大數據背景下數據分析類崗位的招聘特征挖掘
2019-10-19 07:29:58韋婷婷方宏宇宋世領駱威張建桃熊俊濤
現代計算機 2019年25期
關鍵詞:經驗
韋婷婷,方宏宇,宋世領,駱威,張建桃,熊俊濤
(華南農業大學數學與信息學院,廣州510642)
0 引言
隨著大數據應用于各行各業,數據分析相關崗位的需求也越來越大。根據數聯尋英發布的《大數據人才報告》顯示,國內近幾年大數據人才需求量巨大,眾多大型企業的招聘名單里半數以上崗位都從屬于數據分析類[1]。但是,目前學校這方面的人才培養,還滿足不了社會的需要。作為人才培養的搖籃,高校應根據大數據發展對人才的需求特征,進行有針對性的培養計劃。此外,目前針對數據分析崗位需求特征的研究比較少,僅有的少數研究對特征的分類則采用人工分類的方式,缺乏客觀性[2],也難以為求職者提供有效的相關信息。為此,本文從各大主流招聘網站上爬取招聘信息,通過相關的數據挖掘技術實現了以下特征分析:基于TF-IDF 算法的各福利待遇權重計算;基于Kmeans 算法的數據分析崗位需求特征聚類分析;基于統計學知識的工作經驗薪資統計圖、需求特征詞云圖、數據分析崗位全國熱力圖。本文的研究成果將有助于高校相關專業有針對性地培養適應市場需求的人才,并為求職者的能力構建及就業選擇提供參考依據。
1 數據獲取與研究方法
1.1 數據獲取
本文調研了國內多家招聘網站,綜合考慮了數據抓取難度、數據量以及網站權威性等方面,最終選擇拉勾網、智聯招聘、獵聘網、前程無憂四個招聘網站作為本實驗的數據源,部分示例數據如圖1 所示。

圖1 部分抓取數據
1.2 研究思路與方法
本文根據抓取數據各字段不同特點選取不同的分析方法。本文的研究思路主要分為以下六個步驟,如圖2 所示。第一,選取數據源并實現招聘數據的抓取。第二,從抓取的網絡文本集中選取結構化字段,直接進行詞頻統計。第三,實現以成段文本形式出現的福利待遇和職位描述字段的數據預處理。第四,統計福利待遇各關鍵詞詞頻并計算其TF-IDF 值。第五,統計職位描述各關鍵詞詞頻并實現職位描述字段各關鍵詞的K-means 聚類分析。第六,以可視化的方式展示上述各實驗結果并加以分析。

圖2 實驗流程設計
2 實驗設計與實現
2.1 數據預處理
本文從各個數據字段中選取城市、薪資、工作經驗、學歷要求、福利待遇、職位描述字段進行數據預處理[3],具體流程如圖3 所示。為防止專業短語在分詞中被分解,本文抽取了相關的大量關鍵詞短語添加到詞庫中,提高分析的準確性。
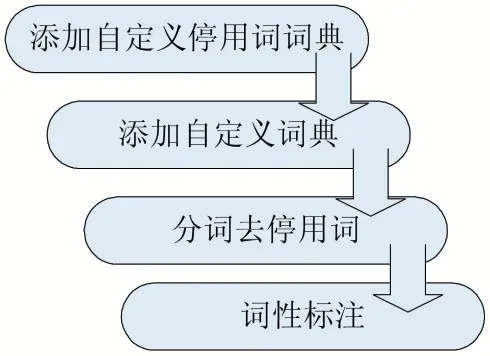
圖3 數據預處理步驟
2.2 福利待遇TF-IDF權重計算
本文選擇TF-IDF 算法計算某關鍵詞對一個文件系統的重要程度[4]。其中TF 值代表詞頻,通常會做歸一化處理。對于某一關鍵詞ti來說其TF 值計算如公式(1)所示。

在上式中ni,j是某關鍵字詞在文件集合中的出現頻次,而分母nk,j則是在文件集合中進行中文分詞后,所有詞出現次數的總和[5]。IDF 值代表反文檔頻率,其計算公式如公式(2)所示。

其中|D|表示文本系統中文件的總數;|{j:ti∈di}|代表包含關鍵詞的文件數目[6]。最后再計算該關鍵詞的TF-IDF 值:tfidfi,j=tfi,j×idfi。
本文將福利待遇字段內容預處理后作為詞頻統計的輸入,再根據詞頻統計結果計算各關鍵詞的TF-IDF值并選擇權重值前30 的關鍵詞分析。此處將每個網站福利待遇字段內容存為一個文件,四個網站的福利待遇文件構成文件系統。
2.3 職位描述K-means聚類
根據相似性原理科學分類[7],K-means 算法較人工分類更具客觀性。本文利用K-means 算法對數據分析崗位需求詞典進行聚類分析,由于在實現K-means 算法之前需要將文本進行向量化處理,選取了Word2Vec模型實現文本向量化,再根據生成各關鍵詞對應的向量值進行聚類。
K-means 算法以各關鍵詞對應向量間的距離作為判斷其相似性的標準,本文采用歐氏距離計算向量間的距離,其計算公式如公式(3)所示。
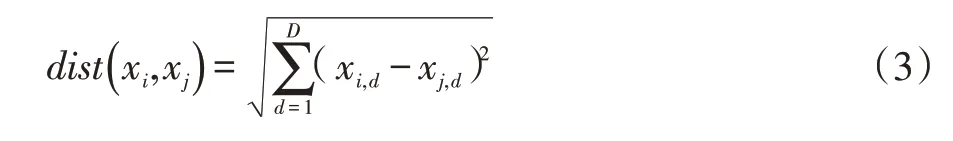
在K-means 的計算過程要通過多次迭代動態地確定分類中心Centerk,每次聚類結束后要調整所有數據對象的mean 值并確定下次分類的中心。定義第K 個類的類簇中心Centerk的方程如公式(4)所示。

其中Ck代表第k 個類簇,|Ck|代表第k 個類簇中所有數據對象的總數。K-means 算法停止迭代的方式有兩種,一種為設定迭代次數T,當達到設定迭代次數時停止迭代。另一種是采用誤差平方和準則函數,此數學模型如公式(5)所示。
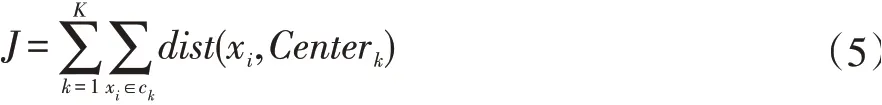
其中K 的值代表的是類簇個數,此方法首先要設定δ值再計算,直到ΔJ<δ時終止迭代,此時得到的聚類結果為最終結果。最后根據聚類分析結果將職位描述高頻關鍵詞進行分類。
3 實驗結果與分析
3.1 可視化結果分析
(1)數據分析崗位全國熱力圖
本文選取“城市”(工作地點)字段制作了數據分析崗位全國熱力圖,探究數據分析崗位需求量的地域因素以及其全國分布情況,如圖4 所示。

圖4 數據分析崗位全國熱力圖
熱力圖中顏色越深,點越密集代表數據分析崗位的需求量越大。從圖4 可以看出數據分析行業作為新興行業并沒有在全國廣泛分布,崗位主要分布在東南沿海地區其中上海、北京、深圳、廣州需求量最大,而杭州、南京、合肥、廈門、天津、福州等城市次之。內陸地區重慶、成都、石家莊等城市數據分析崗位需求人數較多,而我國東北地區和西北地區數據分析崗位需求量較少。
(2)工作經驗與薪資關系分析
本文將工作經驗字段與薪資字段結合分析二者之間關系,兩者之間的統計圖如下圖5 所示。由圖中可知數據分析崗位對應屆畢業生以及從業經驗1 年以下的應聘者需求量很少,而且工資水平主要在6 千元到1萬元之間。而需求的高峰主要集中在經驗1-3 年和經驗3-5 年的從業者,并且月薪水平在1 萬5 千元以上的占比很大。經驗1-3 年的人群中月薪在1 萬5 千元以上的占比接近一半,而在經驗3-5 年的人群中月薪在1 萬5 千元以上的占比已明顯超過一半,可見工作經驗在3-5 年的數據分析從業者最容易找到高薪工作。經驗5-10 年的需求量已明顯減少,但高薪資的占比依然很高。
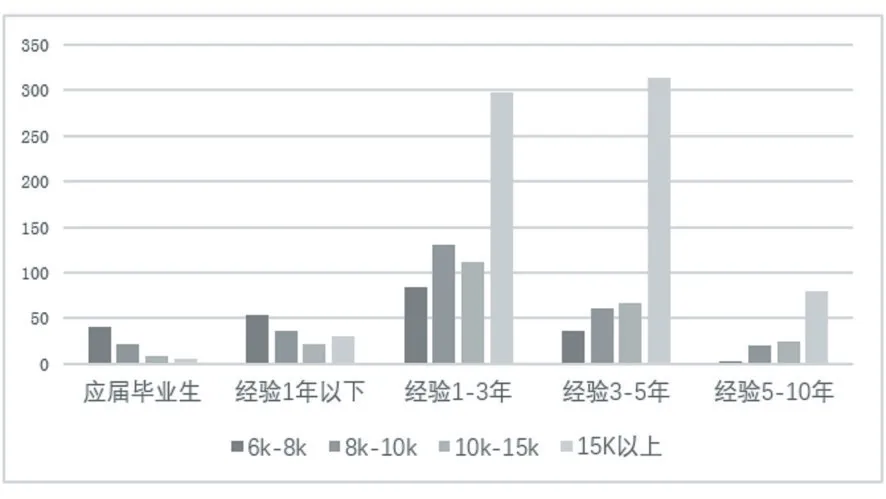
圖5 工作經驗薪資統計圖
3.2 福利待遇統計結果分析
計算福利待遇字段各關鍵詞的TF-IDF 值如表1所示,此處選取權重排行前三十的關鍵詞展示。

表1 福利待遇權重統計表
從總體上看,五險一金的權重遠遠高于其他福利待遇,帶薪年假和發展空間位于第二和第三,說明數據分析類崗位也都普遍提供這三種福利。通過進一步深入分析發現:人數規模較大的企業,通常還提供績效獎金、午餐補助等福利待遇;有些注重員工發展的企業則提供發展空間、崗位晉升、出國進修等待遇;另外還有一些企業提供了人文關懷待遇,例如定期體檢、彈性工作、節日福利和外出旅游等。綜合而言,上市公司、互聯網、高新技術企業所提供的福利待遇更為全面。
3.3 K-means聚類結果分析
(1)職位描述需求詞云圖
基于“職位描述”字段制作職位描述需求詞云圖,如圖6 所示。

圖6 職位描述需求詞云圖
(2)職位描述聚類分析結果
基于詞頻統計結果,將高頻關鍵詞作為K-means算法的輸入,探究數據分析崗位需求類型的劃分。本文通過經驗調參方式將K-means 聚類的類別數定為5類,并展示每類的前15 個關鍵詞,如圖7 所示。

圖7 聚類分析結果
綜合上述兩圖可知,第一類關鍵詞的主題可概括為業務能力,尤其是與需求分析以及數據分析相關的業務能力。其中分析報告,產品運營和需求分析權重較高。第二類主題較明確,可概括為專業及學歷方面的需求,其中本科學歷,統計學和數學專業權重較高。第三類主題為技能需求,其中SQL、Python、SAS、SPSS、Excel 權重較高。第四類主題為個人素質,其中學習能力,邏輯思維能力和溝通能力最為重要,此外還應具備團隊合作能力。第五類主題較模糊,主要與招聘崗位所在公司領域有關,其中互聯網公司數據分析人才需求量最大,在銀行以及通信行業也有一定的崗位需求。
3.4 總體結論
通過上述分析結果,總體結論如下:在工作地點上,北京、上海、廣州、深圳等一線城市或東南沿海發達城市的數據分析崗位需求量大,行業發展較成熟;在工作經驗方面,求職者經驗1 年以下從業者需求量很少,對工作1-5 年的從業者需求量較大薪資也較高,可以看出行業內急需經驗豐富的數據分析人才;福利待遇方面,基本與公司實力相匹配;求職者能力要求方面,主要包括業務能力、職業技能、個人素質三方面。此外,數據分析類崗位普遍要求數學和統計學相關專業。
4 結語
大數據如今備受企業關注,高校人才培養應該與時俱進,以市場需求為基準,設置合理的專業,注重產學研結合,加強學生的項目經歷,才能提升學生的就業競爭力。另外,相關專業的求職者也應進行一定的能力儲備,才能進入福利待遇較好的企業就業。
猜你喜歡
黨課參考(2023年5期)2023-03-18 01:17:10
黨課參考(2023年4期)2023-03-17 02:50:48
黨課參考(2021年20期)2021-11-04 09:39:46
小天使·四年級語數英綜合(2019年3期)2019-05-08 23:53:48
小哥白尼(軍事科學)(2019年6期)2019-03-14 05:49:56
黨課參考(2018年20期)2018-11-09 08:52:36
中國蜂業(2018年6期)2018-08-01 08:51:14
中國市場(2016年12期)2016-05-17 05:10:39
都市麗人(2015年4期)2015-03-20 13:33:22
中醫研究(2013年1期)2013-03-11 20:26:25
