基于深層聲學(xué)特征的端到端語音分離①
2019-10-18 06:40:40李娟娟李子晉
計(jì)算機(jī)系統(tǒng)應(yīng)用 2019年10期
李娟娟,王 丹,李子晉
1(復(fù)旦大學(xué) 計(jì)算機(jī)科學(xué)技術(shù)學(xué)院,上海 201203)2(盲信號處理國家級重點(diǎn)實(shí)驗(yàn)室,上海 200434)3(中國音樂學(xué)院 音樂科技系,北京 100101)
語音作為一項(xiàng)最為便捷的交流工具,實(shí)現(xiàn)了人類社會(huì)高效快速的信息交換,成為人類文明的一個(gè)重要助力.然而在現(xiàn)實(shí)環(huán)境中,感興趣的語音信號通常會(huì)被其他聲源干擾,嚴(yán)重?fù)p害了語音的可懂度,降低了語音交互的性能.為了解決以上問題,語音分離是最為關(guān)鍵的技術(shù)之一.
語音分離是指從多個(gè)說話人的混合語音中分離得到想要的語音數(shù)據(jù),源于著名的“雞尾酒會(huì)問題”[1],主要是研究如何能夠從混合的語音信號中同時(shí)得到目標(biāo)和干擾語音信號,它在語音識別、殘疾人助聽領(lǐng)域具有廣泛的應(yīng)用.本文主要探究兩個(gè)說話人混合的情況.圖1是語音分離技術(shù)的示意圖,圖中左邊的兩張語譜圖分別是兩個(gè)說話人的語音的語譜圖,經(jīng)過混合后得到中間的混合語音的語譜圖,而經(jīng)過語音分離以后得到的是右邊分離出的語音的語譜圖.從圖1可以看出,由于不同的說話人的語音的發(fā)音特性有差異和說話內(nèi)容、語速等不同,以及語音信號這種時(shí)變信號本身具有一定的短時(shí)平穩(wěn)特性,從而使得語音分離具有可行性[2].

圖1 語音分離技術(shù)示意圖
語音分離作為一個(gè)重要的研究領(lǐng)域,幾十年來,受到國內(nèi)外研究者的廣泛關(guān)注和重視.近年來,監(jiān)督性語音分離技術(shù)取得了重要的研究進(jìn)展,特別是深度學(xué)習(xí)的應(yīng)用,極大地促進(jìn)了語音分離的發(fā)展.在基于深度神經(jīng)網(wǎng)絡(luò)的語音分離算法中,特征提取是至關(guān)重要的步驟.傅里葉變換域特征是最常用的語音分離特征,Xu[3]、Huang[4]、Weninger[5]等使用傅里葉幅度譜或者傅里葉對數(shù)幅度譜作為語音分離的輸入特征.Wang等在文獻(xiàn)[6]中總結(jié)了Gammatone濾波變換域特征,并且利用Group Lasso的特征選擇方法得到AMS+RASTAPLP+MFCC的特征組合.Chen等在文獻(xiàn)[7]中提取的多分辨率特征MRCG具有明顯的優(yōu)勢,逐漸取代了組合特征成為語音分離中最常用的特征之一.然而以上這些傳統(tǒng)聲學(xué)特征的提取需要經(jīng)一系列復(fù)雜的操作,會(huì)造成語音能量損失以及長時(shí)間延遲.
近年來,端到端的方法已經(jīng)用于語音識別、語音合成和語音增強(qiáng)等語音任務(wù)中,并在這些任務(wù)中取得了較優(yōu)的效果.Luo等人在文獻(xiàn)[8]中首次提出了基于非負(fù)矩陣分解思想的端到端語音分離,并取得了較優(yōu)的效果.為了進(jìn)一步說明端到端的方法在語音分離這一方向的可行性,本文提出以語音信號的原始波形作為深度神經(jīng)網(wǎng)絡(luò)的輸入,通過網(wǎng)絡(luò)模型來學(xué)習(xí)語音信號的更深層次的深層聲學(xué)特征,實(shí)現(xiàn)端到端的語音分離.
1 基于傳統(tǒng)聲學(xué)特征的語音分離
語音分離旨在分離混合語音信號中的信號,這個(gè)過程能夠很自然地表達(dá)成一個(gè)監(jiān)督性學(xué)習(xí)問題[3-5].一個(gè)典型的監(jiān)督性語音分離系統(tǒng)通常通過監(jiān)督性學(xué)習(xí)算法,例如深度神經(jīng)網(wǎng)絡(luò),學(xué)習(xí)一個(gè)從混合語音的傳統(tǒng)聲學(xué)特征到分離目標(biāo)的映射函數(shù)[9].算法1為基于傳統(tǒng)聲學(xué)特征的語音分離算法.

算法1.基于傳統(tǒng)聲學(xué)特征的語音分離算法1)時(shí)頻分解,通過信號處理的方法將輸入的時(shí)域信號分解成二維的時(shí)頻信號表示;2)特征提取,提取幀級別或者時(shí)頻單元級別的聽覺特征(短時(shí)傅里葉變換譜或者短時(shí)傅里葉功率譜等);3)模型訓(xùn)練,利用大量的輸入輸出訓(xùn)練對通過機(jī)器學(xué)習(xí)算法學(xué)習(xí)一個(gè)從混合語音特征到分離目標(biāo)(理想二值掩蔽或者理想比例掩蔽等)的映射函數(shù);4)波形合成,利用估計(jì)的分離目標(biāo)以及混合信號,通過逆變換(逆傅里葉變換或者逆聽覺濾波)獲得目標(biāo)語音的波形信號.
在提取傳統(tǒng)聲學(xué)特征時(shí),先要進(jìn)行時(shí)頻分解,一般都是將時(shí)域信號通過短時(shí)離散傅里葉變換(Short-time Fourier Transform,STFT)、離散余弦變換(Discrete Cosine Transform,DCT)或者通過一些聽覺濾波器組(如Gammatone濾波器組)得到二維的時(shí)頻域表示.在這個(gè)過程中產(chǎn)生了兩個(gè)問題.一是忽略了在提取特征的過程中造成語音的高頻部分以及相位信息的損失,以及在變換過程中可能會(huì)引入虛假的信息,從而對語音分離的性能造成影響.二是由于變換域中的有效語音分離對高頻分辨率的需求,導(dǎo)致相對較大的時(shí)間窗口長度,對于語音通常超過32毫秒[3,10-12],音樂分離超過90毫秒[13].因?yàn)橄到y(tǒng)的最小延遲受STFT時(shí)間窗的長度限制,所以當(dāng)需要非常短的延遲時(shí),這限制了此類系統(tǒng)的使用,例如電信系統(tǒng)或可聽設(shè)備這類實(shí)時(shí)性系統(tǒng).克服這些問題的一種自然方法是直接建模時(shí)域中的信號.有研究結(jié)果表明,語音原始波形相比基于傅里葉變換的梅爾倒譜系數(shù)等特征,在某些研究領(lǐng)域具有更好的語音性能[14].所以本文選擇以語音信號的原始波形作為深度神經(jīng)網(wǎng)絡(luò)的輸入,通過網(wǎng)絡(luò)模型來學(xué)習(xí)語音信號深層次的深層聲學(xué)特征(Deep Acoustic Feature,DAF),實(shí)現(xiàn)端到端的語音分離.
2 基于深層聲學(xué)特征的端到端語音分離
圖2是基于深層聲學(xué)特征的端到端語音分離算法的整體流程,主要分為4個(gè)部分:(1)信號預(yù)處理,對混合信號的原始波形進(jìn)行分段及規(guī)整.(2)深層聲學(xué)特征提取,提取時(shí)域信號的DAF作為分離模型的輸入.(3)分離模型,訓(xùn)練分離模型得到各個(gè)信號的特征掩蔽值.(4)信號重建,利用得到的信號的特征掩蔽值及混合信號的DAF,通過信號重建得到各個(gè)分離信號的時(shí)域波形.

圖2 算法整體流程
2.1 信號預(yù)處理
數(shù)據(jù)預(yù)處理在許多機(jī)器學(xué)習(xí)算法中起著很重要的作用,如果輸入的特征向量在整個(gè)訓(xùn)練集上均值接近零,那么模型的收斂速度會(huì)很快.語音信號的預(yù)處理模塊包括兩部分,分段、規(guī)整.
首先將混合信號分成K段,每段長度為L,再對每段使用單元L2規(guī)整,Xk是分段后的信號,規(guī)整方式如下:

單元L2規(guī)整即可以削弱時(shí)不變信道的影響,還能減少加性噪聲的影響,同時(shí)時(shí)域信號被縮放到相似的動(dòng)態(tài)范圍內(nèi),使得后續(xù)模型的學(xué)習(xí)過程也能取得較好的效果.
2.2 深層特征提取
在基于深度神經(jīng)網(wǎng)絡(luò)的語音分離算法中,語音分離任務(wù)能夠被表達(dá)成一個(gè)學(xué)習(xí)問題,對于深度學(xué)習(xí)問題,特征提取是至關(guān)重要的步驟.提取好的特征能夠極大地提高語音分離的性能[15].
針對傳統(tǒng)聲學(xué)特征提取方法需要經(jīng)過傅里葉變換、離散余弦變換等操作,提取復(fù)雜特征作為輸入,會(huì)造成能量損失的問題,本文選擇以語音信號的原始波形作為深度神經(jīng)網(wǎng)絡(luò)的輸入,通過網(wǎng)絡(luò)模型來學(xué)習(xí)語音信號深層次的聲學(xué)特征,DAF提取過程如圖3所示.

圖3 DAF提取過程
在DAF的提取過程中,參考語言建模[16]中的門限卷積方法,在第二層全連接層后引入門限機(jī)制如下:

其中,ReLU為線性整流函數(shù),σ為Sigmoid激活函數(shù),⊙表示逐元素乘積操作.引入門限機(jī)制可以控制模型中的信息流動(dòng),幫助模型的神經(jīng)元之間有更加復(fù)雜的聯(lián)系.相比于語音建模中的門限卷積,本文中使用全連接代替卷積操作,雖然使用卷積操作能減少訓(xùn)練參數(shù)從而縮短訓(xùn)練時(shí)間,但是使用全連接操作能減少語音損失的能量,提取的特征也能更多地挖掘深層次的聲學(xué)特征,提升語音分離的性能.
2.3 分離模型
雙向長短時(shí)記憶網(wǎng)絡(luò)(Bi-derectional Long Short Term Memory,BiLSTM)結(jié)構(gòu)能夠有效抓住音頻數(shù)據(jù)中的長時(shí)依賴,對語音建模非常有效[17,18].本文中,分離網(wǎng)絡(luò)由4層深度BiLSTM后面接著一個(gè)全連接層構(gòu)成,在第二層隱藏層的輸出與第四層隱藏層的輸出之間增加了跳躍連接[19],改善了多層網(wǎng)絡(luò)反向傳播的梯度消散問題,提升網(wǎng)絡(luò)性能.
網(wǎng)絡(luò)的輸入是混合信號的DAF,網(wǎng)絡(luò)的輸出是各個(gè)信號的掩蔽值.已有研究證明在語音分離任務(wù)中把掩蔽值(mask)作為分離目標(biāo)能顯著地提高語音分離的可懂度和感知質(zhì)量.其中,最常使用的分離目標(biāo)之一為理想比例掩蔽(Ideal Ratio Mask,IRM)[20].基于IRM的定義,本文中使用的信號的掩蔽值,特征比例掩蔽(Feature Ratio Mask,FRM)的定義如下:

使用掩蔽值作為分離模型的輸出比使用特征DAF的效果更好.全連接層的激活函數(shù)為Softmax函數(shù).為了加速訓(xùn)練進(jìn)程及維持訓(xùn)練過程中的穩(wěn)定性,對分離網(wǎng)絡(luò)的輸入即混合信號的DAF要進(jìn)行層級歸一化.
2.4 信號重建
將混合信號的DAF逐元素乘以各個(gè)信號的FRM,經(jīng)過一層全連接層后.得到規(guī)整的目標(biāo)信號的時(shí)域波形,最后通過逆規(guī)整和整合,重建各個(gè)信號的時(shí)域信號.
2.5 損失函數(shù)
網(wǎng)絡(luò)模型的最終輸出是估計(jì)的干凈信號的時(shí)域波形,由于模型效果的重要評價(jià)指標(biāo)之一是尺度不變信噪比(Scale-invariant Source-to-noise Ratio,SI-SNR)[8],所以在這里不使用估計(jì)語音的時(shí)域波形和干凈的時(shí)域波形的均方誤差,而是基于SI-SNR來設(shè)計(jì)損失函數(shù).SI-SNR的定義如下:
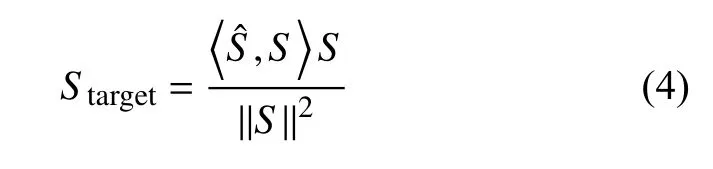

3 實(shí)驗(yàn)結(jié)果和分析
3.1 實(shí)驗(yàn)配置
華爾街日報(bào)語料庫(Wall Street Journal,WSJ0)是語音分離任務(wù)常用的數(shù)據(jù)集[11-13],每條語音大約在5 s左右.混合語音由隨機(jī)選取WSJ0訓(xùn)練集si_tr_s中的任意兩個(gè)說話人,以隨機(jī)選取的0-5 dB信噪比混合而成,最終形成30個(gè)小時(shí)的訓(xùn)練集和10小時(shí)的驗(yàn)證集.測試集使用WSJ0的si_dt_05和si_et_05的未知說話人以相同的混合方式產(chǎn)生,最終生成5小時(shí)的測試集.
實(shí)驗(yàn)中所使用的語音波形文件具有8 kHz的采樣頻率.分段時(shí)的長度L=40 (5 ms),每段之間有50%的重疊,提取的DAF長度為500.深度BiLSTM采用4層隱藏層,每層隱藏層的結(jié)點(diǎn)是500,在第二層隱藏層的輸出與第四層隱藏層的輸出之間有跳躍連接,最后一層全連接層的結(jié)點(diǎn)數(shù)為1000,使用Softmax激活函數(shù).在訓(xùn)練過程中,使用隨機(jī)初始化的網(wǎng)絡(luò),采用的最小批訓(xùn)練方法中每個(gè)最小批的訓(xùn)練集包含128個(gè)樣本.初始的學(xué)習(xí)率設(shè)置為1e-3,當(dāng)驗(yàn)證集上的損失在連續(xù)3個(gè)迭代次數(shù)(epoch)沒有降低時(shí),就將學(xué)習(xí)率設(shè)置為當(dāng)前學(xué)習(xí)率的一半.當(dāng)驗(yàn)證集上的損失在連續(xù)10個(gè)epoch都沒有降低時(shí)停止訓(xùn)練.選用Adam優(yōu)化函數(shù),Adam優(yōu)化器的超參數(shù)具有很好的解釋性,通常無需調(diào)整或僅需很少的微調(diào),適用于大規(guī)模數(shù)據(jù)及參數(shù)的場景.
3.2 評價(jià)指標(biāo)
本實(shí)驗(yàn)中采用的評價(jià)指標(biāo)為BSS-EVAL指標(biāo).BSSEVAL工具箱通常用來評估模型的分離性能,它是由Vincent 等人在 2006年提出的語音分離指標(biāo)[21],并開源的語音分離評估工具箱,廣泛被研究者用于語音分離評價(jià)中.根據(jù) BSS-EVAL 指標(biāo),語音分離評估使用3個(gè)定量值分別是,信噪干擾比(Source to Interference Ratio,SIR),信噪偽影比(Source to Artifact Ratio,SAR)和信噪失真比(Source to Distortion Ratio,SDR).3個(gè)值均是越高越好.其中,SDR計(jì)算分離聲音中存在多少總失真,SDR值越高表示語音分離系統(tǒng)整體上的失真越小,語音分離系統(tǒng)性能越好.SIR直接比較非目標(biāo)聲源噪音與目標(biāo)聲音的分離程度.SAR是指在語音分離過程中引入的人工誤差,SAR值越高,表明引入誤差對語音分離系統(tǒng)影響越小.
3.3 實(shí)驗(yàn)結(jié)果和分析
(1)基于DAF的語音分離算法的效果
表1為所提的基于DAF的語音分離算法在測試集(3000條語音)上的分離語音的平均SDR、SIR及SAR值,分別為11.60、22.58和12.38.從客觀評價(jià)指標(biāo)來看,本文所提出的語音分離算法在測試集上的有效性.

表1 測試集平均SDR、SIR、SAR值
圖4是本文所提語音分離算法在測試集(3000條語音)上的SDR值(每條混合語音分離出來的兩條語音的SDR值取平均)的分布.其中分離后語音的SDR值大于10的有75%,分離效果很好,語音質(zhì)量清晰可懂.SDR值在5到10范圍內(nèi)的有8%,分離效果較好,語音不夠清晰,但是可懂.SDR值在0到5范圍內(nèi)的有10%,分離效果一般,不明顯.SDR值<0的有7%,分離效果差,分離前與分離后沒有差別.經(jīng)觀察分析,這7%的混合語音,混合的兩個(gè)不同的說話人基本是同性別并且發(fā)音特性較為相似,導(dǎo)致分離算法在這部分?jǐn)?shù)據(jù)上處理效果不好.

圖4 測試集上SDR值分布
圖5分別是混合語音、分離語音1和2的DAF的可視圖.從圖中可以看出,DAF中有一條條的類似于頻譜圖中的“聲紋”的東西,并且不同的說話人對應(yīng)的“聲紋”的位置不同,說明深度網(wǎng)絡(luò)確實(shí)可以從語音的時(shí)域信號中學(xué)習(xí)到不同說話人的聲音特性并且能做出相應(yīng)的區(qū)分.

圖5 語音DAF的可視圖
圖6是所提語音分離算法的一個(gè)效果示例,每張小圖的上方是語音信號的原始波形,下方是其對應(yīng)的語譜圖.圖中左邊的兩張小圖分別是測試集中的兩個(gè)說話人的語音,以0.27 dB的信噪比經(jīng)過混合后得到中間的混合語音,右邊是分離出的兩個(gè)說話人語音,分離后的SDR值分別為14.20和12.39.無論是從客觀評價(jià)指標(biāo)SDR,還是從主觀地比較分離前后的語音原始波形和語譜圖,均能看出所提出語音分離算法的有效性.

圖6 一個(gè)語音分離效果示例
(2)不同聲學(xué)特征的效果對比
在這一部分實(shí)驗(yàn)中,為了探究本文使用的深層聲學(xué)特征的有效性,與語音分離任務(wù)中最常用的傳統(tǒng)聲學(xué)特征,經(jīng)過STFT變換的257維對數(shù)功率譜特征(Log Power Spectrum,LPS)做對比.同時(shí)為了驗(yàn)證DAF中使用的門限機(jī)制的有效性,與單獨(dú)使用ReLU、Sigmoid激活函數(shù)做對比,其他實(shí)驗(yàn)配置與3.1小節(jié)的配置相同.
表2為使用不同聲學(xué)特征的測試集上的平均SDR、SIR和SAR值.使用門限機(jī)制DAF、單獨(dú)使用ReLU評價(jià)指標(biāo)比使用LPS特征高,說明使用網(wǎng)絡(luò)去學(xué)習(xí)語音信號深層特征比使用傳統(tǒng)基于STFT的特征有效.而單獨(dú)使用Sigmoid的深層特征比使用LPS評價(jià)指標(biāo)低,說明了提取深層特征中選取恰當(dāng)激活函數(shù)的重要性,選取不當(dāng)會(huì)導(dǎo)致沒有傳統(tǒng)特征效果好.另外,使用DAF特征比使用單獨(dú)ReLU和單獨(dú)使用Sigmoid的評價(jià)指標(biāo)高,說明本文所提出的深度聲學(xué)特征中使用門限機(jī)制的有效性.

表2 不同聲學(xué)特征的測試集平均SDR、SIR、SAR值
(3)不同分離網(wǎng)絡(luò)的效果對比
在這一部分實(shí)驗(yàn)中,為了驗(yàn)證分離網(wǎng)絡(luò)中使用的BiLSTM的雙向的有效性,使用普通LSTM(非雙向)與之做對比.深度LSTM網(wǎng)絡(luò)有4層隱藏層,每層隱藏層的結(jié)點(diǎn)為1000.其他實(shí)驗(yàn)配置與3.1小節(jié)的配置相同.
表3為使用不同分離網(wǎng)絡(luò)(BiLSTM vs 普通LSTM)在測試集上的平均SDR、SIR和SAR值.使用BiLSTM比使用普通LSTM的分離網(wǎng)絡(luò)的SDR值高了5左右.因?yàn)槠胀↙STM在時(shí)序上處理序列沒有考慮未來的上下文信息,忽略了未來時(shí)刻的影響.而使用BiLSTM看到未來信息對當(dāng)前時(shí)刻的影響,更適用于本算法中的分離網(wǎng)絡(luò).

表3 不同分離網(wǎng)絡(luò)的測試集平均SDR、SIR、SAR值
(4)不同損失函數(shù)的效果對比
在本實(shí)驗(yàn)中采用了1/SI-SNR的損失函數(shù),其他最常用的損失函數(shù)是直接基于時(shí)域信號的最小均方差(Minimum Mean Squared Error,MMSE)損失函數(shù),直接優(yōu)化估計(jì)語音與干凈語音的時(shí)域信號差.該損失函數(shù)定義如下:

表4為使用不同損失函數(shù)(1/SI-SNRvs MMSE)在測試集上的平均SDR、SIR和SAR值.使用基于SI-SNR的損失函數(shù)比使用MMSE的SDR值高了4左右.因?yàn)镾I-SNR本身就是評價(jià)語音分離效果的重要指標(biāo),SI-SNR越高則語音質(zhì)量越高,相對于直接優(yōu)化語音原始波形的損失,使用基于SI-SNR的損失函數(shù)更適用于本算法的模型優(yōu)化.

表4 不同損失函數(shù)的測試集平均SDR、SIR、SAR值
(5)不同語音分離算法的效果對比
在這一部分實(shí)驗(yàn)中,為了探究所提算法在語音分離任務(wù)上的性能優(yōu)劣,使用目前四種具有代表性的語音分離算法與之做對比,分別為深度聚類(Deep Clustering,DC)語音分離算法[10],置換不變性(Permutation Invariant Training,PIT)語音分離算法[11]、時(shí)域語音分離算法Tasnet[8]和在音樂分離任務(wù)上表現(xiàn)很好的多任務(wù)Chimera模型[13].這四種方法中有基于時(shí)域的方法,也有基于頻域的方法.在測試集上的測試結(jié)果如表5所示.這可以發(fā)現(xiàn),本文所提出的算法的在語音分離任務(wù)上的有效性.

表5 不同語音分離算法的測試集平均SDR值
(6)時(shí)間延遲
在這部分實(shí)驗(yàn)中,為了探究基于傳統(tǒng)聲學(xué)特征的分離算法和本文所提算法的時(shí)間延遲,選用最常用的STFT特征與之做對比,實(shí)驗(yàn)結(jié)果如表6所示.算法延遲T等于建模所需的時(shí)域波形時(shí)間T1、特征提取所需的時(shí)間T2、分離網(wǎng)絡(luò)的時(shí)間T3和波形重建的時(shí)間T4的和.實(shí)驗(yàn)中保證分離網(wǎng)絡(luò)的結(jié)構(gòu)相同,即T3相同,T4與T2成正比.所以實(shí)際的時(shí)間延遲由T1和T2決定.實(shí)驗(yàn)所使用的GPU為GTX1070.在8 kHz的采樣率下,提取STFT特征時(shí),每幀的采樣點(diǎn)數(shù)最少為256,對應(yīng)時(shí)域波形為32 ms.本文對5 ms的時(shí)域波形進(jìn)行建模,通過模型對5 ms提取DAF特征的時(shí)間為0.002 ms.5.002 ms遠(yuǎn)小于32 ms,本文所提算法能極大地降低時(shí)間延遲.

表6 時(shí)間延遲實(shí)驗(yàn)(單位:ms)
4 總結(jié)與展望
本文提出了基于深層聲學(xué)特征的語音分離算法,該算法通過網(wǎng)絡(luò)模型來學(xué)習(xí)語音信號的更深層次的深層聲學(xué)特征,實(shí)現(xiàn)端到端的語音分離.在實(shí)驗(yàn)部分,選取了SDR、SIR和SAR作為客觀評價(jià)指標(biāo)在WSJ0數(shù)據(jù)集上進(jìn)行了一系列對比實(shí)驗(yàn).結(jié)果表明,本文提出的深層聲學(xué)特征在語音分離任務(wù)中的有效性,提出的算法提升了語音分離的性能.并且本文對5 ms的時(shí)域波形進(jìn)行建模,極大地降低了時(shí)間延遲.但是測試集中仍然有7%的數(shù)據(jù)分離效果不好,對于這部分發(fā)音特性較為相似的語音分離任務(wù),是今后的研究重點(diǎn).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評價(jià)·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
