基于改進C4.5算法的高校財務預警系統設計
2019-11-11 07:36:12趙男男
韶關學院學報 2019年9期
關鍵詞:財務
趙男男
(廣東海洋大學 寸金學院,廣東 湛江524094)
當前一段時間,很多發達國家將高校管理作為提升教育技術發展的一個主要任務,紛紛建立屬于自己的高校財務管理體系,并總結了大量的經驗[1].然而在國內,仍有很多高校財務管理系統在進行財務預警系統設計時,面對著海量的財務數據,無法分析數據屬性特征和數據間存在的因果關系,使得財務預警出現了較大的誤差,進而影響了高校財務狀況管理的穩定性[2].在這種情況下,如何設計出精良的高校財務預警系統成為了國內外教育管理領域需要解決的重點課題,也引起了諸多相關學者的關注[3].
現階段,在高校財務預警系統設計中經常用的算法有很多,并且也積累了一定的研究經驗.文獻[4]面對海量財務數據信息,將并行機制引入到決策算法中,并優化改機制,利用改進后的決策并行機制設計財務預警系統.該算法預警的響應性較高,但是存在數據屬性冗余較多的問題.文獻[5]總結高校財務狀況識別的最優體系,建立不同類型的預警模型,進而完成對高校預警系統的設計.該算法預警魯棒性較好,但是有效的進行財務數據屬性分類,存在預警誤差大的問題.文獻[6]將神經網絡引入到高校財務預警中,利用神經網絡的構造能力和搜索能力完成對預警系統的設計.實驗表明,該算法具有一定的預警精準性,但是存在預警過程較繁瑣,耗時長的問題.
面對上述問題,筆者提出一種基于改進C4.5算法的高校財務預警系統.仿真證明,該算法具有較高的預警精度,在高校管理中的應用價值較高.
1 高校財務數據預處理
高校財務預警系統實現過程中,對財務預警是最終的目的,而實現這個目的的關鍵就是決策算法,財務數據是最根本.為了更好的提升數據的采集質量,為預警系統設計打下扎實的基礎,首先就要組建一個財務數據的倉庫.財務倉庫作為預警系統的核心,其創建根本是要嚴格掌握不同類型財務數據的特點和具有代表性的變化規律,使其可以為各種財務報表分析和配備相匹配的數據狀態,更是做出合理判斷的一個重要憑證[7].
圖1列舉了財務數據倉庫體系的流程圖,組建數據倉庫需要數據挖掘庫和其各種應用工具、數據整理、初始數據源.
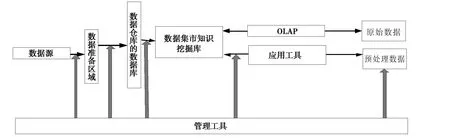
圖1 財務數據倉庫體系
傳統財務預警系統設計之初,財務倉庫實現的過程中,不同類型部門、各種需要財務支出的項目要建立系統的賬本,致使了很多財務數據的混淆,不同類型的數據雜合在一起,包含了大量的噪聲和殘缺數據,數據內容也雜亂無章表現出冗余,沒有規律性.這些數據是不能用于對財務狀況的分析.此外,很多財務信息呈現的狀態也較為模糊,稀疏混亂,難以用于財務狀況判別[8].且初始數據中含有的部分數據是與財務狀況決斷毫不相關的,需要消除.綜上所述可以說明,對數據的預處理是財務預警的關鍵環節.
數據采集的過程就是對多種類型數據源的整理,數據預處理則是將不同類型數據如異構、噪聲、缺失、非結構和半結構化數據的統一整理,以便在數據較為復雜多變的情況下,對財務數據進行更好的整合.其中,在數據采集過程中,會將NoSQL作為中間的模型.在高校財務系統中,存儲了多種海量的復雜財務數據,而NoSQL的最大優勢是:第一,可以應對海量數據的多種存儲方式;第二,對各種類型的數據源進行分批的采集、交換和存儲;第三,可以有效的保持數據結構在數據存儲中和倉庫中形式的一致性.圖2為NoSQL中間件模型體系結構圖.
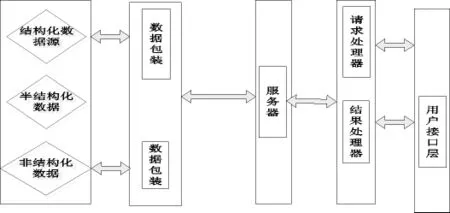
圖2 基于NoSQL中間件模型體系結構
數據采集的主要步驟為:(1)數據初始源:數據融合是需要將不同類型的初始數據融合在一起,其過程是需要清洗不同結構的數據,消除冗余,以最大程度保證數據的可利用性和可靠性;(2)數據融合:將能夠表現相同狀態的數據融合在一起,建立數據一致性制度,并使其變成具有最大保留價值的信息集合;(3)歸檔存儲:對將生命周期較為薄弱的數據進行變換歸納,長時間保留在學校財務數據的中心,為數據的檢索和檢測提供依據.
2 高校財務預警系統的優化設計
2.1 高校財務數據樣本的分類
C4.5算法的優勢在于可以以最快速度對海量數據進行分類,并可以發現數據的分布特性和其價值信息,并且可以將迭代的過程規范在最小的范圍內,能幫預警決策作出更有效的分析.C4.5算法核心原理是,將整個數據訓練集定義根節點,進行有序的區分,并分為很多個不同類型的小的集合,定義為根節點中的最外層的子節點,由此在深化,衍生為一個決策樹,最大的特點就是較為迅速,精度較為優良.但是在高校預警系統設計的應用過程中,會面對海量的數據項屬性,也就是說會形成一個很龐大的決策樹,但海量預警數據中存在很多不均勻數據,缺失數據,當面臨這些數據時,其分類的準確率會迅速下降,在反復排序和掃描后會延長系統的運行時間[9].在實現高校財務數據樣本分類的過程中,假設,獨立的某個數據屬性會有多個取值,并且沒有概化操作標識,并且容易被任意屬性代替其深度概念,則應從信息列表中,將其剔除.如果,高校財務狀態信息表內的基礎建設投資支付情況、校辦資產風險、基礎建設資金投入狀態及其高校自身籌集經費的年遞增趨勢等部分數據有很多取值,并且不能在其取值區域內搜索到概化操作標識的屬性,那么就應該及時剔除.如果,樣本整體的數量是S,屬性的取值范圍為R,概化標識符的屬性由d′de,則利用刪除財務數據樣本中的冗余屬性:

在式(1)中,e′j代表財務情況的描述,e″et代表數據屬性種類.
制定選取數據屬性的標準,利用信息增益最大為選取制度,選取數據屬性后將其作為訓練閾值,進行訓練集的重新分類遞歸調用,將全部的例子歸納在相同的屬性類別中,對組建的樹進行修整.實現過程為:若?′se是屬性冗余度的最大值,在樣本整體數量S內含有數量為m的類型樣本ci,那么將si定義為樣本類型的數量,采用式(2)得出整體信息熵:

在式(2)中,任何一個獨立樣本pi歸類ci的百分比,可以用來預測.
之所以要進行職業體育新模式教學項目的設計,旨在做好學生職業勞動和社會發展相適應的身心素養的培養,保證職業體能的開展、職業競爭能力的培養以及職業保健能力的訓練等都是有針對性展開的。
假設,一個x屬性有數量為v的取值{X1,X2,…,XV},并且,Sj中有多個S內的樣本,這部分樣本具有的明顯特征是,在x內的值是Xj(i=1,2,…,v),則將該屬性定義為財務數據屬性分了的閾值,可利用式(3)計算得出:

在式(3)中,子集Sj中包含Cj的樣本數為S1j.
2.2 高校財務預警系統的優化設計
將熵的物理概念定義為衡量熱力系統的沒有規則的程度.將熵的含義繁衍到信息論中,依據熵的不穩定性,對C4.5算法進行改進,定義數據測試屬性閾值,對全部數據屬性的實體進行歸類,衍生出一個決策樹對數據屬性測試程度進行預測,也由此實現對所有財務數據狀況實際空間的歸類.在衍生決策樹的過程中,數據分類的標準是要選定一個屬性,并且要促使子節點中的數據類別具有統一性.如果任意個獨立節點內的數據具有類值均分度,則該節點為熵.
將全部數據信息剔除冗余后的信息分布程度定義為“信息熵”,即:

在式(4)中,隨機樣本是Ci的百分比為(Pi).
信息增益是定義獨立數據屬性在進行分類中包含的信息量的大小,該值影響了決策樹衍生時所選取的節點,其值也大則對分類的作用就越大,相反其作用就小[10].獨立的屬性會通過計算信息熵來選取樣本分類屬性,利用式(5)計算A分枝獲取的信息增益:

在式(5)中,給定樣本S理想的信息熵為I(S1,S2,…Sm).
在衍生決策樹的時候,重要的一個環節就是對節點的歸類,將衡量節點的優劣標準就是信息增益率,在上述形成的信息熵和其增益的公式中,信息熵和增益的百分比就是信息增益率.而相互對比的是以單位為屬性上的信息量.
信息增益就是在數據集以最小子集為單位時,變量值包含的誤差.為了降低這種誤差,利用式(6)計算出信息增益率:

利用式(7)得到增益率:

當決策樹被衍生后,修減樹是最關鍵的環節,以提升在對數據屬性分類時期樹的效果,剪枝時候,會剔除較多的子樹,其目的就是得到更優質的性能,并且能夠降低決策樹的繁瑣性.利用子樹替代法進行改進C4.5算法的剪枝,其制度就是比較子樹預測誤差和任意子葉預測的誤差,假設,葉子的錯誤率低于子樹,則用葉子代替樹.在衍生決策樹后,需歷經決策樹,搜索出很多路徑,并且不同的路徑要對應不同的特征,將整個大樹的表達規則生成后,發現最具有價值的子集,將規則集存儲在設定的文件中,由此實現高校財務預警,即:

3 仿真實驗證明
實驗是以高校財務預警為結果,建立財務預警分析流程,見圖3.
3.1 評價指標的設計
為了證明提出的改進C4.5算法的高校財務預警系統設計方法有效性,需要進行一次實驗,在Mat-lab7.1環境下搭建高校財務預警系統設計實驗仿真平臺,實驗數據來源于某高校2015-2016年財務狀況.采用其中百 分之四十的數據做為訓練數據,將剩余的百分之六十的數據定為測試數據,將預警精度做為主要評價指標來定義改進C4.5算法進行高校財務預警的整體有效性,將傳統的C4.5算法做為對比算法,采用預警擬合優度做為客觀評價指標來定義不同算法進行高校財務預警系統設計的整體優越性.假設,由?″代表訓練集整體樣本數量,f′eg代表部分子集,則利用式(9)計算出預警誤差:
圖3 預警系統流程圖

在式(9)中,s′sui代表單葉的誤差比,h′drf代表信息雜亂度,則 e′def值越小,算法的預警精度就越好.
如果,s′sf代表樣本分類最大表現度,代表樣本分類屬性數量,則利用式(10)計算出預警擬合優度:

在式(10),E′代表信息增益最大值,e′def代表變量取值,則 K′S值越高,算法的預測精度就越高.
3.2 本文算法的預警誤差測試
利用本文算法進行高校財務預警系統設計,測試本文算法進行高校財務預警誤差,測試結果見圖4.本文算法進行高校財務預警系統設計預警的誤差始終控制在較低的范圍內,可以滿足高校財務預警對其精度的需求(見圖4).
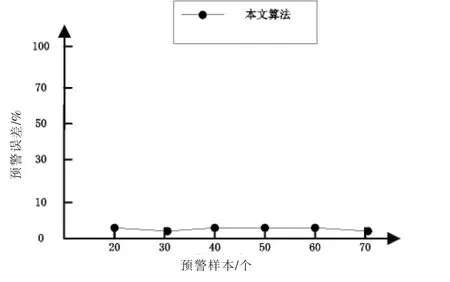
圖4 本文算法預警度對比
3.3 不同算法預警擬合優度對比
分別利用傳統算法和本文算法進行高校財務預警系統設計,對比不同算法進行高校財務預警的擬合優度,對比結果見圖5.利用本文算法進行學校財務預警的擬合優度要高于傳統算法,這是因為采用本文算法進行學校財務預警時,引入Shannon的信息論,改進了選擇測試屬性的規則,保證了本文算法進行學校財務預警的整體優越性(見圖5).

圖5 不同算法預警的擬合優度對比
4 結語
在現階段的國內高校財務管理中,還有部分高校對財務管理存在很多弊端,比如項目實現的速度過于遲緩,導致在規定的情況下,資金還有余額,并且撥款時間間隔較大,但在年底時卻加大撥款的次數和頻率,以至于產生滿溢狀態,影響了高校財務管理的穩定運行.
筆者利用Shannon的信息論對C4.5算法進行改進,并利用改進的C4.5算法設計出新的高校財務預警系統,利用決策樹時刻掌握財務的最新狀況,在一定的情況下,對其發出預警信息,對撥款狀態及時把控,并監督有關的項目進程,實現輔助管理高校財務的目標.高校管理過程較為繁瑣,要建立相關的制度和調配方向,在明確基本方向的基礎上,對實現的具體步驟要有所監督,并對實現的內容要有所評價,同時高校財務管理本身也要做到實施前對其進行規劃,實施中對其財務進行掌控,實施后對其進行評價的路線.而在其中,本文提出的改進C4.5算法可以較大程度的利用積累的信息資源,對高校的財務狀態進行精準預測.
猜你喜歡
江西理工大學學報(2022年2期)2022-07-26 07:05:36
活力(2021年6期)2021-08-05 07:24:28
現代企業(2021年2期)2021-07-20 07:57:18
現代經濟信息(2020年34期)2020-06-08 06:02:40
現代經濟信息(2020年34期)2020-06-08 06:02:40
現代經濟信息(2020年34期)2020-06-08 06:02:36
意林·全彩Color(2019年9期)2019-10-17 02:25:48
活力(2019年15期)2019-09-25 07:21:32
智富時代(2019年2期)2019-04-18 07:44:42
河南水利年鑒(2017年0期)2017-05-19 02:29:27
