CNN 實現(xiàn)的運動想象腦電分類及人-機器人交互*
2019-10-24 02:09:30程時偉周桃春唐智川孫凌云朱安杰
軟件學報 2019年10期
程時偉,周桃春,唐智川,范 菁,孫凌云,朱安杰
1(浙江工業(yè)大學 計算機科學與技術(shù)學院,浙江 杭州 310023)
2(浙江工業(yè)大學 設計藝術(shù)學院,浙江 杭州 310023)
3(計算機輔助設計與圖形學國家重點實驗室(浙江大學),浙江 杭州 310058)
腦機接口(brain computer interface,簡稱 BCI)通過采集與提取大腦產(chǎn)生的腦電圖信號(electroencephalogram,簡稱EEG)來識別人的意圖,基于EEG 信號完成大腦與外部設備的信息傳遞與控制任務,進而恢復甚至增強人的身體運動和感知、認知能力[1].近年來,BCI 的相關(guān)研究得到了快速發(fā)展,但是,由于EEG 信號具有非平穩(wěn)、非線性、低信噪比等特點[2],在預處理、特征提取、多模式分類等方面尚有諸多難題有待解決,從而導致可實際應用的BCI 系統(tǒng)較少.
通常,EEG 數(shù)據(jù)的處理和分析方法主要包括3 個步驟:(1)對EEG 數(shù)據(jù)進行預處理;(2)對預處理后的EEG數(shù)據(jù)進行特征提取;(3)最后對提取的特征向量進行分類.這類方法的主要局限在于,需要依靠研究人員的先驗知識進行復雜的數(shù)據(jù)預處理和特征提取,但在預處理過程中容易剔除可能隱含著有用特征的數(shù)據(jù),而在特征提取過程中又容易忽略不同通道腦電信號間的關(guān)聯(lián)特性[2],這些都會降低分類結(jié)果的準確性和可靠性.而卷積神經(jīng)網(wǎng)絡(convolutional neural network,簡稱CNN)融合了無監(jiān)督學習和有監(jiān)督學習的優(yōu)點,對高維特征向量具有較強的分類能力,能從原始數(shù)據(jù)中學習到有利于分類的特征,減少了人為因素對特征選擇造成的主觀性和不完備性.
因此,為了針對EEG 信號進行便捷、精確的特征提取和分類,本文設計運動想象實驗,在大幅減少腦電電極數(shù)量(傳統(tǒng)方法需要64 個或更多電極,本文只采用14 個電極)、同時增加運動想象分類任務(傳統(tǒng)方法多數(shù)只支持2 或3 分類,本文支持左手、右手、腳和靜息態(tài)的4 分類)的情況下,提取被試用戶的EEG 數(shù)據(jù),并采用CNN方法進行數(shù)據(jù)的特征學習與分類,結(jié)果表明,本文方法比已有運動想象分類算法具有更高的識別率.進而,基于本文方法設計與開發(fā)了一個基于BCI 的人-機器人交互系統(tǒng),實驗結(jié)果表明,該原型系統(tǒng)能快速且準確地判斷出用戶的運動想象指令,控制機器人完成相應的動作,進一步驗證了本文方法的實用性.
1 相關(guān)工作
近年來,國內(nèi)外學者提出的EEG 信號特征提取方法主要包括3 類:(1)基于時域分析的方法,如采用均值、方差、概率密度函數(shù)等[1];(2)基于頻域分析的方法,如Pfurtscheller[3,4]提出的基于mu 節(jié)律的頻域分析方法并應用在運動想象任務中、Zhou 等人[4]將小波包分解(wavelet packet decomposition,簡稱WPT)和獨立成分分析(independent component analysis,簡稱ICA)應用在運動想象數(shù)據(jù)特征提取中;(3)基于空域分析的方法,如Samek等人[5]提出將共空間模式(common spatial pattern,簡稱CSP)應用在腦機接口中.另一方面,也可采用機器學習的方法,如孫會文等人[6]使用支持向量機(support vector machine,簡稱SVM)方法對經(jīng)過希爾伯特黃變換(Hilbert-Huang transform,簡稱HHT)的EEG 數(shù)據(jù)進行分類;張毅等人[7]使用自回歸模型(autoregressive model,簡稱AR)對特征提取后的EEG 信號進行分類;劉伯強等人[8]使用神經(jīng)網(wǎng)絡的反向傳播(back propagation,簡稱BP)算法進行EEG 數(shù)據(jù)分類.
CNN 是一種帶有卷積結(jié)構(gòu)的深度神經(jīng)網(wǎng)絡,卷積結(jié)構(gòu)可以利用空間結(jié)構(gòu)關(guān)系,減少需要學習的參數(shù)數(shù)量,從而提高反向傳播算法的訓練效率,不僅可以防止過擬合,還能降低神經(jīng)網(wǎng)絡的復雜度[9].LeCun 等人[10]采用神經(jīng)網(wǎng)絡誤差反向傳播算法進行手寫數(shù)字的識別,在網(wǎng)絡結(jié)構(gòu)設計中加入下采樣與權(quán)值共享,大幅減少了神經(jīng)網(wǎng)絡的參數(shù)量.此外,為了盡量保證數(shù)據(jù)的平移、尺度、畸變不變性,LeCun 等人[11]設計了局部感受野和共享權(quán)重,提出用于字符識別的卷積神經(jīng)網(wǎng)絡LeNet-5,在銀行的手寫數(shù)字識別系統(tǒng)中取得了較好的結(jié)果.近年來,CNN 也被應用于EEG 信號的特征提取和分析.例如,Hubert 等人[12]基于CNN 對腦電事件相關(guān)電位(event-related potential,簡稱ERP)中的 P300 成分進行分類識別,實現(xiàn)字符拼寫,并在 BCI 競賽的公共數(shù)據(jù)集(http://www.bbci.de/competition/iii/)上進行實驗,結(jié)果表明,其識別率最高可以達到95.5%;蔡邦宇[13]使用CNN 模型對視覺誘發(fā)電位(visual evoked potential,簡稱VEP)進行時域和空域特征分析,結(jié)果表明,平均受試者工作特征(receiver operating characteristic,簡稱ROC)曲線面積比SVM 方法提高了4.4%;唐智川等人[14]基于CNN 對左手和腳的運動想象腦電信號進行分類識別,平均識別率為88.75%±3.42%,并將其應用到基于BCI 的外骨骼應用原型系統(tǒng)中;王衛(wèi)星等人[15]基于CNN 進行左、右手二分類動作和單手的3 分類動作識別,識別精度比原有方法分別提高了4%和8%.
上述相關(guān)研究驗證了CNN 方法在腦電信號處理中應用的可行性,但鮮有研究能在有效減少腦電電極數(shù)目的同時,還能對4 個及以上的運動想象分類問題進行精確的識別,并最終設計與開發(fā)出相應的BCI 原型應用系統(tǒng),實現(xiàn)精確的人-機器人實時交互.
2 基于CNN 的腦電信號分類方法
2.1 腦電信號采集
腦電信號的采集采用10-20 國際標準導聯(lián)放置[1],將鼻根和枕外粗隆相連接,在冠狀位把鼻根、外耳孔和枕狀粗隆相連接,中點為頭頂(即Cz).通過Cz 將兩個連線各分為2 個10%和4 個20%的距離.本文采用Emotiv System 公司(http://www.pstnet.com/eprime.cfm)的Emotiv EPOC 腦電儀,其包含14 個電極(如圖1 所示),采樣頻率為128Hz.
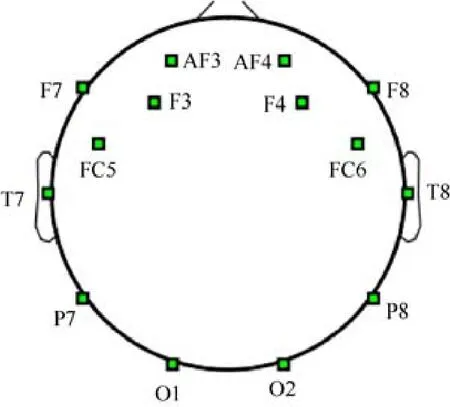
Fig.1 Electrodes configuration of Emotiv EPOC圖1 Emotiv EPOC 腦電儀的電極位置分布
2.2 腦電實驗范式
在實驗過程中采用如圖2 所示的實驗范式[16].
本文招募了7 名被試用戶(5 男2 女,年齡在24 歲~27 歲之間)進行實驗,實驗對象均是右利手,并且均是第1次參加本文中的腦電實驗.每個被試用戶需要完成560 次基于提示的實驗,每次實驗持續(xù)9s 時間,前2s 屏幕顯示“rest”字,用戶休息放松,之后在屏幕中央出現(xiàn)一個“十”字,提示被試用戶實驗即將開始;從4s~8s,屏幕上的“十”字變?yōu)殡S機產(chǎn)生的想象左手、想象右手、想象腳和靜息狀態(tài)的提示.為了保持提示呈現(xiàn)后同步獲得相應的腦電信號,實驗范式程序采用Eprime 實現(xiàn),在每次實驗開始時,向腦電儀發(fā)送一個marker 標記信號,并在實驗結(jié)束后進行離線數(shù)據(jù)分析時,根據(jù)marker 來分割相關(guān)腦電數(shù)據(jù).此外,為了防止被試用戶產(chǎn)生疲勞,影響運動想象腦電實驗的效果,被試用戶每進行20 次實驗后就休息3 分鐘.此外,為了防止被試用戶在運動想象過程中產(chǎn)生實際的肢體動作,影響腦電數(shù)據(jù)質(zhì)量,在正式實驗之前對被試用戶進行了運動想象訓練,并在正式實驗過程中剔除了產(chǎn)生實際肢體動作的實驗數(shù)據(jù).
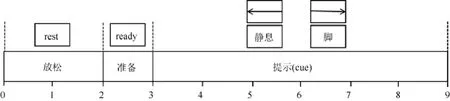
Fig.2 MI experimental paradigm圖2 運動想象實驗范式
2.3 卷積神經(jīng)網(wǎng)絡結(jié)構(gòu)
本文設計的用于運動想象腦電數(shù)據(jù)處理的卷積神經(jīng)網(wǎng)絡如圖3 所示,包括1 個輸入層(input 層)、3 個卷積層(C1、C2、C3 層)、3 個池化層(S1、S2、S3 層)和1 個輸出層(output 層).
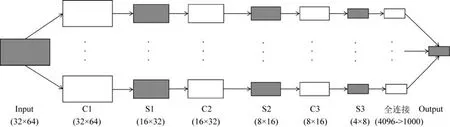
Fig.3 CNN structure for MI EEG data analysis圖3 用于運動想象腦電數(shù)據(jù)分析的卷積神經(jīng)網(wǎng)絡結(jié)構(gòu)
2.3.1 卷積層構(gòu)造
卷積層主要進行特征提取,采用線性濾波器和非線性激活函數(shù).具體地,對輸入數(shù)據(jù)應用多個濾波器,并用一個輸入?yún)?shù)進行多個類型的特征提取.基于上一層的輸入,采用以下公式來提取下一層的特征:

在本文中,輸入數(shù)據(jù)為F3、F4、FC5 和FC6 通道的腦電數(shù)據(jù),數(shù)據(jù)維度為4×512.通常,CNN 模型處理腦電數(shù)據(jù)的輸入數(shù)據(jù)格式為通道數(shù)×時間點,本文初期研究通過上述數(shù)據(jù)格式進行神經(jīng)網(wǎng)絡構(gòu)建與優(yōu)化,但效果不佳,見表1,平均分類識別率只能達到50%左右.為此,本文作了進一步改進,考慮到卷積神經(jīng)網(wǎng)絡對圖像數(shù)據(jù)分析具有較好的識別效果,并在處理塊狀數(shù)據(jù)時具有更大優(yōu)勢,所以本文對運動想象數(shù)據(jù)也采用類似圖像的分塊處理.表1 所示,對不同的數(shù)據(jù)輸入維度進行實驗,結(jié)果表明,在4 種分類狀態(tài)下,32×64 的分塊輸入方式的平均分類識別率最高.因此,本文將原輸入數(shù)據(jù)的維度設置為32×64.
進一步地,建立起本文的卷積層結(jié)構(gòu):C1 層,輸入3 個通道,輸入維度為32×64,輸出32 個通道;C2 層,輸入32個通道,輸入維度為16×32,輸出64 個通道;C3 層,輸入64 個通道,輸入維度為8×16,輸出128 個通道.在卷積層中,步長為1,為了保證數(shù)據(jù)是完整、有效的信息,使用寬卷積,所以,卷積層的輸出維度不變,并使用dropout 防止數(shù)據(jù)的過擬合,同時采用ReLu 代替?zhèn)鹘y(tǒng)神經(jīng)網(wǎng)絡中的tanh 和sigmod 函數(shù),加快網(wǎng)絡訓練速度.
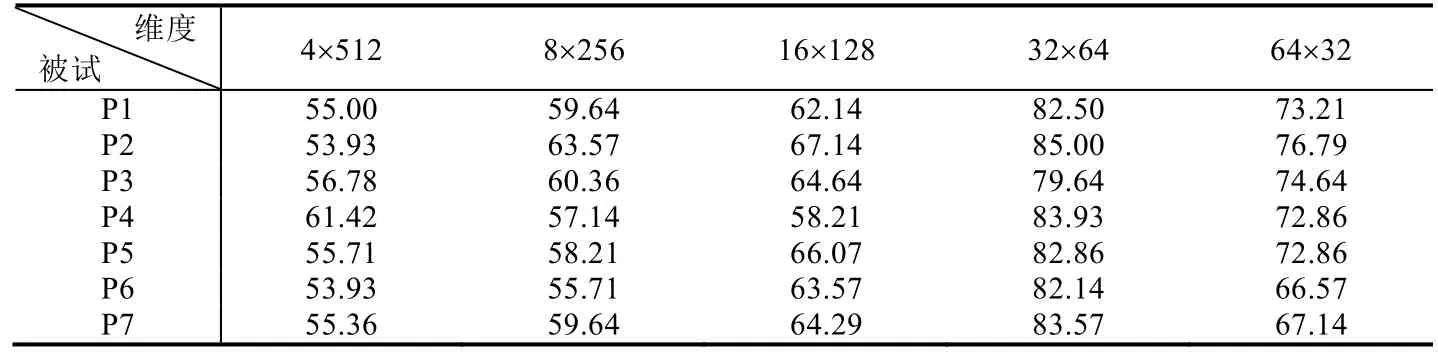
Table 1 Average accuracy of classification under different input dimensions (%)表1 不同腦電輸入維度的平均分類識別率對比(%)
2.3.2 池化層構(gòu)造
池化層(pooling layer)也稱為子采樣層(subsample layer),用于縮減數(shù)據(jù)的規(guī)模,同時保持特征的局部不變性.實現(xiàn)子采樣的方法有很多種,最常見的是最大值合并、平均值合并及隨機合并.本文使用平均值合并進行子采樣,公式如下:

在本文中,池化層的輸入是同一網(wǎng)絡層中卷積層的輸出:S1 層,輸入維度為32×64,輸出維度為16×32;S2 層,輸入維度為16×32,輸出維度為8×16;S3 層,輸入維度為8×16,輸出維度為4×8.在上述池化層中,步長為2,子采樣為2×2,所以,輸出的兩個維度同時減半.為了保證數(shù)據(jù)的完整、有效性,使用寬卷積,同時采用ReLu加快網(wǎng)絡訓練速度.
2.3.3 全連接層構(gòu)造
將經(jīng)過多層卷積和池化的運動想象EEG 二維數(shù)據(jù)的特征圖拼接為一維特征作為全連接網(wǎng)絡的輸入.全連接層l的輸出可通過對輸入加權(quán)求和并通過激活函數(shù)的響應得到,公式如下:

3 實驗結(jié)果與分析
3.1 CNN參數(shù)設置
參數(shù)設置對CNN 模型的效果影響很大.下面對本文CNN 模型的參數(shù)設置進行詳細闡述.
(1)批大小(batchsize):在深度學習中,一般采用隨機梯度下降(stochastic gradient descent,簡稱SGD),即每次在訓練集中獲取batchsize 個樣本進行訓練.當數(shù)據(jù)集和計算量不大時,batchsize 采用全數(shù)據(jù)集,其有兩個優(yōu)點:第一,由全數(shù)據(jù)集確定的方向能夠更好地代表樣本總體,從而更準確地朝向極值所在的方向;第二,全數(shù)據(jù)集可以使用彈性傳播(resilient propagation,簡稱Rprop)算法[17],基于梯度符號并且有針對性的單獨更新各權(quán)值,解決了多批次模型訓練中,各批次訓練權(quán)重的梯度值差別較大,選取一個全局的學習速率困難的問題.但是,對于較大的數(shù)據(jù)集合,上述優(yōu)點卻變成了缺點:第一,隨著數(shù)據(jù)集和計算量的增大以及內(nèi)存的限制,一次載入所有數(shù)據(jù)的可行性較低;第二,如果以Rprop 方式迭代,由于各個batch 之間的采樣差異性,各批次梯度修正值將相互抵消,無法實現(xiàn)修正效果,所以需要采用均方根傳播(root mean square propagation,簡稱RMSProp)算法[18].考慮內(nèi)存的利用率和訓練完一次全數(shù)據(jù)集的迭代次數(shù)[19],結(jié)合實驗經(jīng)驗,本文的batch size 取值為8,即每次取8 個樣本進行訓練.
(2)學習速率:運用梯度下降算法進行優(yōu)化,在權(quán)重更新時,學習速率就是梯度項前的系數(shù).根據(jù)Bengio[20]對梯度訓練的總結(jié),如果學習速率太小,則收斂過慢;如果學習速率太大,則會導致代價函數(shù)震蕩.本文基于Bengio提出的方法,對學習速率賦一個缺省值,取0.01,結(jié)果發(fā)現(xiàn),代價函數(shù)產(chǎn)生震蕩,所以對學習速率進行調(diào)整,設為0.001,最終提高了識別率.
(3)權(quán)重和偏置:根據(jù)LeCun 等人[21]提出的權(quán)重和偏置參數(shù)調(diào)試建議,初始化時使用截斷正態(tài)分布,加入輕微噪聲,打破對稱性,防止零梯度問題,本文中設置正態(tài)分布標準差為0.1.
(4)dropout:這是指在深度學習網(wǎng)絡的訓練過程中,對于神經(jīng)網(wǎng)絡單元,按照一定概率將其暫時從網(wǎng)絡中丟棄.Hintion 提出dropout 方法[22],在訓練模型時隨機地讓某些隱含節(jié)點的權(quán)重不工作,這些節(jié)點暫時可以認為不是網(wǎng)絡結(jié)構(gòu)的一部分,但是它們的權(quán)重得以保留下來(暫時不更新),下次樣本輸入時可能重新工作.由于本文的數(shù)據(jù)樣本相對較少,為了防止在訓練模型時出現(xiàn)過擬合,采用dropout 方法.本文在訓練時卷積層和池化層的dropout 采用0.8,全連接層的dropout 采用0.5;在測試時,dropout 都為1,更新所有權(quán)重.實驗發(fā)現(xiàn),在同樣迭代次數(shù)下,采用dropout 測試樣本的錯誤率明顯低于沒采用dropout 的測試樣本.
3.2 實驗結(jié)果與分析
實驗采集了7 個被試用戶(用P1~P7 表示)的腦電數(shù)據(jù),每個被試采集560 次數(shù)據(jù),為了得到可靠穩(wěn)定的模型,通過交叉驗證(cross-validation)方法分離出50%的訓練樣本和50%的測試樣本.權(quán)重使用截斷正態(tài)分布,標準差為0.1,學習率為0.001.訓練時卷積層和池化層的dropout 采用0.8,全連接層的dropout 采用0.5,在測試時,dropout都為1,腦電數(shù)據(jù)的輸入層維度為32×64.
分類問題需要對分類結(jié)果進行評價,評價指標一般包括識別率(accuracy)、精確率(precision)、召回率(recall rate)和F-score,通過這些評價指標對分類模型的效果進行評估[14].4 個評價指標的定義分別如下.
(1)識別率:對于總的測試數(shù)據(jù)集,通過訓練數(shù)據(jù)訓練的最優(yōu)分類器對測試數(shù)據(jù)正確分類的樣本數(shù)與總樣本數(shù)之比:
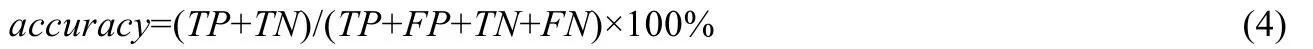
其中,TP為真陽性,TN為真陰性,FP為假陽性,FN為假陰性.
(2)精確率:測試數(shù)據(jù)集中分類為真實正例樣本數(shù)與分類為正例樣本數(shù)之比:

(3)召回率:分類為真實正例的樣本數(shù)與所有真實正例的樣本數(shù)之比:

(4)F-score:這是識別率的延伸,結(jié)合了精確率和召回率,具體計算如下:
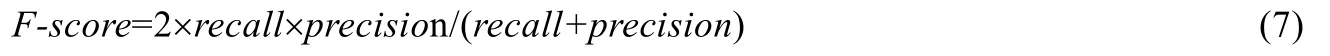
本文從網(wǎng)絡層數(shù)和時間序列兩個方面對實驗結(jié)果進行分析,具體闡述如下.
(1)基于網(wǎng)絡結(jié)構(gòu)層數(shù)的結(jié)果分析
針對每個被試用戶,分別構(gòu)建不同層數(shù)的卷積神經(jīng)網(wǎng)絡,從而找到最好分類效果的卷積神經(jīng)網(wǎng)絡結(jié)構(gòu).受篇幅限制,這里沒有列出所有不同層數(shù)的分類結(jié)果.表2 是在相同條件下(4 種分類),分別構(gòu)建2~5 層卷積和池化結(jié)構(gòu)的訓練測試結(jié)果.可見,3 層的實驗結(jié)果比其他層數(shù)的平均分類識別率更高,因此本文采用3 層卷積和池化網(wǎng)絡結(jié)構(gòu).
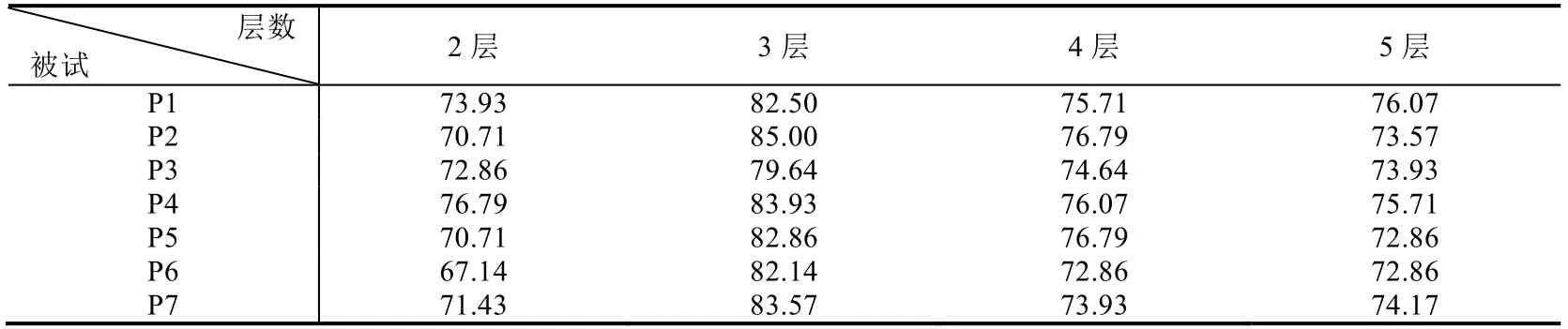
Table 2 Average accuracy of classification with different convolution and pooling layers (%)表2 不同卷積層和池化層CNN 模型的平均分類識別率對比(%)
(2)基于時間序列的結(jié)果分析
將運動想象的腦電實驗數(shù)據(jù)按時間段劃分,每段時長2s,作為輸入數(shù)據(jù).圖4 顯示了在0~6s 的3 個時間段中,被試用戶的平均分類識別率.
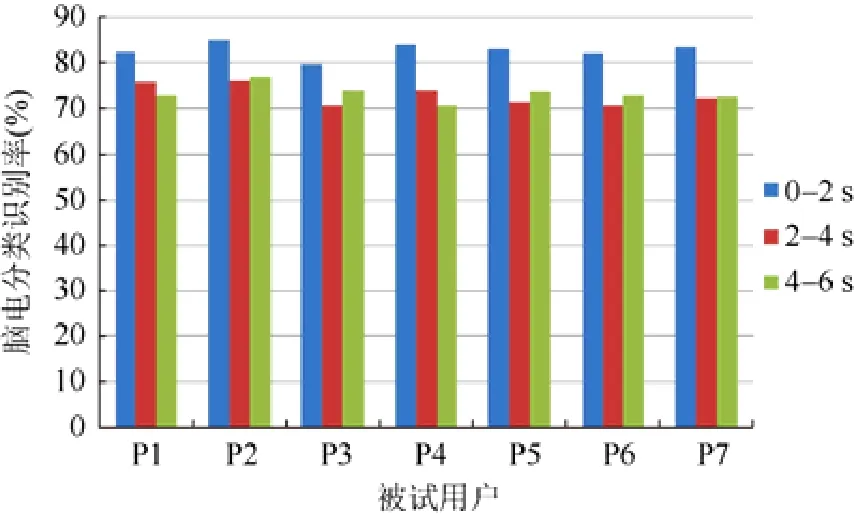
Fig.4 Classification results analysis based on temporal sequence圖4 基于時間序列的分類結(jié)果分析
從圖4 可以看出,前2s(第0~第2s)腦電數(shù)據(jù)的平均分類識別率達到最高,而最后4s(第2s~第6s)腦電的數(shù)據(jù)平均分類識別率較低,說明在實驗開始時,被試用戶專注于運動想象實驗,但是隨著時間的推移,被試用戶精神集中度降低,影響了腦電數(shù)據(jù)的質(zhì)量,最終導致識別率降低.
因此,根據(jù)上述分析結(jié)果,選擇原始輸入數(shù)據(jù)維度為32×64,卷積和池化3 層網(wǎng)絡,選擇運動想象開始后0~2s的腦電數(shù)據(jù)進行分類預測.相關(guān)分類結(jié)果見表3,對角線單元格內(nèi)數(shù)值表示所有被試想象左手、右手、腳運動和靜息狀態(tài)時,其EEG 信號被正確識別為相應類別的平均識別率(precision)和標準差.另外,非對角線單元格內(nèi)的數(shù)值表示EEG 信號被錯誤識別為其他類別的平均識別率和標準差.

Table 3 Confusion matrix of EEG classification results表3 腦電分類平均預測結(jié)果的混淆矩陣
此外,為了進一步驗證本文方法的先進性,使用相同的實驗數(shù)據(jù),采用4 種已有方法(SAE、CSP+SVM、softmax 和WPT+SVM)與本文方法進行對比.這4 種方法都需要先對腦電數(shù)據(jù)進行預處理,包括去除眼電偽跡、濾波等,再經(jīng)過特征提取,最后用分類器進行分類.與已有方法相比,本文基于CNN 方法的平均分類識別率最高,結(jié)果見表4.

Table 4 Average accuracy of classification with different approaches表4 各種分類方法的平均識別率對比
4 應用實例
4.1 原型系統(tǒng)框架設計
本文基于運動想象的人-機器人交互應用場景如圖5 所示,被試用戶要求坐在屏幕前,左、右手和身體保持自然的放松姿勢,并且佩戴好Emotiv 腦電儀,固定好電極位置(參考電極為P3 和P4,采樣頻率為128Hz),確保能夠正常采集腦電信號.本文使用NAO(https://www.softbankrobotics.com/emea/en/robots/nao)仿人機器人,放在被試用戶正前方位置.
每個被試用戶需要完成560 次基于方向箭頭和文字等視覺提示(cue)的實驗,其中,想象左手運動、右手運動、腳運動和靜息狀態(tài)(不作任何運動想象)各140 次,每次實驗之間有3s 的時間間隔,每完成20 次實驗之后休息5 分鐘,防止被試用戶過于疲勞影響實驗結(jié)果.如圖6 所示,在單次運動想象結(jié)束后,采用本文前述訓練出來的分類模型進行實時分類,NAO 機器人根據(jù)分類結(jié)果產(chǎn)生相應的動作.例如,用戶進行左手運動想象,如果分類算法正確識別為左手運動,NAO 機器人則抬起左手.類似地,右手的運動想象對應于NAO 機器人抬起右手;腳的運動想象對應于NAO 機器人向前走動;靜息態(tài)對應于NAO 機器人保持靜止,且播放語音“你現(xiàn)在很安靜”.此外,為了防止被試用戶在運動想象過程中產(chǎn)生實際的肢體動作,影響腦電數(shù)據(jù)質(zhì)量,與第2.2 節(jié)的處理方法一樣,對被試用戶進行了訓練,并剔除了無效數(shù)據(jù).

Fig.6 The mapping bettwen MI classification results and robot actions圖6 運動想象分類結(jié)果與機器人交互動作的映射關(guān)系
該系統(tǒng)的框架如圖7 所示,被試用戶根據(jù)屏幕上隨機出現(xiàn)的向左、向右箭頭,以及“腳”和“靜息”的文字開始進行運動想象.當被試用戶開始進行運動想象時,Emotiv 開始采集腦電數(shù)據(jù),通過TCP/IP 協(xié)議將獲取的腦電數(shù)據(jù)發(fā)送給系統(tǒng)主機進行預處理,然后利用前文訓練的分類模型對腦電數(shù)據(jù)進行分類,再將分類結(jié)果轉(zhuǎn)換為控制命令,并通過TCP/IP 發(fā)送給NAO 機器人,驅(qū)動機器人的電機和揚聲器等組件完成相應的操作.同時,在屏幕上給出分類結(jié)果的視覺反饋(如“向左”這樣的文字).
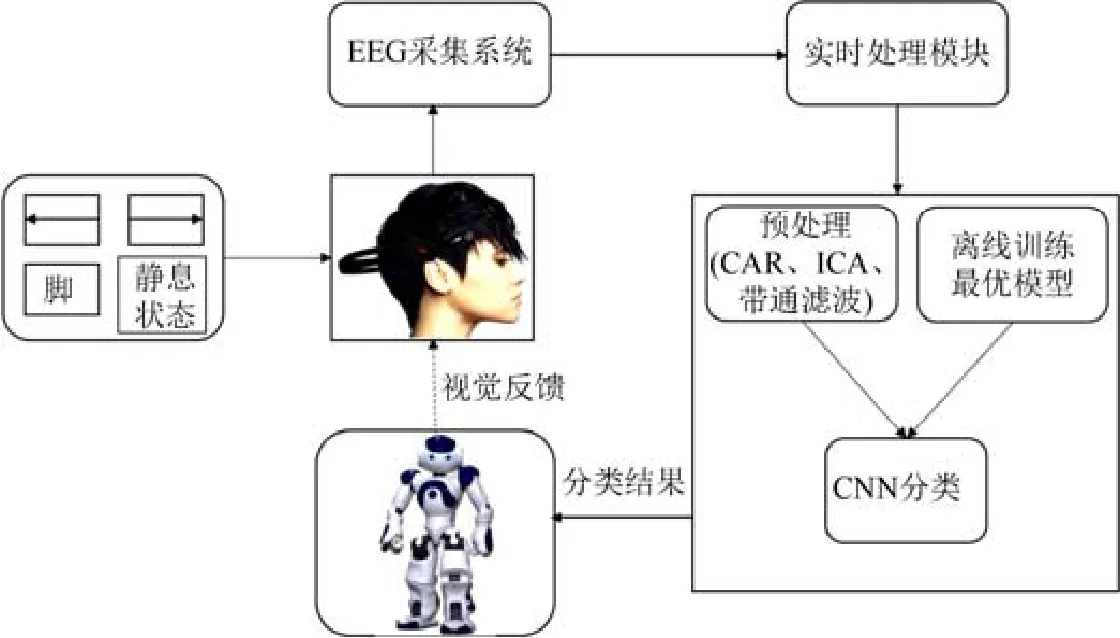
Fig.7 Framework of the prototype system圖7 原型系統(tǒng)框架
4.2 原型系統(tǒng)開發(fā)與實驗
4.2.1 系統(tǒng)功能
原型系統(tǒng)主要包括腦電數(shù)據(jù)采集、腦電數(shù)據(jù)分析和機器人控制這3 個主要功能模塊,采用Python 編程語言實現(xiàn).(1)腦電數(shù)據(jù)采集模塊:主要采集和分發(fā)系統(tǒng)所需的腦電數(shù)據(jù),基于 socket 實現(xiàn),開發(fā)工具包采用pycharm;(2)數(shù)據(jù)分析模塊:主要進行原始數(shù)據(jù)的預處理、數(shù)據(jù)訓練以及分類模型的求解和存儲,其中的數(shù)值分析采用Python 的科學計算工具包numpy,并采用了keras 和Tensorflow 框架進行分類算法的開發(fā);(3)機器人控制模塊:主要接收數(shù)據(jù)分析模塊輸出的分類結(jié)果,并對NAO 機器人進行相應的控制,具體開發(fā)采用NAO 的pynaoqi-python SDK 開發(fā)包.此外,系統(tǒng)圖形用戶界面的開發(fā)基于Python GUI 的Tkiner 編程工具,它可以良好地運行在絕大多數(shù)平臺上,實現(xiàn)跨平臺的效果.
4.2.2 實驗結(jié)果分析
在用戶與機器人的交互過程中,針對4 類運動想象的精確率、召回率和F-score 這3 個評估指標進行分析和對比,見表5.采用分類方法×運動想象類別的方差分析(ANOVA)評估兩者對分類結(jié)果的影響.置信水平為95%.ANOVA 結(jié)果顯示,分類方法對分類結(jié)果具有顯著影響(p<0.05),而運動想象的類別則對分類結(jié)果不具有顯著影響(p>0.05).進一步地,采用Tukey Post Hoc 檢驗對分類方法進行兩兩比較,本文基于CNN 模型分類方法的3 個指標(精確率、召回率和F-score)與其他4 種方法相比均具有顯著差異性(p<0.05),且本文3 個指標的值更大,因此,本文方法具有更好的指標性能,進一步驗證了其在實際交互應用中的有效性和先進性.
4.2.3 討 論
如表6 所示,進一步將本文方法與已有文獻的方法進行了對比(由于已有文獻沒有進行與機器人交互等應用的在線測試,故此處只取本文第3 節(jié)的結(jié)果進行對比).分析發(fā)現(xiàn),參考文獻[18]采用了64 通道、1 000Hz 采樣頻率的Active Two 腦電儀采集腦電信號,并使用CNN 對想象左手和想象腳進行分類,最終所有被試用戶的平均識別率(accuracy)達到89.51%±2.95%;參考文獻[24]采用60 通道、采樣頻率為250Hz 的Neuroscan 腦電儀,使用CNN 方法對4 類運動想象信號進行分類,最終分類識別率達到85.04%±4.26%.雖然這兩項研究比本文的平均識別率稍高,但腦電信號采集通道數(shù)目是本文的4 倍左右(本文通道數(shù)只有14 通道),而本文實驗操作方便且設備價格便宜.此外,參考文獻[18]的分類數(shù)目只有2 類,而本文有4 類.類似地,參考文獻[23]采用了64 通道、160Hz采樣頻率的Biosemi 腦電儀,使用CNN 對9 類運動想象進行分類,但效果不佳,平均分類識別率只有45%.
基于上述分析,從肢體障礙患者使用的便攜性、運動想象分類數(shù)目、分類識別率、設備價格和實驗過程復雜度等方面進行了綜合考慮,分析結(jié)果表明,本文方法具有更好的實用性和可行性.
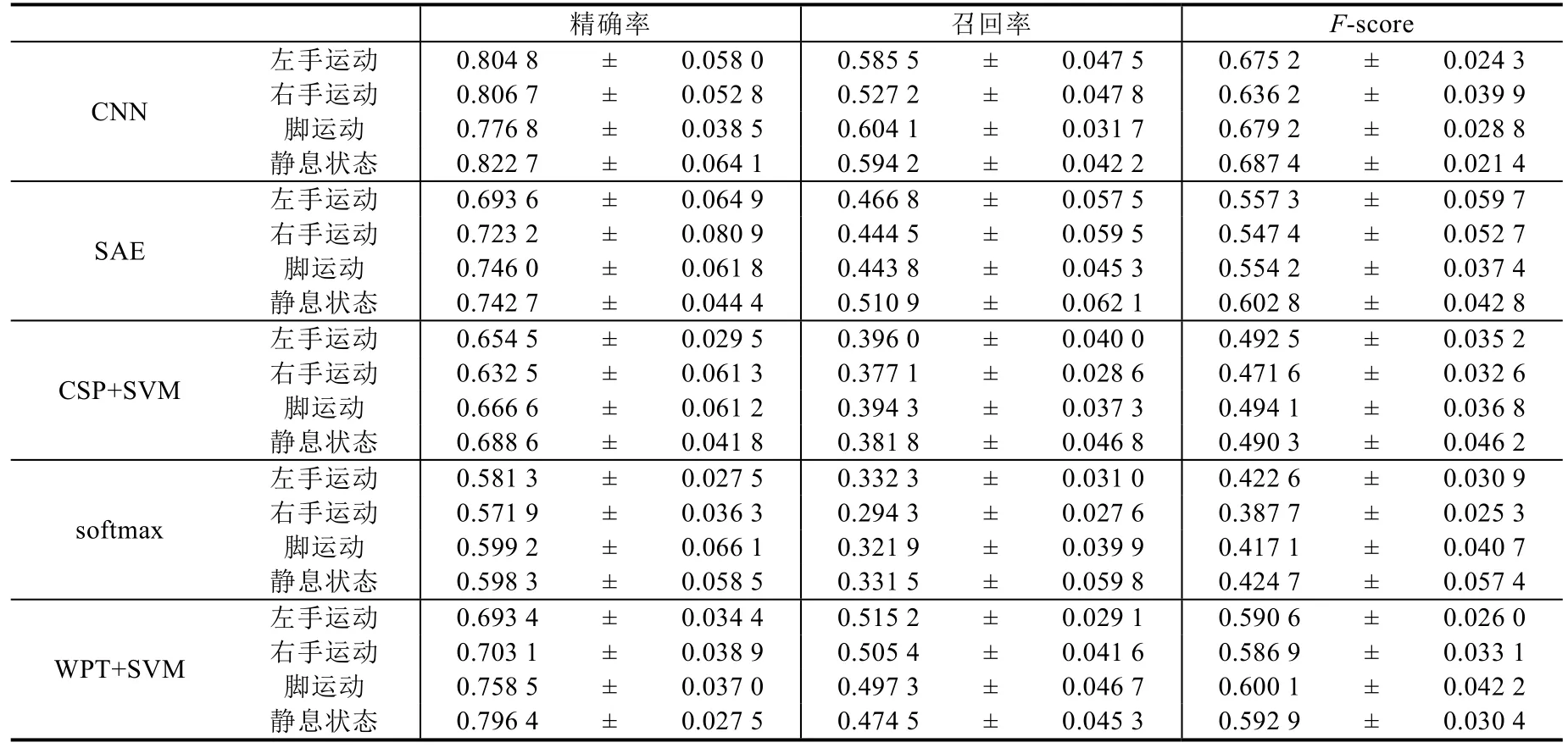
Table 5 Precision,recall rate and F-score of MI classification with different approaches across all subjects表5 所有被試用戶在不同方法下運動想象分類的精確率、召回率和F-score
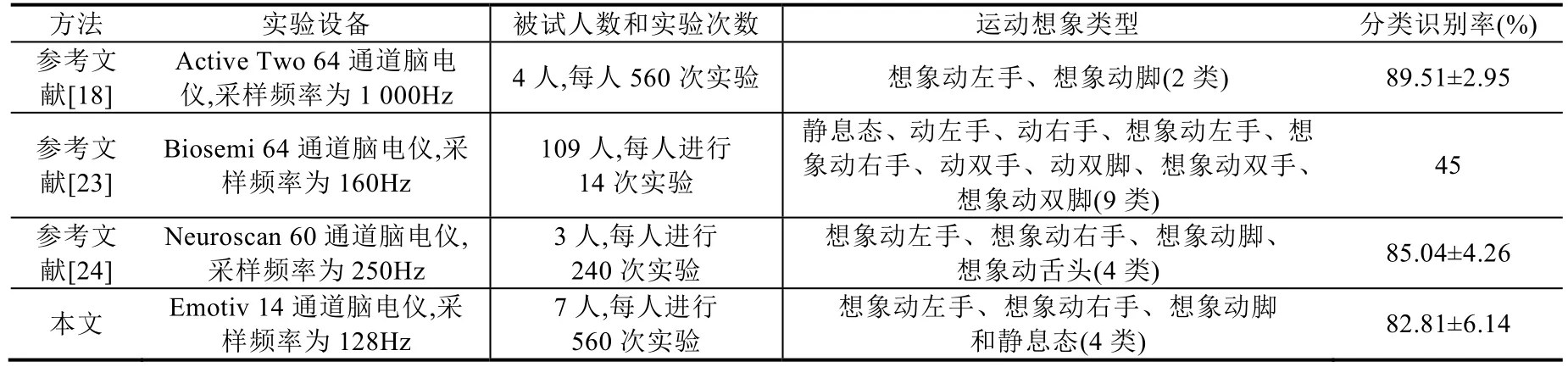
Table 6 Comparison between proposed approach of this paper and others表6 本文方法與已有文獻的對比
進一步地,與其他分類方法(SAE、CSP+SVM、softmax 和WPT+SVM)相比較,本文采用的CNN 方法雖然在識別率上具有一定的優(yōu)勢,但也存在一些不足:(1)由于CNN 網(wǎng)絡的復雜性以及需要調(diào)用較多的參數(shù),需要使用較大的數(shù)據(jù)集進行訓練,否則容易導致過擬合,因此本文對每個被試用戶進行了560 次實驗,而這容易導致被試用戶產(chǎn)生疲勞,從而會影響實驗效果.(2)計算成本較高,因為模型訓練需要耗費較多時間、調(diào)參過程較復雜等.所以,本文方法在實際應用中還應該進一步提高模型訓練效率,簡化計算過程,改善用戶體驗感受.
5 結(jié)論與展望
本文將CNN 用于運動想象腦電信號的分類識別,相關(guān)實驗結(jié)果表明了本文方法能夠從原始腦電數(shù)據(jù)中自動學習特征,并能對4 種運動想象狀態(tài)進行較精確的分類,平均分類識別率達到了82.81%.
此外,本文也存在一定的局限性,下一步將從以下幾個方面繼續(xù)開展研究:(1)完善腦電實驗范式,采集更復雜的腦電數(shù)據(jù),將CNN 模型用于識別更復雜的腦電信號;(2)進一步優(yōu)化CNN 的網(wǎng)絡結(jié)構(gòu),調(diào)整合適參數(shù),并結(jié)合其他深度學習方法,如深度置信網(wǎng)絡(deep belief network,簡稱DBN)來進一步提高分類識別率;(3)面對實際應用中日益涌現(xiàn)的海量、復雜腦電數(shù)據(jù),考慮使用spark 架構(gòu)實現(xiàn)分布式處理,進一步提高腦機交互應用的實時性.
猜你喜歡
科普童話·學霸日記(2021年4期)2021-09-05 04:28:51
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小學生作文(低年級適用)(2019年12期)2020-01-18 07:50:36
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中國化妝品(2018年6期)2018-07-09 03:12:42
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
