基于深度學習的視覺問答系統
2019-10-21 08:16:45葛夢穎孫寶山
現代信息科技 2019年11期
葛夢穎 孫寶山


摘? 要:隨著互聯網的發展,人類可以獲得的信息量呈指數型增長,我們能夠從數據中獲得的知識也大大增多,之前被擱置的人工智能再一次煥發活力。隨著人工智能的不斷發展,近年來,產生了視覺問答(VQA)這一課題,并發展成為人工智能的一大熱門問題。視覺問答(VQA)系統需要將圖片和問題作為輸入,結合圖片及問題中的信息,產生一條人類語言作為輸出。視覺問答(VQA)的關鍵解決方案在于如何融合從輸入圖像和問題中提取的視覺和語言特征。本文圍繞視覺問答問題,從概念、模型等方面對近年來的研究進展進行綜述,同時探討現有工作存在的不足;最后對視覺問答未來的研究方向進行了展望。
關鍵詞:深度學習;人工智能;視覺問答;自然語言處理
Abstract:With the development of the internet,the amount of information available to human beings increases exponentially,and the amount of knowledge we can get from the data also increases greatly. Artificial intelligence,which had been put on hold,is radiate vitality. With the continuous development of artificial intelligence, in recent years,visual question answer (VQA) has emerged as a hot topic in the field of artificial intelligence. Visual question answer (VQA) system needs to take pictures and questions as input and combine these two parts of information to produce a human language as output. The key solution for VQA is how to fuse visual and linguistic features extracted from input images and questions. This paper focuses on the visual question and answer,summarizes the research progress in recent years from the aspects of concept and model,and discusses the existing deficiencies. Finally,the future research direction of VQA are prospected.
Keywords:deep learning;artificial intelligence;visual question answer;natural language processing
0? 引? 言
隨著互聯網科技的光速發展,網絡信息變得越來越包羅萬象、數量龐大。面對龐大的數據,如何篩選有用信息成為互聯網發展的一項重要任務。視覺問答(VQA)是最近幾年出現的一個新任務,視覺問答(VQA)系統能夠參考輸入的圖片內容回答用戶提出的問題,它運用了計算機視覺和自然語言處理兩個領域的知識。在視覺問答中,計算機視覺技術用來理解圖像,NLP技術用來理解問題,兩者必須結合起來才能有效地回答圖像情境中的問題。這相當具有挑戰性,因為傳統上這兩個領域是使用不同的方法和模型來解決各自任務的。給定一張圖片,如果想要機器以自然語言來回答關于這張圖片的某一個問題,那么,機器對圖片的內容、問題的含義和意圖以及相關的常識都需要有一定的理解。在實際應用中,針對信息中大量的圖片,采用視覺問答系統就可以使用機器來采集相應有用的信息,減少了人的工作量。
本文的貢獻有3個方面:
(1)闡述了視覺問答近年來的相關研究現狀;
(2)探討現有視覺問答工作的不足;
(3)提出視覺問答技術的未來需要解決的科學問題及應用方向。
1? 視覺問答研究現狀及方法
視覺問答(VQA)是計算機視覺、自然語言處理和人工智能交叉的新興交叉學科研究課題。給定一個開放式問題和一個參考圖像,視覺問答(VQA)的任務是預測與圖像一致的問題的答案。VQA需要對圖像有很深的理解,但是評估起來要容易得多。它也更加關注人工智能,即產生視覺問題答案所需的推理過程。
在本節中,我們回顧了近年來的VQA研究的發展情況。
(1)傳統分類方法。根據數據集中訓練集答案出現的次數設定一個閾值,保留出現過一定次數的答案,作為答案的候選選項形成一個答案候選集。然后把每一個候選答案設置為不同的標簽,將VQA問題作為一個分類問題來解決。該模型回答的答案大多都與圖像無關并且隨著數據集的不同會回答差別很大的答案。例如SWQA模型[1]:
(2)聯合嵌入。現有的方法主要是將VQA作為一個多標簽分類問題。最近的許多方法探索了在深層神經網絡中添加一個聯合嵌入來表示圖像和問題對。通常,圖像特征是在對象識別數據集預先訓練的卷積神經網絡(CNNs)的最后一個全連通層的輸出。文本問題分為序貫詞,它被輸入到一個遞歸神經網絡(RNN)中,以產生一個固定長度的特征向量作為問題表示。圖像和問題的特征是共同嵌入作為一個矢量來訓練多標簽分類器預測答案。如圖1所示。
聯合嵌入能夠將相對獨立的圖片特征和問題文本表示結合起來,更能夠根據圖片來回答問題。但聯合嵌入中大多都采用連接向量或矩陣相乘或點乘來直接連接圖片和問題表示,雖然這產生了一種聯合表示,但它可能沒有足夠的表達能力來充分捕捉兩種不同方式之間的復雜聯系。
(3)注意機制。與直接使用深度CNN全連接層的實體圖像相比,注意力模型已經被廣泛用于為VQA選擇最相關的圖像區域。早期的研究主要考慮了對圖像區域的問題引導關注。在后來的研究中,另外考慮了注意力的相反方向,即對問題詞的圖像引導注意力。Lu等人[2]引入了共同關注機制,該機制產生并使用對圖像區域和問題詞的關注。為了縮小圖像和問題特征的差距,Yu等人[3]利用注意力不僅提取空間信息,而且提取圖像的語言概念。Z.Yu等人[4]將注意機制與圖像與問題的新型多模態特征融合相結合。
例如AkiraFukui等人的基于MCB的改進算法[5],如圖2所示。
首先,使用基于ImageNet數據預訓練的152層ResNet[6]提取圖像特征[7]。輸入問題首先被標記為單詞,單詞是一個one-hot編碼,并通過一個學習的嵌入層傳遞。然后,再使用MCB將圖像特征與輸入問題表示進行合并。如圖2所示,最后,經過全連接以及softmax預測得到問題答案。
MCB模型結構就是對圖像進行關注的方法。基于MCB的聯合嵌入方法有效地減少了參數的數量,并且該方法將文本表示作為注意機制來影響圖像特征的權重,從而得到與問題相關的圖像特征。
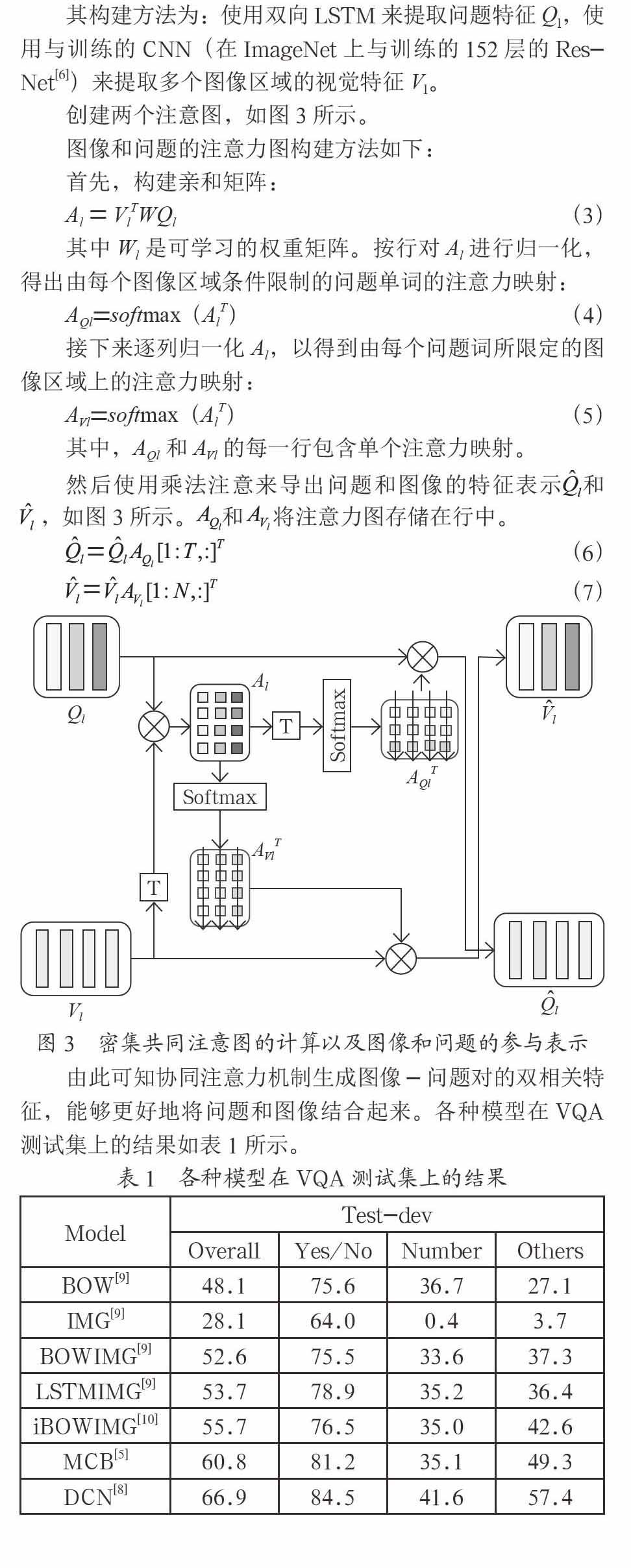
除了圖像上的關注之外,最近的很多文章也提出了協同關注的機制。協同注意也考慮對問題單詞的關注,但它是從整個圖像創建的。應用多個共同關注機制來關注圖像區域和文本中的問題。例如Duy-Kien等人的密集共同關注機制[8],如圖3所示。
這其中,使用了多個協同注意機制來捕獲問題和圖像中的細粒度信息。應用現有的區域方案算法生成目標區域,并根據問題選擇與問題最相關的區域來生成特征;應用雙向LSTM網絡來處理問題,根據圖像區域生成與圖像區域最相關的問題特征。所提出的機制可以處理任何圖像區域和任何問題單詞之間的每個交互,這可能使得能夠模擬正確回答問題所必需的未知的復雜圖像-問題關系。
其構建方法為:使用雙向LSTM來提取問題特征Ql,使用與訓練的CNN(在ImageNet上與訓練的152層的Res-Net[6])來提取多個圖像區域的視覺特征Vl。
創建兩個注意圖,如圖3所示。
2? 存在的問題
總結來說,雖然目前的VQA研究取得了一些成就,但是就目前的模型達到的效果來看,如表1的數據顯示,有以下幾個問題:
(1)整體準確率并不高,除了在回答單一答案的簡單問題(例如:Yes/No問題)上有較高的準確率外,其他方面模型(例如:Number問題)的準確率普遍偏低;
(2)當前的VQA模型結構還相對簡單,答案的內容和形式比較單一,對于開放式的問題和稍復雜的需要更多先驗知識進行簡單推理的問題還無法做出正確的回答;
(3)在許多模型中發現當對圖片背景的常識性推理錯誤、問題聚焦的物體太小、需要高層次的邏輯推理等問題出現時,模型往往無法給出正確的預測;
(4)許多用于VQA的模型往往直接使用ImageNet訓練好的CNN模型,但由于用戶的問題是開放式的,要正確回答開放式問題,這樣一來就顯得模型使用的特征過于單一,因此不能夠很好的回答問題;
(5)還有一個問題是深度學習的共有問題,即缺乏可解釋性,我們大多數都是根據實驗結果來推測模型有效,但是找不到具體有效的地方及缺乏能夠證明的原理。
3? 未來發展方向
作為需要視覺理解與推理能力的,融合計算機視覺以及自然語言處理的視覺問答VQA,它的進步在計算機視覺的發展和自然語言處理的能力提高的基礎上還有著更高的要求,即,對圖像的理解——在圖像處理的基礎能力,如識別,檢測等的基礎上還要學習知識與推理的能力。需要提高模型的精度,提高回答問題的粒度。然而,這條路還有很長的距離要走,一個能夠真正理解圖像、學習到知識和推理能力的VQA模型才是最終目標。
參考文獻:
[1] Malinowski M,Fritz M . A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input [J].OALib Journal,2014.
[2] Lu J,Yang J,Batra D,et al. Hierarchical Question-Image Co-Attention for Visual Question Answering [C].30th Conference on Neural Information Processing Systems(NIPS) in 2016,Barcelona,Spain,2016.
[3] Yu D,Fu J,Mei T,et al. Multi-level Attention Networks for Visual Question Answering [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2017.
[4] Yu Z,Yu J,Fan J,et al. Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering [J].2017 IEEE International Conference on Computer Vision,2017(1):1839-1848.
[5] Fukui A,Park D H,Yang D,et al. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding [J].ScienceOpen,2016:457-468.
[6] He K,Zhang X,Ren S,et al. Deep Residual Learning for Image Recognition [J].2016 IEEE Conference on Computer Vision and Pattern Recognition,2016(1):770-778.
[7] Deng J,Dong W,Socher R,et al. ImageNet:a Large-Scale Hierarchical Image Database [C]// 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009),20-25 June 2009,Miami,Florida,USA. IEEE,2009.
[8] Nguyen D K,Okatani T. Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering [J/OL].https://arxiv.org/pdf/1804.00775.pdf,2018.
[9] Antol S,Agrawal A,Lu J,et al. VQA:Visual Question Answering [J].International Journal of Computer Vision,2017,123(1):4-31.
[10] Zhou B,Tian Y,Sukhbaatar S,et al. Simple Baseline for Visual Question Answering [J].Computer Science,2015.
作者簡介:葛夢穎(1996.12-),女,漢族,安徽宿州人,碩士研究生,研究方向:自然語言處理、深度學習等;孫寶山(1978.10-),男,漢族,天津人,副教授,碩士生導師,工學博士,研究方向:機器學習、自然語言處理等。
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
