基于LSTMP語音識別方法的研究與改進
2019-10-21 08:16:45孫由玉孫寶山盧陽
現代信息科技 2019年11期
孫由玉 孫寶山 盧陽
摘? 要:當前LSTMP是基于LSTM增加了Projection層,并將這個層連接到LSTM的輸入,通過循環連接投影層,對高維度的信息進行降維,減小細胞單元的維度,從而減小相關參數矩陣的參數數目。但LSTMP網絡結構的缺點在于Projection層的輸出需要完成兩個功能,既需要充當歷史信息,又需要作為下一層的輸入。針對以上問題,筆者提出了一種Re-dimension的方法,讓網絡自己選擇一部分參數作為歷史信息,并獲得了一定程度的提升。采用該方法后,能提高語音識別率相對4-5%左右。
關鍵詞:長短時記憶LSTM;降維;語音識別
Abstract:Currently,LSTMP is based on LSTM,which adds a project layer and connects this layer to the input of LSTM. By circularly connecting the projection layer,it reduces the dimension of high-dimensional information,reduces the dimension of cell units,and thus reduces the number of parameters of the related parameter matrix. However,the disadvantage of LSTMP network structure is that the output of the Projection layer needs to complete two functions,which need to act as both historical information and input of the next layer. In view of the above problems,the author proposes a Re-dimension method,which allows the network to select some parameters as historical information,and has achieved a certain degree of improvement. With this method,the speech recognition rate can be improved by about 4-5%.
Keywords:LSTM for long-term and short-term memory;dimensionality reduction;speech recognition
0? 引? 言
隨著移動互聯網的興起,語音識別技術正在走進人們的生活,這給人們的工作、學習和生活提供了一種快捷識別的方式。近年來,基于深度全連接前饋神經網絡的聲學模型已被證明是語音識別的成功范例。最近,將循環神經網絡作為一種強大的模型進行了探索,循環神經網絡在不同的順序數據建模任務中取得了最先進的性能,例如:手寫字符識別,機器翻譯以及語音識別[1]。
基于長短期存儲器(Long Short-Term Memory,LSTM)的存儲器塊通過輸入門[2],輸出門、遺忘門和存儲器單元的集成來運行。通過該LSTM,循環神經網絡可以利用自學習機制用于遠程時間上下文,這有助于改善語音識別中的噪聲魯棒性[3],其中較長窗口內的一部分幀被噪聲掩蔽。已經實施LSTM網絡以在不同的語音識別任務中實現競爭性能,提出了具有各種架構的LSTM網絡的一些擴展以改善語音識別性能。LSTM循環投影作為統一框架引入,通過添加基于LSTM單元輸出的循環信息的前饋層并進一步將信息投影到輸出層。同時,通過LSTM單元細胞之后或之前安排全連接前饋神經網絡來調整LSTM結構。LSTM架構是一種非常特殊的循環神經網絡,用于對語音等順序數據進行建模。它最近被廣泛用于大規模聲學模型估計,并且比許多其他神經網絡表現更好。但是由于LSTM的運行速度很慢,所以有人提出了LSTMP網絡結構。
LSTMP是LSTM with recurrent projection layer的簡稱,是在原有LSTM基礎之上增加了一個Projection層,并將這個層連接到LSTM的輸入,Projection層的加入是為了減少計算量,它的作用和全連接層很像,就是對輸出向量做一下壓縮,從而能把高維度的信息降維,減小細胞單元的維度,以減小相關參數矩陣的參數數目。但是Projection層的輸出需要完成兩個功能,既需要充當歷史信息,又需要作為下一層的輸入。
針對這種情況,本文提出了一種Re-dimension的方法,讓網絡自己選擇一部分參數作為歷史信息,并獲得了一定程度的提升。通過采用改進的LSTMP方法,提高了LSTMP的性能,使語音識別率相對提高了4-5%左右。
1? LSTM網絡
LSTM(Long Short-Term Memory)長短期記憶網絡,是一種時間遞歸神經網絡(RNN)[4],主要是為了解決長序列訓練過程中的梯度消失和梯度爆炸問題。簡單來說,就是相比普通的RNN,LSTM能夠在更長的序列中有更好的表現。所有RNN都具有一種重復神經網絡模塊的鏈式的形式。在標準的RNN中,這個重復的模塊只有一個非常簡單的結構即一個tanh層[5]。如圖1所示。
LSTM與之不同的是其有四個神經網絡層,并且以一種特殊的方式進行交互。其關鍵就是細胞狀態,并且精心設計了“門”結構來控制細胞狀態。其內部主要有三個階段:第一階段是由忘記門來決定丟棄什么樣的信息;第二階段是選擇何種新信息進入細胞狀態,稱為選擇記憶階段;第三階段是決定輸出什么樣的值。四個神經網絡層,如圖2所示。
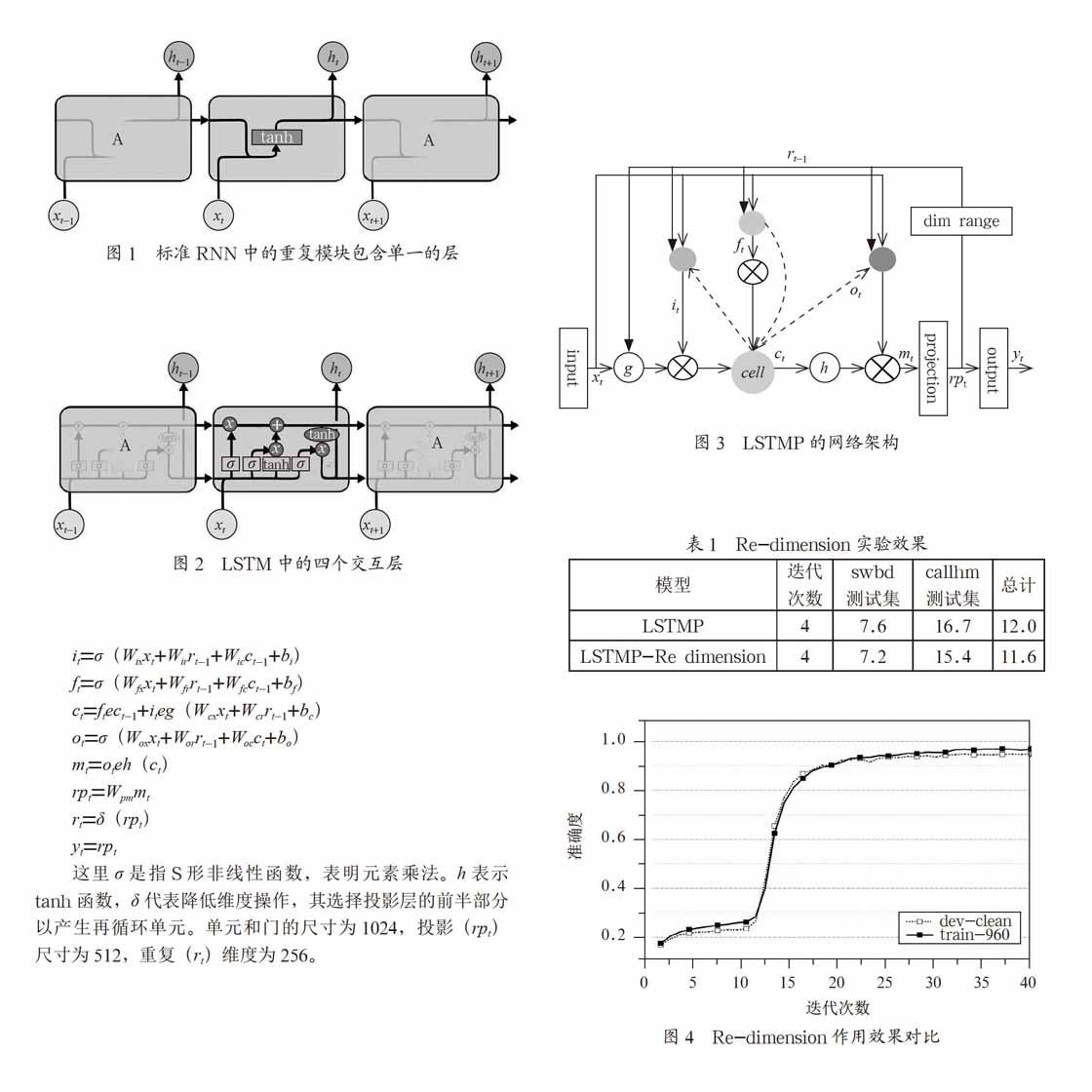
2? LSTMP網絡基本思想
2.1? LSTMP基本結構
LSTMP結構是在LSTM層之后具有一個單獨的線性投影層,并且該投影層產生循環連接。在實施中,使用暗視距節點選擇半隱藏單元來分配循環連接。LSTM中的Projection layer是為了減少計算量的,它的作用和全連接layer很像,就是對輸出向量做一下壓縮,從而能把高緯度的信息降維,減小cell unit的維度,從而減小相關參數矩陣的參數數目[6]。此時的網絡結構表述如下。
2.2? 改進的LSTMP方法
筆者在改進長短時記憶結構的基礎上,又進行了改進。由于LSTMP網絡結構在Projection層的輸出需要完成兩個功能,既需要充當歷史信息,又需要作為下一層的輸入,對整體架構的實現具有一定的復雜性[7]。因此,本文提出一種Re-dimension的方法,讓網絡
自己選擇一部分參數作為歷史信息。這個過程就是dim range部分,如圖3所示。
3? 實驗設計與結果分析
3.1? 實驗工具
本實驗使用Kaldi語音識別工具包進行實驗[8]。Kaldi是一個免費、開源的非常強大的語音識別工具庫,它提供基于有限狀態變換器(Finite-State Transducer,使用OpenFst)的語音識別系統,以及詳細的文件和腳本用于構建完整的識別系統。Kaldi包含的重要特性有:集成Finite State Transducer(編譯OpenFst工具箱,作為一個庫);擴展的線性代數支持;可擴展設計;開源的license;完整的方法和周密的測試。
3.2? 實驗設計
在本實驗中,此網絡的輸入層大小為39,前后隱藏層各有128個塊,輸出層大小為40(39個音素加空白)。邏輯sigmoid函數在[0,1]范圍內。輸入層完全連接到隱藏層,隱藏層完全連接到自身和輸出層。權重總數為183,080。
此網絡的訓練是通過梯度下降和每個訓練樣本后的權重更新完成的。在所有情況下,學習率為10-4,動量為0.9,權重在[-0.1,0.1]范圍內隨機初始化,并且在訓練期間,將標準差為0.6的高斯噪聲添加到輸入中以改善泛化。對于前綴搜索解碼,使用了0.9999的激活閾值。性能測量為目標標簽序列與系統給出的輸出標簽序列之間的標準化編輯距離(標簽錯誤率LER)。
3.3? 結果分析
本實驗在LSTMP的基礎上增加Re-dimension方法后,讓網絡自己選擇一部分參數作為歷史信息。經過反復的訓練,從表1中可以看出,網絡能更好地學習到歷史信息,同時也獲得一定程度的性能提升,如圖4所示。
4? 結? 論
本文通過深入研究LSTMP結構,提出一種Re-dimension方法,讓網絡自己選擇一部分參數作為歷史信息,采用基于改進的LSTMP方法進行實驗,使語音識別率相對提高了4-5%左右。可見該方法可以使網絡獲得一定的性能提升。
參考文獻:
[1] 戴禮榮,張仕良,黃智穎.基于深度學習的語音識別技術現狀與展望 [J].數據采集與處理,2017,32(2):221-231.
[2] 陳曉宇.基于數據驅動的渦扇發動機故障預測研究 [D].阜新:遼寧工程技術大學,2018.
[3] 李杰.基于深度學習的語音識別聲學模型建模方法研究 [D].北京:中國科學院大學,2016.
[4] 胡鑫,程玉柱,吳祎,等.長短期記憶網絡的林火圖像分割方法 [J].中國農機化學報,2019,40(1):103-107.
[5] 沈旭東.基于深度學習的時間序列算法綜述 [J].信息技術與信息化,2019(1):71-76.
[6] Peddinti V,Wang Y,Povey D,et al. Low Latency Acoustic Modeling Using Temporal Convolution and LSTMs [J].IEEE Signal Processing Letters,2017(99):1.
[7] Chan W,Jaitly N,Le Q,et al. Listen,attend and spell:A neural network for large vocabulary conversational speech recognition [C]// IEEE International Conference on Acoustics,Speech and Signal Processing. IEEE,2016:4960-4964.
[8] R. Prabhavalkar,T. N. Sainath,et al. Minimum Word Error Rate Training for Attention-based Sequence-to-sequence Models [J].IEEE Conference on Acoustics,Speech,and Signal Processing(ICASSP),2018.
作者簡介:孫由玉(1995-),女,漢族,山東濱州人,碩士研究生,研究方向:自然語言處理;孫寶山(1978-),男,漢族,天津人,副教授,工學博士,研究方向:自然語言處理;盧陽(1992-),女,漢族,天津人,碩士研究生,研究方向:自然語言處理。
