涪陵焦石壩頁巖氣井調產分析及預測
2019-10-15 07:17:40夏欽鋒
現代計算機 2019年24期
夏欽鋒
(中石化重慶涪陵頁巖氣勘探開發有限公司,重慶408014)
0 引言
近年來,隨著我國頁巖氣勘探開發的快速推進,我國已經成為繼美國和加拿大之后全球第三個開展頁巖氣商業開發的國家[1-2]。目前國內外學者根據翁氏模型理論基礎,結合多元線性回歸系數求解法,對實際頁巖氣生產井進行產能預測,分析頁巖氣井產量變化規律[3];謝維楊[4]結合頁巖氣藏水平井壓裂后產生水力壓裂縫這一情況,建立水力壓裂縫導流的頁巖氣藏水平井后期穩定開采的滲流模型;任俊杰等人[5]綜合考慮頁巖氣解吸、擴散和滲流特征,建立頁巖氣藏壓裂水平井產能模型。總體而言,目前國內外學者在研究頁巖氣井產能時,一般采用經驗法、解析法和數值模擬三種方法來預測頁巖氣井生產規律,可靠性都不高,不能依據已有的歷史生產數據進行準確的壓力預測。
在調產過程中產量發生變化時,壓力也隨之變化。生產過程中采集的大量數據蘊含信息豐富,根據歷史生產數據對氣井的生產壓力進行預測,對后期持續開發和利用有著促進作用。然而調產過程中產量變化梯度多、調產周期波動大、歷史數據不平衡、生產數據具有強非線性[6]、強耦合等特點,導致生產壓力難以預測。在調產井中,壓力的遞減趨勢隨產量的變化而發生改變,不能通過一般模型進行建模[9-10]。
針對上述問題,本文采用FCM 方法對調產井生產數據進行自適應聚類,保證數據的準確性;再運用Kendall 秩相關系數分析法對生產數據進行相關性分析,以確定用于遞歸神經網絡建模的輸入變量;最后分別對每一類數據進行建模,形成多模型庫。在壓力預測時,輸入需要預測的產量以及歷史數據,系統將自動識別并調用其對應的模型進行壓力預測,實現不同產量下的壓力預測。
1 相關性分析
通過對原始生產數據進行相關性分析,找出數據之間的隱藏特性,從而挖掘出有用的數據進行進一步分析。其主要相互影響的參數有:產量、壓力、水。進行相關性分析主要分為以下兩個部分:
(1)評價數據質量的可靠性,包含產量、壓力、水等重要指標。
(2)數據相關性檢驗。依據典型氣井的生產數據分析可知,壓力、產量、水之間有較強的相關性,通過提取幾組生產數據進行相關性檢驗,其中包括產量-壓力、產量-時間和壓力-時間。

圖1 壓力預測流程圖
使用Spearman 相關性分析對生產數據進行分析[11],它是利用數據的秩進行計算,適用于有序數據或不滿足正態分布假設的等間隔數據,關聯值范圍在[-1,1],絕對是越大,表明相關性越強。先對原始變量的數據排秩,根據秩使用Spearman 相關系數公式進行計算,相關系數符號表示相關方向。其計算公式為:

式中,αi是第i 個x 值的秩,βi是第i 個y 值的秩。αˉ、βˉ分別是αi和βi的平均值。
選取涪陵焦石壩區塊的以下典型井生產數據,通過上面方法進行數據相關性,其原始生產數據如圖2、圖3 所示。

圖2 焦頁24-1HF數據圖

圖3 焦頁37-3HF數據圖

表1 焦頁24-1HF 相關性分析結果

表2 焦頁37-3HF 相關性分析結果
根據圖2、3 和表1、2 可以說明產水量明顯變化時,壓力也發生變化,壓力變化與產水量之間有著良好的負相關。該氣井水主要由產氣攜液得到,其水量與得到的氣體是有正相關性,說明產氣越豐富,得到的水就越多。由于地層存儲豐富,所以產氣量較為豐富,得到的水量也較為充足,從而致使壓力遞減速度比較慢。
2 模糊C均值聚類算法
模糊C 均值聚類算法(FCM)是用隸屬度確定每個數據點屬于某個聚類的程度的一種聚類算法。FCM 把n 個向量xi(i=1,2,…,n)分為c 個模糊組,并求每組的聚類中心,使得非相似性指標的價值函數達到最小。FCM 用模糊劃分,使得每個給定數據點用值在[ ]0,1間的隸屬度來確定其屬于各個組的程度。與引入模糊劃分相適應,隸屬矩陣U 允許有取值在[ ]0,1 間的元素。不過,規定一個數據集的隸屬度的和總等于1。

那么,FCM 的價值函數(或目標函數)就是:

這里uij介于[0 ,1] 之間;ci為模糊組I 的聚類中心,dij=‖ ci-xj‖為第i 個聚類中心與第j 個數據點間的歐幾里德距離,且m ∈[1,∞)是一個加權指數。
構造如下新的目標函數,使公式(2)達到最小值的必要條件:

這里λj( j= 1,…,n )是公式(2)的n 個約束式的拉格朗日乘子,對所有輸入參量求導,使公式(3)達到最小的必要條件為:

和:

由上述兩個必要條件,FCM 算法是一個簡單的迭代過程。在批處理方式運行時,FCM 用下列步驟確定聚類中心ci和隸屬矩陣U:
步驟1:用值在[0 ,1] 間的隨機數初始化隸屬矩陣U,使其滿足公式(2)中的約束條件;
步 驟 2:用 公 式(5)計 算 c 個 聚 類 中心ci(i=1,2,…,c);
步驟3:根據公式(3)計算價值函數。如果它小于某個確定的閾值,或它相對上次價值,函數值的改變量小于某個閾值,則算法停止;
步驟4:用公式(6)計算新的U 矩陣。返回步驟2。
通過FCM 算法對原始數據進行聚類分析,然后把原始數據分為我們想要的幾種情況,具體結果如圖4、圖5 所示,首先根據每口調產井產量類型大致設置需要分類的數量。

圖4 焦頁24-1HF分類結果圖(設置為3類)

圖5 焦頁37-3HF分類結果圖(設置為4類)
通過圖4 可以看出,把焦頁24-1HF 井中的產量分為三類,能夠良好地顯示出產量的梯度,從而更好地進行預測分析。圖5 中焦頁24-1HF 井的數據結構較為復雜,把它分為三類,能夠良好地分出其梯度。
3 Elman神經網絡多模型建模以及預測
根據不同的劃分標準,神經網絡可劃分成不同的種類。按連接方式來分主要有兩種:前向神經網絡和反饋(遞歸)神經網絡。人工神經網絡以其自身的自組織、自適應和自學習的特點,被廣泛應用于各個領域,在控制領域對非線性系統的建模與控制的應用也發揮越來大的作用。不過一般采用的前向網絡所建立的輸入/輸出之間的關系式往往是靜態的,而實際應用中的被控對象通常都是時變的。因此采用靜態神經網絡建模就不能準確地描述系統的動態性能[7]。而Elman 神經網絡不僅可以反映系統動態特性而且可以存儲信息。網絡中存在信息的延時,并且具有延時信息的反饋。遞歸網絡存儲信息的特性來源于網絡信號的反饋,信號遞歸使得網絡在某時刻k 的出入狀態不僅與k時刻的輸入狀態有關,而且還與k 時刻以前的信號有關,這充分的表現了網絡系統的動態性能,非常適用于具有時序性的頁巖氣生產數據的建模與預測[8]。其各層關系式為:
輸入層:

隱含層:

關聯層:
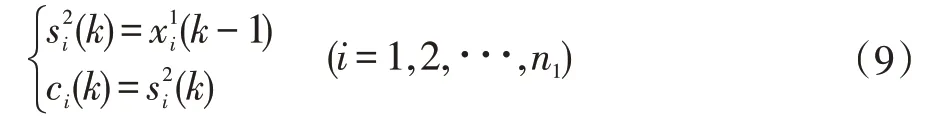
輸出層:

最終采用Elman 神經網絡多模型建模,考慮到每口頁巖氣井整體都有一個下降趨勢,針對這種情況我們不僅對分類結果分別建立模型,還把所有歷史數據也建立了模型,并且將建模結果保存在數組中,以便后期預測使用,如圖6 所示。

圖6 神經網絡建立模型(37-3HF分為4和5類)
其中,Net 表示整體數據建立的模型,net 中有4個神經網絡模型,分別對應于產量不同的分類結果建立的模型,最后根據需要預測的產量自動調用模型進行預測。
4 實驗研究
設置需要預測的產量,以及輸入當前產量下對應壓力的歷史數據,通過識別需要預測的產量,對應找到最符合設置的產量的模型,調用模型進行預測。首先設置自行選擇預測天數功能,操作人員可根據實際情況選擇需要預測的天數,并且填入哪種產量下的壓力預測,導入幾天歷史數據方可預測。在建模時以及預測時,不僅考慮了氣井壓力整體下降趨勢(對整體建立模型,將預測結果作為局部模型的輸入)以及各生產因素之間的相互影響,而且充分考慮當天生產壓力與歷史生產壓力的關系(歷史4 天預測第五天)。當輸入產量為100000 時(37-3HF),需要預測的天數設置為5,分類數設置為5 時,選取為經過訓練的歷史真實數據如表3。

表3 37-3HF 真實值與預測值對比表
從表3 可以看出,采用Spearman 相關性分析對歷史數據之間進行相關性分析后,在運用FCM 算法分類得到的幾類歷史數據,分別建立Elman 模型,針對不同產量下,預測得到的值非常接近真實值,有良好的預測結果,可供工作人員在后續調產中提供可靠的依據。
從圖7 可以看出,調產井37-3HF 在不同類別和不同產量的情況下,采用Elman 神經網絡針對每一類的局部模型進行預測時,通過對預測輸出值與當天真實數據對比可以看出,預測精度可以達到預期效果。而BP 神經網絡不能通過擬合歷史數據得到良好的模型進行預測,誤差較大,僅適用于定產井的預測。
當輸入產量為100000 時(24-1HF),需要預測的天數設置為5,分類數設置為3 時,選取為經過訓練的歷史真實數據如表4。

表4 24-1HF 真實值與預測值對比表

圖7 Elman神經網絡預測結果及誤差(37-3HF)

圖8 Elman神經網絡預測結果及誤差(24-1HF)
從表4 可以看出,采用Spearman 相關性分析對歷史數據之間進行相關性分析后,在運用FCM 算法分類得到的幾類歷史數據,分別建立Elman 模型,針對不同產量下,預測得到的值非常接近真實值,有良好的預測結果,可供工作人員在后續調產中提供可靠的依據。
從圖8 可以看出,調產井24-1HF 在不同分類、產量的情況下,利用Elman 神經網絡每一類的局部模型進行預測時,通過對神經網絡預測輸出與實際數據對比可以看出,預測精度可以達到預期的效果。而BP 神經網絡不能通過擬合歷史數據得到良好的模型進行預測,誤差較大,僅適用于定產井的預測。
5 結語
本文提出了一種適用于頁巖氣調產井生產數據預處理的方法,通過FCM 算法把不同產量進行了分類,消除了異常數據對Elman 神經網絡建模的影響;從而構造良好的神經網絡模型進行預測,與傳統BP 神經網絡相比,提高了預測精度;但在網絡收斂速度上仍有改進空間。
本文方法適用于涪陵焦石壩頁巖氣調產井,在模型精度優化上,還需要對神經網絡建模做進一步改進,仍需要考慮到頁巖氣生產壓力受多種因素影響,開發實踐中,需要充分考慮產量、水、油壓、套壓等各方面的影響,同時盡量保證數據的準確性與真實性,這樣方可建立相對準確的生產壓力模型,以提高評價精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
