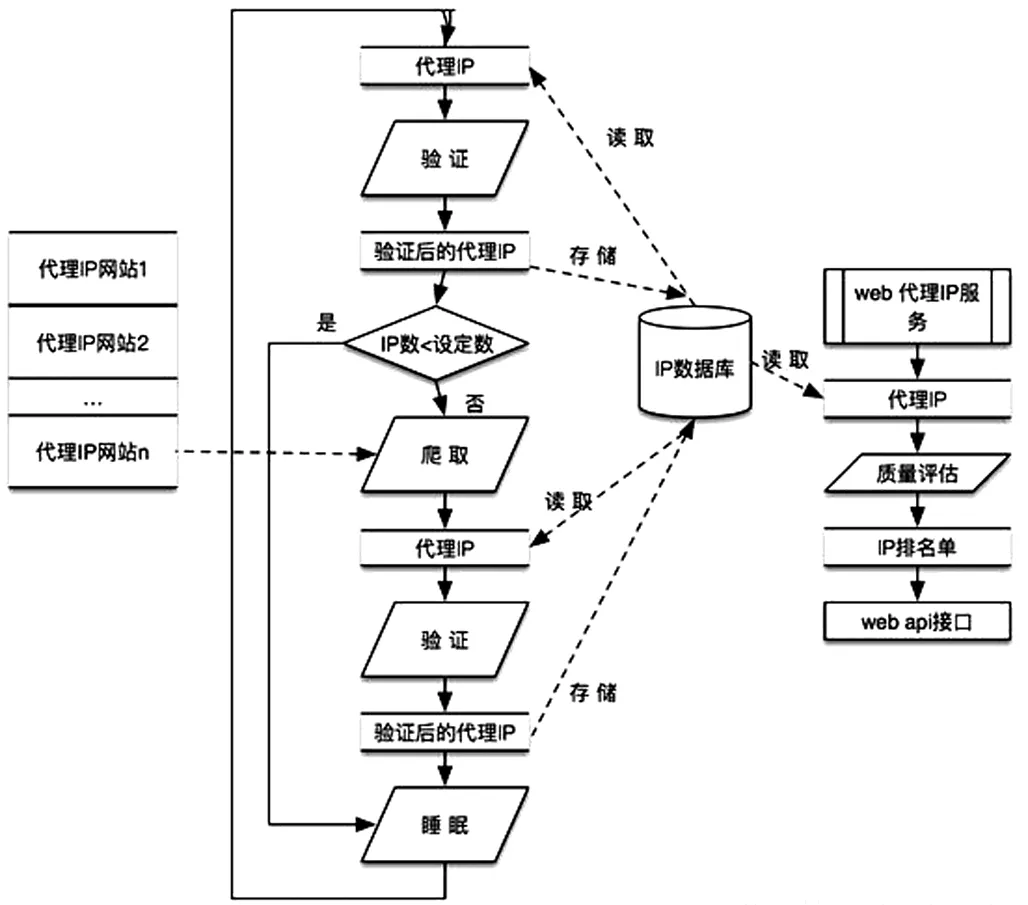
三、Python數據爬蟲操作
(一)微信登錄
微信公眾號平臺數據需要在登錄的情況下才能訪問到,所以微信公眾號登錄是爬蟲需要解決的第一個問題。微信公眾號一般有以下幾個步驟:
1.客戶端向用戶服務器發送登錄請求;
2.服務器接收到登錄請求后會生成相應的密鑰返回給客戶端;
3.客戶端將用戶的用戶名、密碼以及中服務器發回的登錄密鑰結合在一起再向服務器提交登錄信息,服務器驗證成功之后將會返回正確的登錄狀態以及當前用戶的個人信息。成功登錄之后客戶端只需要保持與服務器的session會話就可以方便地訪問微信公眾號中的數據資源。
(二)微信公眾號正文內容抓取
本文爬蟲針對用戶的微信公眾號內容提供了相應的抓取方法。一種方法是:本文爬蟲可以將用戶的所有微信公眾號內容全部以文件的形式完全記錄到磁盤,但是這樣做就需要很多的物理存儲空間才能將如此之多的用戶數據保存下來。另一種方法是:本文爬蟲提供了簡單的字符串匹配功能,在抓取用戶微信公眾號內容的過程中會根據需要匹配的關鍵字進行匹配,如果發現匹配成功的爬蟲會將該數據內容保存到磁盤。這樣研究人員就可以有針對性地進行相關研究和分析。
(三)某微信公眾號的爬蟲數據分析
通過對某一微信公眾號的數據進行爬蟲,從網頁上爬取文本數據之后可以進行一系列的分析,以關鍵詞出現頻率為例畫出詞云圖。相對傳統的統計圖有更好的觀賞性,并且清晰直觀的看出此微信公眾號的主要內容與CNN卷積神經網絡,運算,領導等關鍵詞有關,可以粗略推斷本文爬取的公眾號是與人工智能和數據科學有關的公眾號。

四、結論與展望
在本文利用Python數據爬蟲對微信公眾號數據進行爬取中,選出爬取文本中高頻出現的詞匯,并用詞云圖的形式表示出來,由于其清晰明了的可視化效果,可以為初學者的統計分析提供分析方向。
大數據時代,對大數據的分析應當成為一個行業,數據擁有者應該開放數據的分析接口,讓數據的價值釋放,而爬蟲開發者,很多時候是數據分析者,最起碼是個數據清洗和篩選者。他們蒙上了一層神秘面紗,帶著一絲黑客氣息,法律應當給他們更大的生存空間,讓這個有價值的行業創造更大的價值。
猜你喜歡
中國信息化周報(2016年46期)2017-03-25 17:35:29
中國信息化周報(2016年47期)2017-03-25 17:33:41
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國信息化周報(2016年9期)2016-03-21 19:47:42
中國信息化周報(2015年27期)2015-08-12 22:09:31
中國信息化周報(2015年28期)2015-08-06 22:08:50
中國信息化周報(2015年13期)2015-06-01 21:47:12
創業家(2015年10期)2015-02-27 07:55:08
